Kubernetes Service Discovery
Overview
Kubernetes Service Discovery is the key to unlocking communication between services in dynamic environments. In this article, we'll explore the ins and outs of this crucial aspect within Kubernetes. From DNS-based discovery to service meshes, we'll guide you through methods that empower your applications to effortlessly locate and connect with each other, ensuring efficient load balancing, scaling, and fault-tolerance
Understanding Service Discovery in Kubernetes
In the world of Kubernetes, a service is a clever abstraction that groups Pods together, functioning as network micro-services. These micro-services can perform a variety of tasks for users, ranging from calculations to video playback. Kubernetes offers four main types of services based on their structure and usage.
ClusterIP
ClusterIP stands as the default and most prevalent service type in Kubernetes. These services are endowed with an internal IP address, permitting interaction solely among services within the same cluster. They come in handy for intra-cluster communication. For instance, they facilitate communication between a frontend and a backend application component.
NodePort
NodePort services extend the capabilities of ClusterIP services. Each NodePort service incorporates a ClusterIP service alongside a cluster-wide port. This port acts as a conduit for external requests, channeling them to services within the cluster. While all external requests funnel through this singular endpoint, NodePort services allow connections from outside the cluster via <NodeIP>:<NodePort>. They are particularly useful when external connectivity needs to be established for a group of services.
LoadBalancer
The LoadBalancer services build upon NodePort services. They include a NodePort service complete with its ClusterIP counterpart and a cluster-wide port. For external load balancing, cloud service providers like AWS and Azure create native load balancers that route requests to your Kubernetes services. These services prove beneficial when a cloud service hosts your Kubernetes cluster.
ExternalName
ExternalName services stand apart by being linked to DNS names rather than traditional selectors such as "my-service." By employing a CNAME record, the service aligns with the content of the ExternalName field. This type of service is often employed in Kubernetes to represent external datastores, like databases situated outside of the Kubernetes environment.
How Service Discovery Works
Service discovery emerges as the unifying force that seamlessly connects dynamic microservices.
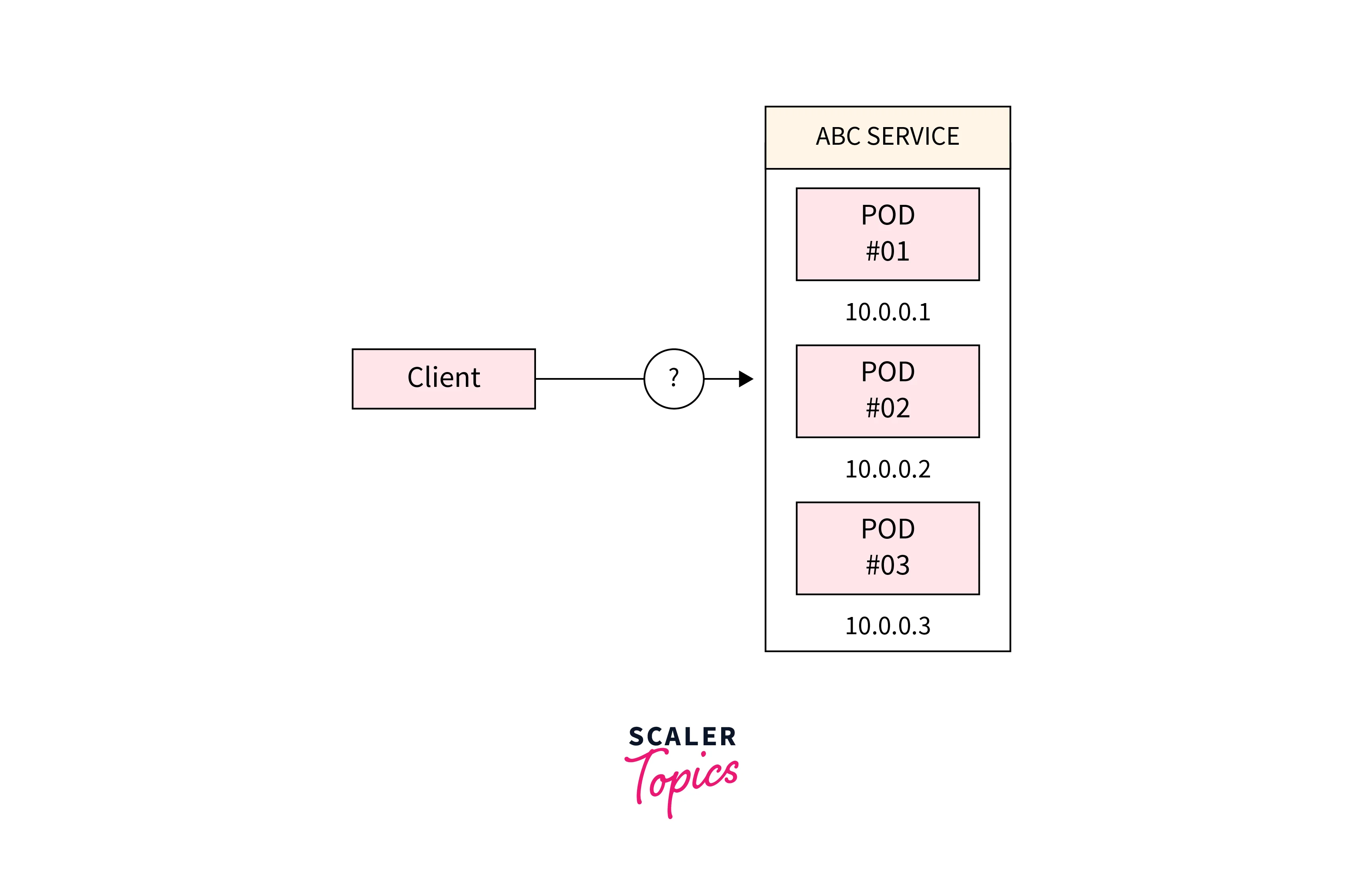
Key Elements of Kubernetes Service Discovery
-
Pods:
These stand as the foundational computational units within Kubernetes, akin to the building blocks of individual containers. They encapsulate application components, providing dedicated environments for each service.
-
Nodes:
The abodes of Pods, Nodes serve as the worker machines in Kubernetes. They offer the computational resources necessary for executing Pods, ensuring service availability and performance.
-
Kubernetes Service:
Acting as a crucial abstraction, a Kubernetes Service bundles together Pods with similar functions and incorporates a defined access policy. This abstraction acts as a conduit, enabling services to communicate without grappling with intricate networking details.
Utilizing Labels and Selectors
The crux of Kubernetes' service discovery mechanism lies in the concept of labels and selectors. Labels function as unique identifiers attached to API objects like Pods and Nodes, carrying metadata for precise identification and categorization. These labels operate both from the server's vantage (labels) and the client's viewpoint (selectors).
By leveraging these labels, Kubernetes effectively associates services with Pods, crafting an abstract unit. This orchestration mirrors the encapsulation principles seen in traditional programming languages like C++ or Java. Each service takes the form of a well-defined function, comprising a group of Pods collaborating harmoniously towards a predefined objective.
Navigating Service Invocation
During service invocation, whether by internal or external clients, the orchestration involves a service manifest enriched with selectors. These selectors serve as the criteria for uncovering pertinent Pods. Kubernetes commences its magic, scanning its environment to pinpoint Pods whose labels align with the stipulated selectors. Once identified, these Pods are allocated to fulfill the requirements of the invoking service.
This multi-layered architecture establishes the groundwork for a swift and adaptable service discovery mechanism within Kubernetes. Amidst the fluidity of containers and Pods, this choreographed symphony guarantees that applications seamlessly spot and interact with the requisite services.
In essence, Kubernetes service discovery operates akin to an invisible maestro, harmonizing the interplay between diverse services and empowering the dynamic realm of microservices to thrive.
Kubernetes DNS-Based Service Discovery
Service discovery manifests itself in diverse ways, and one prominent approach is DNS-based service discovery (DNS-SD). This method, dating back even before the widespread adoption of microservices, leverages the domain name system to facilitate service discovery. DNS-SD's mechanics involve clients querying DNS PTR records for a specific service type, which in turn yield SRV/TXT record pairs containing instance information. These pairs are of the form <Service>.<Domain> and lead to further DNS queries to resolve an instance's domain name into its corresponding IP address.
However, despite its historical significance and usage, DNS-SD presents certain intricacies and limitations. It operates as a service registry rather than a full-fledged service discovery mechanism. Depending on the context, the implementation can take a client-side or server-side form, indicating a level of ambiguity in its deployment. Moreover, while it may appear complex with its layers of indirection, DNS-SD isn't always deemed a comprehensive solution.
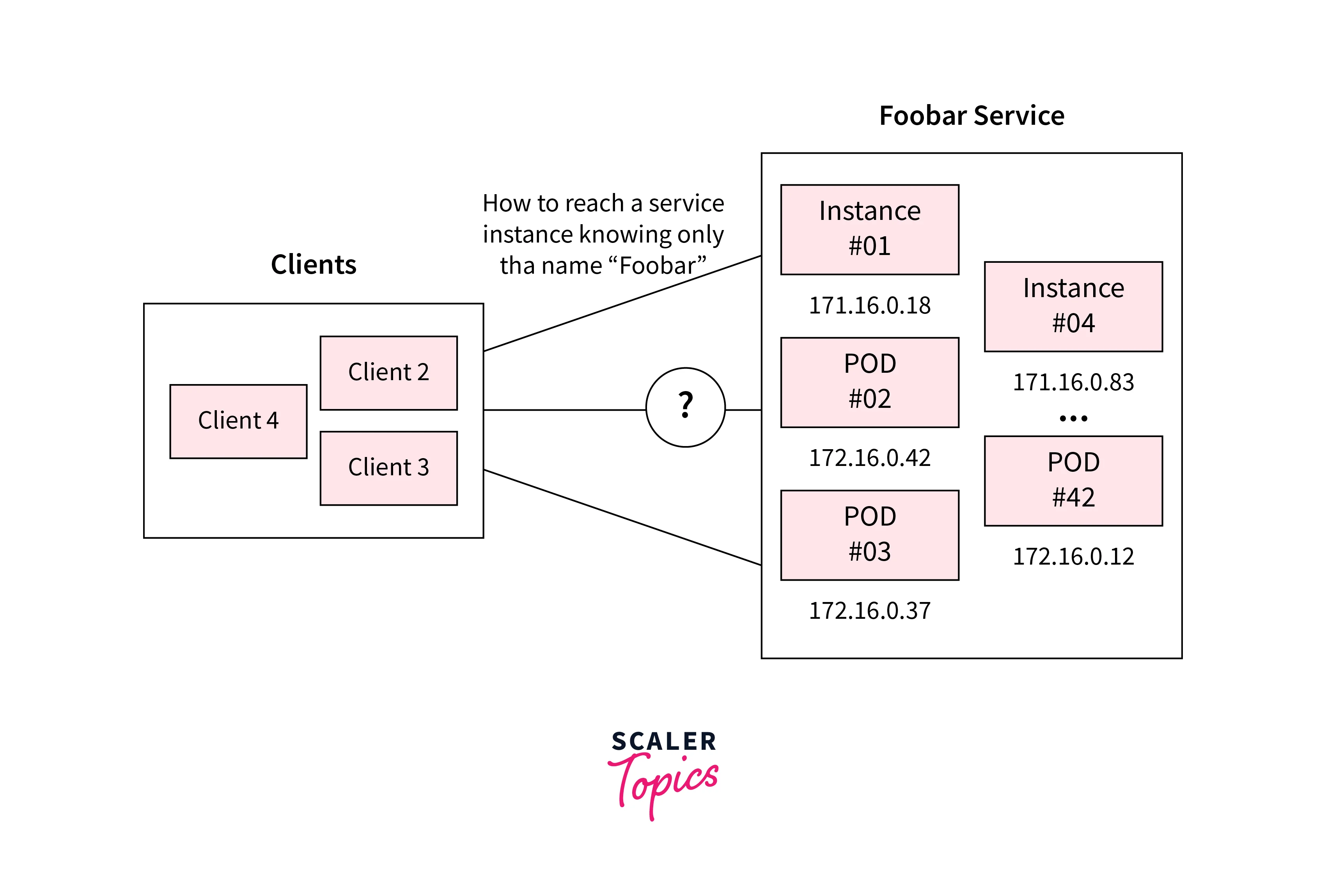
An alternate avenue for service discovery involves the clever utilization of Round-robin DNS. Initially intended for load balancing or distribution, this technique's mechanics entail having multiple A records assigned to the same hostname (service name). In a rotating fashion, these records facilitate the abstraction of numerous replicas behind a singular service name.
Nonetheless, embracing DNS for service discovery isn't without its caveats. A key limitation lies in the slowness associated with updating DNS records. The existence of various cache layers, including those in client-side libraries, combined with historical inconsistencies in TTL (Time-to-Live) values, translates to delays in propagating alterations in the set of service instances to all clients.
While DNS-based service discovery holds its historical significance, its complex layers and inherent limitations make it less than ideal for the dynamic and rapidly evolving world of Kubernetes service discovery.
Creating and Managing Kubernetes Services
The orchestration of a Kubernetes service begins with the configuration of a YAML manifest, which outlines the service's properties and behavior. Here's a glimpse of a service YAML as an illustrative example:
Key Elements of the Service Manifest
metadata
This stands as the logical name of the service. Upon creation, it metamorphoses into the DNS name associated with the service. This name becomes instrumental in how other services and components refer to it.
spec: selector:
The selector is a pivotal aspect that determines the inclusion of specific pods in the service. In the provided example, the pods bearing the label app: nginx are automatically incorporated into the service's realm, forming a united front for communication.
spec: ports:
This section encompasses an array of port configurations, each specifying a distinct network protocol and port number. Optionally, a port configuration can include a targetPort attribute, denoting the port to which the pod should direct its traffic.
Navigating Service Creation
To bring a service to life within your Kubernetes cluster, execute the following command, making sure to adjust the path to your YAML file:
With this command, Kubernetes interprets the provided manifest and instantiates a service that stands as a linchpin for communication among your application's components.
Integrating Services with other Kubernetes Components
Creating a Kubernetes service is only half the equation. To enable seamless communication between the service and the application components, a deployment's (or any other Kubernetes component) selector is pivotal. When defining a service, this selector corresponds to the labels assigned to the pods belonging to the deployment.
By ensuring that the service's selector aligns with the deployment's pod labels, Kubernetes establishes an unbreakable link. This link empowers the service to efficiently route traffic to the designated pods, fostering a cohesive communication network.
Here's a code example showcasing how a service is associated with a deployment:
This manifest file attaches a service port to the pod's port 80.
Service Discovery with Environment Variables
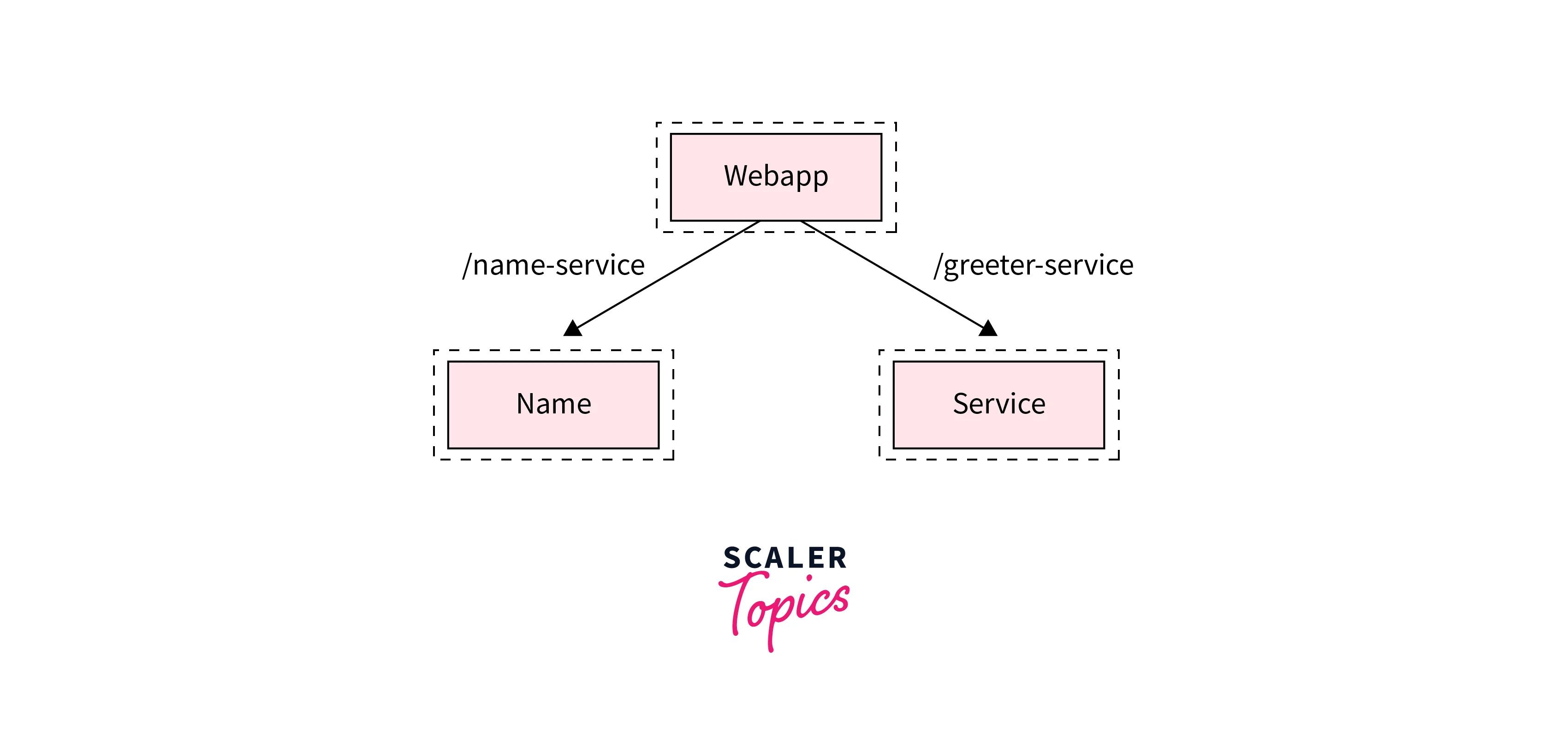
To understand Kubernetes Service Discovery using environment variables, let's discuss a sample application. The application will have 3 services:
-
webapp:
This is a simple microservice that uses the other two microservices to output a greeting for an individual.
-
greeting:
This microservice provides a greeting.
-
name:
This microservice that returns a name.
Assume that these services are built and deployed as Docker images in Kubernetes. The "webapp" service necessitates the configuration of the subsequent environment variables to establish communication with the "name" and "greeting" services. The NAME_SERVICE_HOST GREETING_SERVICE_HOST and NAME_SERVICE_HOST GREETING_SERVICE_HOST environment variables establish references to these services based on their labels, obviating the need for static references like pod or host IP addresses.
The advantage of this approach is that even if an existing "name" and/or "greeting" pod becomes non-functional, the "webapp" service will sustain its functionality, provided that the cluster possesses adequate resources to uphold the operation of the reliant services:
- NAME_SERVICE_HOST
- NAME_SERVICE_PORT
- NAME_SERVICE_PATH
- GREETING_SERVICE_HOST
- GREETING_SERVICE_PORT
- GREETING_SERVICE_PATH
Therefore, the replicaSet that configures our webapp service will have the following variables:
These environment variables will point to greeting and name services respectively.
Kubernetes service discovery hinges on the kubelet's capacity to supply environment variables, allowing pods to interact with other pods connected to a particular service. This orchestration method functions optimally when pods are created after the services they intend to communicate with. In such cases, the environment variables provide a convenient way for pods to access the network of interconnected services.
Not everything is as sooth as it seems. Challenges arise when the timing of service and pod creation doesn't align perfectly. If a pod is generated before its associated service, the necessary environment variables might not be available. Consequently, this situation hampers the ability of pods to engage effectively with the intended services, leading to communication barriers.
The intricate coordination required between service and pod creation can sometimes be akin to a puzzle, with the pieces needing to fall into place at the right time. In an environment where containers and pods are spun up and taken down rapidly, ensuring synchronization between service and pod creation is an ongoing endeavor. Kubernetes is continuously evolving to bridge this timing gap, aiming to ensure seamless communication between services and pods.
Leveraging environment variables presents both, advantages and challenges when it comes to Kubernetes service discovery. While these variables enable smooth communication between pods, they also necessitate meticulous management of service and pod creation timelines. Kubernetes service discovery, driven by environment variables, underscores the platform's commitment to fostering effective inter-pod communication. As Kubernetes evolves, managing the synergy between environment variables and the timing of pod and service creation becomes a vital component of maintaining connectivity and communication among microservices.
Service Discovery with DNS SRV Records
When it comes to Kubernetes service discovery with DNS, we are introduced to a new Kubernetes service, known as the Kubernetes DNS service.
The Kubernetes DNS service plays a fundamental role in facilitating seamless communication within the intricate network of services and pods within a Kubernetes cluster. Before Kubernetes version 1.11, the DNS service relied on kube-DNS, but with the introduction of version 1.11, CoreDNS emerged as a replacement**, aimed at enhancing security and stability.
Irrespective of the underlying software, both kube-dns and CoreDNS operate on a common principle:
-
Service and Pod Creation:
The foundation of the DNS service entails the creation of a service named kube-dns (or CoreDNS) along with one or more pods.
-
Dynamic DNS Record Updates:
The kube-dns service remains vigilant, continually monitoring service and endpoint events emanating from the Kubernetes API. In response to events such as service or pod creation, update, or deletion, kube-dns diligently updates its DNS records.
-
Pod Configuration:
For each freshly instantiated pod, the kubelet meticulously configures the /etc/resolv.conf nameserver option. This configuration aligns the pod's DNS resolution process with the cluster IP of the kube-dns service. Additional search options are thoughtfully incorporated to allow for the usage of shorter hostnames.
The outcome of this orchestration is an environment where applications running within containers can effortlessly resolve hostnames to the corresponding cluster IP addresses. The simplicity and consistency in addressing services and pods are achieved through the Kubernetes DNS mechanism.
Kubernetes DNS Records
A closer examination of Kubernetes DNS records unveils their structural composition and functionality. The comprehensive DNS A record for a Kubernetes service is constructed as follows:
Similarly, for a pod, the DNS record encapsulates the actual IP address of the pod, structured as:
Additionally, SRV records are meticulously generated for named ports associated with Kubernetes services, adopting the format:
Collectively, these records culminate in a DNS-driven service discovery mechanism. This mechanism empowers applications and microservices within the cluster to effortlessly target uncomplicated and consistent hostnames, thereby accessing the spectrum of services and pods interconnected within the Kubernetes framework.
This configuration often renders the use of full hostnames unnecessary. When targeting services within the same namespace, the service name itself becomes sufficient:
When traversing into a different namespace, the namespace must be appended to the query:
For interactions with pods, a slightly more comprehensive structure is required:
It's worth noting that Kubernetes automatically completes only the .svc suffixes, thus mandating explicit specification up to the .pod level to ensure accurate resolution.
Service Discovery with DNS
With the practical utilization of Kubernetes DNS in sight, a dive into the intricate implementation details adds depth to the comprehension of its functionality. Version 1.11 of Kubernetes marked a transition from kube-dns to a new solution, CoreDNS. This transition was prompted by a pursuit of heightened performance and security.
kube-dns:
- kube-dns: Container housing SkyDNS, the engine for DNS query resolution.
- dnsmasq: Container hosting a lightweight DNS resolver and cache that efficiently stores responses from SkyDNS.
- sidecar: Sidecar container responsible for metrics reporting and health checks response.
The adoption of kube-dns was grounded in the need for efficient DNS resolution, but certain security vulnerabilities and scaling performance limitations necessitated the emergence of an alternative, CoreDNS.
CoreDNS:
-
Simplicity:
A single container handles DNS query resolution, caching, health checks, and metrics reporting.
-
Enhanced Functionality:
CoreDNS rectifies the vulnerabilities and scaling constraints of its predecessor. It introduces enhancements such as more efficient compatibility between stubDomains and external services and the ability to optimize DNS-based round-robin load balancing.
-
Smart Resolution:
A feature known as "autopath" heightens DNS response speed when resolving external hostnames. It achieves this by intelligently iterating through each search domain suffix listed in resolv.conf.
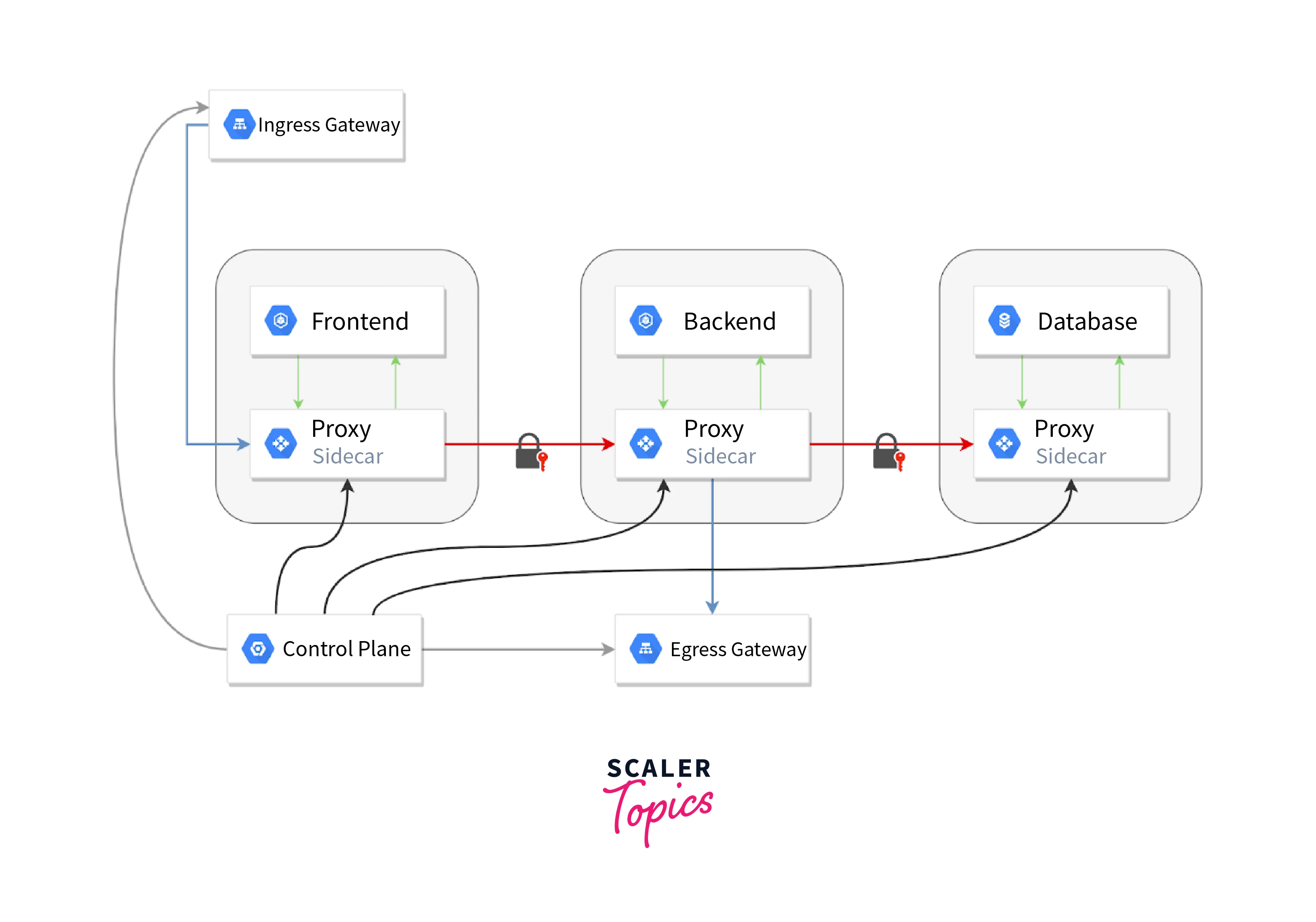
Service Mesh and Service Discovery
In Kubernetes, a service mesh acts as the conductor of service communications within the cluster. This layer sits atop the infrastructure, simplifying and streamlining interactions among services while ensuring scalability and efficiency.
Think of a service mesh as a traffic controller for services. It eliminates manual work and potential errors, lightening the operational load. This comparison mirrors how a parcel is guided through mail routes, reaching its destination faster and more reliably. Similarly, a service mesh guides traffic flow, ensuring seamless communication.
Service mesh excels in untangling the complexity of microservices while providing clear benefits:
-
Connectivity:
Service mesh intelligently routes traffic between services, enabling advanced deployment strategies like blue/green releases. It's like matchmaking for services.
-
Security:
It ensures secure communication by enforcing policies. For instance, it can restrict access to production services from development environments.
-
Monitoring:
Service mesh offers a window into your microservices world, integrating with tools like Prometheus and Jaeger. This provides insights into dependencies, traffic flow, and performance metrics.
Here are some practical use-cases for service mesh:
-
Better Insight into Your Services
With Service Mesh, you gain clear sight into how your services communicate, trace their paths, and keep an eye on their performance. Imagine having a map of your services' interactions, helping you quickly spot and fix problems. For example, if one service slows down, you can temporarily disconnect it to keep things running smoothly.
-
Blue/Green Deployment
Rolling out updates is like changing tires on a moving car. Service Mesh makes it easier. You can introduce new features to a small group of users first, ensuring everything works fine before going big. This way, you reduce the chances of breaking things while enhancing your apps.
-
Testing
Even champions need practice. Service Mesh lets you simulate chaos by creating delays and faults in your system. This helps you find weak spots, making your apps stronger. It's like stress-testing your app without causing a meltdown.
-
Modernize Old Apps
If you're upgrading old apps to fit the new Kubernetes world, Service Mesh acts as a bridge. You can transition piece by piece, without changing how your services talk to each other. Think of it as using a GPS for your old car while planning to buy a new one.
-
API Gateways
Dreaming of Service Mesh but not fully Kubernetes-ready? Start by using it for your APIs. Your operations team can learn the ropes while measuring your API's usage. This is like taking baby steps toward a bigger goal.
Service Mesh and Service Discovery work hand in hand to keep your applications running smoothly. Imagine Service Mesh as a traffic controller, managing communication between different parts of your app. It ensures they talk correctly, helps troubleshoot issues, and even handles upgrades without causing chaos. On the other hand, Service Discovery is like your app's GPS, making sure every service knows how to find others. It helps them connect, share information, and work together seamlessly.
While Service Mesh focuses on how services communicate, Service Discovery ensures they can locate each other. Together, they form a powerful duo, guiding your apps through the complexity of Kubernetes, enhancing reliability, and making your journey even more rewarding.
Best Practices for Service Discovery in Kubernetes
Consider these best practices when exploring Kubernetes service discovery:
-
Tailoring Service Types:
Your application's nature dictates the service type you should opt for in Kubernetes. Four core service types are at your disposal:
- ClusterIP
- NodePort
- LoadBalancer
- ExternalName
-
Precise Configuration:
Defining an apt selector when crafting a service is crucial. Selectors need to be specific and precise to ensure accurate service discovery, bolstering efficiency and reliability.
-
Embrace Probes:
Employ readiness and liveness probes to maintain service health. These probes gauge Pod readiness and functioning status, guaranteeing traffic routes solely to healthy Pods, enhancing overall service discovery reliability.
-
Ingress Implementation:
When external access is imperative, turn to Ingress. This tool empowers you to delineate routing rules, SSL termination, and name-based virtual hosting for services, simplifying external access management while ensuring security.
-
Customize DNS Policies:
Leverage Kubernetes' support for custom DNS policies and stub domains. Custom DNS policies permit tailored Pod DNS query resolution configurations, while stub domains enable the setup of custom DNS servers for specific domains, optimizing service discovery according to your application's distinct needs.
-
Fortify with Network Policies:
To safeguard service discovery's security and coherence, network policies are paramount. By setting these policies, you retain control over traffic flow between services and Pods, permitting only authorized components to communicate. This safeguards your application, warding off potential security threats and maintaining service discovery's overall stability.
Troubleshooting Service Discovery Issues
When navigating the complexities of Kubernetes, addressing service discovery troubles is key. Here's a simplified breakdown to troubleshoot such scenarios:
-
Kubernetes DNS Server Pods:
In modern Kubernetes clusters (since version 1.12), the CoreDNS serves as a dependable DNS server within the cluster. CoreDNS is seamlessly integrated into Kubernetes as a set of Pods managed by a Deployment object called "coredns" in the kube-system Namespace. To confirm operational status:
-
Kubernetes DNS Service Object:
The CoreDNS Pods are accessed through a Service named kube-dns, offering a steady name, IP address, and ports for client connection:
Ensure the CLUSTER-IP value matches each container's /etc/resolv.conf file, and port 53 is properly set.
-
Inspect Kubernetes DNS Logs:
To comprehend the CoreDNS Pods' behavior, inspect logs via:
Ensure a consistent output and watch for any anomalies.
By verifying the operational status of CoreDNS Pods, Service configurations, and inspecting logs, you can promptly troubleshoot service discovery issues within the Kubernetes landscape.
Conclusion
- Service mesh for microservices elevates microservices networking with traffic control, security, and observability.
- Service Discovery using Environmental Variables is better than DNS due to complexity issues.
- YAML manifests create and manage services for efficient routing and policies.
- Kubernetes auto-sets env. variables for pods, streamlining service discovery.
- Service Mesh offers control, security, and visibility, and service discovery aids dynamic routing.
- Check logs and status of pods and deployments to troubleshoot service discovery