Kubernetes Workloads
Overview
Kubernetes workloads refer to the diverse types of applications and processes managed within a Kubernetes cluster. They include Pods, which are the smallest deployable units; ReplicaSets for ensuring a desired number of identical Pods; Deployments for managing updates and rollbacks; StatefulSets for stateful applications; DaemonSets for running a copy of a Pod on each node; Jobs for short-lived batch tasks; and CronJobs for scheduling tasks at specified intervals. These workload abstractions enable efficient deployment, scaling, and management of applications in a Kubernetes environment.
Kubernetes Workload Basic Concepts
Each of the Kubernetes Workloads concepts serves a specific purpose within the Kubernetes ecosystem, catering to various application types, operational needs, and deployment scenarios.
Let's delve into each of these Kubernetes workload concepts in more detail.
-
Pods:
- The smallest deployable unit in Kubernetes.
- Can contain one or more containers sharing the same network and storage.
- Ephemeral in nature, not automatically replaced if they fail.
- Managed manually or through higher-level controllers.
-
ReplicaSets:
- Ensures a specified number of identical Pod replicas are running.
- Provides high availability by automatically replacing failed Pods.
- Doesn't handle updates, focused on maintaining the desired replica count.
- Direct manipulation is less common, often managed through Deployments.
-
Deployments:
- Builds upon ReplicaSets to manage application updates and rollbacks.
- Allows declarative definition of desired state (replicas, image, config).
- Automates scaling and updates while ensuring application stability.
- Enables controlled, gradual changes with minimal downtime.
-
StatefulSets:
- Designed for stateful applications needing unique identities and storage.
- Maintains a consistent, predictable naming convention for Pods.
- Useful for databases, distributed systems, and applications requiring persistence.
- Ensures ordered deployment, scaling, and termination of Pods.
-
DaemonSets:
- Ensures a specific Pod runs on every node in the cluster.
- Ideal for system-level services like monitoring agents or log collectors.
- Guarantees presence of designated Pods across the entire cluster.
-
Jobs:
- Manages short-lived batch processes or one-time tasks.
- Ensures Pods complete tasks successfully before termination.
- Useful for data processing, backups, and other finite operations.
- Suitable for tasks that don't require continuous execution.
-
CronJobs:
- Schedules tasks at specified intervals using cron-like syntax.
- Creates and manages Jobs based on the defined schedule.
- Automates repetitive tasks like backups, data cleanup, etc.
- Offers a way to handle periodic operations in Kubernetes.
Understanding Kubernetes Pods
A Pod is the smallest and simplest unit in the Kubernetes object model. It represents a single instance of a running process in a cluster. A Pod can contain one or more containers that are tightly coupled and share the same network namespace, storage, and other resources. Containers within the same Pod can communicate using localhost, making it suitable for co-located processes.
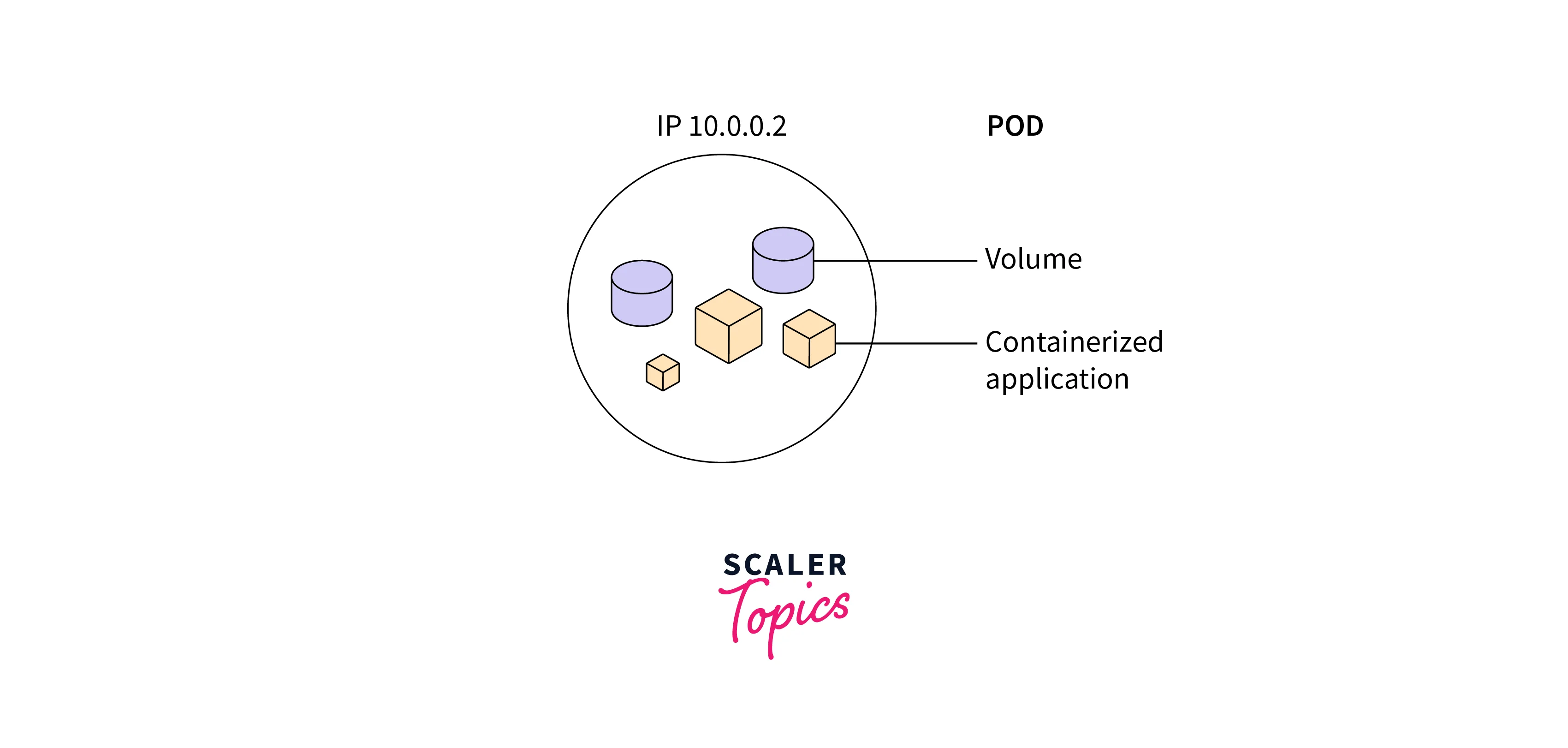
- Atomic Deployment:
Containers within a Pod are deployed together as a single atomic unit. They share the same lifecycle, and if a Pod is scheduled to a node, all containers within that Pod are scheduled to that node as well. - Use Cases:
Pods are often used to group related containers, such as a main application container along with sidecar containers for logging, monitoring, or data synchronization. - Shared Resources:
Pods share the same IP address and port space. They can communicate with each other over localhost, which simplifies inter-container communication. - Single Point of Failure:
Pods are relatively fragile. If a Pod fails or is terminated, all the containers within it are lost. Therefore, it's common to use higher-level controllers like ReplicaSets or Deployments to manage Pods and ensure availability. - Pod Identity:
Pods do not have a stable identity. They can be replaced, rescheduled, or terminated, which makes them unsuitable for stateful applications that require consistent identities. - No Auto-Healing:
Kubernetes does not automatically restart failed Pods. For this reason, ReplicaSets or Deployments are commonly used to manage Pods to ensure desired replica counts and replace failed Pods.
Deployment Workload
Deployment Workload in Kubernetes (K8s) refers to a type of workload that manages the deployment and scaling of containerized applications. Kubernetes provides several workload types to manage different types of applications, and the Deployment is one of the most commonly used workload types.
A Deployment in Kubernetes is a higher-level abstraction that allows you to declaratively define how your application should be deployed and maintained. It ensures that a specified number of replica pods are running at all times, even in the face of failures or updates.
Key features and concepts of a Deployment workload in Kubernetes include:
- Pod Template:
The Deployment specifies a pod template which defines the desired state of the application pods. This includes the container images, resource requirements, environment variables, etc. - Replica Sets:
Behind the scenes, Kubernetes uses a Replica Set to manage the desired number of replicas (pods) based on the template specified in the Deployment. If the actual number of replicas deviates from the desired state, the Replica Set controller automatically adjusts the number. - Scaling:
You can easily scale the number of replicas up or down by modifying the Deployment's replica count. Kubernetes will take care of creating or terminating pods as needed. - Rolling Updates:
Deployments support rolling updates by allowing you to update the application with new versions without any downtime. Kubernetes ensures that the old and new versions are gradually replaced, preventing service disruptions. - Labels and Selectors:
Deployments use labels to select and manage pods. The selector in the Deployment specification is used to identify which pods should be managed by the Deployment. - Pod Affinity and Anti-Affinity:
Deployments can define rules for pod placement to ensure that pods are scheduled on specific nodes based on labels and node characteristics.
Creating a Deployment typically involves creating a YAML file that describes the desired state of the Deployment, including the pod template, replica count, and other relevant configurations. Here's a simplified example of a Deployment YAML:
This YAML creates a Deployment with three replicas of a containerized application named "my-app-container."
StatefulSet Workload
A StatefulSet is another type of workload in Kubernetes that is designed to manage stateful applications. While Deployments are great for stateless applications that can be easily scaled up or down without concern for the individual instances' identity, StatefulSets are intended for applications that require unique network identities and stable storage.
StatefulSets provide a way to deploy and manage stateful applications that maintain a consistent identity and configuration throughout their lifecycle. Some common use cases for StatefulSets include databases (like MySQL, PostgreSQL), message queues (like RabbitMQ, Kafka), and distributed storage systems.
Key features and concepts of a StatefulSet workload in Kubernetes include:
- Ordered and Stable Deployment:
StatefulSets maintain a consistent identity for each of their replicas. They ensure that pods are deployed in a predictable order and maintain their identities across rescheduling or scaling operations. - Network Identity:
Each pod in a StatefulSet has a unique hostname, and the pods are assigned predictable domain names based on the order in which they were created. This is crucial for applications that rely on stable network identifiers. - Stable Storage:
StatefulSets allow you to use Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) to provide stable storage for each replica. This ensures that the data persists across pod rescheduling or updates. - Scaling:
You can scale a StatefulSet by increasing or decreasing the number of replicas. New pods are created with unique identities and stable storage, similar to the initial deployment. - Update Strategies:
StatefulSets offer different update strategies, such as rolling updates and partitioned updates, which allow you to control how updates are applied to the replicas while maintaining the application's stability.
Creating a StatefulSet involves defining a similar YAML configuration, but with additional considerations for pod identity and storage. Here's a simplified example of a StatefulSet YAML:
In this example, the StatefulSet deploys a MySQL database with three replicas. Each pod has a unique identity and is associated with a PersistentVolumeClaim for data storage.
DaemonSet Workload
A DaemonSet is another type of workload in Kubernetes that is used to ensure that a specific pod runs on all (or a subset of) nodes in a cluster. Unlike Deployments or StatefulSets, which focus on running multiple replicas of an application, DaemonSets are designed to run a single instance of a pod on each node.
DaemonSets are often used for system-level tasks, monitoring agents, logging collectors, network plugins, or any other scenario where you need to ensure that a specific pod is present on every node in the cluster.
Key features and concepts of a DaemonSet workload in Kubernetes include:
- One Pod per Node:
A DaemonSet guarantees that exactly one pod runs on each node (or a subset of nodes if you use node selectors or affinity/anti-affinity rules). - Node-Level Operations:
DaemonSets are useful for tasks that need to interact with node-level resources or configurations, such as node monitoring, node-local storage, or networking services. - Autoscaling and Node Additions:
When nodes are added to the cluster, DaemonSets automatically ensure that the specified pod is started on the new nodes. This can be particularly useful in scenarios where nodes are frequently added or removed, such as in cloud-based environments. - Rolling Updates:
DaemonSets can be updated just like Deployments. You can roll out changes by updating the DaemonSet definition, and Kubernetes will manage the rolling update process for you.
Creating a DaemonSet involves defining a YAML configuration that describes the pod's desired state. Here's a simplified example of a DaemonSet YAML:
In this example, a DaemonSet named "my-daemon" is defined to run a single pod with the container "daemon-container" on each node. The DaemonSet ensures that one instance of this pod runs on every node in the cluster.
Job and CronJob Workloads
In Kubernetes, both "Job" and "CronJob" are workload types designed for running batch or scheduled tasks. They are useful for scenarios where you need to perform a task once or at specific intervals, such as data processing, backups, or other time-bound operations.
Here's an overview of the Job and CronJob workloads:
Job
A Job in Kubernetes is a workload that creates one or more pods to perform a task and ensures that the task completes successfully. Jobs are useful for tasks that need to run to completion, meaning they run until the specified task is completed, and then the pods terminate. If a pod fails or terminates before completing the task, Kubernetes automatically creates a replacement pod to ensure the task is completed.
Key features and concepts of a Job workload in Kubernetes include:
- Parallel Execution:
By default, Jobs create one pod to perform the task. If you need to perform tasks in parallel, you can create multiple pods by specifying the desired number of completions in the Job configuration. - Completion and Termination:
Jobs are used for tasks that are expected to run to completion. Once the task is completed successfully, the pod(s) are terminated. If a pod fails, Kubernetes attempts to replace it until the specified number of completions is achieved. - Retry Mechanism:
Jobs can be configured with a retry mechanism. If a pod fails, Kubernetes can automatically create a replacement pod up to a specified number of retries.
CronJob
A CronJob is a Kubernetes workload that allows you to schedule Jobs at specific intervals using cron-like syntax. CronJobs are used for tasks that need to be performed on a recurring basis, such as backups, regular maintenance, or data synchronization.
Key features and concepts of a CronJob workload in Kubernetes include:
- Scheduled Execution:
CronJobs schedule the execution of Jobs at specific intervals defined using cron syntax. This allows you to specify complex time-based schedules, such as hourly, daily, weekly, etc. - Job Creation:
Each scheduled execution of a CronJob creates a new Job instance. The Job carries out the task according to the schedule defined by the CronJob. - Retries and Backoff:
Similar to regular Jobs, CronJobs can also be configured with retry mechanisms and backoff policies. If a Job fails, Kubernetes can automatically create replacement pods based on the configured settings.
Here's a simplified example of a CronJob YAML:
In this example, a CronJob named "my-cronjob" is defined to run a Job every 5 minutes. The Job's pod runs a simple command to print a message.
ReplicaSet Workload
A ReplicaSet is a workload object in Kubernetes that ensures a specified number of replicas (pods) of a particular pod template are running at all times. ReplicaSets are a lower-level abstraction compared to Deployments and StatefulSets, but they serve an essential role in managing the desired number of pod instances in a cluster.
ReplicaSets are typically used to maintain a desired level of availability and scalability for stateless applications. They are often managed by higher-level controllers like Deployments, which provide additional features like rolling updates and scaling strategies.
Key features and concepts of a ReplicaSet workload in Kubernetes include:
- Desired Replicas:
A ReplicaSet ensures that a specific number of replicas (pods) are running according to the desired count specified in its configuration. - Pod Template:
Similar to Deployments, a ReplicaSet specifies a pod template that defines the desired state of the pods, including container images, resource requirements, and other settings. - Pod Scaling:
You can scale the number of replicas up or down by updating the ReplicaSet's configuration. Kubernetes will automatically adjust the number of running pods to match the desired replica count. - Matching Labels:
ReplicaSets use labels to select and manage pods. The ReplicaSet ensures that the number of selected pods matches the desired replica count. - Automatic Healing:
If a pod managed by a ReplicaSet fails or is terminated, the ReplicaSet controller will automatically create a replacement pod to maintain the desired replica count.
Here's a simplified example of a ReplicaSet YAML:
In this example, a ReplicaSet named "my-replicaset" is defined with a desired replica count of 3. It ensures that three pods, each running the "my-container" container, are running based on the pod template provided.
Horizontal Pod Autoscaler (HPA) and Workload Scaling
The Horizontal Pod Autoscaler (HPA) is a feature in Kubernetes that automatically adjusts the number of replica pods in a Deployment, ReplicaSet, or StatefulSet based on observed CPU utilization or custom metrics. HPA helps maintain optimal resource utilization and application performance by dynamically scaling the number of pods up or down in response to workload demands.
Here's how the Horizontal Pod Autoscaler works and how it relates to workload scaling:
- Metrics Monitoring:
HPA monitors metrics from either the CPU usage or custom metrics exposed by the application. You define the metric and the target utilization (e.g., 70% CPU utilization) that you want to maintain. - Autoscaling Decision:
Based on the observed metric values, HPA calculates whether to scale the replicas up or down. If the metric exceeds the target utilization, it triggers scaling up. If the metric falls below the target utilization, it triggers scaling down. - Scaling Mechanism:
When scaling up, HPA creates additional pod replicas to handle the increased load. When scaling down, HPA terminates unnecessary replicas to conserve resources. - Pod Lifecycle:
HPA interacts with the underlying workload controller (e.g., Deployment) to manage the number of replicas. It's important to note that HPA doesn't change the application code; it simply adjusts the number of pods based on observed metrics.
Workload Scaling
Kubernetes workloads scaling is the process of adjusting the number of instances (pods) of a particular workload (Deployment, ReplicaSet, StatefulSet) to accommodate changes in demand. There are two main types of scaling in Kubernetes:
- Vertical Scaling:
Vertical scaling involves changing the resources allocated to individual pods. You can modify the CPU and memory limits and requests for a container within a pod. However, vertical scaling usually involves some level of downtime or disruption, as you're changing the existing pod configuration. - Horizontal Scaling:
Horizontal scaling involves changing the number of pod replicas. This is the type of scaling that the Horizontal Pod Autoscaler (HPA) primarily handles. Horizontal scaling is dynamic and can respond quickly to changing workload demands without service disruptions.
The HPA automates horizontal scaling based on observed metrics, making it a powerful tool to ensure your applications are both performant and cost-effective. It's a valuable part of Kubernetes' self-healing and self-adaptive capabilities, allowing your workloads to automatically adjust to changes in traffic or load.
To use the Horizontal Pod Autoscaler, you need to set up metrics monitoring, define the scaling target, and then create or modify an HPA resource. Here's a simplified example of creating an HPA for a Deployment:
In this example, the HPA scales the "my-app-deployment" Deployment based on CPU utilization, maintaining an average CPU utilization of 70%. The number of replicas can vary between 1 and 10.
Best Practices for Managing Kubernetes Workloads
Managing Kubernetes workloads effectively requires following best practices to ensure stability, scalability, and efficient resource utilization.
- Use Labels and Selectors:
Utilize labels to categorize and organize your resources. Use selectors to associate resources, such as pods and services, based on labels. This helps with managing and querying resources effectively. - Use Namespaces:
Organize workloads using namespaces to isolate applications, environments, and teams. This prevents naming conflicts and provides better resource management. - Resource Requests and Limits:
Set appropriate resource requests and limits for CPU and memory in your pod specifications. This ensures optimal resource allocation and prevents resource contention. - Liveness and Readiness Probes:
Implement liveness and readiness probes in your pod definitions. Liveness probes help restart pods that are unhealthy, and readiness probes ensure that pods are ready to receive traffic before they are added to the load balancer. - Horizontal Pod Autoscaling (HPA):
Use HPA to automatically scale your workloads based on metrics like CPU utilization or custom metrics. - Deployment Rollouts:
Use Deployments to manage your application rollouts. Utilize rolling updates to ensure smooth transitions between versions and to minimize downtime. - Secrets and ConfigMaps:
Store configuration data and sensitive information separately from your application code using Secrets and ConfigMaps. This allows for easier management and enhances security. - Service Discovery and Load Balancing:
Use Services for load balancing and service discovery. Externalize services with LoadBalancers or Ingress controllers for external access. - Stateful Workloads with StatefulSets:
If your application requires stable network identities and storage, consider using StatefulSets to manage stateful workloads like databases. - CronJobs for Scheduled Tasks:
Use CronJobs for scheduling periodic batch jobs or maintenance tasks. - Pod Design Principles:
Follow best practices for pod design, such as a single responsibility per pod, avoiding running as root, and using environment variables or ConfigMaps for configuration.
Conclusion
- Kubernetes workloads refer to the diverse types of applications and processes managed within a Kubernetes cluster.
- Pods are the smallest deployable unit containing one or more containers with shared resources.
- ReplicaSets ensures a specific number of identical pods are running to maintain availability.
- Deployments manages pods and allows easy updates with rolling deployments and rollbacks.
- StatefulSets are used for stateful apps needing stable network identities and ordered scaling.
- DaemonSet guarantees a pod on every node, ideal for node-level tasks.
- Jobs runs short-lived tasks to completion, suitable for batch processing.
- CronJob schedules Jobs at intervals using cron syntax for recurring tasks.