Lazy Evaluation in Spark
Overview
Lazy evaluation in Spark plays a crucial role in optimizing the performance by resource utilization of big data processing. Lazy evaluation in Spark delays the execution of transformations until triggered by an action, which helps Spark to analyze and optimize the computation, resulting in significant improvements in efficiency and scalability.
Introduction
Lazy evaluation in Spark is a technique where computations are delayed until necessary and play a crucial role in optimizing data processing pipelines. By strategically postponing transformations until actions are triggered, Spark leverages lazy evaluation to minimize unnecessary computations, improve resource utilization, and enhance overall performance.
What is Lazy Evaluation?
Lazy evaluation is a key concept in Apache Spark, where the transformations on data are not immediately executed, but rather their execution is delayed until an action is triggered.
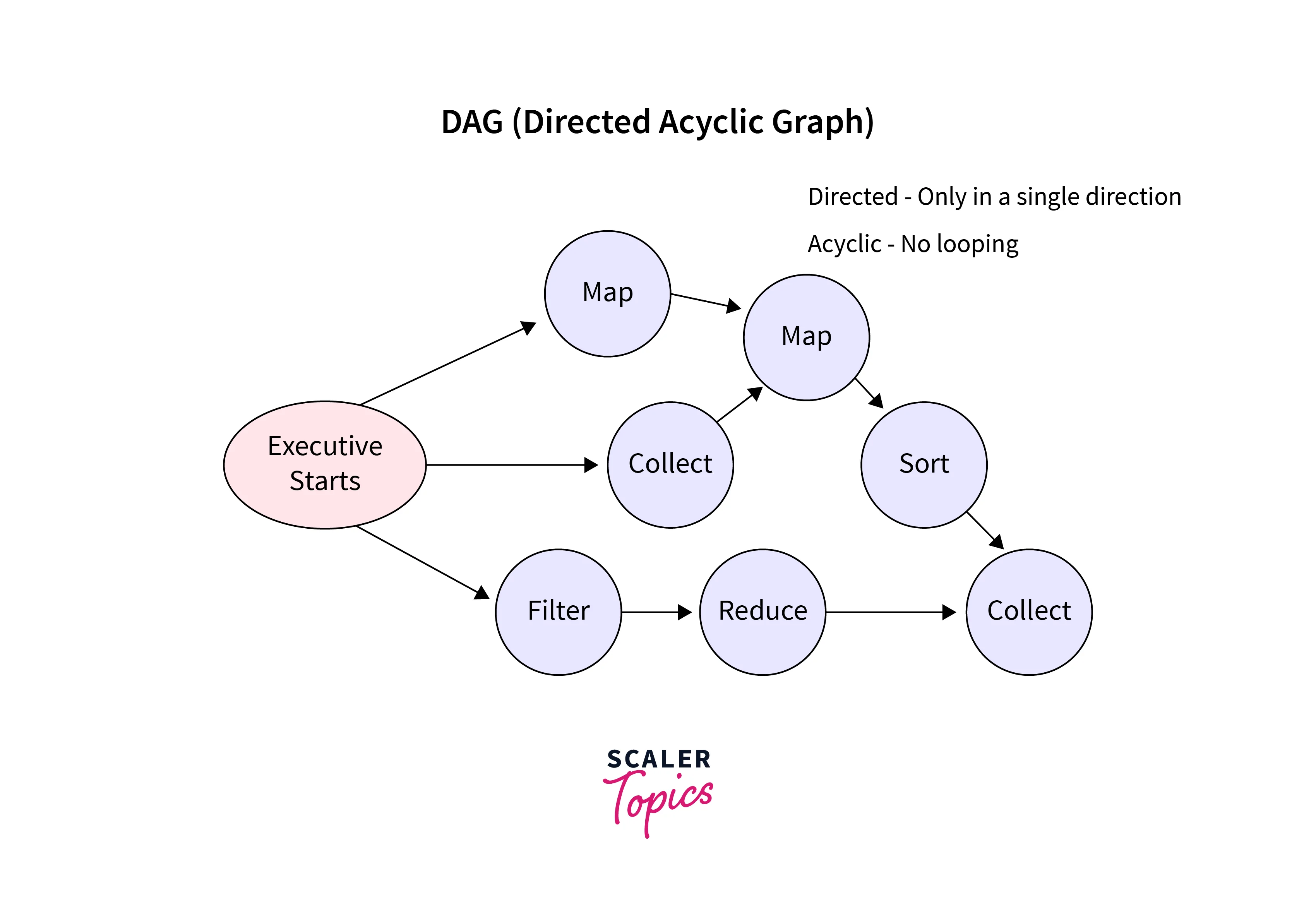
In Spark, transformations are operations that convert an input RDD (Resilient Distributed Dataset) or DataFrame into a new RDD or DataFrame. When transformations are called in Spark, they do not immediately compute their results. Instead, Spark builds up a logical execution plan called the DAG (Directed Acyclic Graph) that represents the sequence of transformations to be applied. The DAG is an internal representation of the computation.
It's important to note that lazy evaluation in Spark does not imply that transformations are never executed. The execution of transformations is deferred until an action is invoked on the RDD or DataFrame. Actions in Spark, trigger the execution of the entire DAG, and the computed results are returned to the driver program or written to an external storage system.
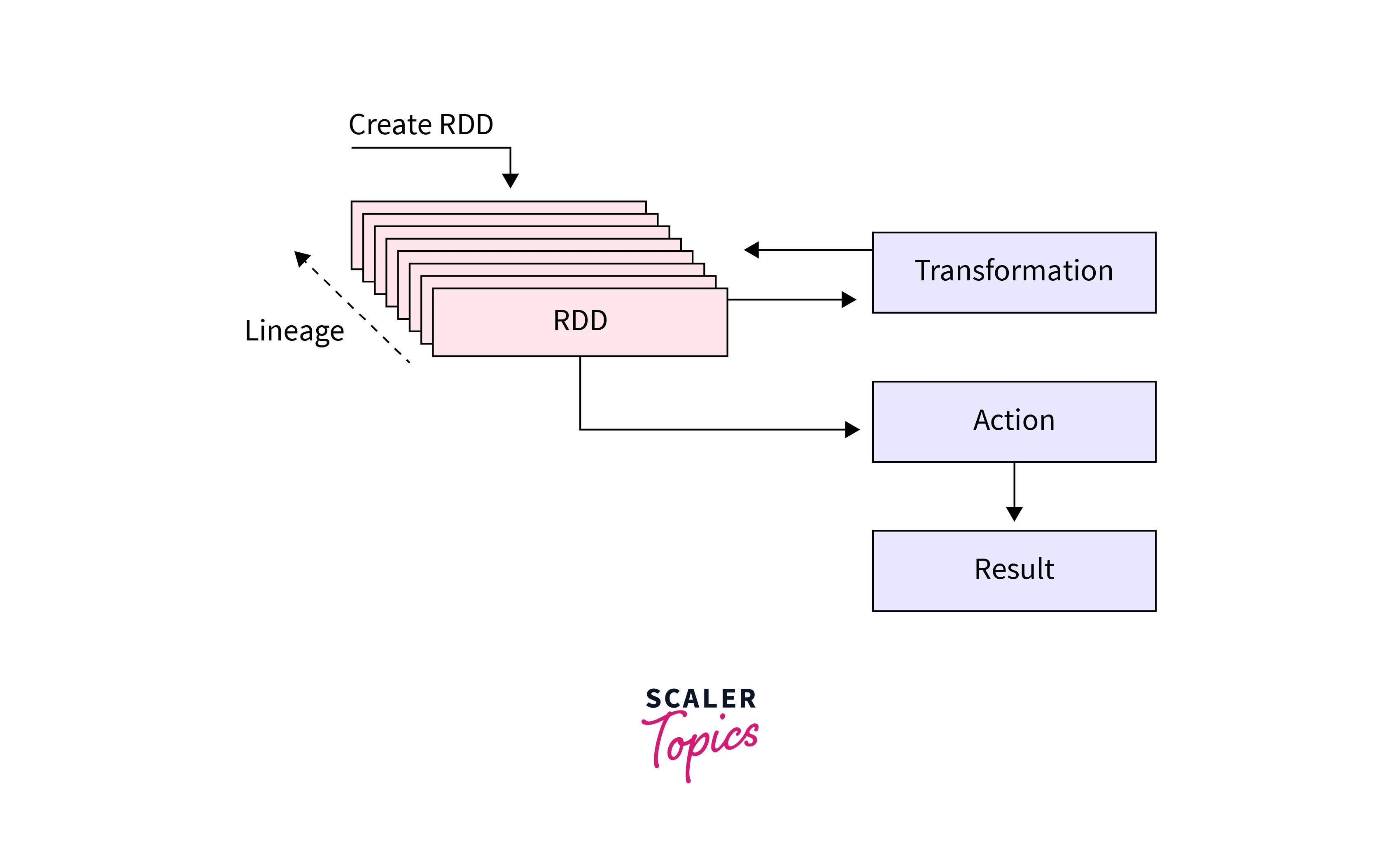
What is the Difference between TRANSFORMATIONS and ACTIONS?
Transformations and actions in Apache Spark, serve different purposes. Let us highlight the crucial differences between them:
| Basis | Transformations | Actions |
|---|---|---|
| Definition | Operation responsible for creating a new RDD, DataFrame, or Dataset from an existing one. | Operations responsible for triggering the execution of computations and returning results or writing data to an external system. |
| Return Type | Returns a new RDD, DataFrame, or Dataset, representing the transformed data. | Returns a value or produces a side effect (e.g., writing to storage, printing, or updating external state). |
| Evaluation | Lazily evaluated. They are not executed immediately but only when an action is triggered. | Causes the evaluation of the DAG and the execution of the preceding transformations. |
| Execution | Its execution can be optimized by applying various techniques such as operator fusion, predicate pushdown, and column pruning to minimize unnecessary. | It executes eagerly, leading to the execution of the transformations required to produce the desired results. |
| Examples | Common transformations in Spark include map, filter, groupBy, and join. | Common actions in Spark include collect, count, take, reduce, and saveAsTextFile. |
Transformations
Transformations in Apache Spark are operations that are applied to distributed datasets (RDDs) or structured datasets (DataFrames or Datasets) to create new RDDs or DataFrames. Transformations are lazily evaluated, meaning that they do not immediately execute, but instead, build a logical execution plan (DAG) that represents the sequence of transformations to be applied. When an action is triggered, the transformations are executed in an optimized manner.
Transformations in Spark enable data manipulation, filtering, aggregations, and more. Transformations are immutable, meaning they do not modify the original RDD or DataFrame but create a new one with the applied transformation.
Some common transformations in Spark are:
- Map
- Filter
- FlatMap
- GroupBy
- ReduceByKey
- Distinct
- Sort
- Sample
- Union
- Join
- Aggregations
Actions
Actions in Apache Spark are operations that trigger the execution of computations and return results or write data to an external system. Unlike transformations, which are lazily evaluated, actions trigger the DAG to be executed which leads to the evaluation of transformations and the production of final results.
Actions are eager operations and can cause significant computational and I/O costs, especially when working with large datasets.
Some commonly used actions in Spark are:
- Collect
- Count
- First
- Take
- Reduce
- Aggregate
- Save
- Foreach
- CountByKey
- CollectAsMap
Spark’s Catalyst Optimizer
Spark's Catalyst Optimizer is a powerful query optimization framework that is built into Apache Spark's SQL and DataFrame API. It is responsible for optimizing and transforming the logical and physical execution plans of Spark queries. The Catalyst Optimizer performs a wide range of optimizations including predicate pushdown, column pruning, operator reordering, constant folding, and more.
It leverages a rule-based approach, along with various optimization techniques, to transform and optimize logical and physical query plans. By reducing data movement, computational overhead, and memory consumption, the Catalyst Optimizer helps Spark deliver efficient and scalable data processing capabilities.
Some of the key features and benefits of Spark's Catalyst Optimizer are:
-
Logical and Physical Query Plans:
Catalyst operates on two levels: logical and physical plans. The logical plan represents the high-level operations and transformations specified by the user, while the physical plan represents the actual execution steps.
-
Rule-Based Optimization:
Rule-based optimization applies a set of predefined optimization rules that match a specific pattern in the plan query plans, transforming and simplifying them to produce an optimized plan.
-
Predicate Pushdown:
Catalyst pushes predicates (filters) as close to the data source as possible. This reduces the amount of data that needs to be processed in a query.
-
Column Pruning:
Catalyst performs column pruning by eliminating unnecessary columns from the query plan. It analyzes the columns used by each operator and removes any unused columns, reducing data transfer and memory consumption.
-
Expression Simplification:
Catalyst simplifies complex expressions by applying algebraic and logical simplification rules. It simplifies expressions by replacing them with equivalent, simpler forms, reducing the complexity of the overall query plan.
-
Extensibility:
Catalyst allows users to define their own optimization rules and strategies. This enables customization and fine-tuning of the optimization process to suit specific use cases or data scenarios.
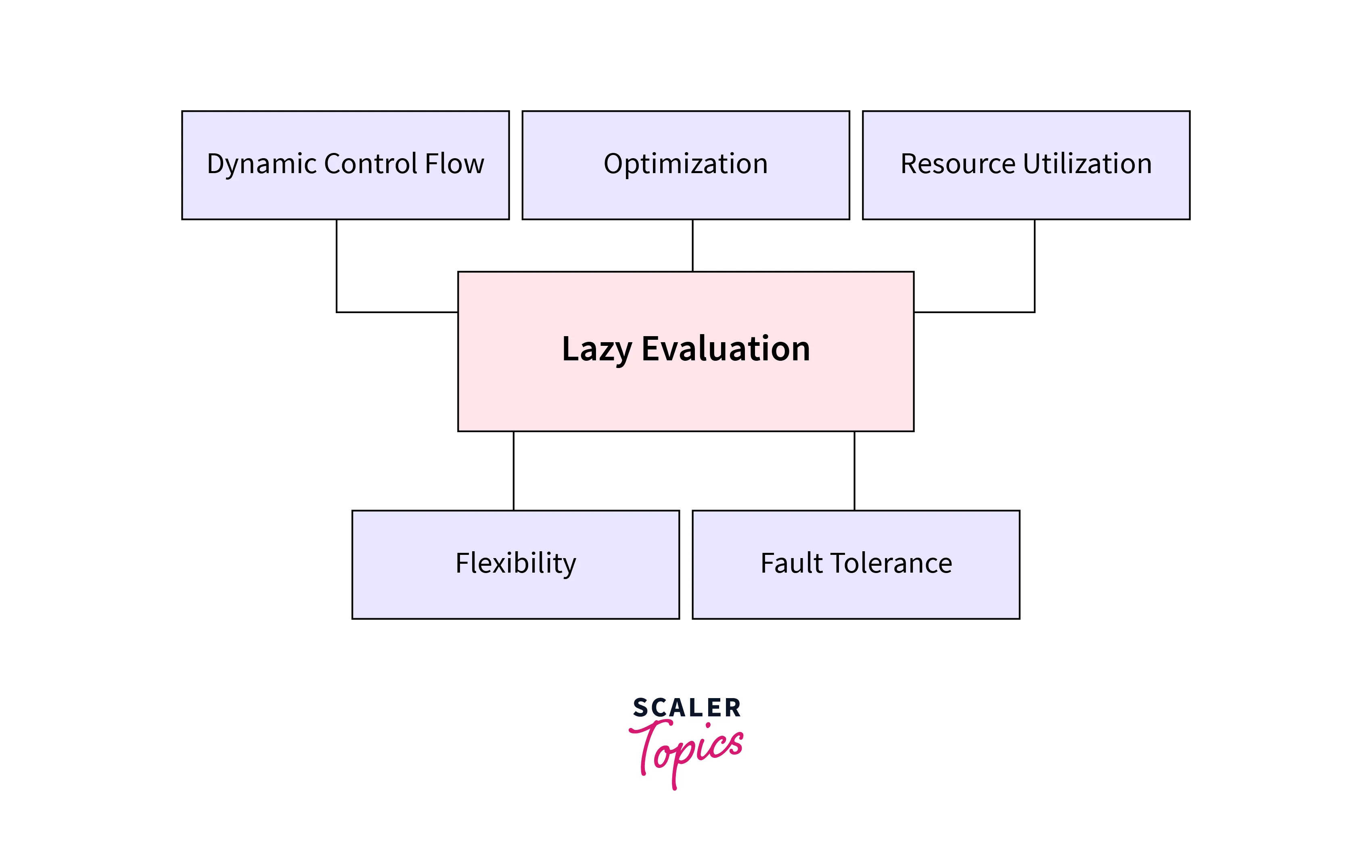
What are the Advantages of Using Lazy Evaluation?
Using lazy evaluation in Spark provides several advantages in programming and data processing. Let's see some of its key advantages:
-
Optimized Performance:
Lazy evaluation allows for optimized performance by delaying computations which means that unnecessary computations and operations can be avoided, resulting in improved runtime efficiency and reduced processing time.
-
Resource Efficiency:
Lazy evaluation helps in efficient resource utilization. By delaying the execution of computations until they are needed, unnecessary resource allocation, memory consumption, and CPU usage can be avoided.
-
Short-Circuiting:
Lazy evaluation enables short-circuiting, where computations are terminated early if the result is already determined. This is particularly useful when dealing with conditions or loops where the subsequent computations are irrelevant or unnecessary based on an earlier result.
-
Flexibility and Composition:
By deferring computations, lazy evaluation allows functions and expressions to be composed, combined, and reused in various contexts without immediately executing them. This enables modularity, code reuse, and the creation of more flexible and composable software components.
-
Dynamic Control Flow:
Lazy evaluation facilitates dynamic control flow and conditional execution. It allows programs to evaluate and execute different parts of the code based on runtime conditions, enabling more dynamic and adaptable behavior.
-
Incremental and On-Demand Processing:
Lazy evaluation supports incremental and on-demand processing of data. It allows for processing data in smaller chunks or batches, reducing memory requirements and improving efficiency when dealing with large datasets.
-
Error Handling and Fault Tolerance:
Lazy evaluation can improve error handling and fault tolerance in applications. By postponing computations until necessary, it provides an opportunity to catch and handle errors more effectively.
Conclusion
- Lazy evaluation in Spark is a powerful optimization technique in Apache Spark that improves the performance and resource utilization of big data processing.
- Lazy evaluation in spark delays the execution of transformations until they are triggered by an action, which helps to apply various optimizations, and pipeline computations, and minimize unnecessary computations and data movement.
- Transformations are lazily evaluated, meaning that they do not immediately execute, but instead, build a logical execution plan (DAG) that represents the sequence of transformations to be applied.
- Actions cause the DAG to be executed which leads to the evaluation of transformations and the production of final results.
- Spark's Catalyst Optimizer is a query optimization framework in Apache Spark that transforms and optimizes logical and physical query plans to improve query performance and efficiency.