Program to Calculate the Levenshtein Distance in List in Python

Overview
Levenshtein Distance, also known as Edit Distance, is a measure of similarity between two strings of characters. Given two words, the Levenshtein Distance is defined as the number of characters needed to be inserted, deleted, or replaced in one string, to transform it into another string. The algorithm returns a numeric value representing the similarity between the two strings. Less is the Levenshtein distance, more is the similarity.
What is Levenshtein Distance?
Have you ever wondered how word processors like MS Word and Google Docs can identify misspelled words and provide suggestions? These word processors use multiple string algorithms to match each word written by the user against the words in their dictionary. Now, identifying misspelled words can be done using a standard String Matching algorithm. However, to provide suggestions, the processors need to find a list of such words that are close similar to the misspelled word. In simpler words, the processor needs an algorithm that computes the similarity between two words. This can be calculated by finding the Levenshtein Distance between the two strings.
Levenshtein Distance (a.k.a Edit Distance) calculates the distance between two words and returns a number representing how similar the words are. The number represents the total number of edits required to transform one word into another. There are three ways by which the editing can be done:
- Insertion A new character can be inserted anywhere in the given string. Example: A: "helo" B: "hello" We can insert the character 'l' at position 4 in string A to get string B.
- Deletion A character can be deleted from anywhere in the given string. Example A: "helloo" B: "hello" We can delete a character at position 6 in string A to get string B.
- Replacement A character can be replaced with the other character. Example A: "hella" B: "hello" We replace the character 'a' with 'o' at position 5 in string A to get the string B.
Each of these operations adds 1 to the edit distance.
Understanding the Levenshtein Algorithm
Problem Statement
Consider two input strings A and B of length n and m respectively, containing lowercase English letters only. The problem is to find the Levenshtein distance between A and B using the following edits:
- Insert a character in A
- Delete a character from A
- Replace a character in A with any other character.
The cost of each operation is 1.
Algorithm (Using sub-subproblems)
Levenshtein distance between two strings can be found using dynamic programming. The algorithm exhibits the property of overlapping subproblems.
Consider the strings A and B.
- Case 1: . In this case, we can skip the first position and the edit distance of the whole problem is equal to the edit distance of and . Here means substring of from position to position .
- Case 2: . In this case, we will use the three operations mentioned above to find the edit distance.
- Insert in : The edit distance is equal to 1 + the edit distance of and . This is because the first character in matches the newly added first character in .
- Delete : The edit distance is equal to 1 + the edit distance of and . This is because we have simply deleted the first character in . The characters left in both strings will contribute to the edit distance of the whole problem.
- Replace with : The edit distance will be equal to 1 + the edit distance of and . The edit distance will be the minimum cost of inserting, deleting, or replacing the characters in to get the string .
The general idea of the algorithm is to transform the prefix of string equal to the prefix of string using the minimum number of insert, delete and replace operations. At every mismatch, we need to apply the three types of edit and choose the operation that minimizes the overall edit distance of the problem.
Example
Let us consider an example where = "gate" and = "goat". To calculate the Levenshtein distance, we will use the above approach.
- = "gate" and = "goat". Since , we simply move to the next character.
- Since , we have three choice. If we perform:
- Insert: We get = "goate" and = "goat".
- Delete: We get = "gte" and = "goat".
- Replace: We get = "gote" and = "goat".
Now if we look at the choice where we insert an element, we see that deleting the last character from = "goate" will transform it into the string B. Hence in this case the edit distance will be . In the rest cases, we see that the number of operations will be more, so we take the minimum of the three cases. Edit Distance of = "gate" and = "goat" is .
Understand the Array
Now to efficiently compute the result, we need to add memoization in the above algorithm. To do this, we need some states to define a subproblem uniquely. To identify a subproblem, we only need to know the length of the prefix of string and string . Hence we need two variables and , to define our dynamic programming states. Let us define = Levenshtein distance of string and string .
Base Case: In the base case, we can consider that the length of one of the strings is . In this case, we will either use only insert operations, if the length of is , or else we will use only delete operations if the length of string is . for all from to . for all from to .
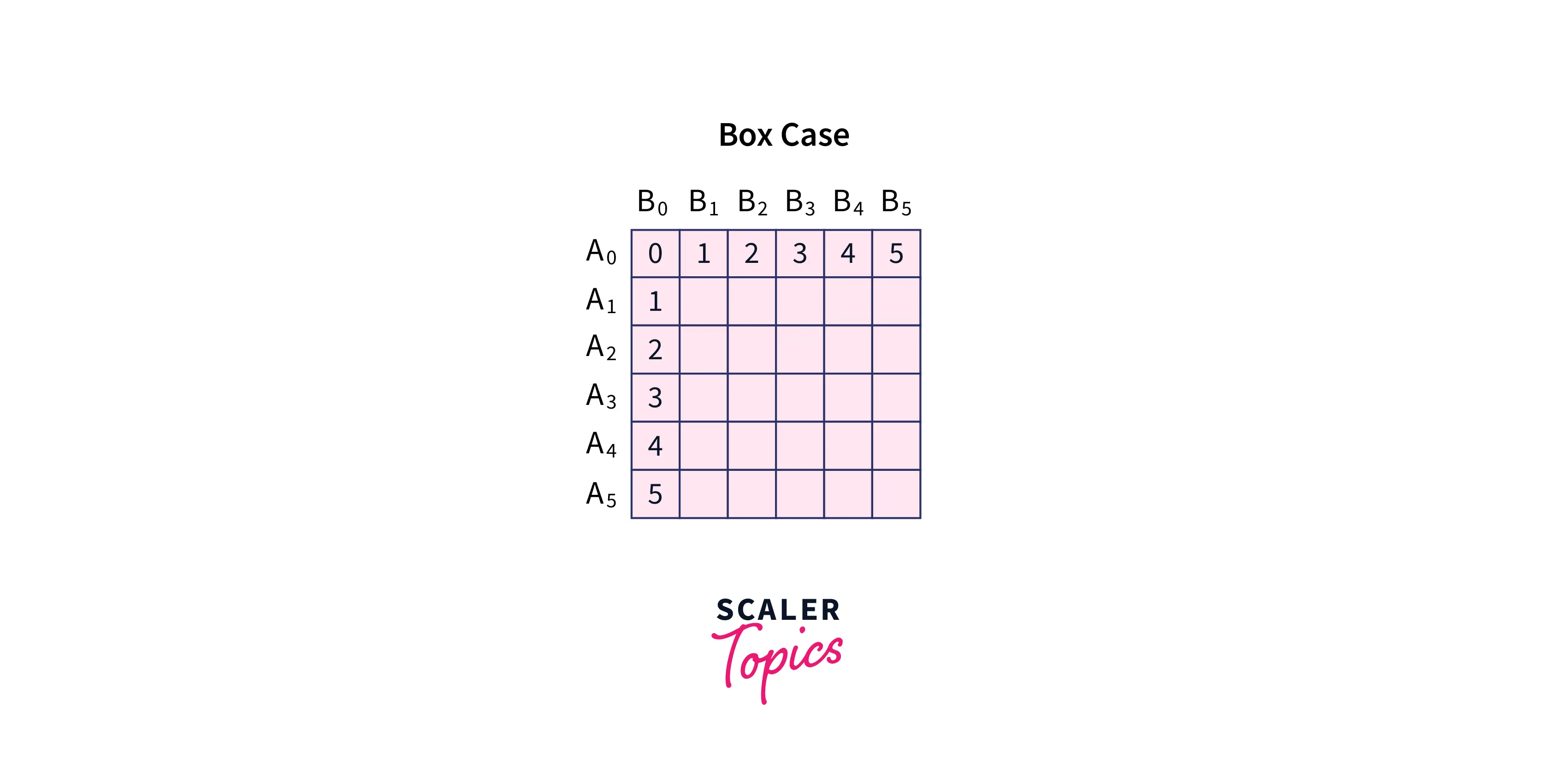
Transitions
Suppose we want to calculate the edit distance of and , then
- Case 1:
- Case 2: . In this case, we need to perform an edit operation.
- If we perform insert operation then we will take characters from and characters from , so .
- If we perform delete operation then we have not matched the character in B yet, so we simply carry forward the edit distance calculated till character of and character of , so .
- If we do a replace, then , as we have replaced character of with character of .
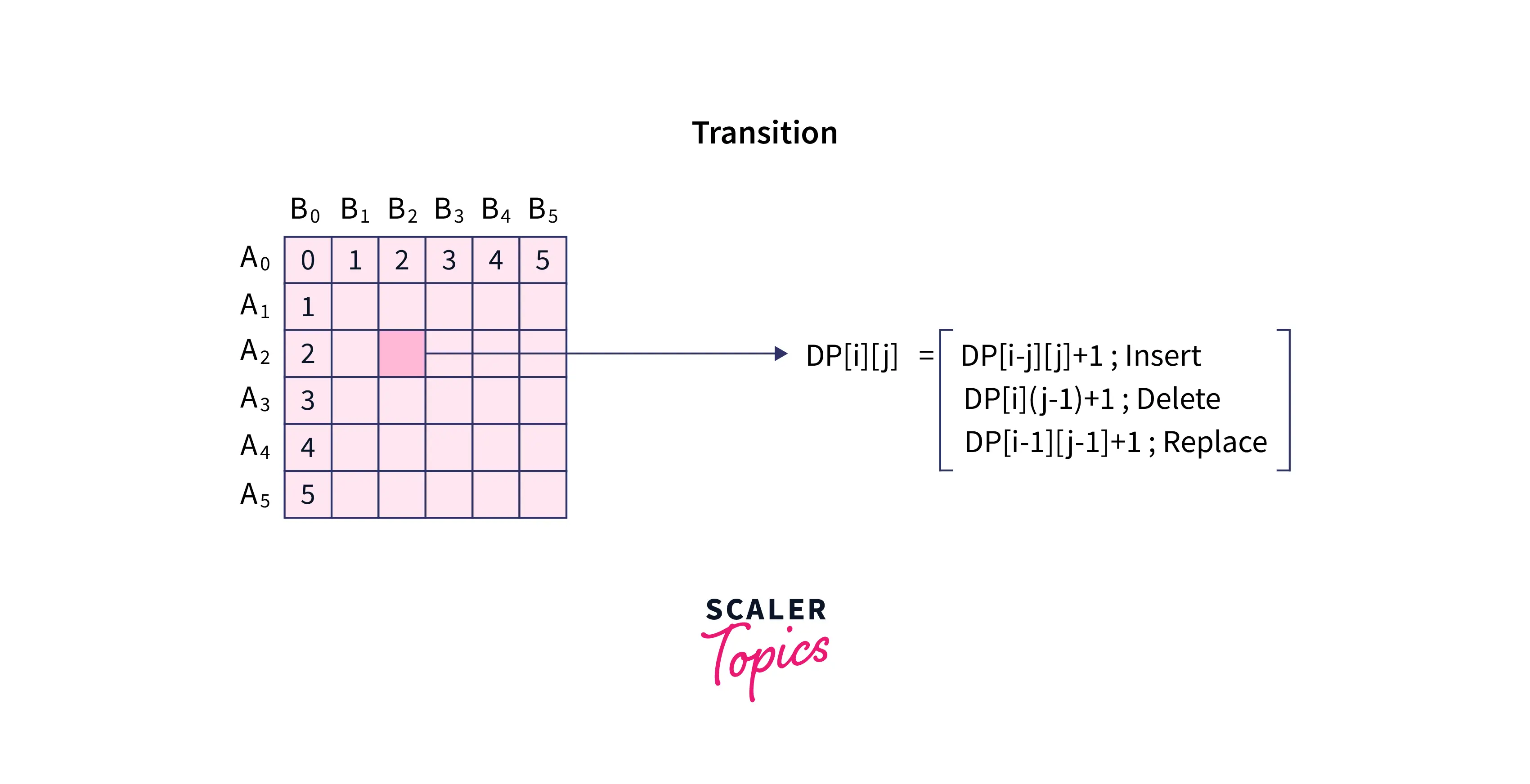
Finally, we write
Final Output After we calculate all the transitions, the Levenshtein Distance will be equal to .
Example
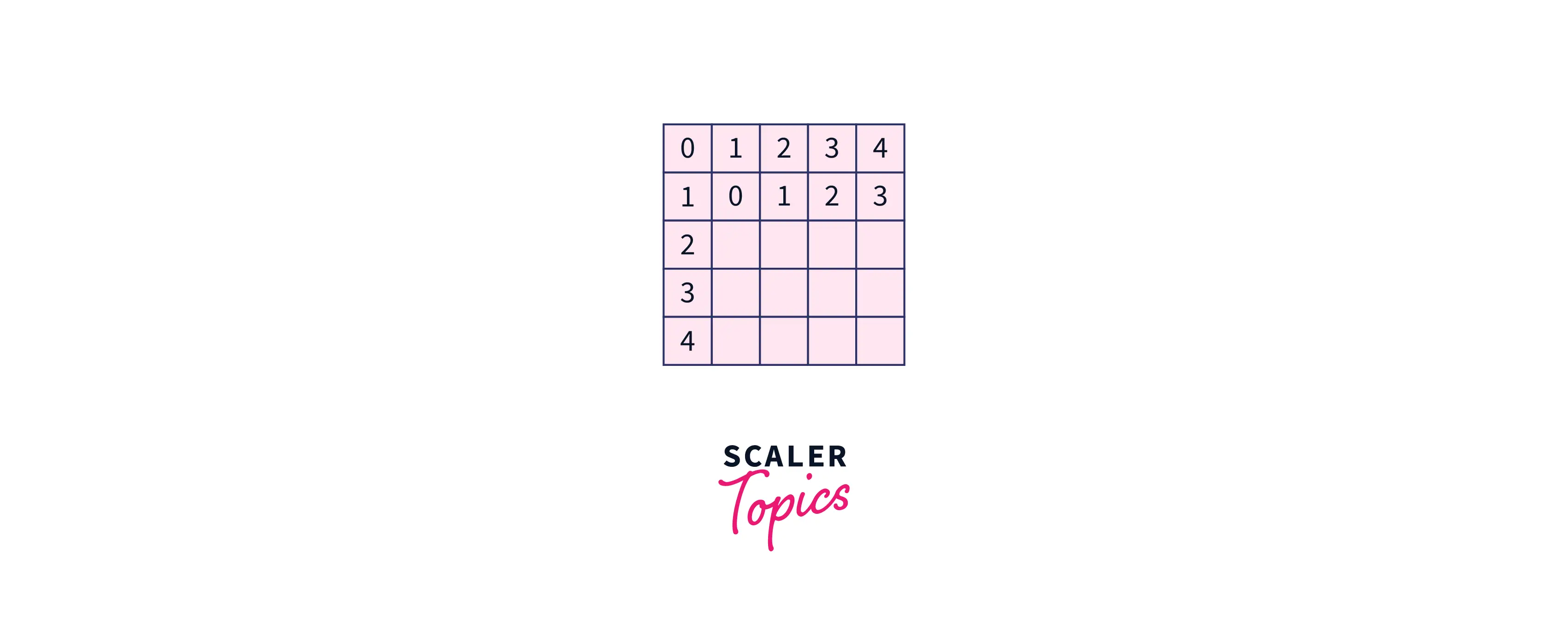
Let us look at the matrix for = "gate" and = "goat". Here . Consider and be the iterators. When and we calculate the edit distance for with all the prefixes of . Since , . Since is an extra character, a delete operation is required, . In this way, we build the rest of the matrix.
When and , we calculate the edit distance for with all prefixes of .
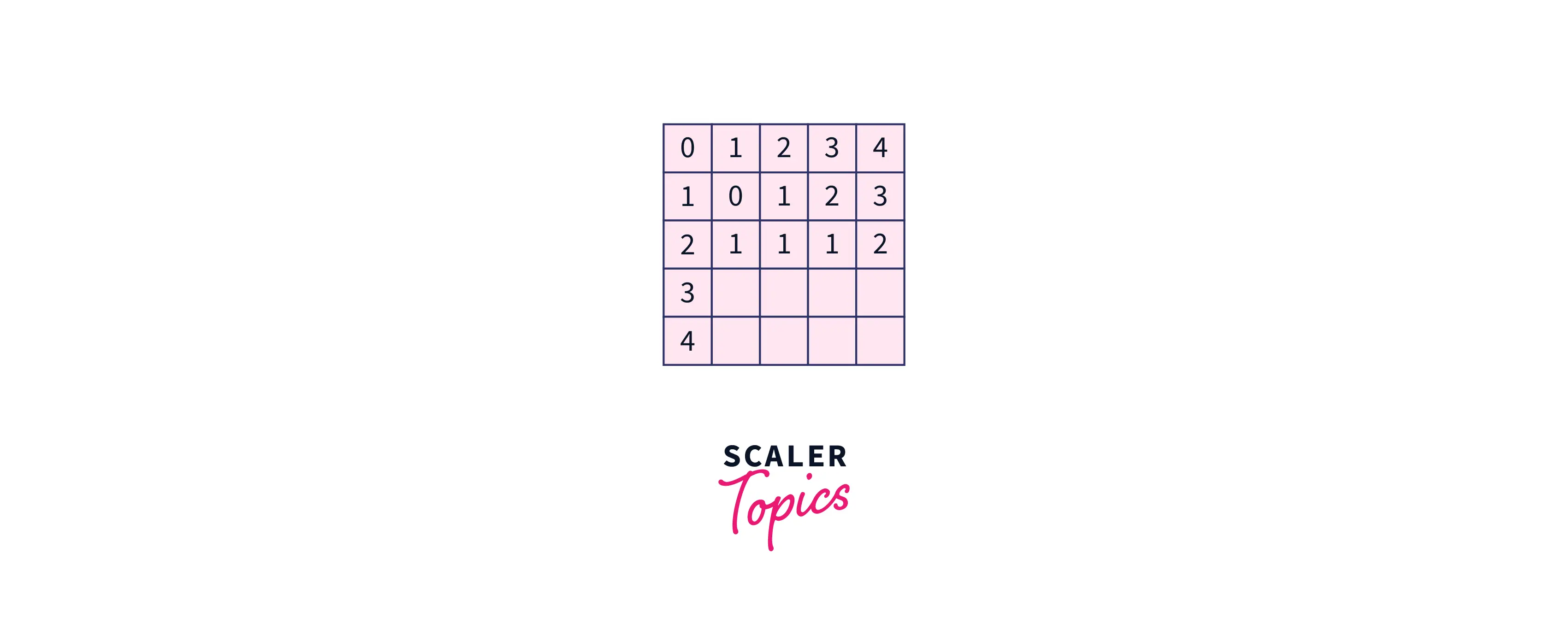
Repeating the same process, we will end up with the whole matrix.

Implementation
Output
Complexity Analysis of Levenshtein Algorithm
Time Complexity
In the implementation, we have a state, and for each transition, we take time, hence the time complexity is where and are the lengths of strings and respectively. Time Complexity:
Space Complexity
In the implementation, we use a table to store states of the problem, hence the space complexity is where and are the lengths of strings and respectively. Space Complexity:
Calculating the Levenshtein Distance using Enchant
Introduction
Spell Checking in Python is also implemented in the in-built module pyenchant. This module can be used to calculate the Levenshtein distance between two strings. To download this package, run the following command in the terminal:
Algorithm
The following function pyenchant.utils.levenshtein() can be used to calculate the edit distance between two strings. This function is a library implementation of the above-discussed algorithm.
Example
Output
Conclusion
- Levenshtein distance is used to measure text similarity between two strings. It is equal to the number of edits (insert, delete, replace) required to convert one string into another.
- The Levenshtein algorithm exhibits the property of overlapping sub-problem, hence dynamic programming is used to calculate the same.
- Levenshtein algorithm is also available as an inbuilt function in the pyenchant library. When developing a spell checker, can be very helpful.