Linear Algebra for Data Science

Linear algebra for data science is an indispensable mathematical framework, providing the foundation for various data analysis and machine learning tasks.
Importance of Linear Algebra in Data Science
The importance of linear algebra for data science cannot be overstated, as it is fundamental to numerous aspects of the field:
- Algorithm Development:
Linear algebra for data science is essential for developing and understanding the mathematical underpinnings of data science algorithms, particularly those in machine learning and statistics. - Data Manipulation:
It provides the tools for efficient data manipulation, allowing for operations on large datasets that are common in data science. - Modeling and Optimization:
Linear algebra for data science is crucial for creating models that can be optimized and scaled effectively, ensuring that they can handle real-world data sizes and complexities.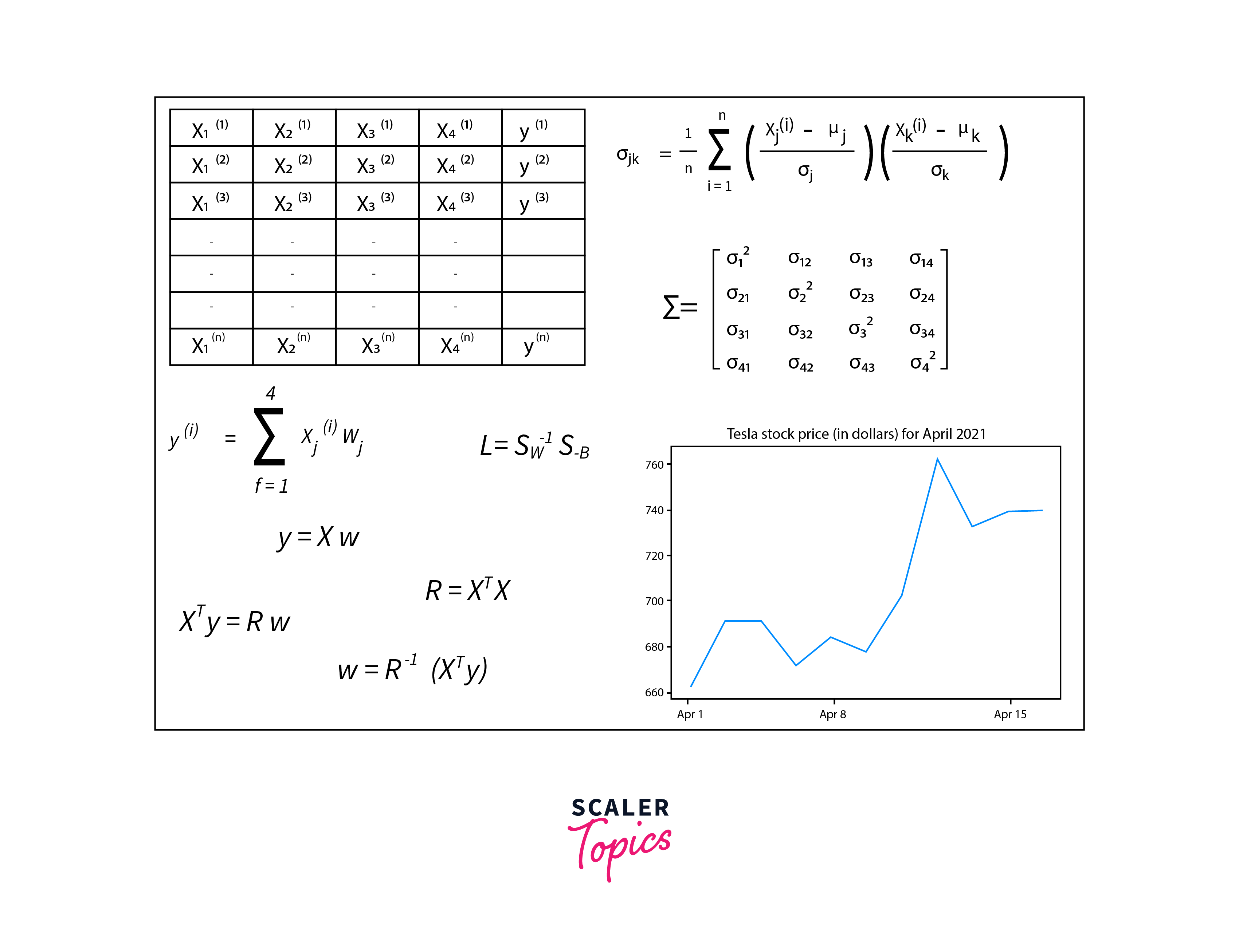
- Advanced Data Analysis:
Techniques like singular value decomposition (SVD) and eigen decomposition, which are central to advanced data analysis tasks, rely heavily on linear algebra principles. - Facilitating Machine Learning:
From basic regression models to advanced neural networks, linear algebra for data science is at the heart of machine learning algorithms, enabling them to learn from data and make predictions. - Handling Multidimensional Data:
Linear algebra is key to managing and interpreting multidimensional data, making it indispensable for tasks involving images, videos, and other complex data types.
Representation of Problems in Data Science
In data science, representing problems effectively is crucial for analysis and solution development. Linear algebra for data science plays a pivotal role in this representation by providing a structured and efficient way to handle and manipulate data. Here’s how problems in data science are commonly represented using linear algebra:
- Vector Representation:
Individual data points can be represented as vectors in a high-dimensional space, where each dimension corresponds to a feature or attribute of the data. This vector representation is fundamental in numerous data science tasks, including classification and clustering.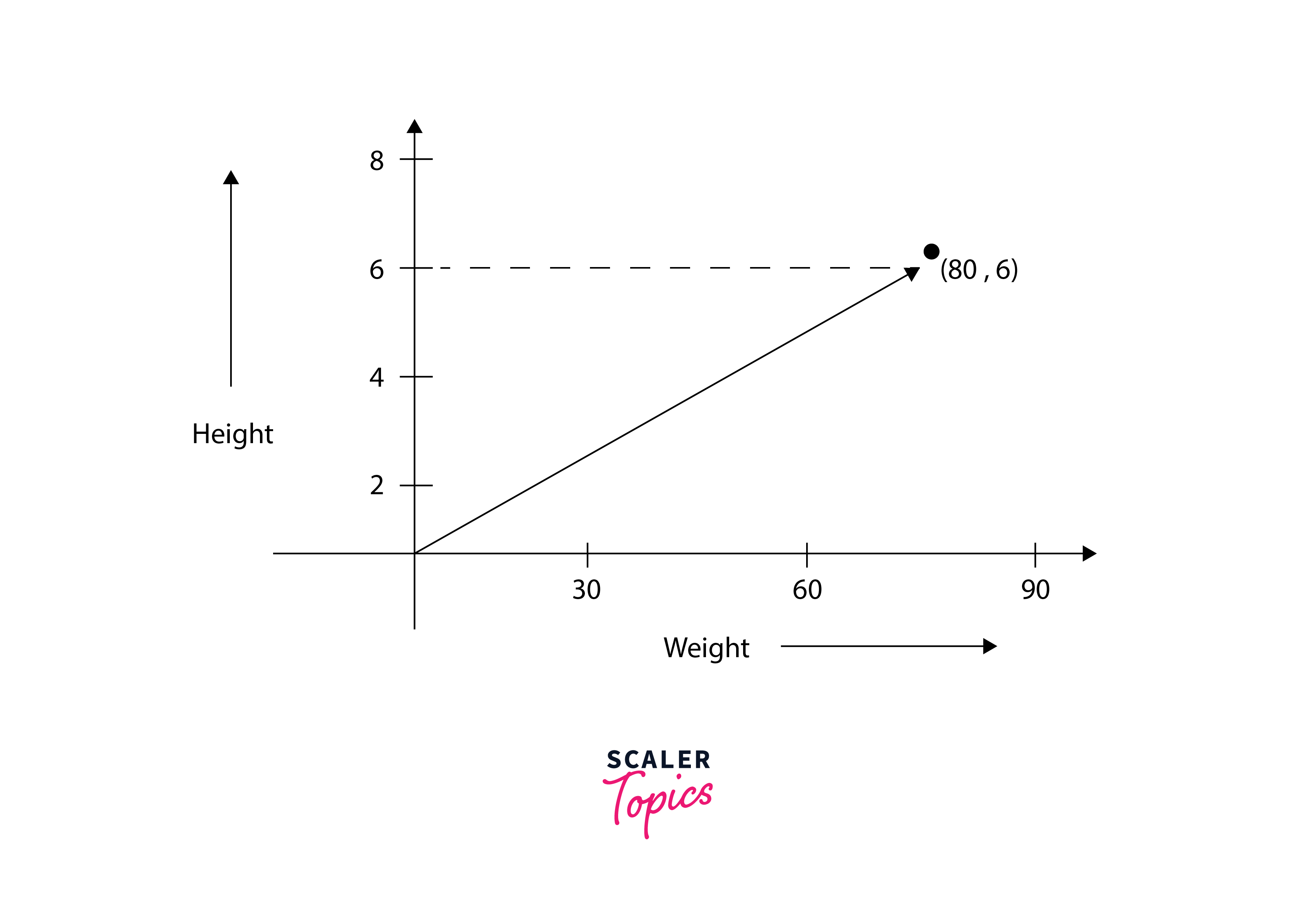
- Matrices for Data Sets:
Entire datasets are often represented as matrices, with rows corresponding to individual records and columns to features. This matrix format is conducive to applying linear algebra operations for data preprocessing, transformation, and analysis. - Tensors for Complex Data:
For more complex data types, such as images or time-series data, tensors (multidimensional arrays) are used. Tensors extend the concept of matrices to higher dimensions and are crucial in fields like computer vision and deep learning. - Linear Equations and Systems:
Many data science problems, especially those involving predictions and optimizations, can be formulated as systems of linear equations. Solving these systems is a fundamental application of linear algebra, enabling the discovery of relationships and patterns within the data.
- Transformation and Dimensionality Reduction:
Linear transformations, represented by matrices, are used to change the basis of data, often for dimensionality reduction. Techniques like Principal Component Analysis (PCA) are based on linear algebra and are essential for simplifying complex datasets while preserving their essential characteristics.
Linear Algebra basics
Understanding the basics of linear algebra is fundamental for anyone delving into data science. Here are some of the core concepts and components:
Scalars, Vectors, Matrices, and Tensors:
- Scalars:
A single number, often representing a magnitude or quantity in linear algebra for data science. - Vectors:
An ordered array of numbers, which can be thought of as points in space, with each element representing a coordinate in a certain dimension. - Matrices:
A two-dimensional array of numbers, where each element is identified by two indices instead of just one as in vectors. Matrices are used to represent linear transformations or relations between sets of vectors.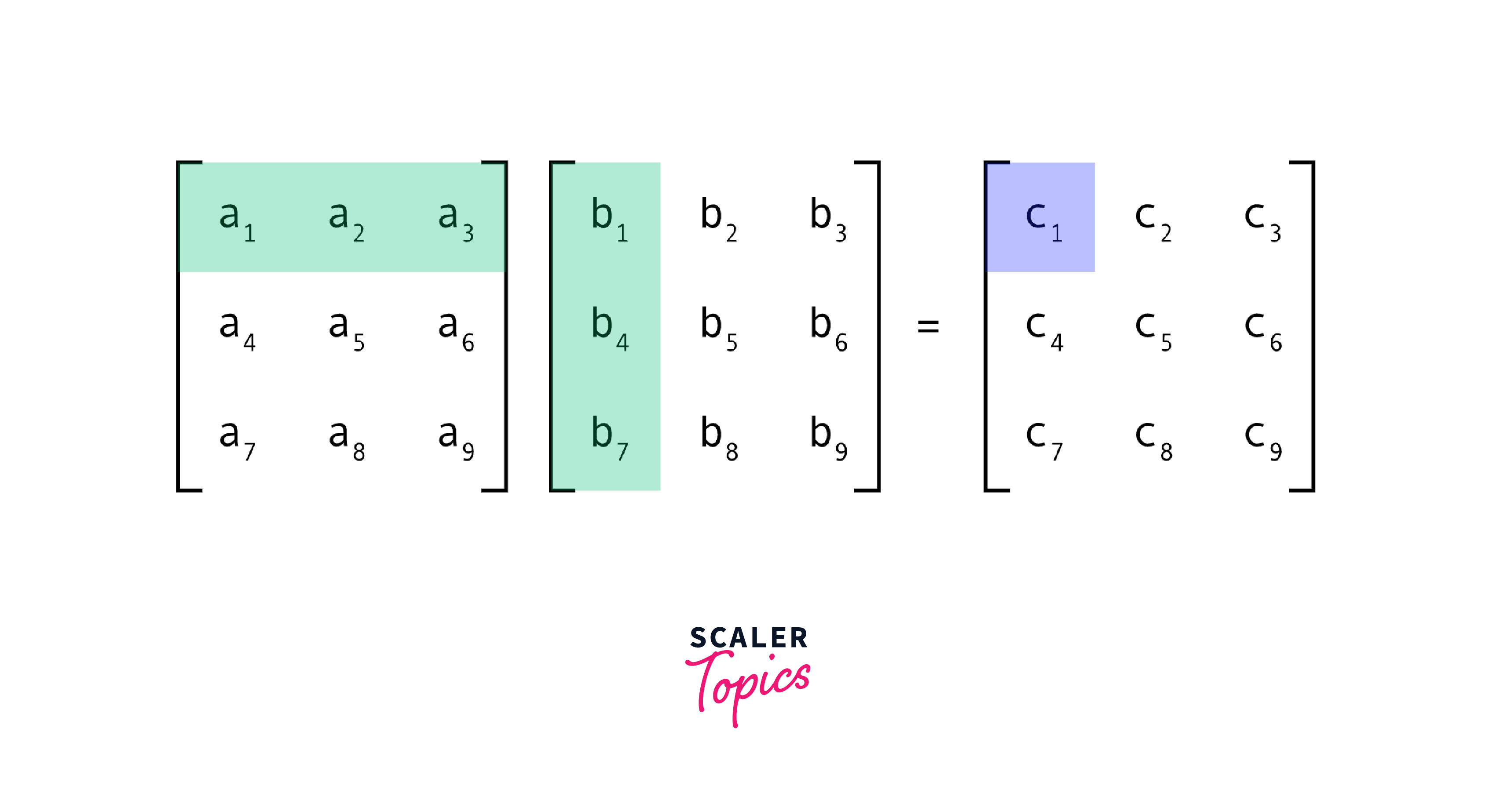
- Tensors:
A generalization of scalars, vectors, and matrices to an arbitrary number of dimensions, crucial for handling more complex data structures like images or multi-dimensional time series.
Operations:
- Addition and Subtraction:
Vector and matrix addition and subtraction are performed element-wise and require operands of the same dimensions. - Scalar Multiplication:
Multiplying a vector or matrix by a scalar value scales each element by that scalar. - Dot Product:
A key operation in linear algebra for data science, the dot product between two vectors measures their similarity and projects one vector in the direction of another. - Matrix Multiplication:
Combines two matrices to form a new matrix, reflecting compounded linear transformations. This operation is fundamental in many data science algorithms.
Use of matrix
Matrices are central to linear algebra for data science, serving a variety of purposes that enable the efficient processing and analysis of data. Here are some of the primary uses of matrices in data science:
- Data Representation:
Matrices are used to organize and store data in a structured format, with rows often representing individual data points and columns representing features or variables. This organization facilitates efficient bulk operations and analyses. - Linear Transformations:
Matrices are fundamental in representing linear transformations, which are operations applied to vectors that alter their magnitude and direction without changing the dimensionality of the space. These transformations are crucial in various data preprocessing steps, such as scaling and rotation. - Systems of Linear Equations:
Many data science problems can be formulated as systems of linear equations, which can be represented and solved using matrix operations. Solutions to these systems can reveal underlying patterns and relationships within the data. - Dimensionality Reduction:
Techniques such as Principal Component Analysis (PCA) and Singular Value Decomposition (SVD) use matrices to reduce the dimensionality of data. These methods transform the original data into a lower-dimensional space, making it easier to analyze while preserving most of the information. - Graphs and Networks:
In graph theory, which is often used in data science for modeling relationships and interactions, matrices such as adjacency matrices and incidence matrices represent graphs. These matrices are instrumental in analyzing network properties and implementing algorithms.
Eigen Values and Eigen Vectors
Eigenvalues and eigenvectors are fundamental concepts in linear algebra for data science, playing a crucial role in understanding and manipulating data transformations. Here's an overview of their importance and applications:
Eigenvalues
An eigenvalue is a scalar that represents the factor by which the magnitude of an eigenvector is scaled during a linear transformation represented by a matrix. In the context of linear algebra for data science, eigenvalues can provide insights into the properties of a matrix, such as its invertibility or stability of the system it represents. Eigenvalues are denoted typically by .
Eigenvectors
An eigenvector is a nonzero vector that changes at most by a scalar factor when that linear transformation is applied. This means that the direction of the eigenvector is invariant under the associated linear transformation, making eigenvectors crucial for understanding the fundamental directions of data spread or variance in a dataset. Eigenvectors are often normalized to have unit length for simplicity.
Applications in Data Science
- Principal Component Analysis (PCA):
PCA, a widely used technique for dimensionality reduction in data science, relies on eigenvalues and eigenvectors to identify the principal components of a dataset. The eigenvectors of the covariance matrix of the dataset, corresponding to the largest eigenvalues, represent the directions of maximum variance. - Spectral Clustering:
In spectral clustering, the eigenvectors of similarity matrices (like Laplacian matrices) are used to perform dimensionality reduction before clustering, enabling the identification of cluster structures in data that might not be linearly separable. - Graph Analysis:
In the analysis of graphs and networks, eigenvalues and eigenvectors of adjacency matrices or Laplacian matrices can reveal important properties about the graph, such as connectivity, the presence of communities, or the centrality of nodes.
Solving Matrix in Data Science Using Linear Algebra
In data science, solving problems often involves working with matrix equations, and linear algebra provides effective tools for this purpose. Specifically, two methods stand out:
Row Echelon Form
Row Echelon Form (REF) is a form of a matrix where all non-zero rows are above any rows of all zeros, and the leading coefficient (the first non-zero number from the left, also called the pivot) of a non-zero row is always to the right of the leading coefficient of the row above it. The process of transforming a matrix into REF is called Gaussian elimination, and it's a fundamental technique in linear algebra for solving systems of linear equations, among other applications.
The key steps in Gaussian elimination to achieve REF include:
- Swapping rows if necessary to ensure the pivot element is not zero.
- Scaling rows to make the pivot element 1 (if it's not already).
- Row addition to eliminate the elements below the pivot, ensuring zeros below each leading coefficient.
- Once a matrix is in REF, you can solve a system of linear equations by back-substitution if the system is consistent (i.e., it has at least one solution).
Inverse of a Matrix
To find the inverse of a matrix , denoted as is a matrix that, when multiplied with yields the identity matrix . The identity matrix is a square matrix with ones on the diagonal and zeros elsewhere. Not all matrices have inverses; a matrix must be square (same number of rows and columns) and non-singular (having a non-zero determinant) to have an inverse.
The inverse is particularly useful in solving systems of linear equations represented in matrix form . If exists, the solution can be found as .
Important Applications of Linear Algebra in Data Science
Linear algebra for data science finds application in numerous areas, significantly enhancing the analytical capabilities in the field:
- Machine Learning:
Linear algebra is foundational to the algorithms in machine learning, from simple linear regression to complex neural networks, facilitating computations and optimizations. - Image Processing:
Techniques like image scaling, rotation, and transformation rely on matrix operations, making linear algebra crucial in computer vision applications. - Natural Language Processing (NLP):
Vector space models, which represent text as vectors in high-dimensional spaces, leverage linear algebra to analyze and interpret language data. - Recommendation Systems:
Linear algebra algorithms help in building recommendation systems by processing user and item matrices to identify patterns and suggest relevant items to users. - Data Compression:
Techniques such as Singular Value Decomposition (SVD) and Principal Component Analysis (PCA) use linear algebra to reduce data dimensionality, facilitating data storage and transmission efficiency.
FAQs
Q. Why is linear algebra important in data science?
A. Linear algebra is essential in data science for efficient data representation, facilitating complex calculations, and forming the basis of many machine learning algorithms.
Q. How is linear algebra used in machine learning?
A. In machine learning, linear algebra is used for operations like training models, optimizing algorithms, and handling multidimensional data.
Q. Can linear algebra techniques help in big data analysis?
A. Yes, linear algebra techniques are crucial in big data analysis for handling large datasets and performing scalable computations.
Q. What role does linear algebra play in image processing?
A. Linear algebra plays a key role in image processing, particularly in tasks like image transformations, filtering, and feature extraction.
Conclusion
- Linear algebra forms the mathematical foundation for a wide range of data science algorithms, from basic analyses to advanced machine learning models.
- It provides efficient methods for representing and manipulating data, enabling the handling of large and complex datasets with ease.
- Techniques like dimensionality reduction, image processing, and natural language processing rely on linear algebra to extract meaningful insights from data.
- Linear algebra offers robust methods for solving various data science problems, including systems of equations and optimization challenges.