Threads vs Processes in Linux
Overview
This article explores threads in Linux, their internal structure, and its differences with the processes. Threads are lightweight execution units within a process that enable efficient and concurrent task execution.
We'll examine thread internals, including the stack and register set. We will also discuss the creation flow, process tree, and the system calls involved. Understanding the disparities between threads and processes allows us to optimize resource usage, enhance application performance, and design scalable systems. Brace yourself for an insightful exploration of Linux threads and their vital role in modern computing!
Introduction to linux thread
In the realm of Linux, threads play a significant role in enabling concurrent and efficient task execution. But what exactly are threads in Linux? Understanding threads in Linux, including their internal structure and distinctions from processes, is crucial for optimizing resource utilization and enhancing application performance.
In this article, we will explore the intricacies of threads in Linux, dive into their internals, and uncover the differences between Linux threads and processes. Let's embark on this journey to unravel the power and potential of Linux threads.
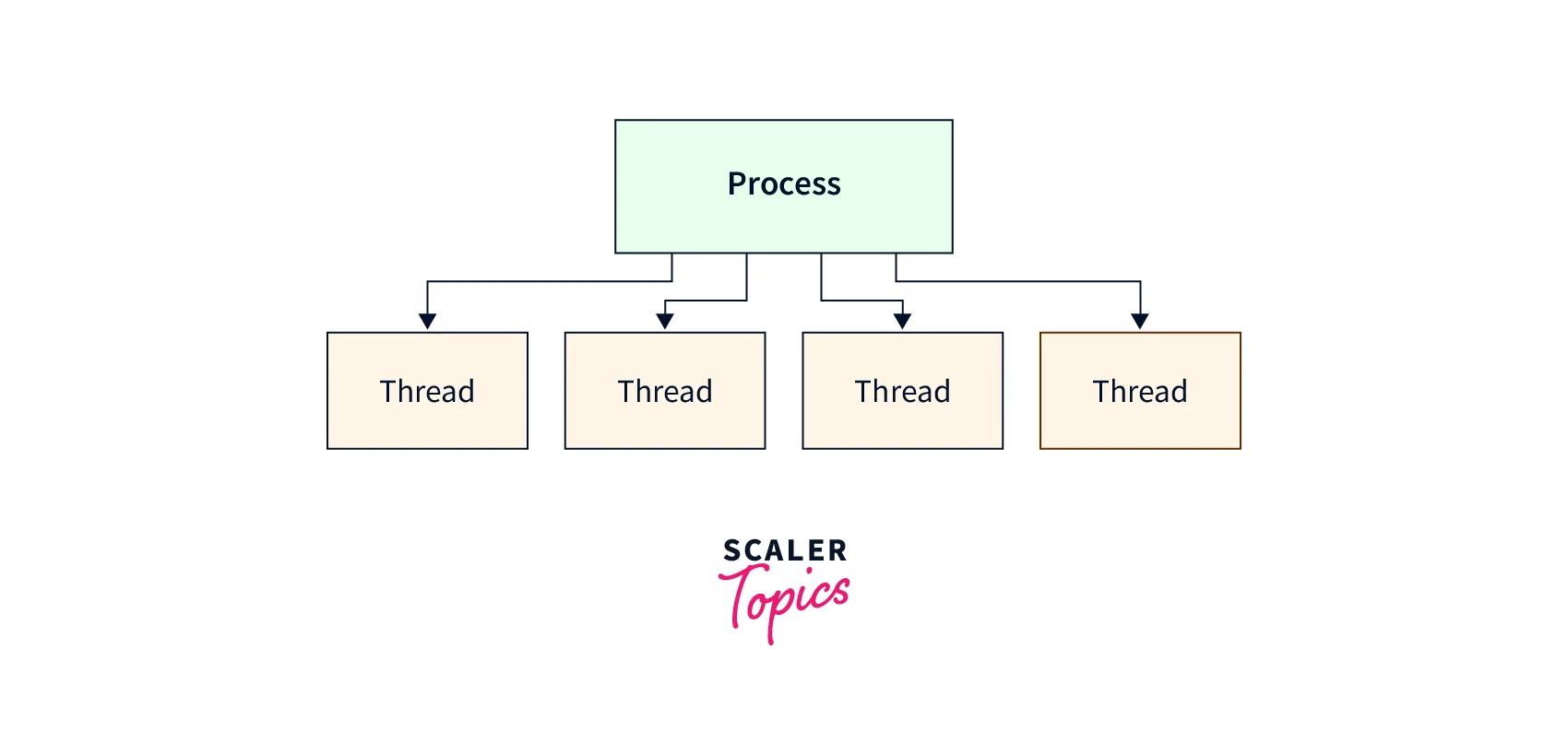
What is a Linux Thread
A Linux thread is a lightweight unit of execution within a process that can operate independently. It allows for concurrent execution of tasks, enabling parallel processing and efficient resource utilization. Threads share the same memory space and resources with other threads in the process, making data sharing and communication between threads seamless.
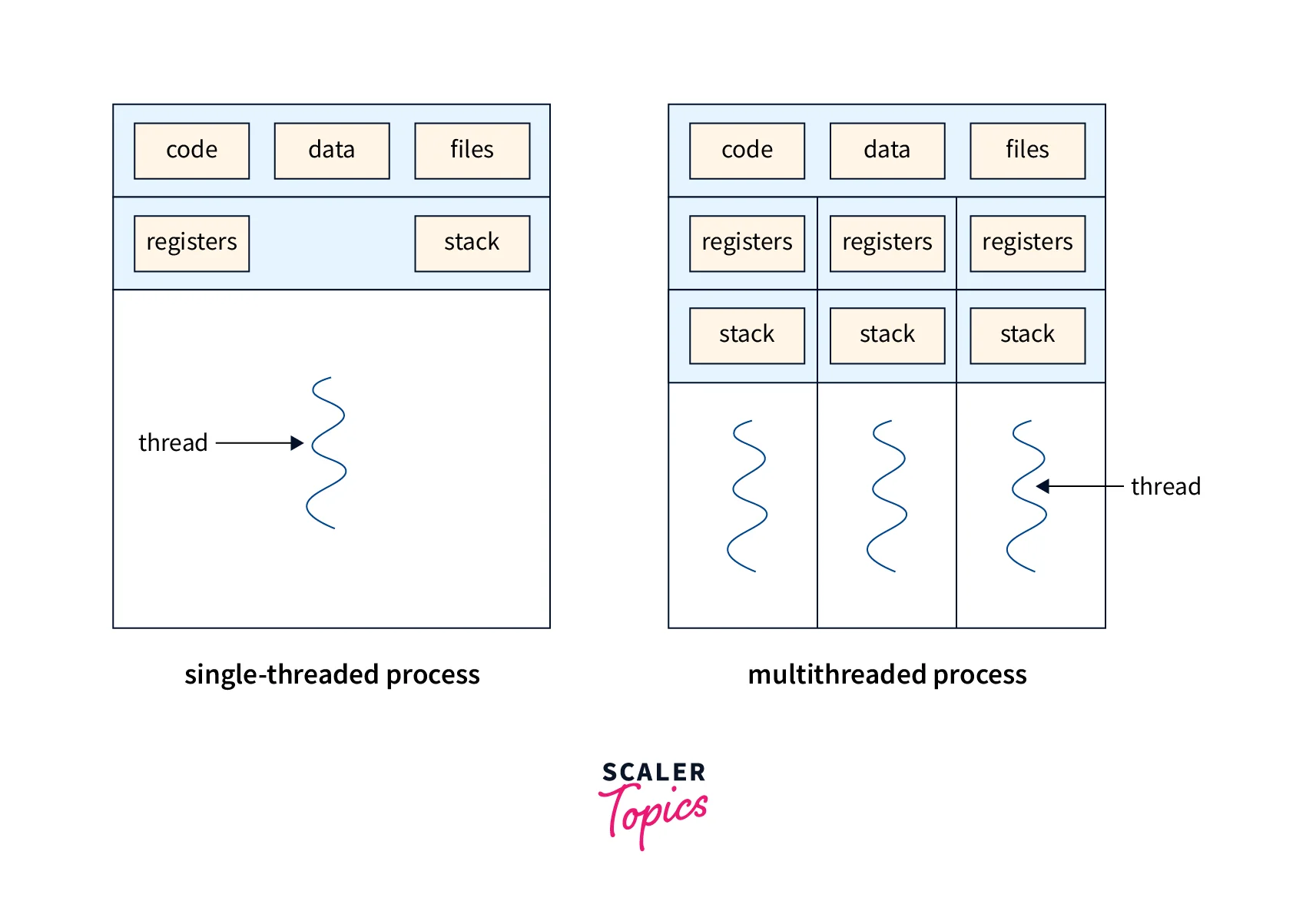
Internal Structure of Thread
The internal structure of a thread consists of three main components: the stack, register set and thread-specific data.
- Stack: The stack is a region of memory allocated for the thread's execution. It holds the thread's local variables, function calls, and return addresses. Each thread has its stack, allowing for independent execution.
- Register Set: The register set contains the thread's execution context, including the values of CPU registers. These registers store crucial information such as program counters, stack pointers, and other processor-specific registers.
- Thread-Specific Data: Thread-specific data allows each thread to maintain its unique state. It can include variables specific to the thread, such as thread ID or thread-specific storage.
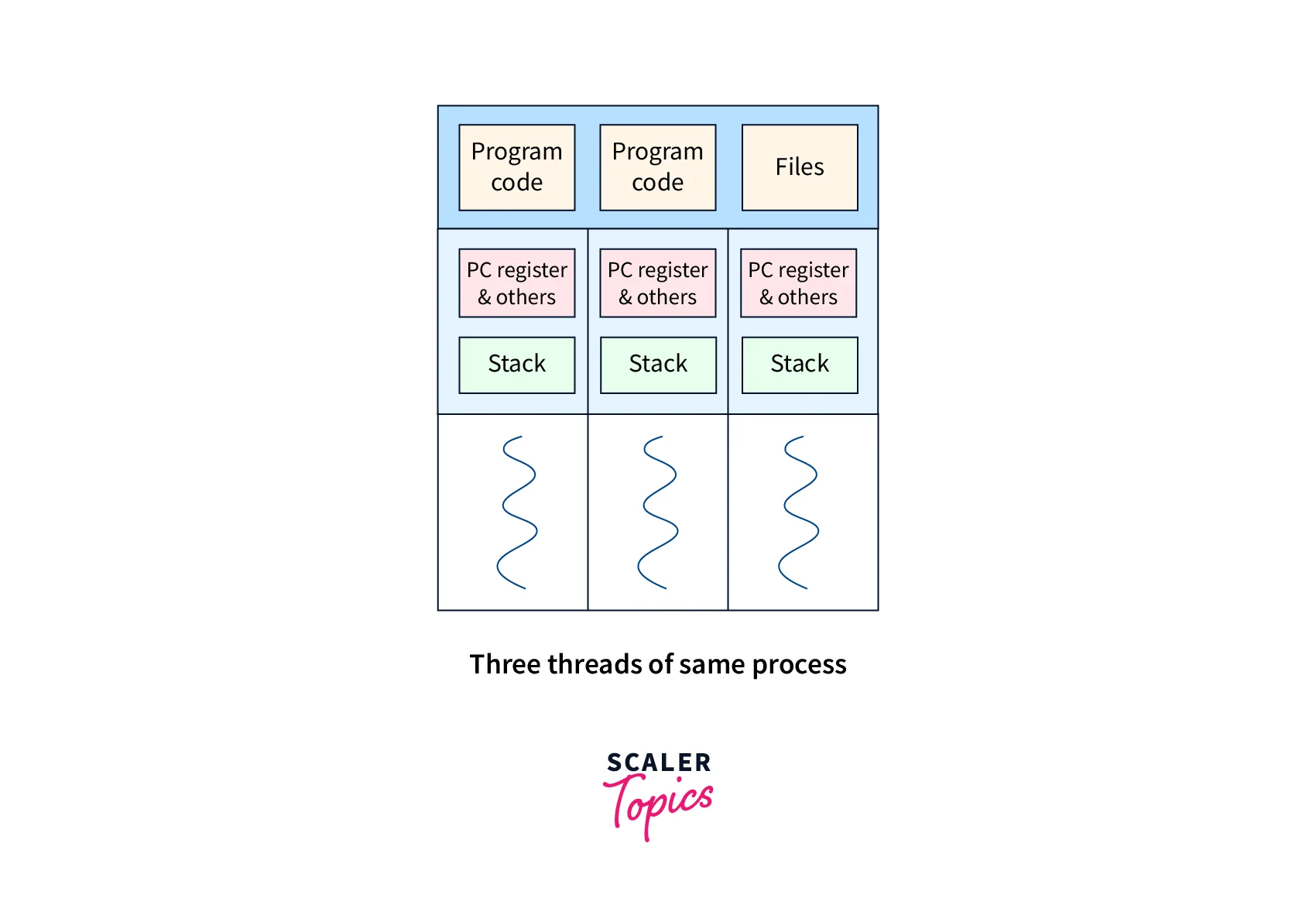
Understanding the internal structure of a thread is vital for effective thread management, synchronization, and communication in Linux systems.
What is a linux Process
A Linux process is an instance of a running program in the Linux operating system. It represents an independent unit of execution that operates within its own memory space and has its own set of system resources. Each process is assigned a unique Process ID (PID) that distinguishes it from other processes.
Processes in Linux play a crucial role in executing and managing tasks, allowing multiple programs to run concurrently and interact with the underlying system resources.
The System Calls Involved
System calls play a crucial role in creating and managing processes in Linux. They provide a way for programs to interact with the kernel and access operating system services. In the context of process management, use the following system calls:
- fork(): The fork() system call creates a new process by duplicating the existing parent process. After calling fork(), two identical processes, the parent and the child, are created. The child process inherits the memory space and resources of the parent process.
- exec(): The exec() system call replaces the current process with a new program. It loads the new program into the memory space of the existing process, replacing the current instructions and data. It allows for the execution of a different program within the same process.
- exit(): The exit() system call is used to terminate a process. It releases the allocated resources and notifies the parent process about its termination status.
- wait(): The wait() system call allows a parent process to wait for the termination of its child process. It retrieves the exit status of the child process, allowing the parent process to perform actions based on that status.
- kill(): The kill() system call sends a signal to a specific process or group of processes. Signals terminate a process, handle specific events, or request process actions.
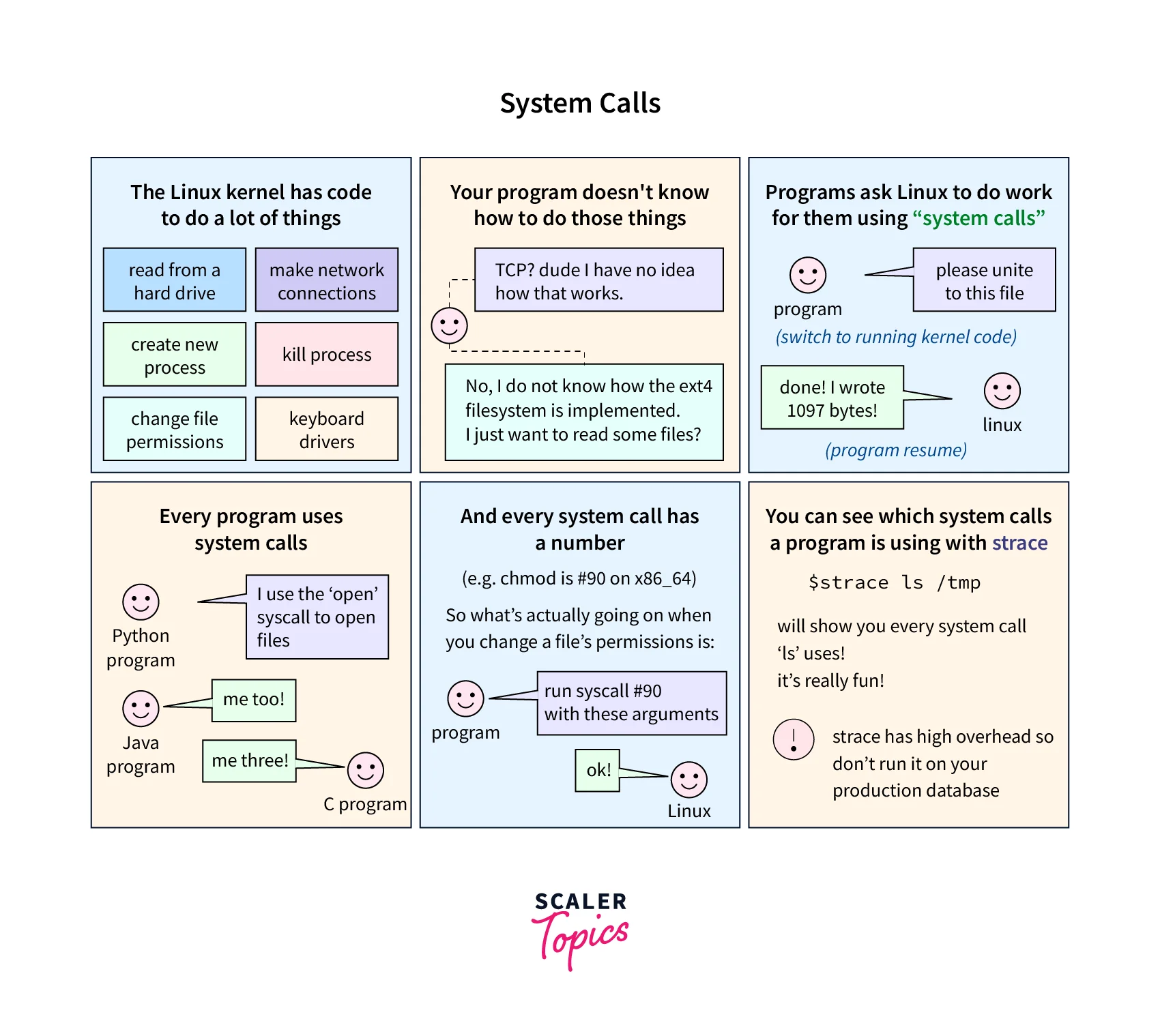
These system calls provide the necessary interfaces for process creation, termination, communication, and synchronization. They are essential for managing the lifecycle and behavior of processes in a Linux system.
Internal Structure of Process
In Linux, the internal structure of a process is managed by the Linux kernel through a data structure called task_struct. This structure, represented as a dynamic list called tasklist, holds information about all running processes in the system. The task_struct includes various fields that categorize the process's attributes and state, such as scheduling parameters, memory image, signals, machine registers, system calls state, file descriptors, and kernel stack.
When a new process is created, the Linux kernel allocates memory for a new task_struct in the kernel memory space. This newly created task_struct represents the process and contains the necessary information to manage and control its execution.
It is important to note that as Linux system users, we don't directly create or manage the internal data structure for processes. However, understanding the concept of task_struct and its role in representing Linux processes provides insight into the underlying mechanisms of process management in the Linux operating system.
The internal structure of a Linux process consists of several components that contribute to its functioning and behavior. These components include:
-
Process ID (PID): Each process is assigned a unique identifier called the Process ID (PID). It serves as a reference to distinguish one process from another. To check the PID of all the running processes execute the ps aux command.
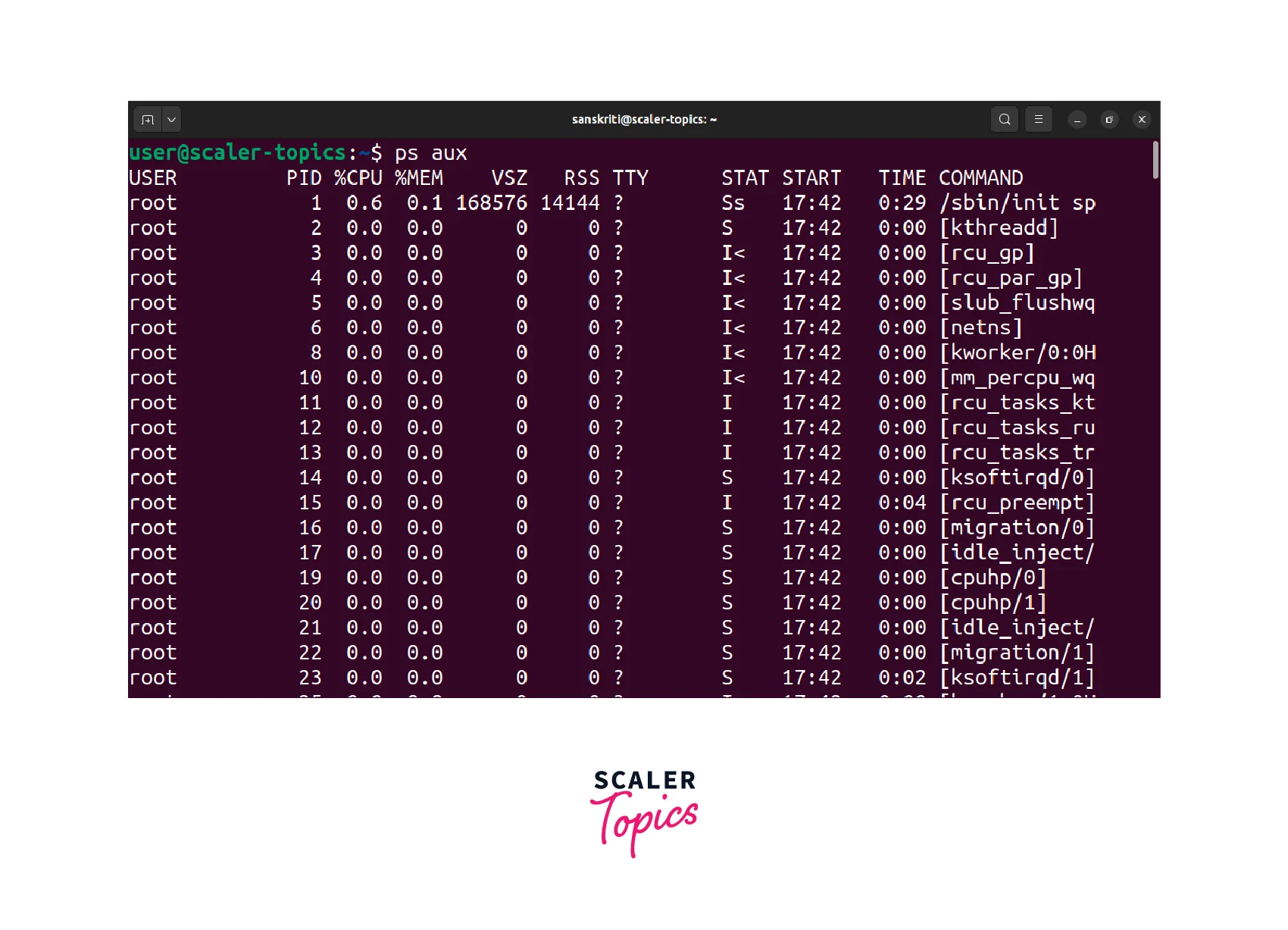
-
Memory Space: A process has its own memory space, which is divided into different segments. These segments include the code segment (text), data segment, and stack segment. The code segment contains the executable instructions of the program. The data segment stores global and static variables. The stack segment holds the function call stack and local variables.
-
Process State: The process state represents the current condition of a process. It can be one of the following states: running, waiting, sleeping, stopped, or terminated. The state of a process changes dynamically based on its execution and interactions with the system.
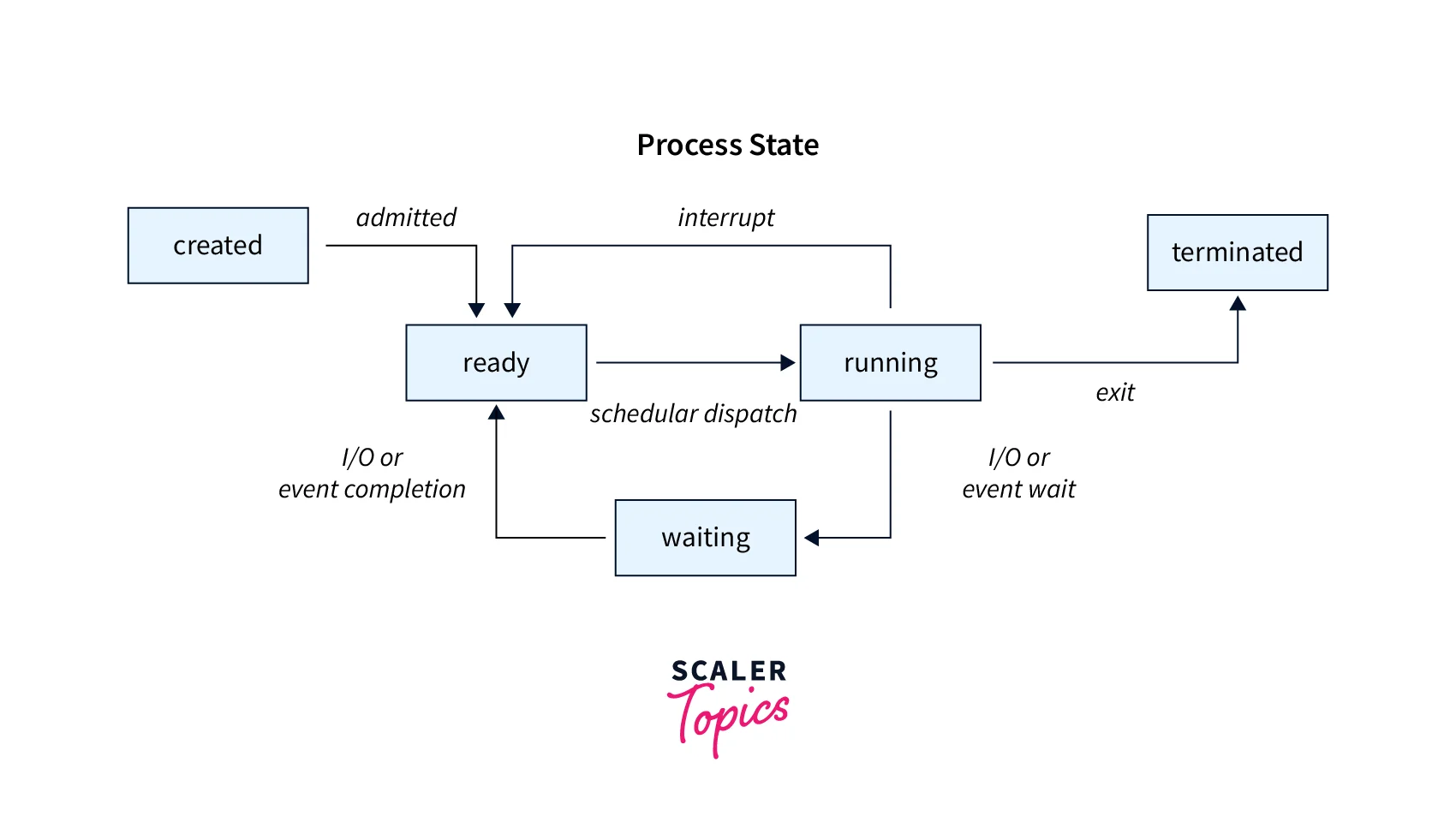
-
Process Priority: A priority value is assigned to each process, which determines its relative importance and scheduling preference. Higher-priority processes are given more CPU time compared to lower-priority ones. Execute the top command to see the priorities of processes.
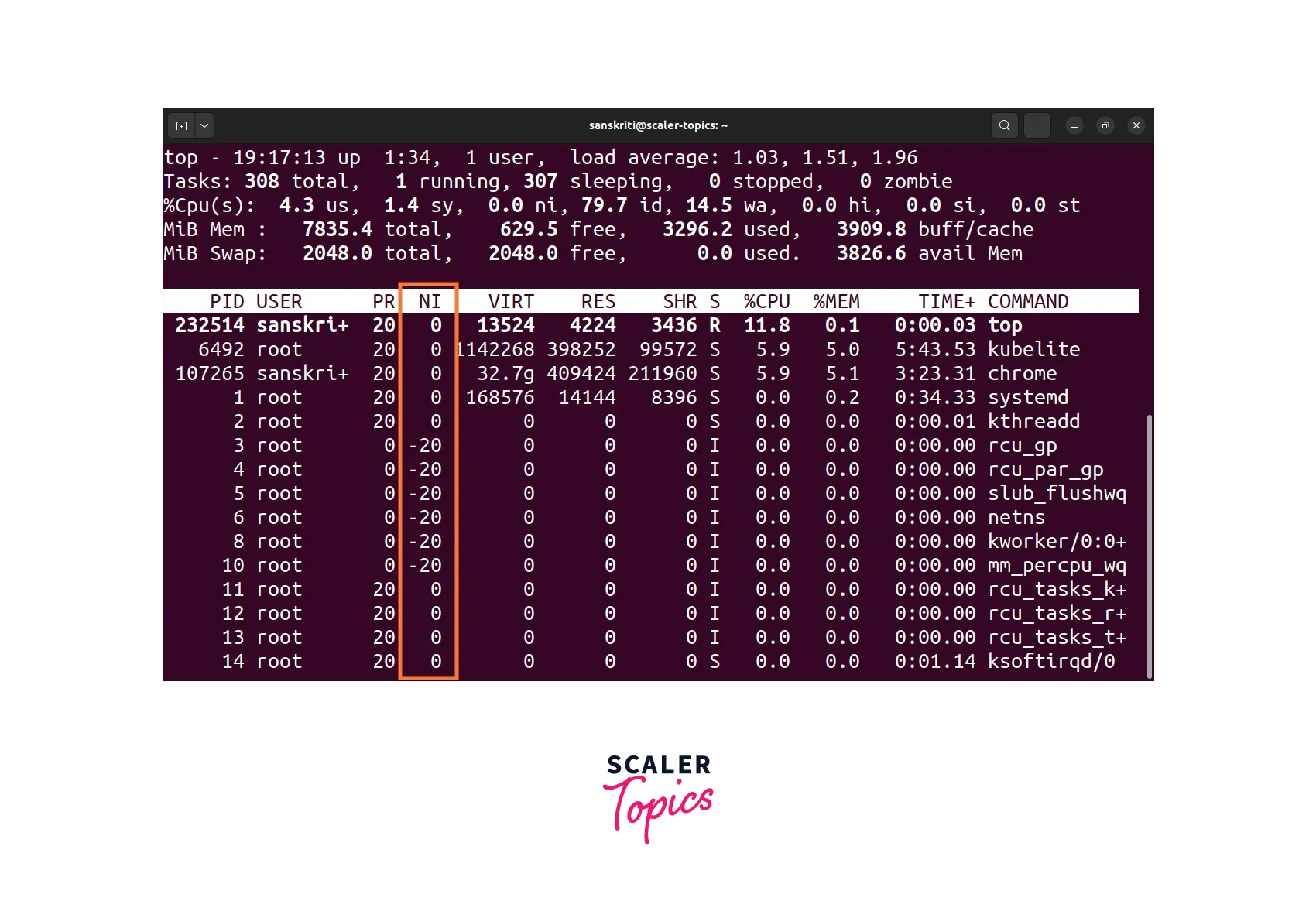
-
File Descriptors: Processes can access files and resources through file descriptors. A file descriptor is an integer representing an open file or a communication endpoint. It facilitates reading from or writing to files, network sockets, and other I/O operations.
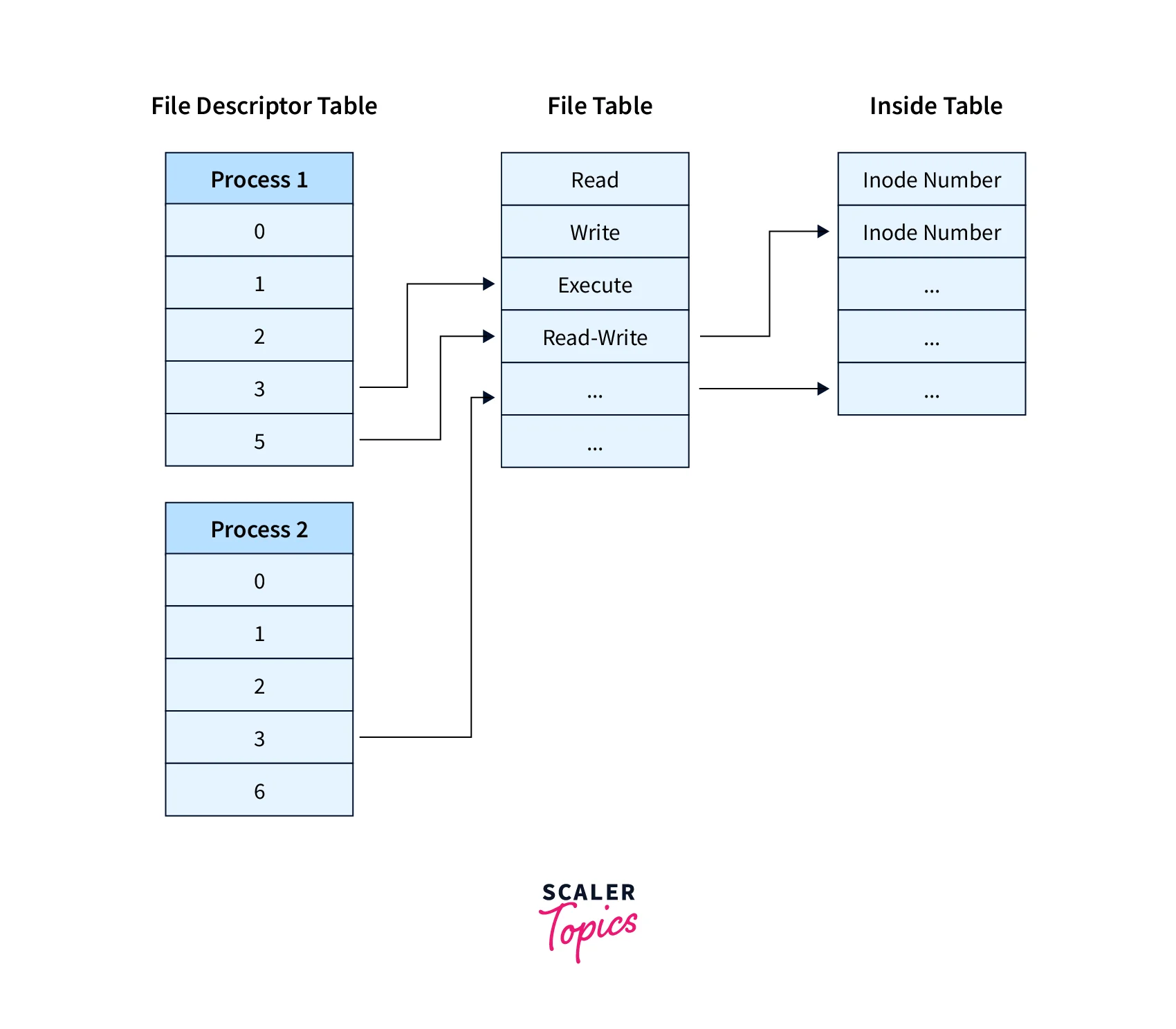
Understanding the internal structure of a process helps in managing and analyzing its behavior.
Creation Flow
The creation flow of a process in Linux involves several steps. Here is a brief overview of the process creation flow:
- Fork: The process creation typically starts with a fork system call. The fork system call creates a new process by duplicating the existing process (parent process). The new process is called the child process.
- Copy-on-Write: After the fork, the child process shares the same memory space as the parent process through a mechanism called copy-on-write. This means that initially, both processes share the same memory pages. If either process modifies a shared page, a separate copy of that page is created for the modifying process.
- Exec: Once the fork is complete, the child process can execute a different program using the exec system call. The exec system call replaces the memory space of the child process with the specified program's code and data.
- PID Assignment: Each process is assigned a unique process identifier (PID) by the kernel. The PID is used to identify and manage the process.
- Parent-Child Relationship: The parent process maintains a reference to its child process, allowing it to monitor and manage its execution. The parent can wait for the child to complete its execution using the wait system call.
- Process Termination: Processes can terminate voluntarily or due to an external event. When a process completes its execution or encounters an error, it can exit using the exit system call. The kernel then releases the allocated resources and notifies the parent process.
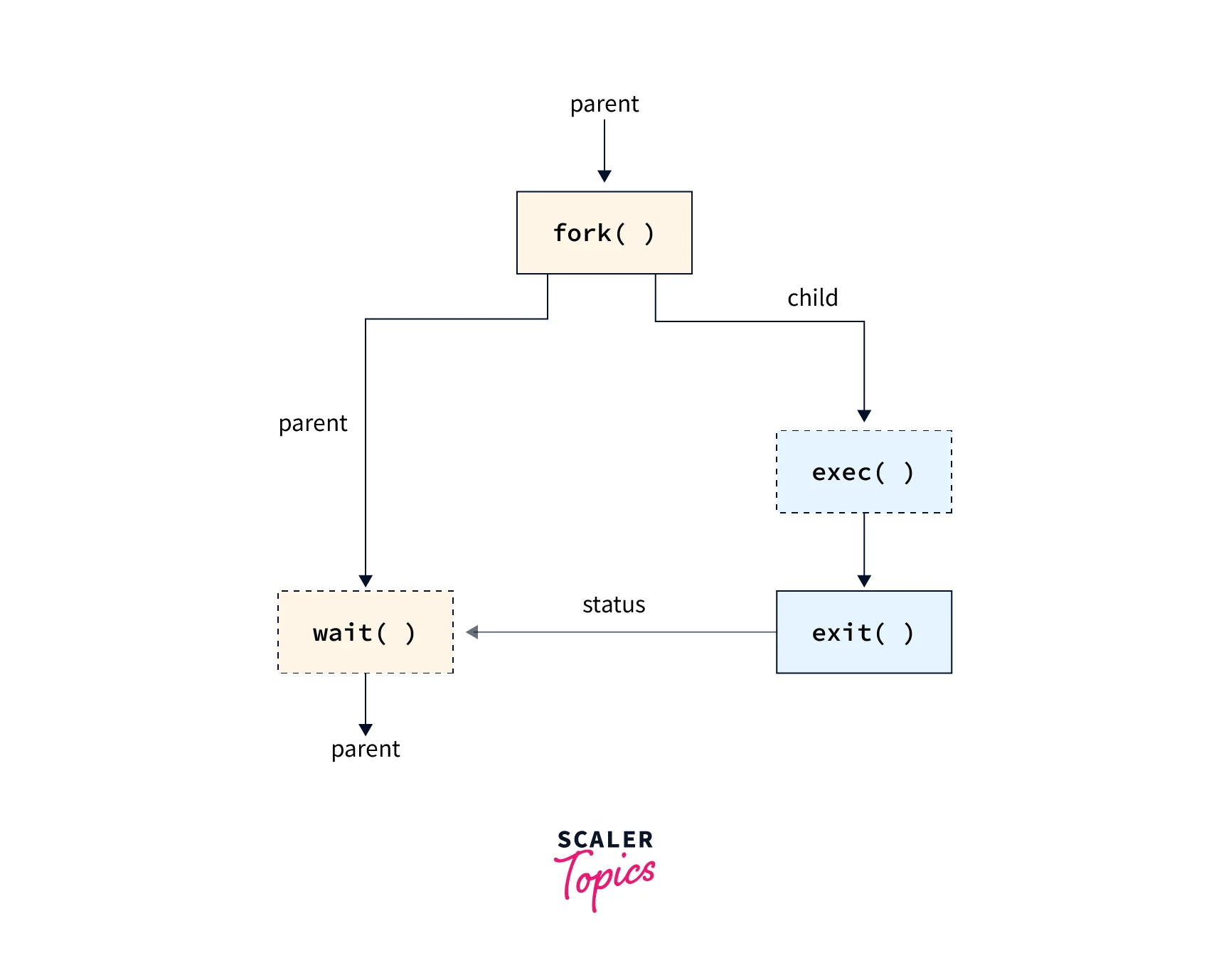
This is a simplified overview of the process creation flow in Linux. The actual implementation may involve additional steps and considerations, such as resource allocation, signal handling, and process scheduling.
The Process Tree
In Linux, processes are organized in a hierarchical structure known as the process tree. The process tree represents the relationships between parent and child processes, forming a tree-like structure. Here are the key characteristics of the process tree:
- Root Process: The process tree begins with a root process, which is typically the first process created during system boot, known as init or systemd.
- Parent-Child Relationship: Each process, except for the root process, has a parent process from which it was created. The process that initiates the creation of a new process is referred to as the parent process, while the newly created process is called the child process.
- Process Groups: Processes with a common ancestor, known as a session leader, form a process group. Process groups are useful for managing sets of related processes and controlling their behavior collectively.
- Terminal Process: In a terminal session, the process group leader is called the terminal process. It manages the input and output for the associated terminal, allowing for interactive communication with the user.
- Process IDs (PIDs): Each process in the tree has a unique Process ID (PID) assigned to it, enabling identification and communication between processes.
- Signals: Processes can send signals to other processes within the process tree. Signals are used for inter-process communication, allowing processes to notify, interrupt, or terminate other processes.
The process tree reflects the hierarchical structure of process creation and provides a way to organize and manage processes in the Linux system. It facilitates process coordination, resource sharing, and efficient process management.
Differences between a Process and a Thread
In this section, we will explore the differences between a process and a thread in Linux. Understanding these differences is crucial for effectively utilizing the benefits of threads in Linux and designing efficient and scalable systems. Let's delve into the dissimilarities between processes and threads and gain a clear understanding.
| Parameter | Process | Thread |
|---|---|---|
| Execution Unit | Independent entity that can run concurrently | Lightweight unit within a process |
| Resource Usage | Has its own memory space and system resources | Shares memory space and resources with other threads |
| Creation | Created using the fork() system call | Created using the pthread_create() system call |
| Communication | Requires inter-process communication mechanisms | Enables easy sharing of data within the same process |
| Scheduling | Managed by the kernel using process scheduling | Scheduled within the context of the parent process |
| Context Switch | Involves a higher overhead due to separate processes | Involves a lower overhead due to shared resources |
| Dependency | Can have dependencies on other processes | Relies on the existence of the parent process |
| Fault Isolation | Provides strong isolation and fault tolerance | Lack of isolation, failure of one thread affects others |
Remember that processes offer stronger isolation and fault tolerance, while threads provide lower overhead and efficient data sharing. Consider the trade-offs and choose the most suitable option for your application's performance, scalability, and resource utilization needs.
Conclusion
In conclusion, this article has provided an overview of threads in Linux, their internal structure, and their distinctions from processes. By understanding the key concepts and features of Linux threads, we can leverage their advantages for the efficient and concurrent execution of tasks. Let's recap the key takeaways:
- Threads in Linux are lightweight processes that can execute independently within a process.
- The internal structure of a thread includes a stack, register set, and thread-specific data.
- Linux processes are created using the fork() system call and have their own memory space.
- The creation flow of a process involves duplicating the parent process and modifying specific attributes.
- The process tree in Linux represents the hierarchy and relationships between parent and child processes.
- Threads share the same memory space with other threads in a process, enabling efficient data sharing.
- The differences between a process and a thread lie in their memory management and execution context.
By mastering the concepts of threads in Linux, developers and system administrators can optimize resource utilization, enhance application performance, and design scalable systems.