Introduction to Meta AI’s LLaMA
Overview
Meta's LLaMA, a language model that aims to revolutionize the field of artificial intelligence. LLaMA is a quartet of different-sized models released by Meta under a noncommercial license for research use cases. This blog highlights LLaMA's performance in various benchmarks, including common sense reasoning, trivia, reading comprehension, question answering, mathematical reasoning, code generation, and general domain knowledge.
What is LLaMA?
LLaMA, which stands for Large Language Model, Meta AI, is a language model developed by Meta AI, the parent company of Facebook. It is specifically optimized for assistant-like chat use cases and is capable of generating human-like text. Meta's LLaMA is a powerful generative text model that can be utilized for various natural language processing tasks.

Features of LLaMA:
- LLaMA is designed to generate human-like text and is optimized for assistant-like chat use cases.
- It is a powerful generative text model that can be used for a variety of natural language processing tasks.
- LLaMA has multiple versions, with the latest being LLaMA 2.
- LLaMA 2 is an open-source large language model freely available for research and commercial use.
- LLaMA 2 is designed to enable developers and organizations to build generative AI-powered tools and experiences.
- It has been fine-tuned on a large amount of data and has billions of parameters, allowing it to generate high-quality and contextually relevant text.
To learn more about Meta's LLaMA, you can visit the official website.
How Does Meta's LLaMA Work?
LLaMA from Meta is a powerful language model which is built on the transformer architecture and operates as an auto-regressive language model. LLaMA works by taking a sequence of words as input and recursively generating the next word to generate coherent and contextually relevant text.
One of the distinguishing features of LLaMA is its training on a publicly available wide array of text data in multiple languages, including Bulgarian, Catalan, Czech, Danish, German, English, Spanish, French, Croatian, Hungarian, Italian, Dutch, Polish, Portuguese, Romanian, Russian, Slovenian, Serbian, Swedish, and Ukrainian.
LLaMA models are available in different sizes, including 7B, 13B, 33B, and 65B parameters. They can be accessed through the Hugging Face library or the official repository on GitHub facebookresearch/llama
The LLaMA models have gained significant attention and interest from the AI research community due to their impressive performance and potential for various natural language processing tasks.
It's worth noting that LLaMA models have been made available for research and commercial use, and their weights were leaked and made accessible through unauthorized means, prompting further exploration and utilization by the developer community.
Getting Started with LLaMA Models
To get started with LLaMA models using Hugging Face. The ctransformers library provides an interface to work with various language models, including LLaMA. It simplifies the process of loading, configuring, and using these models. In this case, the LLaMA model is quite large with 2.7 billion parameters, and ctransformers allows you to use it efficiently in a Colab environment.
Let's break down the implementation step by step and explain the relevant components:
Step 1: Installing ctransformers The first line of code is used to install the ctransformers library. This library provides an interface for working with various language models, including LLaMA.
Step 2: Defining the model_id The model_id variable is set to TheBloke/Llama-2-7B-GGML. This specific model represents the LLaMA model with 2.7 billion parameters.
Step 3: Importing AutoModelForCausalLM The AutoModelForCausalLM class is imported from the ctransformers library. This class is used to load and interact with the LLaMA model.
Step 4: Configuring the Model The config dictionary holds various configuration parameters for the LLaMA model. In this example, the parameters max_new_tokens, repetition_penalty, temperature, and stream are set. These parameters control aspects like the maximum number of tokens generated, repetition penalty, temperature for randomness, and streaming mode.
Step 5: Initializing the LLaMA model The AutoModelForCausalLM.from_pretrained() method is used to initialize the LLaMA model. It takes the model_id as the first argument and sets the model_type as "llama". Additional parameters like gpu_layers (number of layers to be used on the GPU) and the config dictionary are also passed.
Step 6: Setting the Prompt The prompt variable is set to a specific text, in this case, a prompt to generate seven wonders of the World.
Step 7: Generation Finally, the LLaMA model is used to generate by calling llm(prompt, stream=False). This generates text based on the provided prompt using the LLaMA model.
Output
How Does LLaMA Differ From Other AI Models?
LLaMA (Large Language Model, Meta AI) stands out from other AI models in several ways:
| LLaMA | Other AI Models | |
|---|---|---|
| Availability | Available for research and non-commercial use | Varies (Some models are proprietary or restricted) |
| Model Size | 65 billion parameters | Varies (Some models may have fewer or more parameters) |
| Benchmark | Comprehensive evaluations and comparisons | Varies (Performance may differ across different models) |
| Research Focus | Designed to support AI research efforts | Varies (Some models may have specific applications) |
| Fine-tuning | Available for LLaMA 2 models | Varies (Some models may have fine-tuning capabilities) |
| Safety Measures | Considered in supervised fine-tuning of LLaMA 2 models | Varies (Safety measures may differ across models) |
Please note that the above comparison is a general overview and may not capture all the specific details of each AI model. The availability, features, and performance of AI models can vary significantly depending on the specific implementation and updates made by the developers.
Challenges and Limitations of LLaMA
LLaMA, like other AI models, also faces certain challenges and limitations. Some of these include:
-
Ethical Considerations: As LLaMA and similar AI models become more powerful and influential, ethical considerations come to the forefront. Concerns about privacy, data security, and algorithmic biases raise questions about the responsible deployment of such models. Transparent documentation of model behaviour, fair representation in training data, and addressing societal implications are imperative for using LLaMA responsibly.
-
Interpretability vs. Complexity: LLaMA's deep neural network architecture poses challenges in terms of interpretability. Deep learning models, in general, are often regarded as black boxes due to their intricate decision-making processes. The difficulty in interpreting LLaMA's predictions can limit its adoption in critical applications where transparency and accountability are paramount.
-
Contextual Limitations and Niche Tasks: LLaMA, like other language models, may have limitations in understanding and generating context-specific or niche domain knowledge. While LLaMA is a powerful model, there might be specific tasks or highly specialized domains where its performance may not be optimal.
It is important to consider these challenges and limitations when working with LLaMA or any other AI model to ensure responsible and effective use.
Other Models from Meta AI
There are a few examples of models from Meta AI, each with its architecture, working principles, and applications. These models contribute to various areas of NLP, ranging from text generation and chatbot development to machine translation and benchmarking.
BART (Bidirectional and Auto-Regressive Transformers)
BART, developed by Facebook AI, is a sequence-to-sequence model that combines the strengths of bidirectional and autoregressive transformers. It consists of an encoder-decoder architecture where both the encoder and decoder are transformer models. BART utilizes a masked language model (MLM) objective during pre-training, similar to BERT, to learn bidirectional representations. During fine-tuning, BART can be used for various tasks such as text generation, summarization, and text classification.
BART is trained using a combination of denoising and autoregressive objectives. In the denoising objective, corrupted input is generated by randomly masking tokens and replacing them with noise, and the model is trained to reconstruct the original input. In the autoregressive objective, the model generates the target sequence autoregressively, predicting each token conditioned on the previously generated tokens. BART leverages both objectives to learn powerful representations that can be fine-tuned for specific downstream tasks.
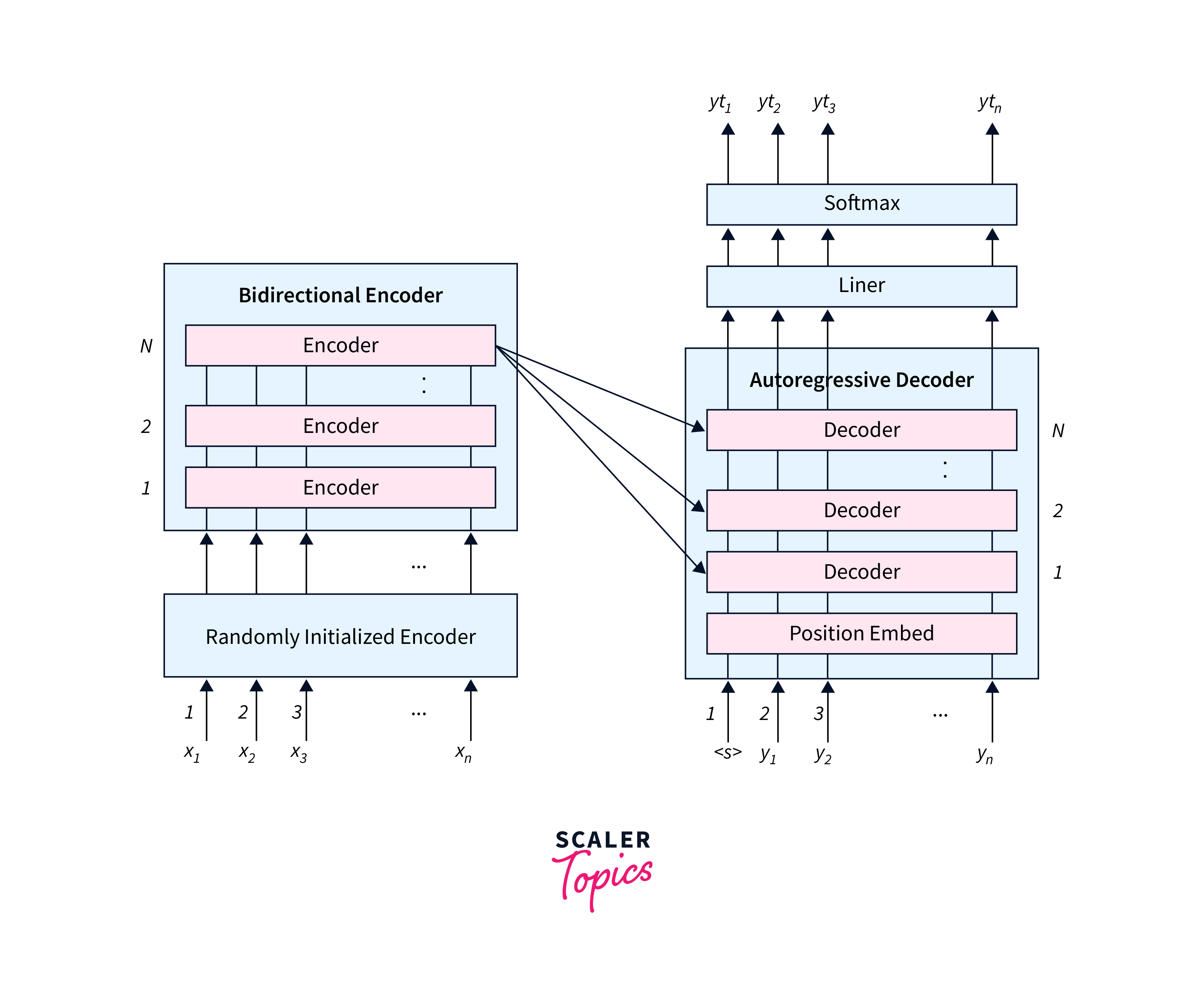
BART has been successfully applied to various natural language processing (NLP) tasks. It has shown promise in abstractive text summarization, document classification, machine translation, and text generation tasks. BART's bidirectional nature allows it to capture contextual information from both directions, making it particularly effective for tasks that require an understanding of global context.
Blender: Open-Domain Chatbot
Blender is an open-domain chatbot developed by Facebook AI. It employs a sequence-to-sequence architecture with a transformer-based encoder-decoder model. The encoder processes the input message, while the decoder generates the response. Blender is trained using a combination of supervised fine-tuning and reinforcement learning from human feedback.
Blender is trained using a two-step process. First, it is fine-tuned using supervised training, where human AI trainers engage in conversations and provide responses. The dataset is collected and used to train the initial model. Next, reinforcement learning from human feedback is employed to improve the model's responses. AI trainers rank different model-generated responses, and the model is fine-tuned using these rankings to optimize its performance.
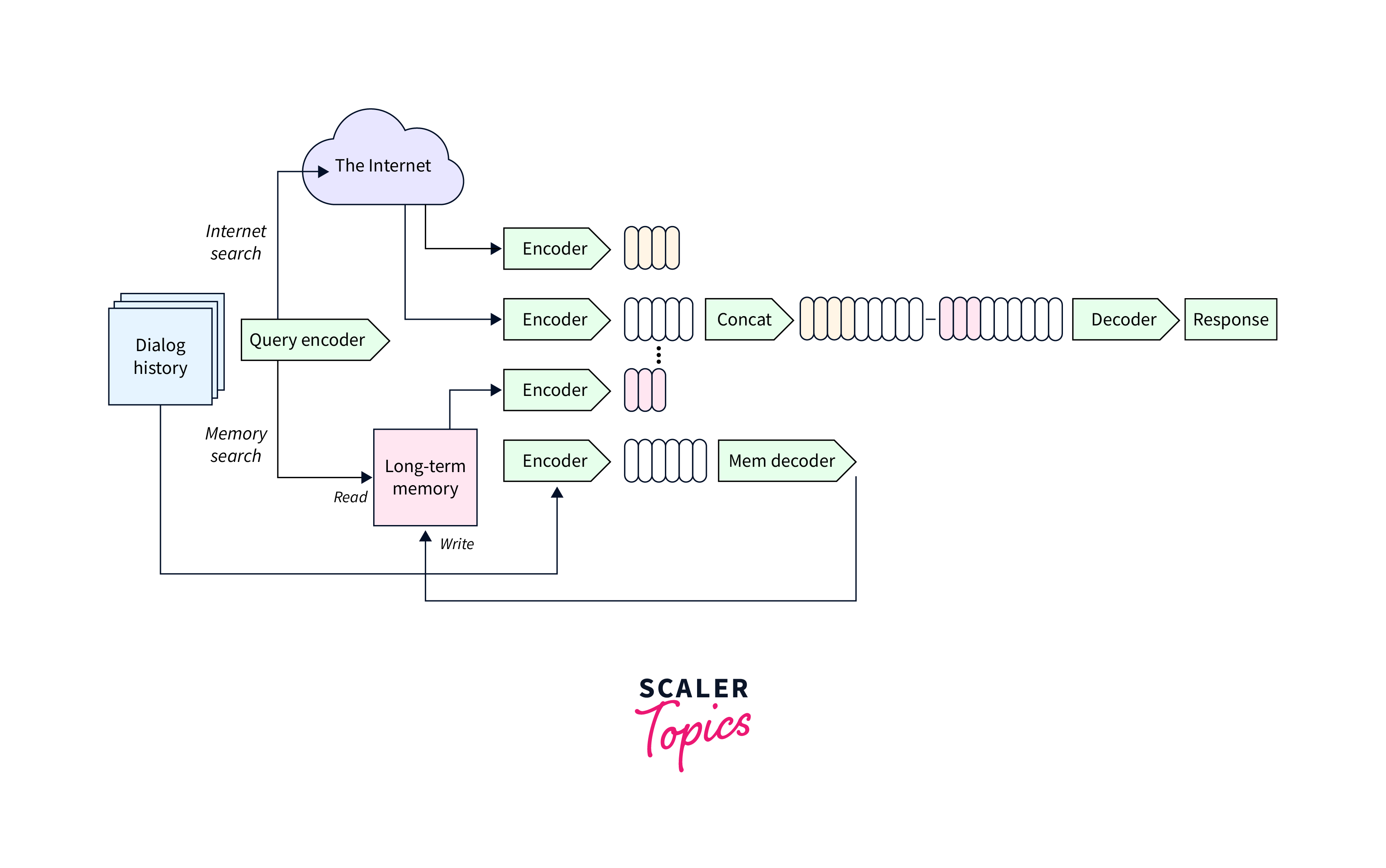
Blender is designed to engage in open-domain conversations and has been trained on a large dataset of conversations from various sources. It can be used as a chatbot in applications such as customer support, virtual assistants, and social chat platforms. Blender aims to generate more engaging and coherent responses by leveraging both supervised fine-tuning and reinforcement learning.
Dynabench: Rethinking Benchmarking in NLP
Dynabench is not an AI model itself but a framework for rethinking benchmarking in NLP. It addresses the limitations of static benchmarks by providing a dynamic and interactive platform for evaluating and benchmarking NLP models. Dynabench allows the creation of new tasks, adapts to changing data distributions, and incorporates continuous human evaluation.
Dynabench facilitates a collaborative approach to benchmarking in NLP. It allows researchers to propose new tasks and data collection protocols that are evaluated through continuous human evaluation. The platform ensures that benchmark tasks remain relevant and adapt to emerging challenges in the field. It encourages the involvement of human annotators for evaluation and provides mechanisms for continuous improvement of benchmark tasks.
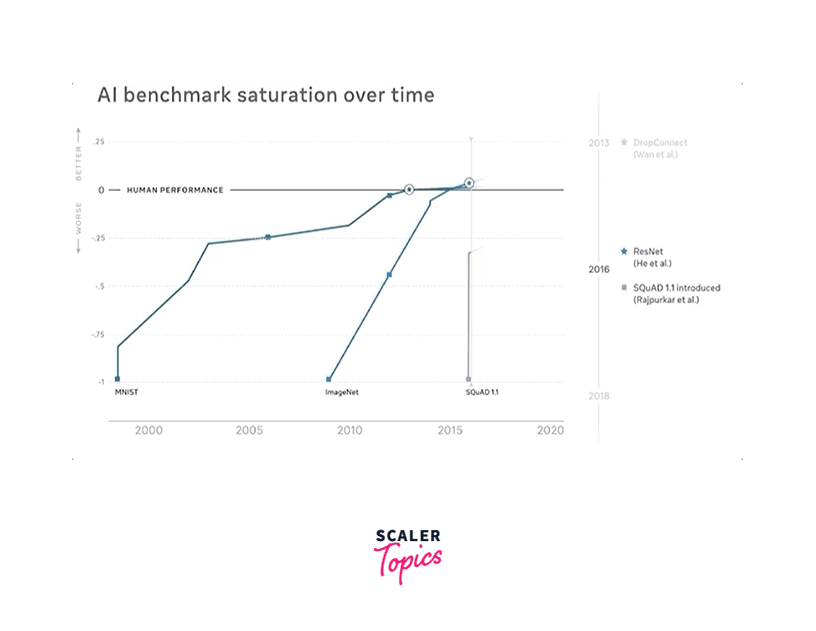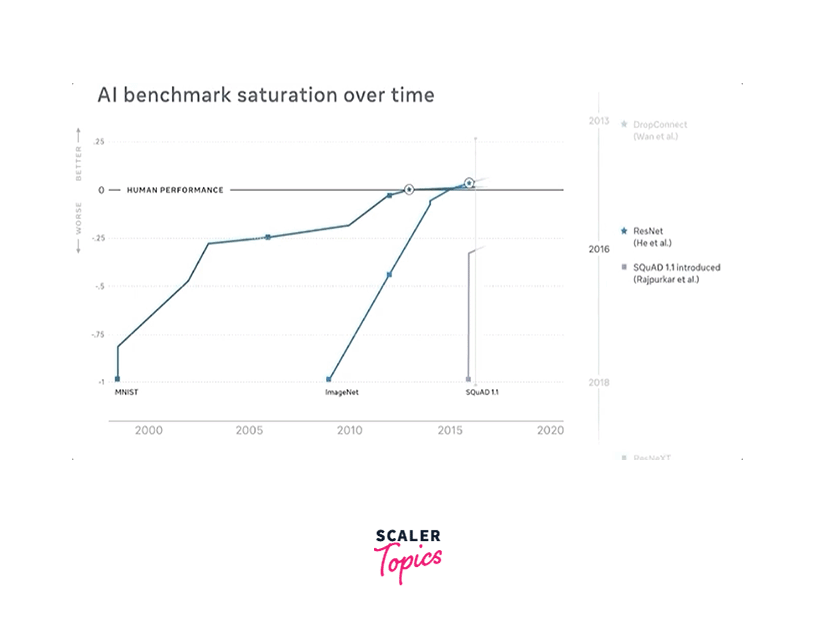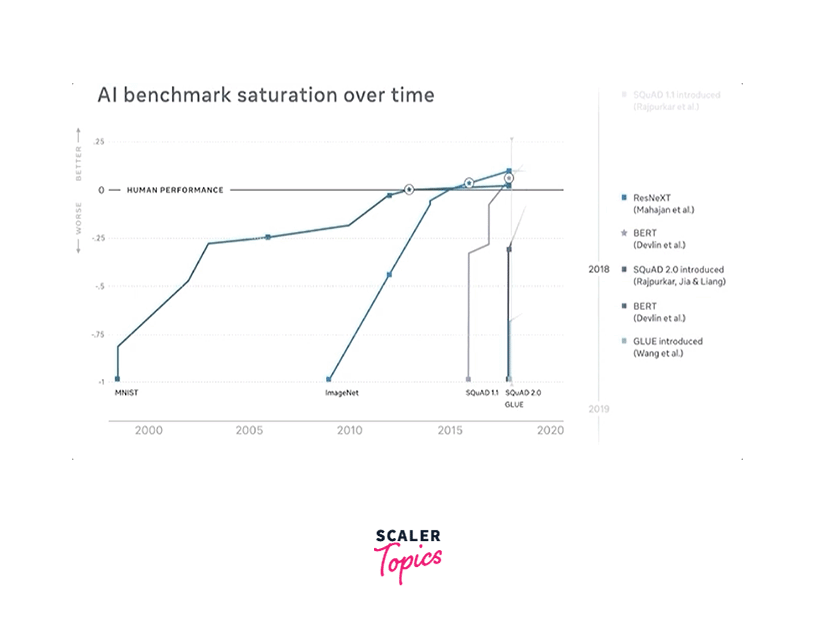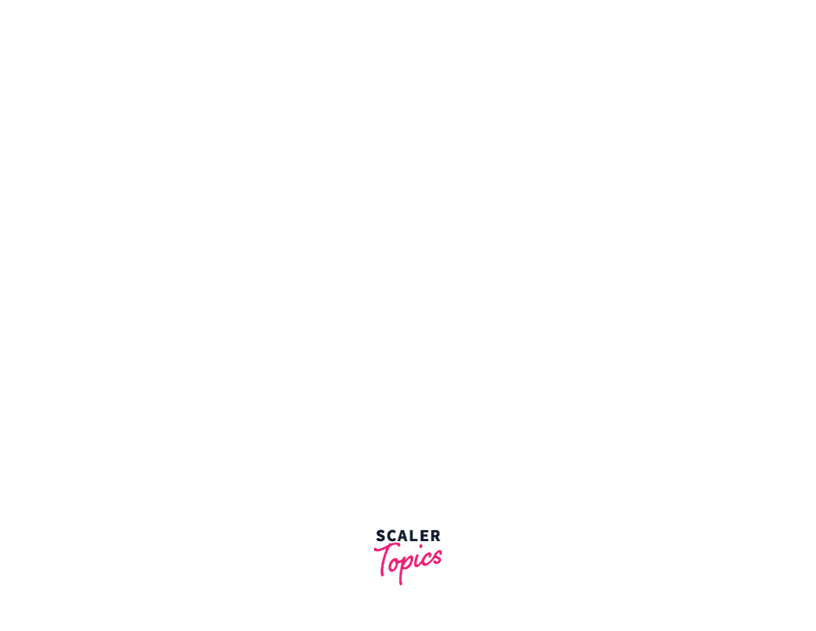
Dynabench provides a framework to create and evaluate NLP benchmarks effectively. It enables researchers to design tasks that align with real-world requirements and challenges. By incorporating continuous human evaluation, Dynabench encourages the development of models that better address human needs and preferences.
M2M-100: Multilingual Machine Translation Model
M2M-100 is a multilingual machine translation model developed by Facebook AI. It is designed to translate between 100 different languages without relying on English as an intermediate language. It employs a transformer-based architecture, similar to other state-of-the-art machine translation models.
M2M-100 is trained using a massive multilingual dataset, consisting of parallel sentences in various languages. The model learns to map the input sentence in one language to the output sentence in another language. M2M-100 is trained in a supervised manner using parallel corpora and employs transformers to capture contextual information and generate accurate translations.
M2M-100 is a versatile model that can be used for multilingual machine translation tasks. Its ability to translate between 100 languages directly allows for more efficient and accurate translations without relying on English as an intermediate language. This makes it particularly useful for languages that have limited resources and translation capabilities.
Applications and Current Developments in Meta AI's LLaMA
Meta's LLaMA has gained attention and seen developments in various applications. Here are some notable applications and current developments:
-
On-device AI Applications with Qualcomm: Meta has partnered with Qualcomm to enable on-device AI applications powered by Snapdragon chips. This collaboration allows AI experiences to work even in areas with no connectivity or in airplane mode, providing improved privacy and cost-efficiency for developers and users.
-
Generative AI and LLaMA-Adapter: Meta's LLaMA has advanced generative AI research and accelerated the frontier of Open Source (OSS) LLMs. With high-quality instruction-following and chat data, LLaMA can be fine-tuned to behave like ChatGPT. LLaMA-Adapter and QLoRA have introduced parameter-efficient fine-tuning methods, enabling cost-effective fine-tuning of LLaMA models on consumer GPUs.
-
Improved Models and Features: Meta's LLaMA continues to enhance its models and features. Updates to PaLM (Pattern and Language Model) include higher quality outputs, a larger 32,000-token context window for analyzing larger documents, and grounding capabilities for enterprise data. Codey, the model for code generation and chat, offers better performance, and Imagen, the model for image generation, features improved image quality and a new digital watermarking functionality.
-
LLaMA 2 and Claude 2 in Model Garden: Meta's Model Garden offers over 100 large models, including LLaMA 2 and Claude 2. These models provide researchers and developers with a wide range of AI capabilities and options for their projects.
-
Open-Source and Collaboration: Meta's decision to open-source LLaMA reflects its belief in an open approach to AI development. By making the code accessible, Meta encourages collaboration within the AI community to improve tools and address vulnerabilities. This collaborative approach aims to support responsible and safer AI development.
Conclusion
- LLaMA is a powerful language model developed by Meta AI for research purposes.
- It offers significant advancements in various natural language processing tasks and has shown promising performance compared to other state-of-the-art language models.
- LLaMA models are not intended for direct interaction but serve as a valuable tool for researchers and experts in the field.
- By sharing LLaMA under a noncommercial license, Meta AI hopes to foster innovation, collaboration, and responsible use of AI language models in diverse research domains.