Machine Learning in Big Data
Overview
Machine Learning in Big Data is an interesting and quickly expanding area that has the potential to alter how we evaluate and extract insights from enormous amounts of information. Machine Learning allows us to make sense of vast and diverse data sources, identify hidden patterns and trends, and build predictive models that can be used to inform decision-making and drive innovation using advanced algorithms and statistical models. Machine Learning is utilized across various industries and use cases, from healthcare and finance to marketing and e-commerce.
Introduction
In this article, we will be learning about Machine Learning in Big Data but before that, let us get familiar with Machine Learning and Big Data.
Machine Learning and Big Data are two topics quickly expanding and have been increasingly intertwined in recent years. The use of complex algorithms and statistical models to enable computers to learn and make predictions or choices without being explicitly programmed is called Machine Learning. Big Data, on the other hand, refers to the massive and complicated datasets generated in today's digital world.
These two fields' convergence has transformed how we process and evaluate data. We can use Machine Learning to make sense of the huge amounts of data generated daily and utilize it to gain insights, detect trends, and make predictions. This has far-reaching ramifications for various businesses, including finance, healthcare, retail, and e-commerce.
One of the most important advantages of Machine Learning in the context of Big Data is its capacity to automate operations that would be too time-consuming or difficult for humans to perform manually. Machine Learning algorithms, , for example,, can be used to sift through massive datasets to find trends or anomalies or to categorize data into distinct groups depending on specified criteria.
What is Big Data?
Big Data is an ever-growing large set of data. These huge collections of data are growing exponentially with time. We generate massive amounts of data regularly, which take more work to process using standard tools and technology. We employ specialized tools and technologies such as Apache Hadoop, HPCC, Storm, Zoho Analytics, etc. Because data is so crucial these days, we need a dedicated staff of engineers to deal with it in addition to specialized technologies.
5 V's of Big Data
Big Data refers to huge and complicated datasets produced in an increasingly digital society. To grasp the problems and opportunities in Big Data, consider the 5 V's: Volume, Velocity, Variety, Veracity, and Value.
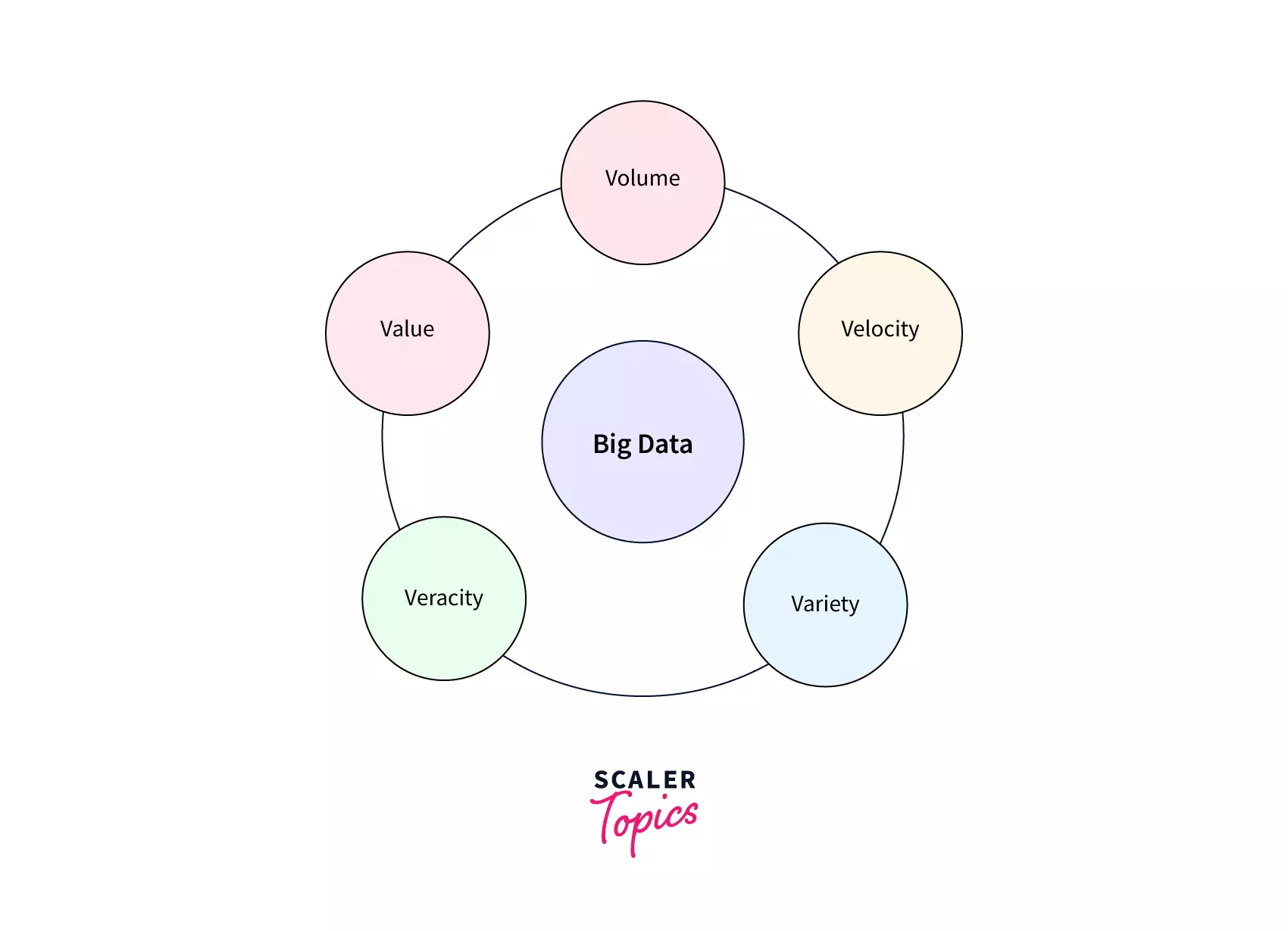
- Volume: refers to the total amount of data, ranging from terabytes to petabytes or even exabytes of data.
- Velocity: relates to how quickly data is created and processed, which can be quantified in real-time or near-real-time.
- Variety: refers to the various generated data types, including structured, unstructured, and semi-structured data.
- Veracity: relates to the data's quality and correctness, with minimal presence of errors, biases, and inconsistencies.
- Value: refers to the insights and value which data can provide, that can be used in decision-making and to promote innovation.
Sources of Data in Big Data
Understanding Big Data data sources is critical for anybody working in data analysis or data science, as it can assist in processing, analyzing, and making sense of this huge and complicated resource.
Social Media
In the realm of Big Data, social media has emerged as a major data source. Every day, platforms like Facebook, Twitter, Instagram, and LinkedIn generate vast data through user-generated posts, comments, likes, and shares. This data can benefit businesses and organizations by providing insights into customer behaviour, sentiment, and preferences.
Data from social media can take several forms, including text, photos, and videos. Understanding this data necessitates sophisticated algorithms and tools capable of processing and making sense of the massive amounts of data created every second. , For example,, natural language processing (NLP) techniques can extract meaning from text data, image recognition tools can be used to identify objects and face in photographs, and sentiment analysis algorithms can be used to interpret the emotional content of social media posts.
Third-Party Cloud Storage
Third-party cloud storage is becoming an increasingly essential data source in the Big Data field. Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform all provide large-scale storage systems that can handle massive volumes of data. This information can originate from various sources, including websites, smartphone apps, and Internet of Things devices.
Scalability is one of the primary advantages of adopting third-party cloud storage for Big Data. These suppliers provide flexible storage solutions that can be scaled up or down as needed, allowing businesses and organizations to handle massive amounts of data without investing in costly hardware or infrastructure. Furthermore, cloud storage providers frequently provide various data management and analysis tools to assist businesses in making sense of their data.
Online Web Pages
Online web pages are a key data source in Big Data. Every day, websites generate vast data, including user traffic, clickstream data, user activity, and more. This data can benefit businesses and organizations by providing insights into user preferences, behaviours, and interactions.
Web scraping, data mining, and machine learning are used to collect and analyze web page data. Online web scraping is the automatic extraction of data from web pages, whereas data mining is the analysis of big datasets to detect patterns and trends. Machine Learning algorithms can offer predictions and suggestions based on web page data.
Dealing with the sheer number and variety of information available is one of the most difficult aspects of gathering and evaluating web page data. In addition, there are also worries about data privacy and security since businesses and organizations must guarantee that they acquire and handle web page data in a responsible and compliant manner.
Internet of Things
A significant data source in Big Data has emerged: the Internet of Things (IoT). Sensors incorporated in IoT devices capture and send data about the physical world, such as temperature, humidity, pressure, position, and more. This data can be extremely helpful to businesses and organizations since it provides insights into machine behaviour and the physical environment.
Smart home devices, wearables, and industrial sensors are all examples of IoT devices. Understanding IoT data necessitates sophisticated algorithms and tools capable of processing and making sense of massive amounts of data created every second. In addition, data integration, cleaning, and transformation may be required along with Machine Learning approaches to find patterns and trends in the data.
One of the primary advantages of adopting IoT devices for Big Data is the ability to make real-time data-driven choices. As a result, businesses and organizations may optimize processes, minimize downtime, and boost efficiency by collecting and analyzing data in real-time.
What is Machine Learning?
Machine Learning (ML) is a subfield of artificial intelligence (AI) that focuses on developing computer systems that can learn from data and make predictions. Machine Learning is fundamentally about creating systems that can learn from data, recognize patterns and trends, and make decisions or predictions based on that information.
Machine Learning is classified into three types: supervised learning, unsupervised learning, and reinforcement learning. The algorithm in supervised learning is trained on labelled data, which means that it is given input-output pairs and learns to make predictions based on that data. Unsupervised learning entails training the algorithm on unlabeled data, which requires the system to recognize patterns and structure in the data without prior knowledge. Finally, reinforcement learning is based on the concept of a reward system, in which the algorithm learns to optimize a reward function through trial and error.
Natural language processing, computer vision, and predictive analytics are all applications that use Machine Learning techniques. , For example,, these algorithms may learn from massive volumes of data, allowing them to recognize patterns and trends that people may find difficult or impossible to discern. These can then be used to predict, classify, or even produce new data.
How to Apply Machine Learning in Big Data?
Machine Learning and Big Data are two powerful technologies that, when combined, have the potential to drive innovation and improve decision-making. Yet, using Machine Learning in Big Data can be difficult since it necessitates advanced algorithms and tools capable of dealing with the sheer volume and complexity of the data.
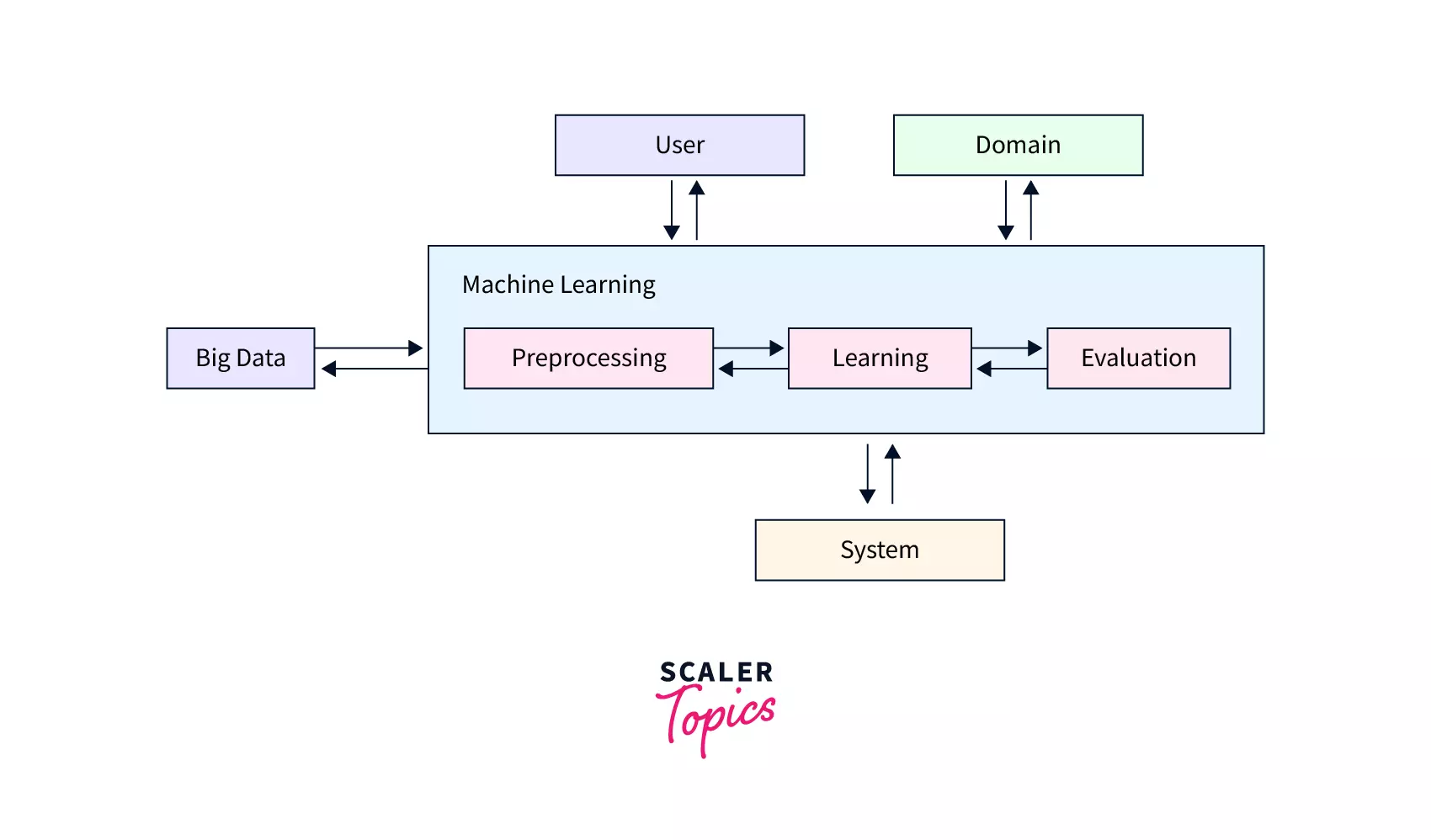
The first step in applying Machine Learning in Big Data is to identify the business problem that needs to be solved. Predicting client behaviour and optimizing supply chain operations are two examples. After defining the problem, the next stage is to collect and prepare the data. Data cleansing, transformation, and integration may be required to ensure accurate and consistent data.
After preparing the data, the next step is to choose the best Machine Learning algorithm for the situation. Depending on the type of data and the desired outcome, this may involve supervised, unsupervised, or reinforcement learning. The algorithm must then be trained on the data, which may entail iterative testing, refining, and retraining operations.
Following training, the algorithm can be used in real-time to make predictions or classify new data. This could include putting the algorithm into production and connecting it with other systems like customer relationship management (CRM) or enterprise resource planning (ERP).
Application of Machine Learning
Machine Learning has numerous applications in various areas, including healthcare, finance, transportation, etc. In addition, Machine Learning may assist businesses and organizations in making better decisions, increasing efficiency and production, and driving innovation and growth.
Data Segmentation
The process of breaking a huge dataset into smaller, more manageable sections based on certain criteria is known as data segmentation. By evaluating patterns and correlations in data, Machine Learning can be used to automate the process of data segmentation. This can assist businesses and organizations in identifying hidden trends and insights in data and making more educated decisions based on these insights. Customer segmentation for focused marketing efforts, product segmentation for supply chain optimization, and financial segmentation for risk management are all examples of how data segmentation may be used.
Data Analytics
The process of studying and interpreting data to extract insights and useful information is known as data analytics. In data analytics, Machine Learning can automate data analysis and identify hidden patterns and relationships in data. This can assist businesses and organizations in making better decisions based on data-driven insights. Machine Learning is commonly used in data analytics for predictive modelling, clustering, classification, and anomaly detection.
Simulation
To study and analyze the behaviour of a real-world system or process, a digital model or representation of it is created. By analyzing data and detecting patterns and relationships, Machine Learning can be used in simulation to improve the accuracy and efficiency of models. This can assist businesses and organizations in simulating real-world scenarios more accurately and making more educated decisions based on the insights gathered from the simulations. , For example,, Machine Learning is commonly used for traffic simulation, weather prediction, and financial modelling.
Big Data and Machine Learning Use Case
Combining Big Data and Machine Learning has numerous applications in various industries. In healthcare , for example,, Machine Learning algorithms can examine enormous volumes of patient data to produce more accurate diagnoses and treatment regimens. In addition, Machine Learning may be used in banking to detect fraud and identify potential problems in real-time.
Machine Learning can be used in e-commerce to personalize product recommendations for clients based on browsing and purchasing history. In addition, Machine Learning can be used to optimize logistics and supply chain operations in transportation.
Another application of Big Data and Machine Learning is predictive maintenance. Machine Learning algorithms analyze massive volumes of sensor data to detect trends and forecast equipment problems before they occur, lowering downtime and maintenance costs.
Difference Between Big Data and Machine Learning
Big Data and Machine Learning are frequently used interchangeably. Another distinction is in their application.
Let us look at the differences between both of them.
| Big Data | Machine Learning |
|---|---|
| Big Data refers to the massive amounts of structured and unstructured data that businesses generate daily. | Machine Learning is a subset of artificial intelligence that involves using algorithms and statistical models to identify patterns and make predictions from data. |
| Big Data is concerned with storing, processing, and managing massive volumes of data. | Machine Learning is concerned with using that data to learn and anticipate future events. |
| Big Data is used to mining massive data sets for insights and detect trends. | Machine Learning creates predictive models to make accurate predictions based on the data. |
Conclusion
- Machine Learning and Big Data are two powerful technologies that, when combined, have the potential to drive innovation and improve decision-making.
- Machine Learning is utilized across various industries and use cases, from healthcare and finance to marketing and e-commerce.
- There are several steps involved in applying Machine Learning to Big Data. The various steps are: identifying the business problem that needs to be solved, collecting and preparing the data, and choosing the best Machine Learning algorithm for the situation.
- Big Data is concerned with managing massive volumes of data, whereas Machine Learning is concerned with using that data to make predictions and discover patterns.
- Big Data comprises numerous data sources, including social media platforms, internet transactions, mobile devices, sensor networks, etc.
- One of the most important advantages of Machine Learning in the context of Big Data is its capacity to automate operations that would be too time-consuming or difficult for humans to perform manually.