Machine Learning Models

Machine Learning Models are algorithms designed to learn from and make predictions or decisions based on data, mimicking the way humans learn and adapt to new information. This technology is at the heart of artificial intelligence, enabling computers to uncover insights and patterns without being explicitly programmed for specific tasks.
What is a Machine Learning Model?
A Machine Learning Model is a mathematical model that enables a computer to learn from data. It uses algorithms to analyze and interpret data, identify patterns, and make decisions with minimal human intervention. These models are trained on datasets, allowing them to improve their accuracy over time as they are exposed to more data. Machine learning models can be categorized into supervised, unsupervised, and reinforcement learning, each with unique approaches to learning and solving problems. This capability forms the basis for a wide range of applications, from predictive analytics to autonomous systems, making machine learning a pivotal technology in the AI landscape.
Classification of Machine Learning Models
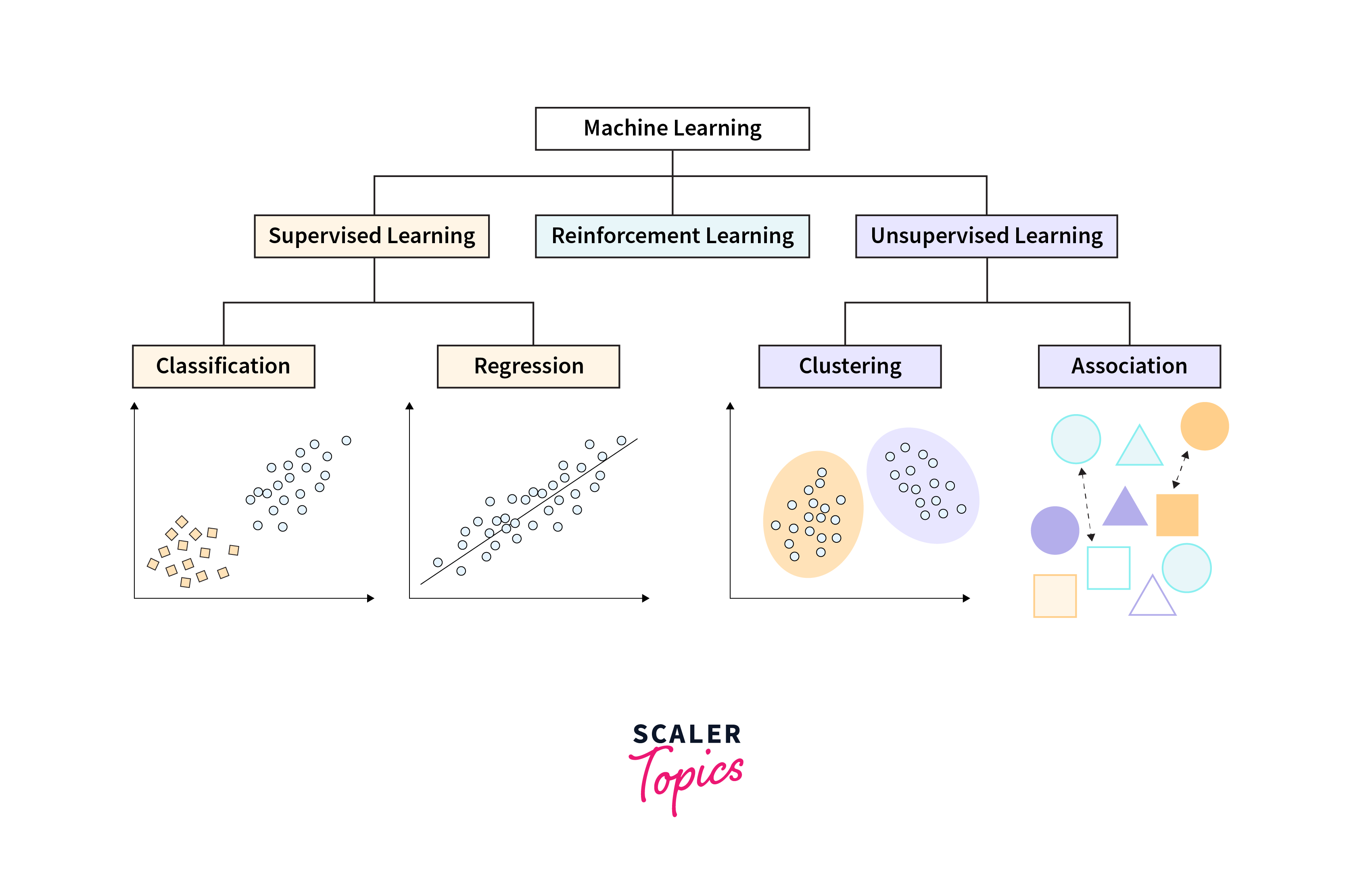
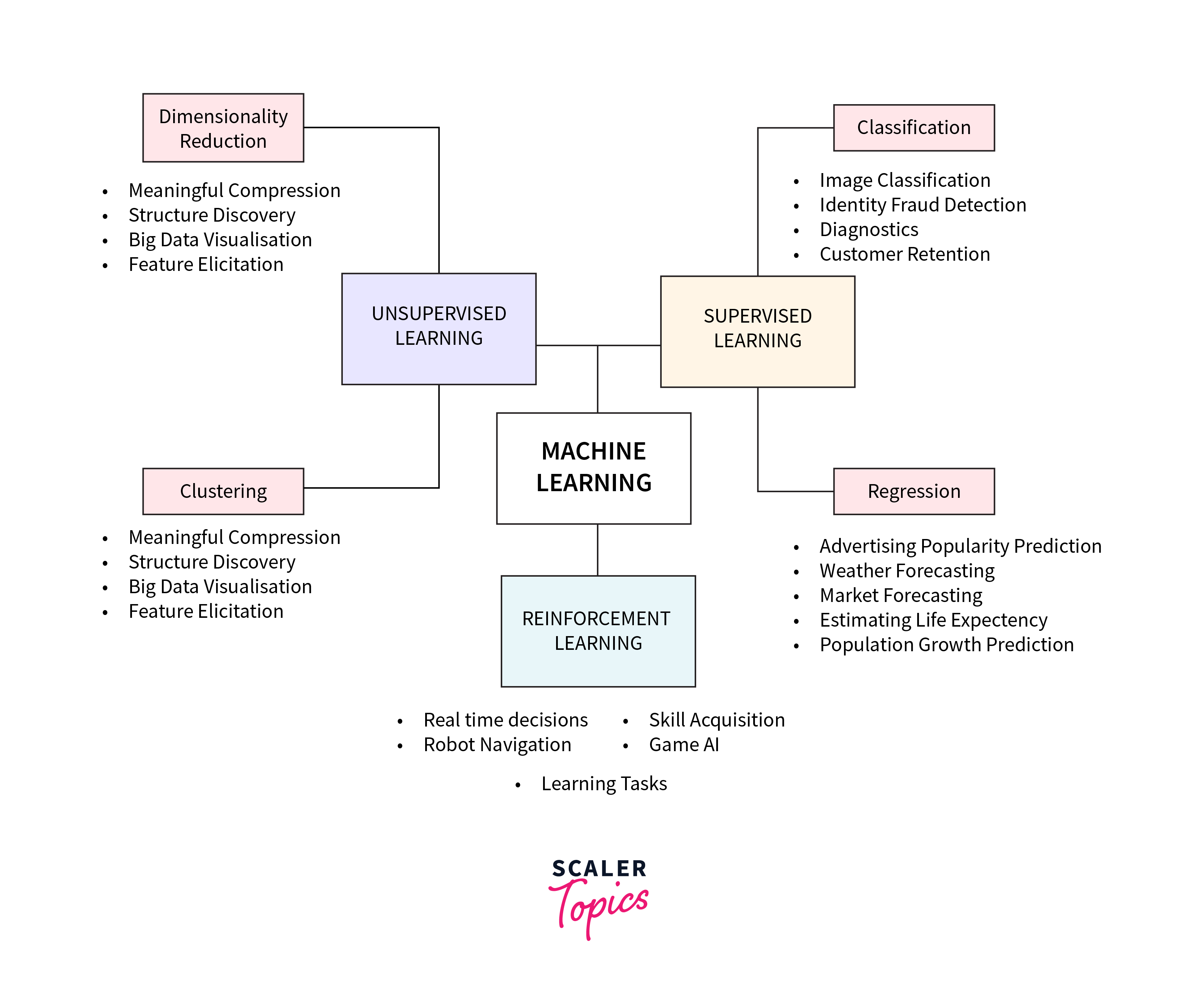
Machine Learning Models can be broadly classified into three main categories: Supervised Learning, Unsupervised Learning, and Reinforcement Learning. Each category has its own set of algorithms and applications, tailored to different types of data and learning objectives. This classification helps in understanding the nature of the learning process involved and guides the selection of the most appropriate model for a given problem.
Supervised Learning
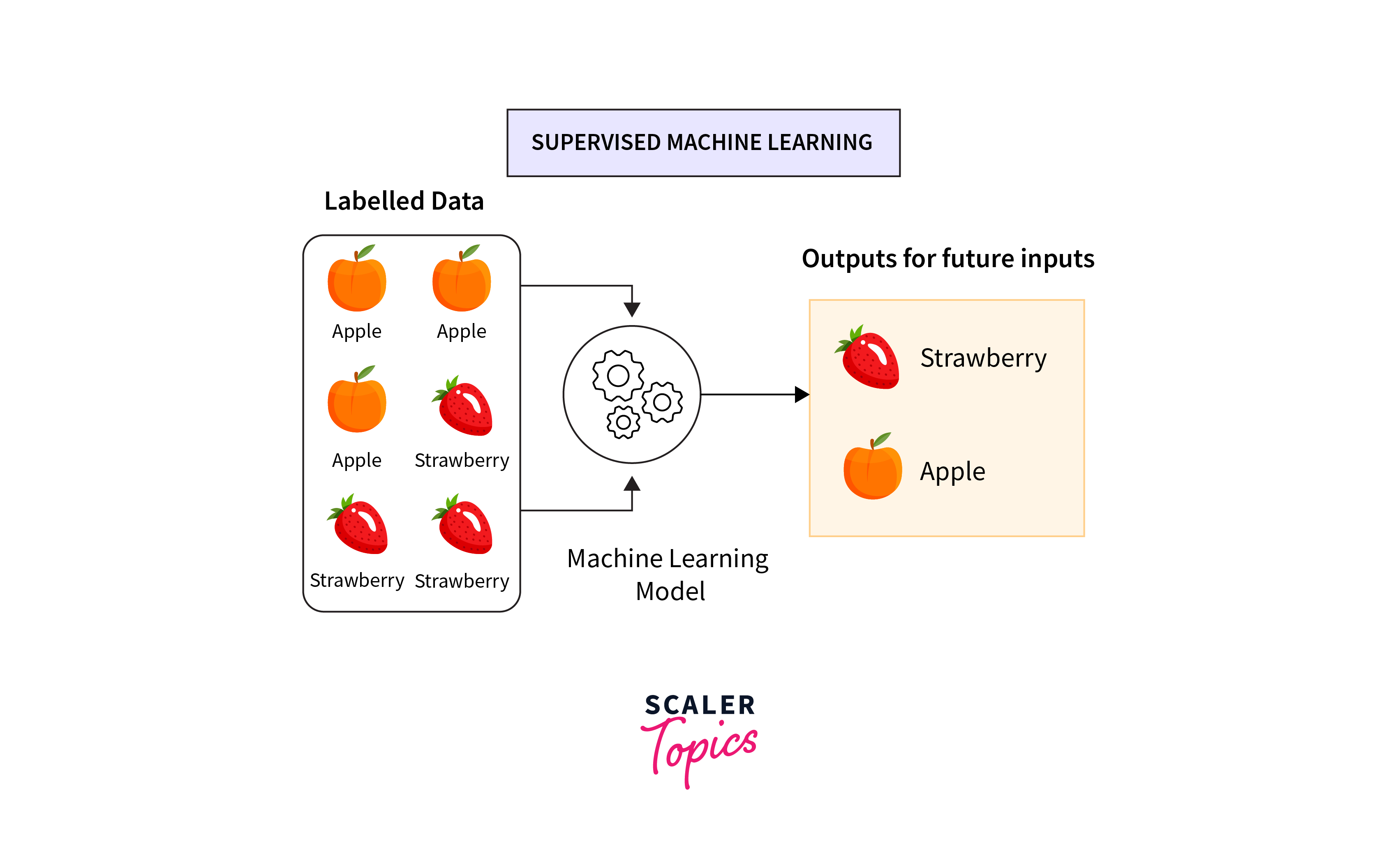
Supervised Learning is a type of Machine Learning where the model is trained on a labeled dataset, meaning that each training example is paired with an output label. The model learns to map inputs to desired outputs, making it ideal for predictive tasks. Supervised learning algorithms include linear regression for continuous outcomes and logistic regression, decision trees, and neural networks for categorical outcomes. This approach is widely used in applications such as spam detection, image recognition, and predicting consumer behavior, where the relationship between the input data and the output prediction is clear and defined.
Unsupervised Learning
Unsupervised Learning involves training a machine learning model on data without labeled responses. The goal is for the model to identify patterns and relationships in the data on its own. Common unsupervised learning algorithms include clustering, like K-means for grouping similar data points together, and dimensionality reduction techniques, such as Principal Component Analysis (PCA), which simplify data without losing critical information. Unsupervised learning is particularly useful in exploratory data analysis, anomaly detection, and customer segmentation, where the underlying structures or patterns within the data are not previously known.
Reinforcement Learning
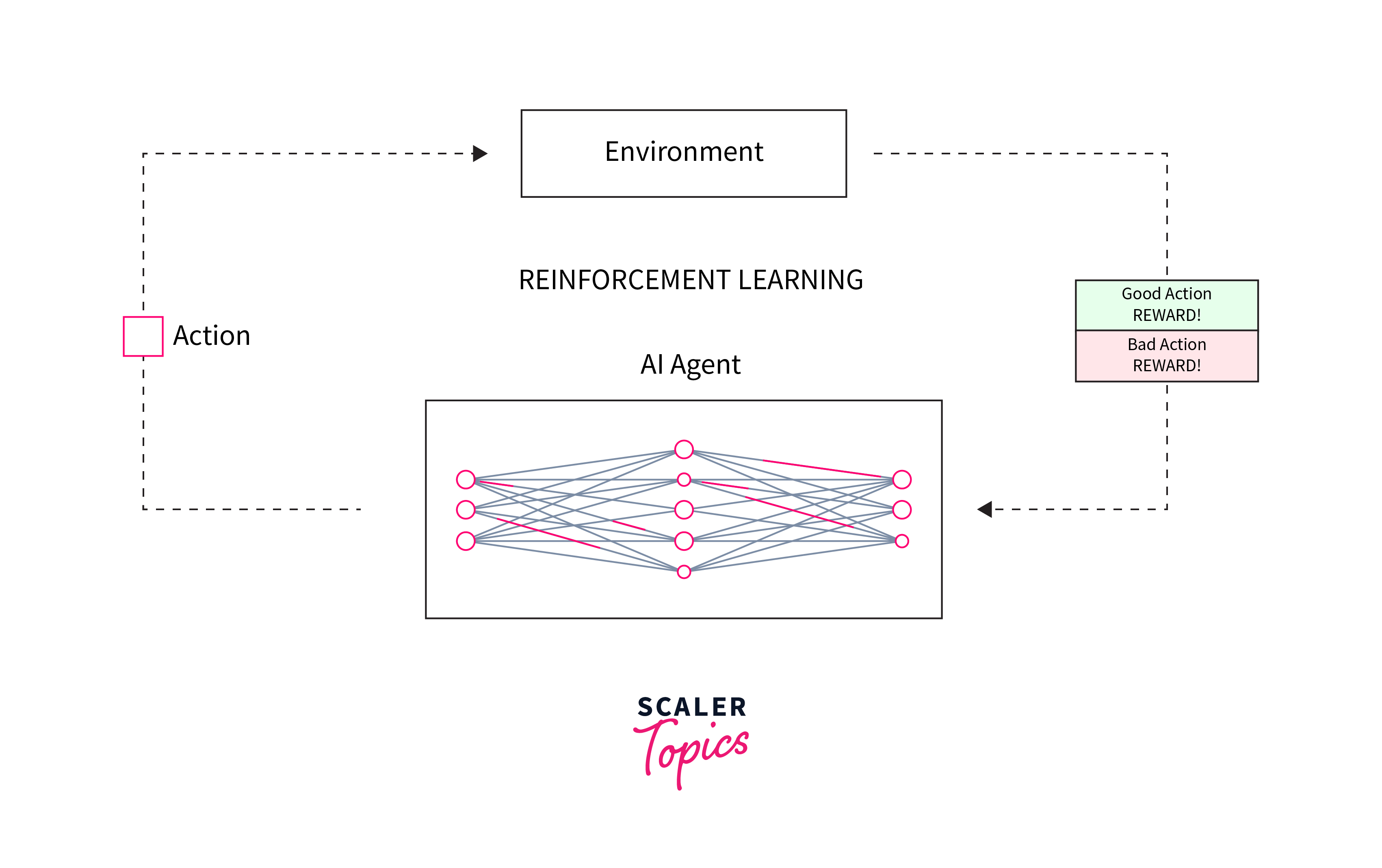
Reinforcement Learning is a type of machine learning where an algorithm learns to make decisions by taking actions in an environment to achieve a goal. It differs from supervised and unsupervised learning by focusing on how an agent should act in a given situation to maximize a cumulative reward. The learning process involves the agent experimenting with actions and learning from the outcomes, adjusting its strategy based on the feedback received in the form of rewards or penalties. Reinforcement learning is widely used in areas such as robotics, game playing, and navigation, where the model needs to make a sequence of decisions that lead to a desired outcome.
Supervised Learning
Supervised Learning is a cornerstone of machine learning, where models are trained using labeled data to predict outcomes for new, unseen data. This approach relies on learning the relationship between input features and the target output during the training phase, allowing for accurate predictions and decisions in various applications.
Classification

Classification is a type of supervised learning where the output variable is a category, such as "spam" or "not spam" in email filtering, or "malignant" or "benign" in medical diagnosis. The goal is to accurately assign each input data point to one of the predefined categories. Algorithms used for classification include Logistic Regression, Decision Trees, Random Forests, Support Vector Machines (SVM), and Neural Networks. Classification is widely used in applications requiring discrete outcomes, making it essential for tasks like fraud detection, customer segmentation, and image recognition.
Classification: Types and Models
Classification in supervised learning can be broadly categorized into binary classification, multiclass classification, and multi-label classification:
-
Binary Classification:
The simplest form, where there are only two possible classes. For example, an email is either spam (1) or not spam (0). A common algorithm for binary classification is Logistic Regression, which uses the sigmoid function:where (z) is the output of the linear part of the model. The sigmoid function maps any real-valued number into a value between 0 and 1, suitable for binary classification.
-
Multiclass Classification:
Involves categorizing data into three or more classes. For instance, classifying types of fruits in images. Algorithms like Decision Trees, Support Vector Machines (with techniques like one-vs-all), and Neural Networks are used for multiclass classification. -
Multi-label Classification:
Each instance may be assigned multiple labels simultaneously, such as tagging a blog post with multiple topics. Techniques for multi-label classification often involve adaptations of binary and multiclass methods to handle multiple labels per instance.
Types of Models for Classification:
-
Logistic Regression
-
Decision Trees
-
Random Forests
-
Support Vector Machines (SVM)
-
Neural Networks
Regression
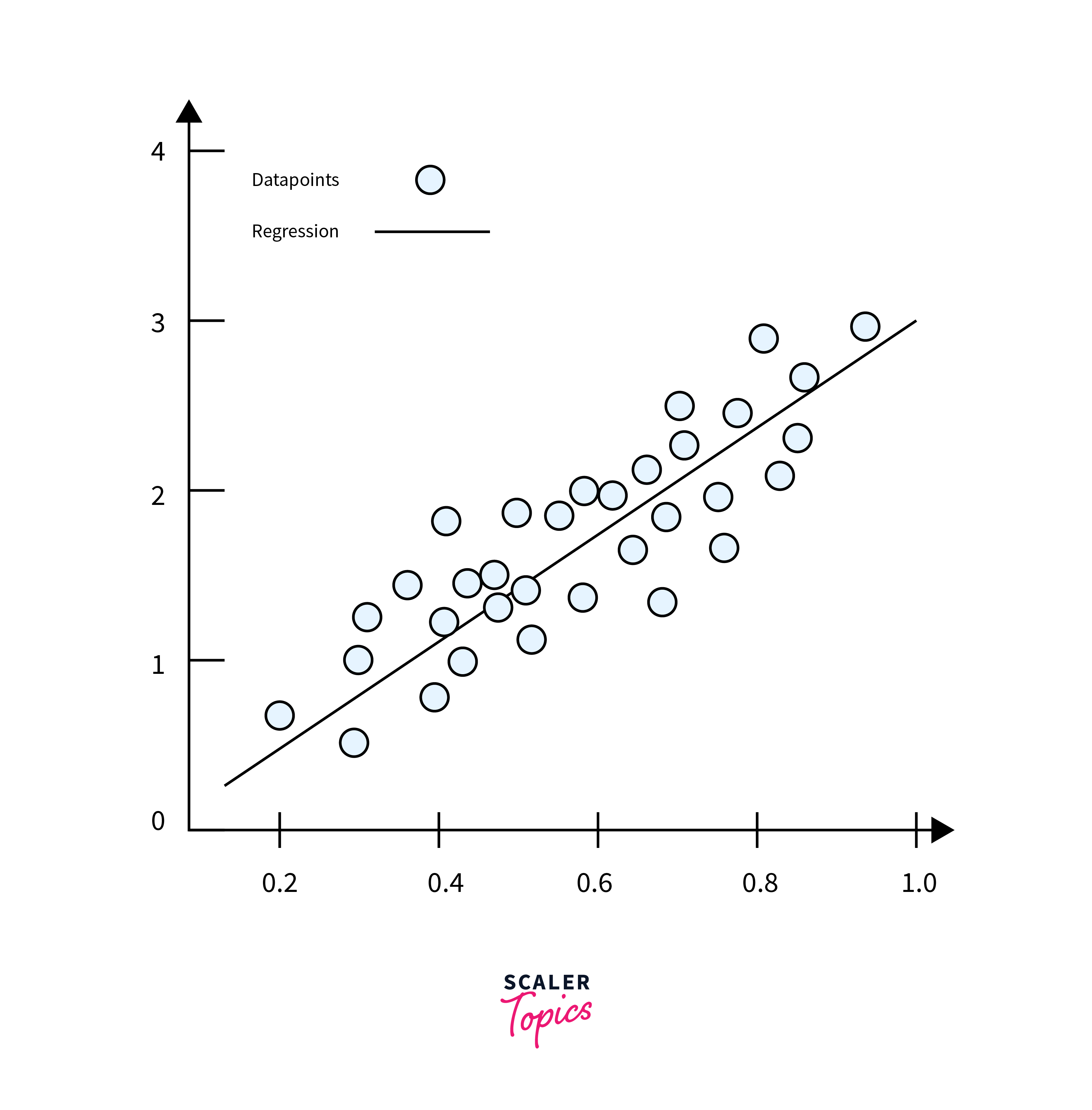
Regression is another type of supervised learning used to predict a continuous outcome variable based on one or more predictor variables. Unlike classification, which predicts discrete labels (categories with no inherent order), regression aims to forecast a continuous quantity (a measurable quantity that can change gradually), making it invaluable for predicting things like sales figures, temperatures, and financial forecasts.
Types of Regression
-
Linear Regression:
This model is ideal for scenarios where a linear relationship exists between input and output variables. For example, predicting house prices based on their size. The formula represents the relationship, where (y) is the predicted house price, (x) is the size of the house, is the starting price, reflects how much the price increases with house size, and is the error in prediction. -
Polynomial Regression:
Useful for more complex relationships where adjustments to the linear model are needed to fit curves. An application could be predicting electricity consumption based on temperature, where higher degree terms , etc.) account for rapid increases or decreases in consumption during extreme temperatures. -
Ridge and Lasso Regression:
These methods are particularly valuable in situations with many variables, some of which might contribute little to the prediction. For instance, in predicting an individual's risk of heart disease based on a wide range of features including age, weight, height, diet, exercise frequency, and genetic factors, Ridge and Lasso help emphasize important features while penalizing the less significant ones to improve model accuracy and prevent overfitting. Ridge regression does this by adding a penalty to the square of the coefficients, thus shrinking them but not necessarily to zero. Lasso, on the other hand, can shrink some coefficients to zero, effectively performing feature selection.
Models for Regression
- Simple and Multiple Linear Regression Models
- Decision Tree Regression
- Random Forest Regression
- Support Vector Regression (SVR)
- Neural Networks for Regression
Unsupervised Machine Learning
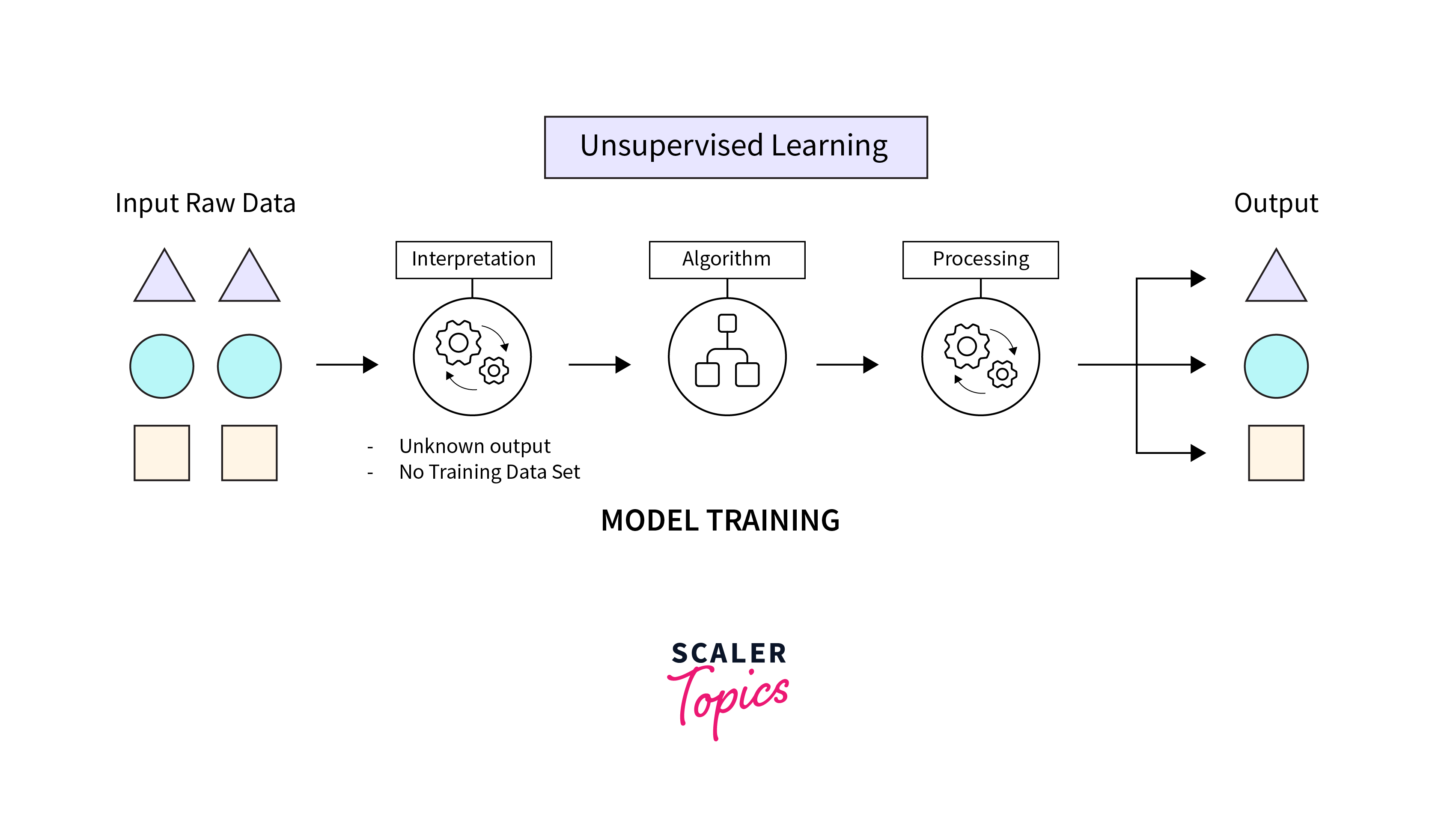
Unsupervised Machine Learning involves models that learn patterns from untagged data. Unlike supervised learning, where models predict a label based on input data, unsupervised learning discovers the inherent structure within the data. This type of learning is key for exploratory data analysis, identifying hidden patterns, and understanding data's underlying dynamics.
Clustering
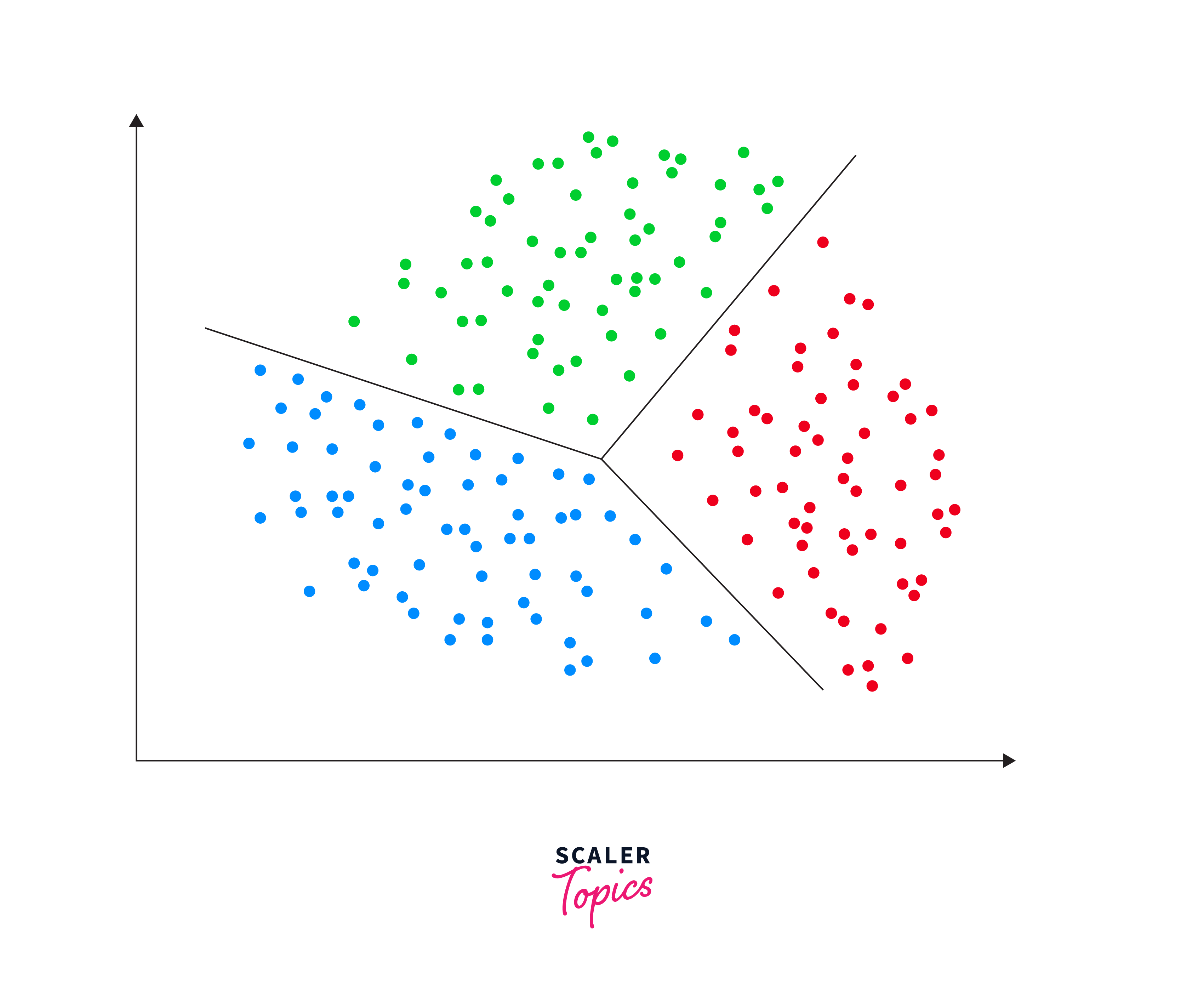
Clustering is a primary technique in unsupervised learning used to group data points into clusters based on similarity. The aim is to have data points in the same cluster be more similar to each other than to those in other clusters. Clustering is widely applied in market segmentation, anomaly detection, and organizing large sets of data in various fields. Here are some common clustering models and their applications:
-
K-Means Clustering:
Splits the data into K distinct, non-overlapping clusters based on the distance to the centroid of the clusters. It's effective in partitioning data into a specified number of clusters, although it requires the number of clusters to be defined in advance. -
Hierarchical Clustering:
Builds a tree of clusters by either a divisive method (starting with all data points in one cluster and dividing it) or an agglomerative method (starting with each data point in its own cluster and merging them). This method is useful for understanding data's hierarchical structure and does not require specifying the number of clusters upfront. -
DBSCAN (Density-Based Spatial Clustering of Applications with Noise):
Forms clusters based on the density of data points, allowing it to find clusters of arbitrary shape and identify outliers. DBSCAN is particularly useful in scenarios where the data contains noise and clusters are not uniformly sized or shaped. -
Spectral Clustering:
Uses the eigenvalues of a similarity matrix to reduce dimensions before clustering in fewer dimensions. This method is effective for clustering complex datasets where traditional methods like K-means may not perform well.
Association Rule Learning
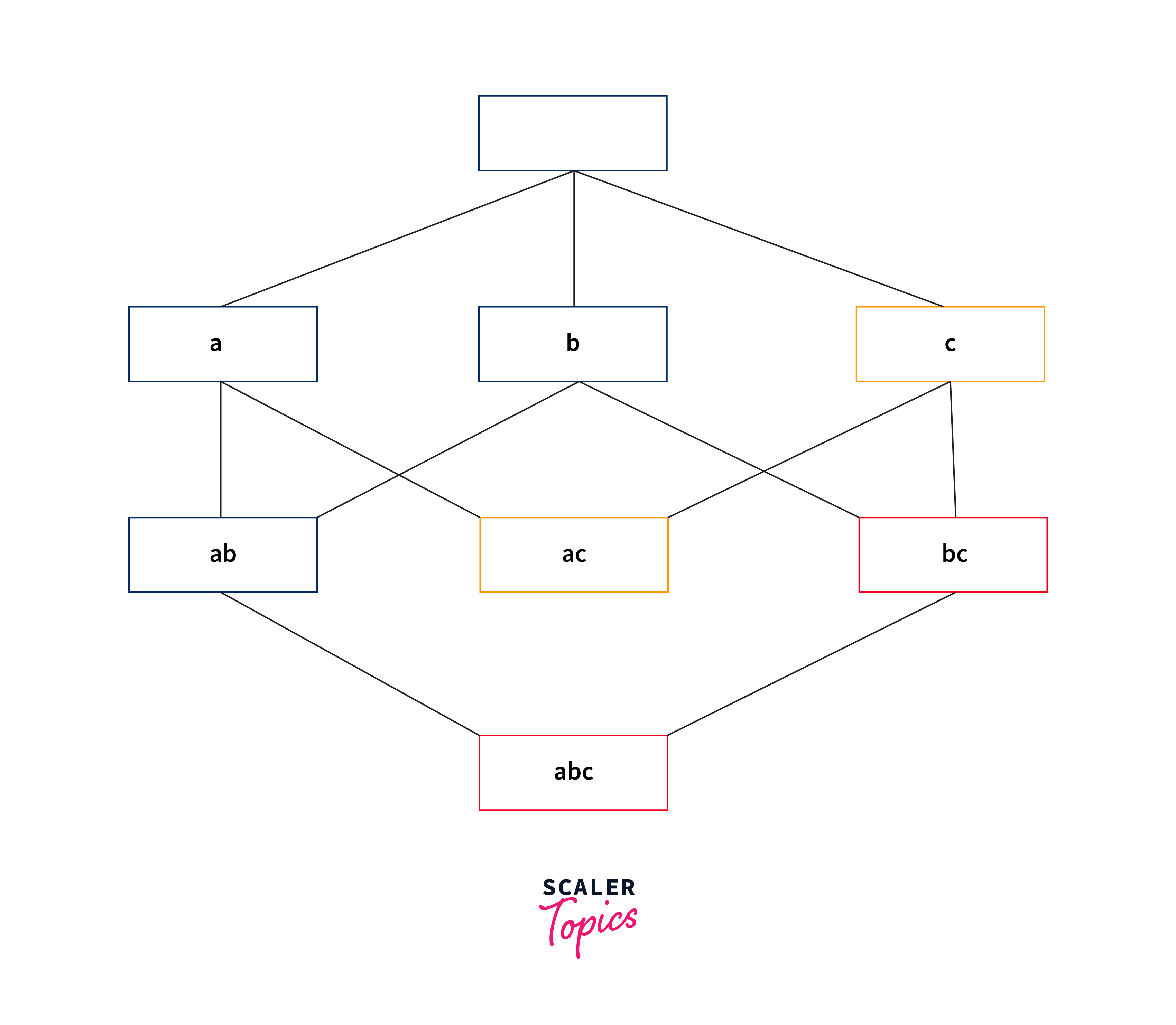
Association Rule Learning is a method in unsupervised machine learning used to discover interesting relationships (associations and correlations) between variables in large datasets. It's widely known for its application in market basket analysis, where it helps retailers understand the relationships between different products purchased together. The goal is to identify strong rules discovered in databases using some measures of interestingness.
Key concepts in association rule learning include:
- Support:
The frequency with which items appear together in the dataset. A high support indicates that the rule applies to a large portion of the dataset. - Confidence:
The likelihood that an item B is purchased when item A is purchased. It measures the reliability of the inference made by the rule. - Lift:
The ratio of the observed support to that expected if A and B were independent. A lift value greater than 1 indicates that A and B appear more often together than expected, showing a positive relationship between them.
Common algorithms used in association rule learning include:
- Apriori Algorithm:
Identifies the itemsets that appear together in the dataset with frequency above a certain threshold (support), and then constructs association rules that have high confidence. - FP-Growth Algorithm:
More efficient than the Apriori algorithm, it uses a tree structure to compress the database and finds frequent itemsets without candidate generation, significantly reducing the computational burden.
Dimensionality Reduction
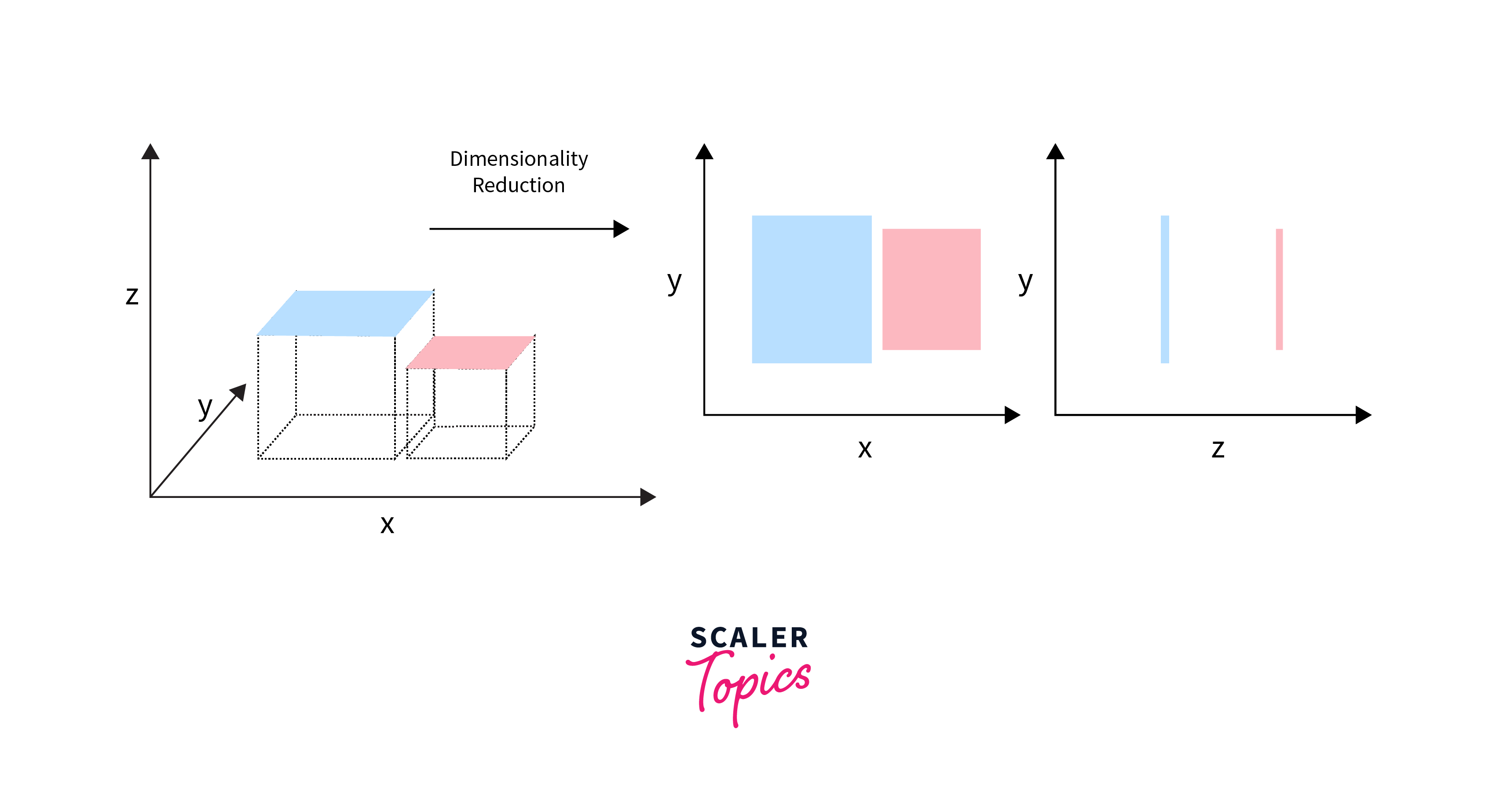
Dimensionality Reduction is a technique in unsupervised machine learning aimed at reducing the number of input variables in a dataset. Simplifying the data without losing essential information, helps to mitigate issues related to high-dimensional spaces — often referred to as the "curse of dimensionality." This approach enhances the efficiency of machine learning models, facilitates data visualization, and can improve model performance by removing irrelevant features or noise.
Reinforcement Learning

Reinforcement Learning (RL) is a type of machine learning where an agent learns to make decisions by performing actions in an environment to achieve a goal. The agent receives rewards or penalties based on the actions it takes, guiding it to learn the best strategy, or policy, to accumulate the maximum reward over time. This learning paradigm is distinct because it focuses on learning through interaction and is particularly suited for problems where there is no correct answer available a priori, but feedback is available in terms of rewards or punishments.
How to Choose the Best Machine Learning Model?
Choosing the best Machine Learning (ML) model for a specific task involves considering several factors to ensure that the model meets the project's requirements for accuracy, efficiency, and scalability. Here's a guide to help you navigate the selection process:
-
Understand the Problem:
Clearly define the problem you're trying to solve. Is it a classification, regression, clustering, or reinforcement learning task? The nature of the problem will significantly narrow down your choices. -
Data Characteristics:
Examine your dataset. The size, quality, and nature of your data (e.g., text, images, numerical) can influence the choice of the model. Some models are better suited for large datasets, while others can perform well on smaller datasets. Additionally, consider if your data is labeled or unlabeled. -
Performance Metrics:
Decide on the metrics you will use to evaluate the model's performance. Accuracy, precision, recall, and F1 score are common for classification tasks, while mean squared error (MSE) and mean absolute error (MAE) might be used for regression tasks. The choice of metric depends on the specific objectives of your project. -
Complexity and Scalability:
Consider the complexity of the model and its scalability. Complex models may provide higher accuracy but require more data, computational resources, and tuning. In contrast, simpler models can be easier to implement and interpret but might not capture complex patterns in the data as well. -
Training Time:
Evaluate how much time and computational resources are available for training the model. Some models, especially deep learning models, require significant computational power and time to train. -
Interpretability:
If understanding how the model makes decisions is important (for example, in healthcare or finance), prioritize models that are more interpretable, like decision trees or linear regression, over "black box" models like deep neural networks. -
Experiment and Compare:
Finally, it's often useful to experiment with multiple models and compare their performance based on your selected metrics. Cross-validation can help assess how the models will generalize to an independent dataset. -
Consider Pre-trained Models or Transfer Learning:
For tasks like image or natural language processing, consider using pre-trained models or applying transfer learning, especially if your dataset is small. These approaches can significantly reduce development time and computational costs.
FAQs
Q. Can one machine learning model fit all types of problems?
A. No, different problems require different models based on the nature of the task and data.
Q. How important is data quality in machine learning?
A. Extremely important; high-quality, relevant data is crucial for training effective machine learning models.
Q. Is it necessary to have a large dataset for machine learning?
A. Not always; some models can learn from smaller datasets, but larger datasets generally improve model performance.
Q. Can machine learning models predict future events?
A. Yes, machine learning models can forecast future events based on historical data, though accuracy depends on the model and data quality.
Conclusion
- Selecting the right machine learning model is a critical step that depends on understanding the specific problem, the nature of the data, and the desired outcomes.
- The quality and quantity of data play a significant role in the effectiveness of a machine-learning model, highlighting the importance of data preparation and analysis.
- Different types of machine learning tasks—such as classification, regression, clustering, and reinforcement learning—require different models, each with its strengths and limitations.
- Balancing factors such as model complexity, interpretability, training time, and computational requirements is essential for achieving optimal performance while meeting project constraints.
- Continuous experimentation and comparison of models using relevant performance metrics are key to identifying the best solution for a given machine learning challenge, often requiring iterations and refinements to align with evolving project needs and data landscapes.