Machine Learning vs Data Mining
Overview
In today's data-driven world, the realms of machine learning and data mining play crucial roles in extracting insights from vast amounts of information. While both fields involve extracting knowledge from data, they differ in their approaches, objectives, and applications. Understanding the distinctions between machine learning and data mining is essential for individuals and organizations seeking to leverage the power of data analytics effectively. In this article, we will aim to understand the difference between machine learning vs data mining.
What is Data Mining?
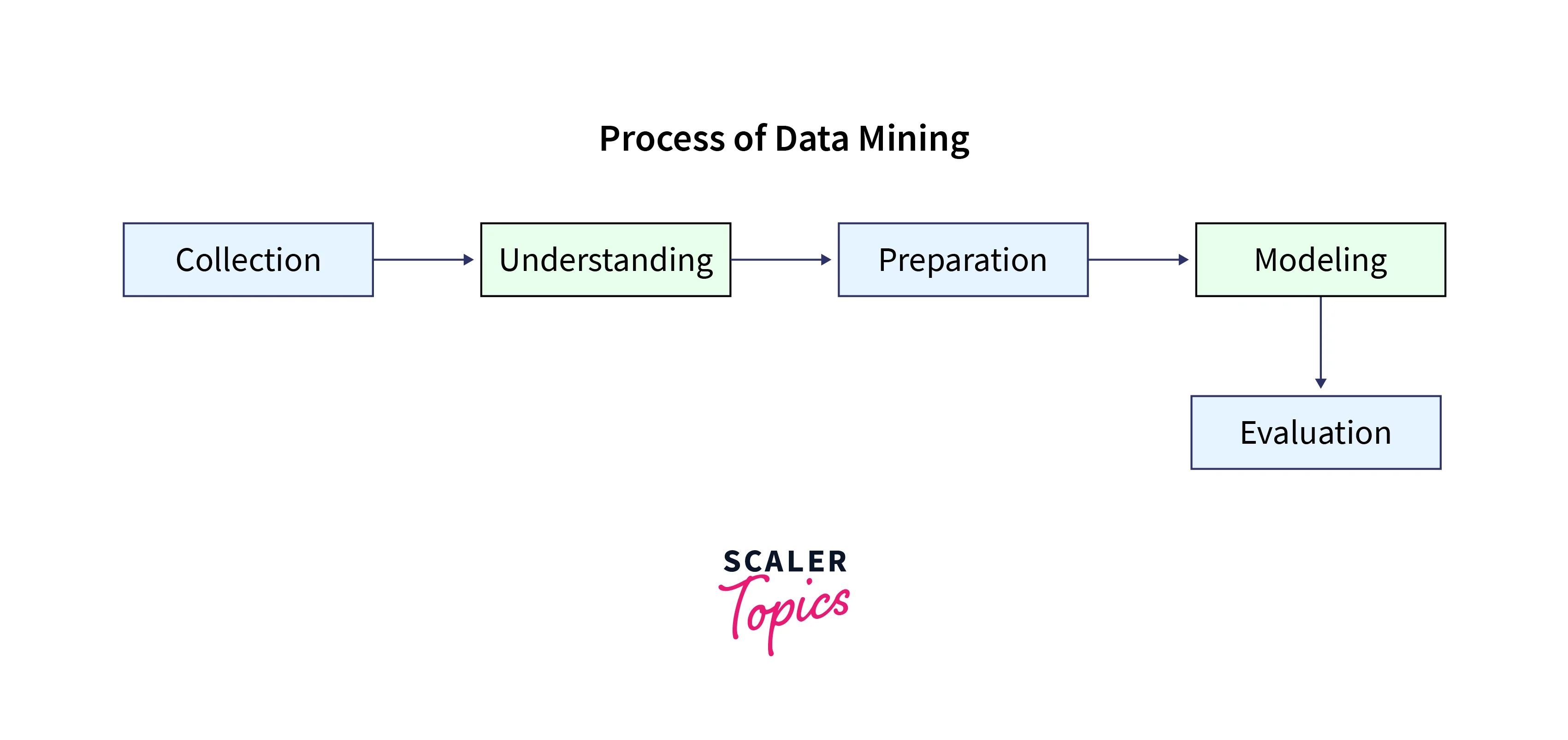
Data mining is the process of discovering valuable patterns, relationships, or knowledge from large volumes of data. It involves applying statistical and computational techniques to explore and extract insights to aid decision-making, prediction, and optimization. Data mining aims to transform raw data into meaningful and actionable information.
Data mining encompasses a range of techniques and methodologies, each suited to different types of data and analysis objectives. By leveraging these techniques, data mining allows analysts and researchers to uncover hidden patterns, identify trends, and make predictions or inferences based on the available data.
A few of the most commonly used data mining techniques include clustering, classification, regression, association rule mining, outlier detection, etc. Clustering is used to group similar data points based on their characteristics, such as customer segmentation in marketing. Classification involves assigning predefined categories to data instances, such as predicting whether an email is spam or not. Regression is utilized to predict numeric values based on input variables, such as predicting house prices based on features like area and location. Association rule mining uncovers relationships and patterns in data, such as identifying items frequently purchased together in a retail transaction. Outlier detection identifies unusual or anomalous data points, such as detecting fraudulent credit card transactions.
What is Machine Learning?
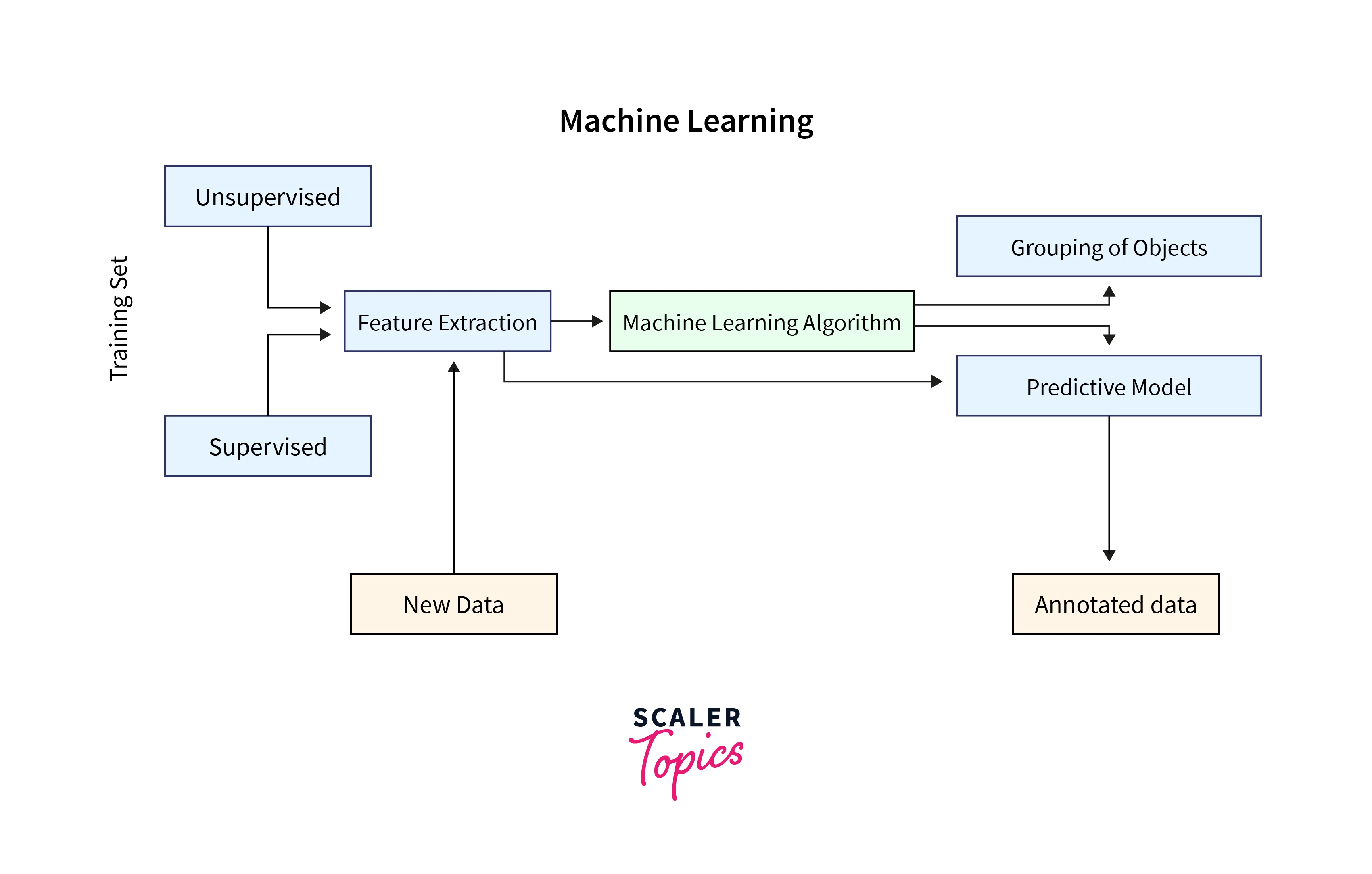
Machine learning is a subfield of artificial intelligence (AI) that focuses on developing algorithms and models that enable computers to learn from data and improve their performance without explicit programming. Instead of relying on predefined rules, machine learning algorithms are designed to automatically learn patterns, make predictions, or take actions based on the data they are exposed to.
The core idea behind machine learning is to build models that can generalize from the provided data to make accurate predictions or decisions on new, unseen data. These models are trained using labeled or unlabeled data, depending on the type of learning algorithm employed.
Machine Learning algorithms can be divided into three categories - supervised, unsupervised, and reinforcement learning algorithms. In supervised learning, the algorithm learns from labeled training data, where each data point is associated with a known outcome or target variable. By analyzing the features of the labeled data, supervised learning algorithms can learn to generalize patterns and make accurate predictions on unseen or future data. Supervised learning finds applications in tasks such as classification, regression, and recommendation systems.
On the other hand, unsupervised learning algorithms explore unlabeled data to uncover underlying patterns or structures without prior knowledge of the outcomes. These algorithms group similar data points, identify anomalies, or discover hidden relationships. Unsupervised learning techniques include clustering, dimensionality reduction, and association rule mining.
In reinforcement learning, an algorithm learns through trial and error by interacting with an environment. It receives feedback in the form of rewards or penalties based on its actions. The goal of reinforcement learning is to discover the best actions or policies that maximize the total cumulative reward over time. It is like a learning process where the algorithm explores different actions, observes the consequences, and adjusts its strategy accordingly to achieve optimal performance. Reinforcement learning is commonly used in tasks where an optimal sequence of actions needs to be determined, such as game playing (e.g., AlphaGo) or autonomous robot control (e.g., self-driving cars).
Difference Between Data mining and Machine learning
- Data mining and machine learning are closely related fields within data analytics, but they differ in their objectives, approaches, and emphasis. Understanding the distinctions between data mining and machine learning is crucial for effectively utilizing these techniques in different contexts.
- Data mining is a broader concept encompassing various techniques and methodologies to discover patterns, relationships, and insights from large volumes of data. On the other hand, machine learning is a subset of artificial intelligence that emphasizes the development of algorithms and models that can automatically learn and improve from data without being explicitly programmed.
- One key difference between data mining and machine learning lies in their respective goals. Data mining aims to extract knowledge and insights from data, emphasizing discovering patterns and relationships that may not be initially apparent. On the other hand, machine learning is primarily focused on developing predictive models that can make accurate predictions or decisions based on learned patterns and relationships within the data.
- Furthermore, machine-learning techniques are often used in the overall data mining process. Various data mining techniques can be employed to preprocess and explore the data, select relevant features, identify outliers, and uncover hidden patterns. Machine learning algorithms then build upon this to develop predictive models using the processed and analyzed data.
- Data mining lacks the ability for self-learning. It adheres to predefined guidelines and provides specific solutions to given problems. On the other hand, machine learning algorithms possess self-defined capabilities, allowing them to adapt their rules based on the situation. They can discover solutions for specific problems and resolve them in their unique manner.
- Data mining leverages extensive data to extract valuable information and predict future outcomes. For instance, marketing companies may use past data to forecast sales. In contrast, machine learning relies less on the quantity of data and instead focuses on algorithms. Transportation companies like OLA and Uber utilize machine learning techniques, such as calculating the Estimated Time of Arrival (ETA) for rides.
- Another distinction between data mining and machine learning lies in their dependence on human involvement. In data mining, human effort is required in various stages, such as understanding the domain, defining the problem, selecting relevant data, preprocessing the data, and designing appropriate data mining techniques to extract useful patterns and insights from the data. On the other hand, in machine learning, human effort is mainly focused on preparing training datasets, selecting suitable machine learning models, and hyperparameter tuning. While some preprocessing is necessary, machine learning algorithms can automatically learn from the data and make predictions or decisions without significant human intervention. Therefore, data mining involves more human effort as it requires domain knowledge, data understanding, and manual exploration of data to discover valuable patterns, whereas machine learning relies more on automated learning processes.
- Data mining utilizes components such as databases, data warehouse servers, data mining engines, and pattern assessment techniques to extract valuable information. In contrast, machine learning employs neural networks, predictive models, and automated algorithms to make decisions and draw conclusions.
Machine Learning Vs Data Mining
Here is the tabular comparison of machine learning vs data mining -
| Factor | Machine Learning | Data Mining |
|---|---|---|
| Objective | Building models that learn from data and make predictions or decisions based on learned patterns and relationships. | Discovering patterns, relationships, and insights from data to inform decision-making and optimization. |
| Emphasis | Prediction and decision-making | Discovery of patterns and relationships in the data |
| Techniques | Supervised learning, unsupervised learning, reinforcement learning | Exploratory data analysis, association rule mining, classification, regression, clustering, outlier detection |
| Implementation Approach | Algorithm-based modeling | Statistical and computational techniques |
| Input/Output | Training models using datasets to make predictions or decisions on new, unseen data. | Analysis of existing datasets to uncover patterns and relationships. |
| Application | Prediction, recommendation systems, anomaly detection | Market basket analysis, customer segmentation, fraud detection |
| Example Algorithms | Random Forest, Support Vector Machines, Neural Networks | Apriori algorithm, K-means clustering, Decision Trees |
Build a strong foundation in data science by enrolling in our free course and embrace the future of data-driven decision-making.
Conclusion
- Machine learning and data mining are two distinct yet interconnected fields within data analytics. While machine learning focuses on building predictive models that learn from data to make accurate predictions or decisions, data mining aims to extract knowledge and insights from large datasets through statistical and computational techniques.
- Machine learning encompasses supervised, unsupervised, and reinforcement learning, enabling computers to learn patterns and relationships from labeled or unlabeled data. In contrast, data mining techniques include exploratory data analysis, association rule mining, classification, regression, clustering, and outlier detection to uncover hidden patterns and relationships in data.
- Data mining techniques often serve as a foundation for machine learning by preprocessing and exploring data, selecting relevant features, and identifying patterns and anomalies. Machine learning algorithms then build upon this groundwork to develop predictive models.
- Understanding the distinctions between machine learning and data mining allows practitioners to leverage their unique strengths and apply them effectively in various data-driven applications. Combining both fields can lead to powerful insights and predictive capabilities, empowering organizations to make data-informed decisions and optimize their processes.