BBC News Classification Project
Overview
Working with Machine Learning and Natural Language Processing at the same time seems like a daunting task. However, with the help of this article, you will be able to work with them in no time. In this article, we will use ML and NLP to classify the news from BBC (British Broadcasting Corporation) into five sections.
Additionally, by developing multiple classifiers that might assist news networks in directing their information to a particular audience, this project can be expanded to real-time applications.
What are We Building?
In the BBC News Classification Project, we are building a predictive model to evaluate the various news records and classify them accordingly with the help of some parameters.
The parameters into consideration are the various headlines with their respective categories.
After cleaning and preprocessing the dataset using NLP techniques, we will use Machine Learning algorithms like Random Forest and SVM to classify each headline to its respective category.
Pre-requisites
To churn the best out of this article, the following prerequisites would be a plus:
- Basic Knowledge of Python would be beneficial.
- Implementation of libraries like Pandas, Numpy, Seaborn, Matplotlib, and SciKit Learn.
- Understanding of Machine Learning algorithms like Random Forest, Linear, and Logistic Regression.
- Intermediate understanding of various text cleaning and preprocessing techniques like stemming and lemmatization.
How Are We Going to Build This?
Here's how we are going to work on this project:
- Libraries - Importing the necessary NLP and ML libraries.
- Data Analysis - This step will enable us to figure out the various values and features of the dataset.
- Data Visualization - With basic Data Visualization, we will be able to figure out the various underlying patterns of our dataset.
- Preprocessing - Since we are working with textual data in this project, preprocessing is very important for us to create a classifier. Using techniques like Tokenization and Lemmatization, we'll make our data model-ready.
- Model Training - In this step, we will use various Machine Learning algorithms like Random Forest, Logistic Regression, SVC, etc., to try and create a classifier that successfully classifies news to their respective categories.
- Model Evaluation - To make sure our classifier is working the way we want it to, we'll perform various evaluation techniques like accuracy and ROC score.
- Model Testing - Finally, we will test our classifier with real-life data to see if it can actually predict the category of the headline.
Final Output
Our final output would be to create a classifier that can predict the headline to its respective category.
Requirements
- Environment - Either an online or offline compiler
- Libraries - Pandas, Numpy, Seaborn, Matplotlib, SciKit Learn, PorterStemmer, Lemmatizer, stopwords, etc.
About the Data
The dataset that we'll be working with is the BBC News Dataset. BBC News news story datasets are made available for use as standards in machine learning research. For the convenience of use, the original data is transformed into a single CSV file while preserving the news title, the name of the relevant text file, the news content, and its category.
Understanding the Dataset
The aim of our classifier is to be able to successfully predict the category of a headline. This could potentially help news corporations to segregate their news headlines and be more accurate with their telecasts.
Algorithms Used in BBC News Classification
For this project, here are the Machine Algorithms that we used to successfully predict the category from its headline:
-
Logistic Regression Logistic Regression is a classification algorithm. It is used to forecast a binary outcome based on a number of independent variables.
-
Naive Bayes The Naive Bayes algorithm is a supervised learning method for classification issues that is based on the Bayes theorem. It is primarily employed in text categorization with an extensive training set.
-
Random Forest The supervised machine learning approach Random Forest grows and combines different decision trees to produce a "forest." The Random Forest model is built on the premise that different uncorrelated models (decision trees) perform noticeably better when combined than when used independently.
-
Linear SVC The Linear SVC (Support Vector Classifier) helps us by fitting our data, returning a "best fit" hyperplane that divides or categorizes your data. From there, after getting the hyperplane, you can then feed some features to your classifier to see what the "predicted" class is. This makes this specific algorithm rather suitable for our uses, though you can use this for many situations.
Building the Classifier
Loading the Dataset
To start things off, we will load our dataset using Pandas.
Output

Visualization of the Dataset
Now that we have loaded our dataset, let us get some insights. We need to find a way to generate ideas by looking at the dataset alone. Hence, we will use Seaborn to see the various plots from our dataset.
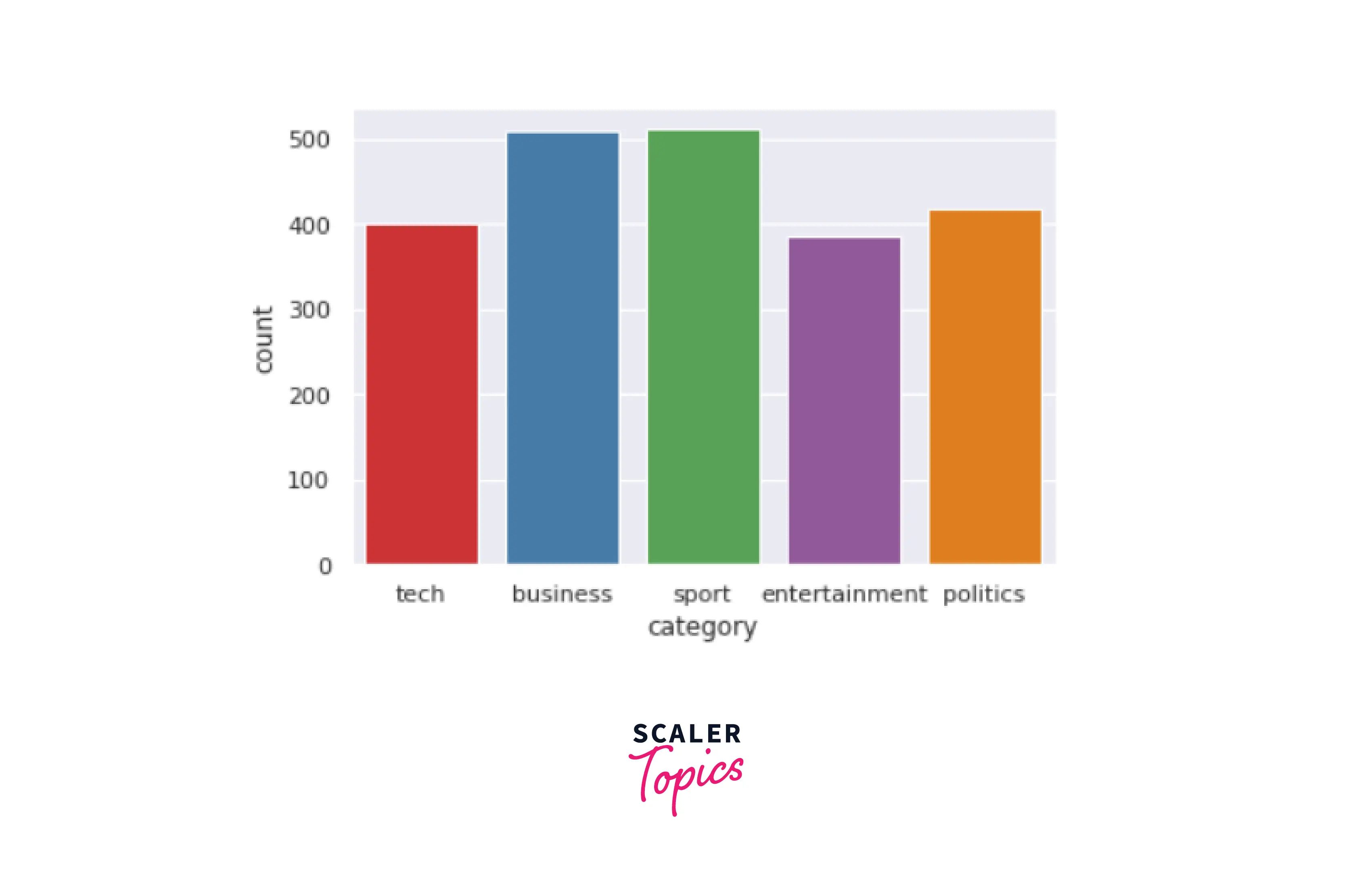
Firstly, let us check the total number of headlines using a simple bar plot.
Output
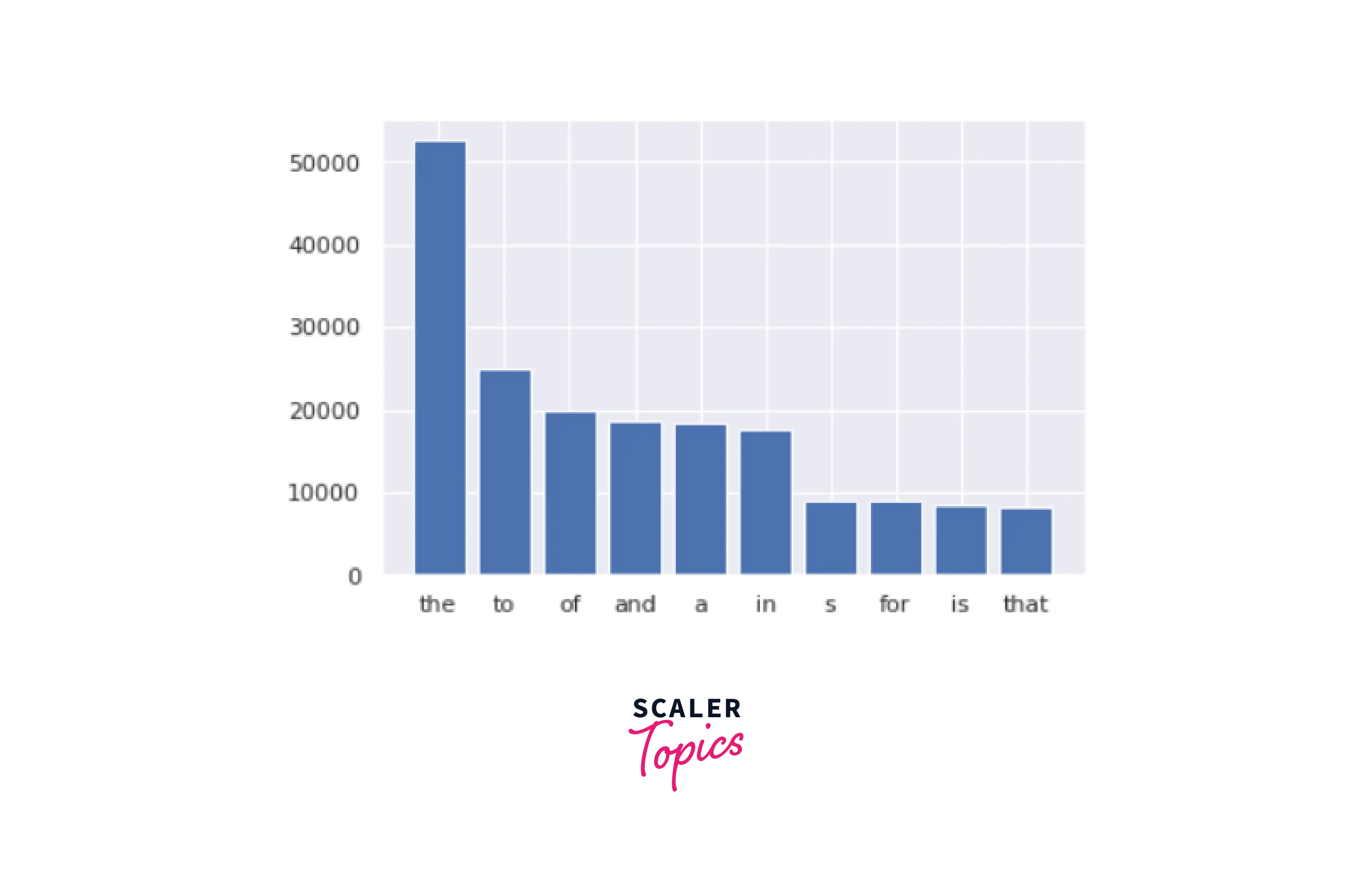
We will visualize the number of stop words present in our dataset:
Output
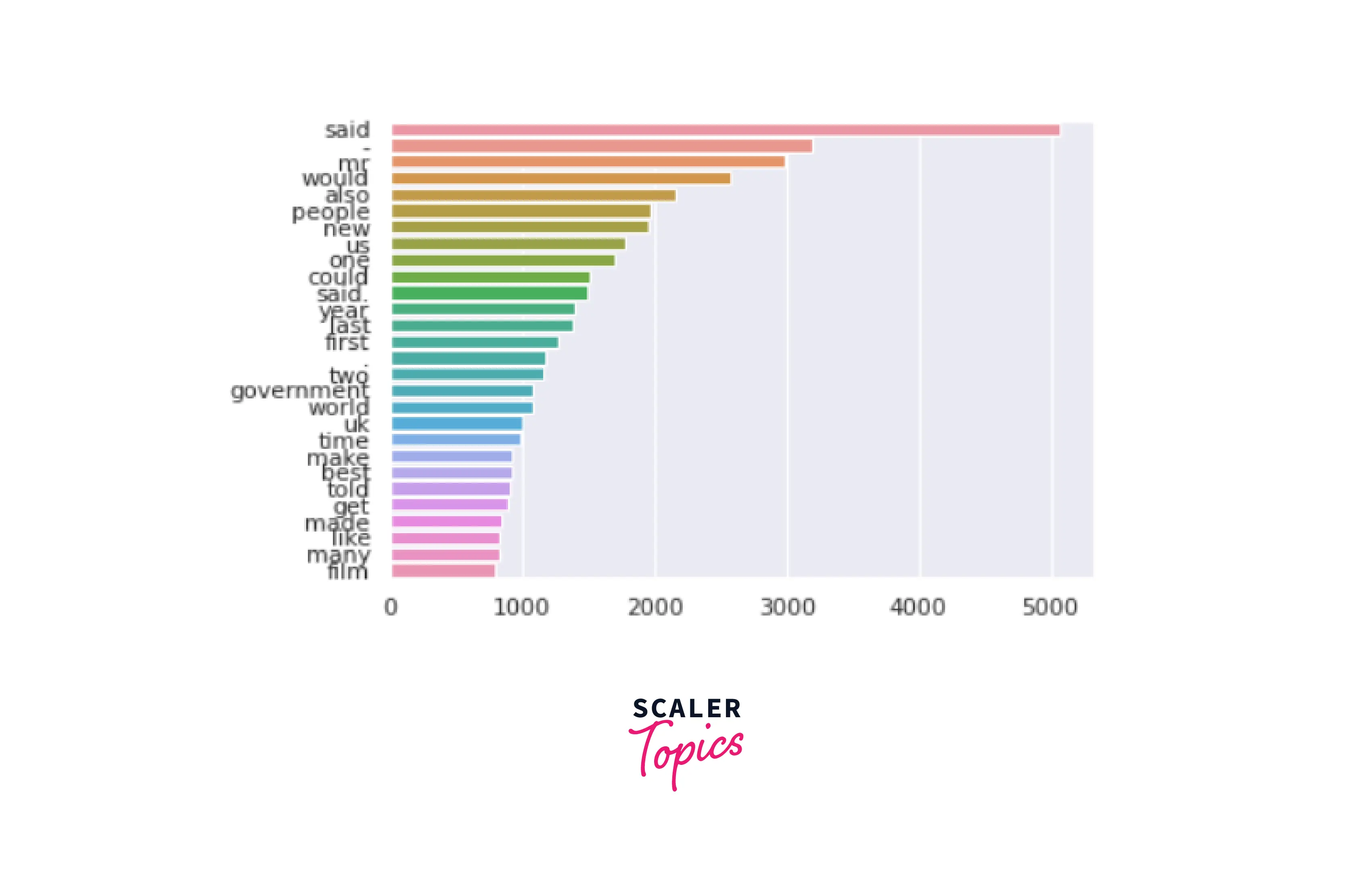
Using a rainbow plot, we will determine the most frequently occurring words in our dataset:
Output
To conclude, let us create a word cloud to visualize all the words in our dataset:
Output

Now that we have finished generating insights using visualization, let us move on to cleaning and preprocessing our dataset.
Data Preprocessing
Right now, our dataset is not ideal for model building. It consists of things like stop words, recurring words, punctuations, inconsistencies, etc., which will make our model under/overfit. Using basic techniques like tokenization, lemmatization, etc, we will be able to clean and preprocess our dataset.
- Lowering
We will make sure that our dataset is in lowercase, as it'll make it consistent throughout entirely.
-
Tokenization
Splitting paragraphs and sentences into smaller units so they are easily trained in Natural Language Processing is called tokenization. The NLTK module in Python has word_tokenize(), which helps us perform tokenization.
Output
-
Stop Word Removal
The words which are generally filtered out before processing a natural language are called stop words. These are actually the most common words in any language (like articles, prepositions, pronouns, conjunctions, etc) and do not add much information to the text.
Output
-
Stemming and Lemmatization
Stemming is the practice of removing the last few characters from a word, which frequently results in inaccurate spelling and meanings. By taking context into account, lemmatization reduces a term to its logical base form or lemma.
-
Encoding Data
The process of encoding meaningful text into number/vector representation to maintain the relationship between words and sentences is called Encoding Data.
In this project, we will encode our dataset using the TF-IDF Vectorizer in NLP.
Output
To conclude, we will map the numerical values to the various categories of our dataset:
Output
Model Training
Before moving on with model training, we will split our dataset into train and test using train_test_split() provided by sklearn.
To remove spaces, commas, exclamation, etc., we will use the CountVectorizer() function.
-
Logistic Regression
Output
-
Random Forest
Output
-
Naive Bayes
Output
-
Linear SVM (Support Vector Machine)
Output
Model Evaluation
Model Evaluation helps us validate our Machine Learning models to know which model performs best and which model needs improvement.
-
Logistic Regression Metrics
Output
-
Random Forest Metrics
Output
-
Naive Bayes Metrics
Output
-
Linear SVM Metrics
Output
Model Testing
According to our evaluation, all the models are performing exceptionally well. All of them have similar accuracy and precision score (97-98%)
To check if our Machine Learning models perform well with actual data, we will take some of the real-time data available on the BBC website and see what category they are in. Since we can use any of our models, we will go with Naive Bayes
Output
As we can see, our headline was from the FIFA World Cup. Our Naive Bayes model has successfully predicted it to be from the SPORTS category.
What is Next
Here are the next steps you can take to give this project your own spin!
- Web Implementation - We can use React or Flask to create a web interface for this ML project.
- Models - Apart from the standard ML models, you can use ensemble models and figure out the best model to work with.
Conclusion
- BBC News Classification is a project in which we create a classifier that can successfully predict any news article's category.
- The maximum accuracy we could have achieved was 98% using Naive Bayes.