Content Based Filtering in Machine Learning

Overview
As the name suggests, content-based filtering is a Machine Learning implementation that uses Content or features gathered in a system to provide similar recommendations. The most relevant information is fetched from the dataset based on user observations. The most common examples of this are Netflix, Myntra, Hulu, Hotstar, Instagram Explore, etc. For instance, if a user likes a show or a user adds a movie to a list on Netflix, similar suggestions pop up on the feed.
What Is Content-Based Filtering?
As mentioned earlier, Content based filtering is a recommendation algorithm to find similar suggestions. Here, every unique value in a dataset is assigned keywords or attributes which help them to be recognized. Then based on these patterns, the information about the user's likes and dislikes is saved, recommending relevant items.
Let us consider an example where the user is looking for hotels in Bandra, Mumbai, near the airport, where the nightly cost is 2000 Rs. Here the recommender system considers the keywords - Mumbai and Airport, and the features considered will be - distance from the airport and nightly cost.
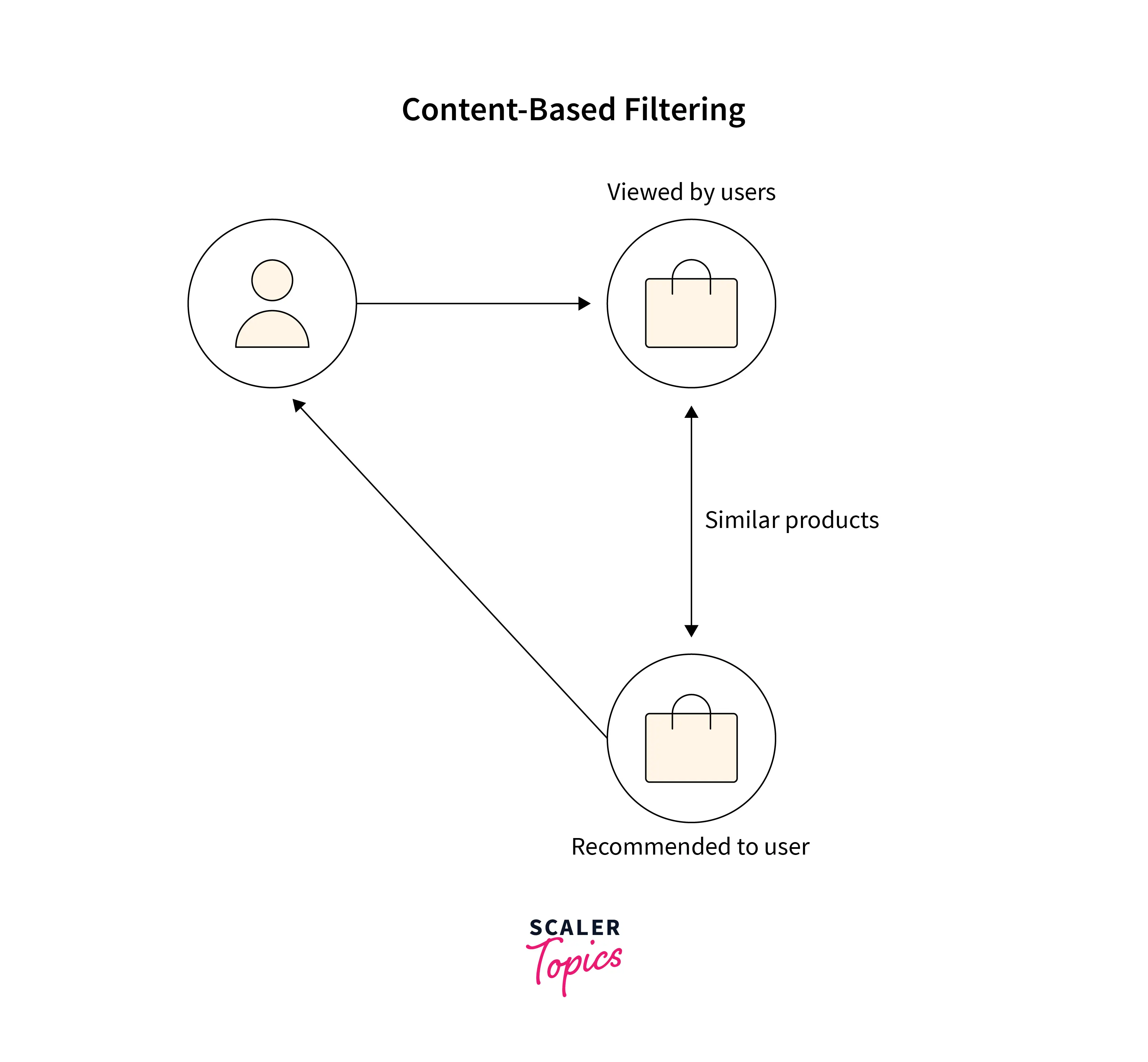
In a nutshell, Content based filtering captures attributes based on user patterns and then suggests similar products.
Why use Content-Based Filtering?
In the case of Content based filtering, user privacy is maintained. The recommendation system works on browsed, purchased, and past products. It does not need any other personal information or inputs from the user.
Since the system utilizes browsed products, the features to be looked for remain the same, thus making the results specific and user based. Thus every user will have a distinct set of results making the experience unique.
Considering the above points, we can also summarize that the results are unambiguous and candid. Moreover, since there is no input from the user and the sole parameter is the attributes, the output generated is transparent and relevant.
Another reason to work with Content based filtering is that it is relatively uncomplicated to use and even easier to build.
For example, Netflix's play something feature uses Content based filtering.
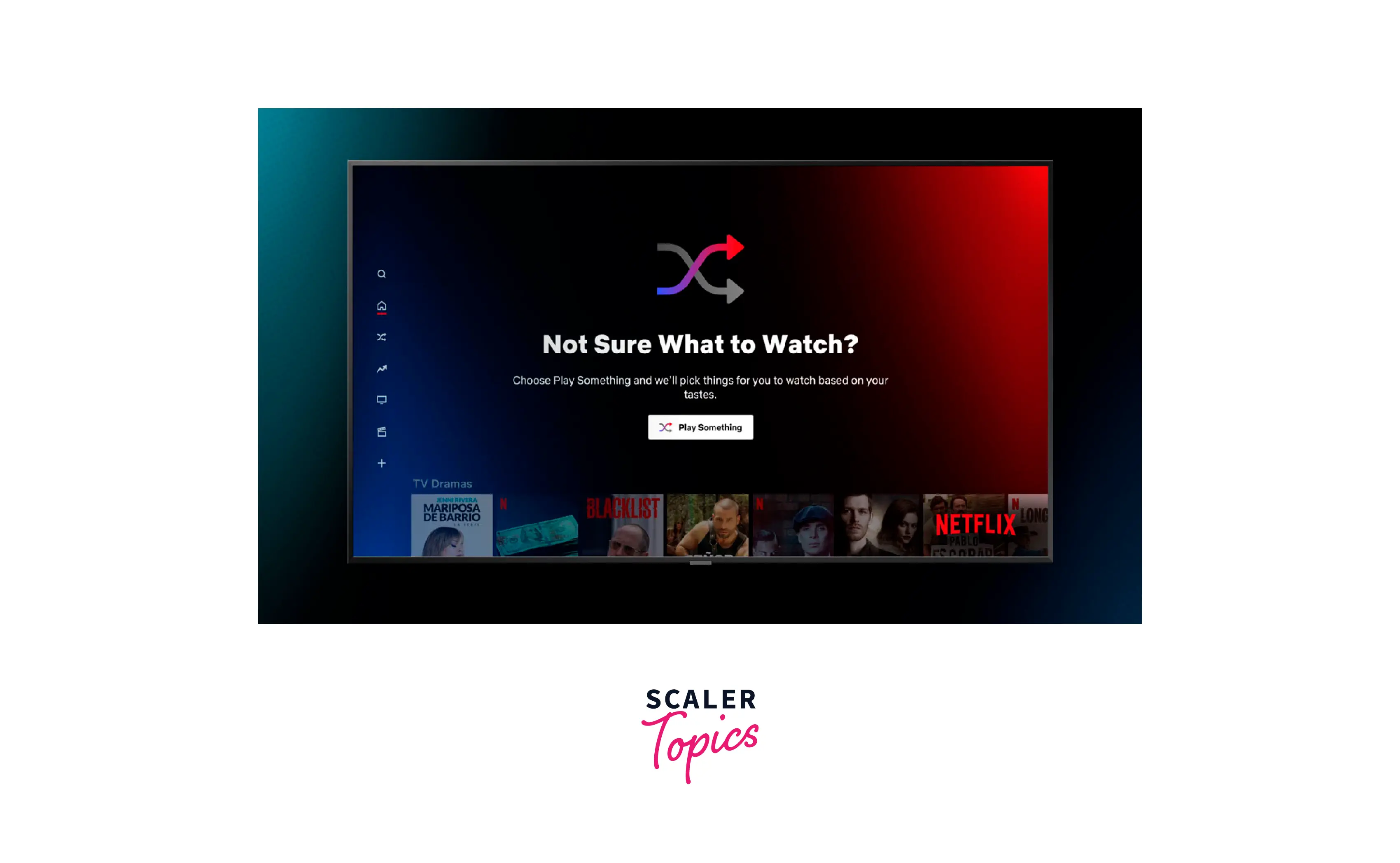
Method to Perform Content based Filtering
Let us now understand how Content based filtering works.
- Identification of attributes and features - Based on the search results, browses, and purchases, an inventory of attributes or features is compiled.
- Feature Matrix - Feature matrix maps products and their features and assigns them a numerical or a binary value based on the resemblance to the searched product. This sets up the basis for accepting the product for recommendation or rejecting it.
- Judging acceptance or rejection - Either the binary values assigned to the dot product vector decides if the product is to be considered. A higher value shows acceptance, and a more inferior one shows rejection.
Content Filtering Using Item Data
Item-based Content filtering assesses each attribute of every Item in the feature matrix and recommends items according to it. Pandas is a Python library that assists in calculating the matrix values for the recommendation.
In this case, the Item to be considered for recommendation is crossed with the product browsed based on the similarity of the two products. Next, based on the rating of the browsed product, the algorithm renders a rating for all the other items and foreshadows their rating. The items having a higher predicted rating are then suggested to the user.
The similarity between two products is calculated as the cosine of two items -
(A,B) = ABcos
The predicted rating is calculated like this -
Predicted Rating = ( User rating X similarity) (similarity)
Example For Item-Based Filtering
Let us consider an example where we have two users and two items. Based on user 1's experience, we determine if the product will be recommended.
Step 1: Matrix analysis
The below matrix depicts the rating given by Users 1 and 2 to items 1 and 2 out of 5.
| Item/User | User 1 | User 2 |
|---|---|---|
| 1 | 3 | 2 |
| 2 | 5 | 4 |
Step 2: Calculating similarity
Based on the above formula, we have,
S(I1I2) = [(3 * 2)+(5 * 4)] , where S(I1I2) is the similarity between I1 and I2. After calculating,
S(I1I2) = 0.997
Step 3: Calculating Rating
R(U1I2) = () 0.997
R(U1I2) = 2, where R(U1I2) is the rating for User 1 for Item 2.
The consequential rating is 2. In the case of large datasets, above average is recommended. Here, since we have only 2 values, we can choose not to recommend this Item.
Content Filtering Using User Data
In the earlier examples, we examined only the browsed products, purchased products, and purchased history. Now, if we add some more attributes, it will provide us with a lot more customized results, i.e., using user data. Building profiles or accounts is one way to save data that can later be used.
More importance is given to the attributes that are common in several items rather than to those that are not. The fact that not all of an object's attributes are identical to the user helps determine its level of significance. Since user reviews are essential when assessing items, websites that provide recommendations often request that users rate their products.
The only liability of this method is the loss of data privacy in exchange for accurate results.
In short, Content filtering using user data takes in suitable inputs or uses saved inputs to produce results.
Example for User Data Based Filtering
Consider another example of browsing clothes, specifically a white tennis skirt.
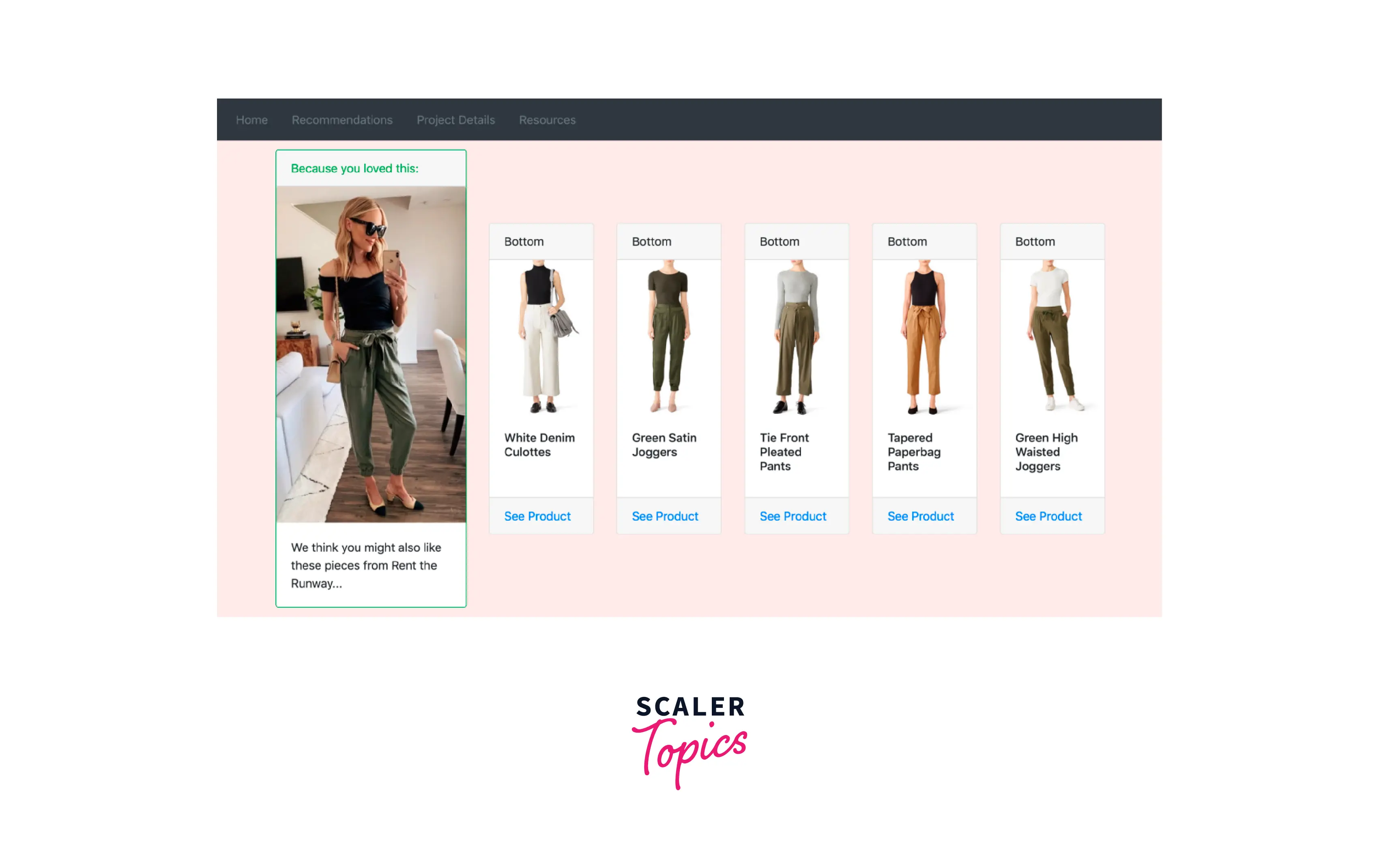
Here the attributes are - white and skirt, and the keyword is tennis. The search is narrowed down further when we add user data, like size, address, or budget, to this equation. Such as, only the specific size is considered, and the rest are scrapped. In terms of address, only the products available in and around the location are revealed.
Thus, the results, in this case, are precise and relevant.
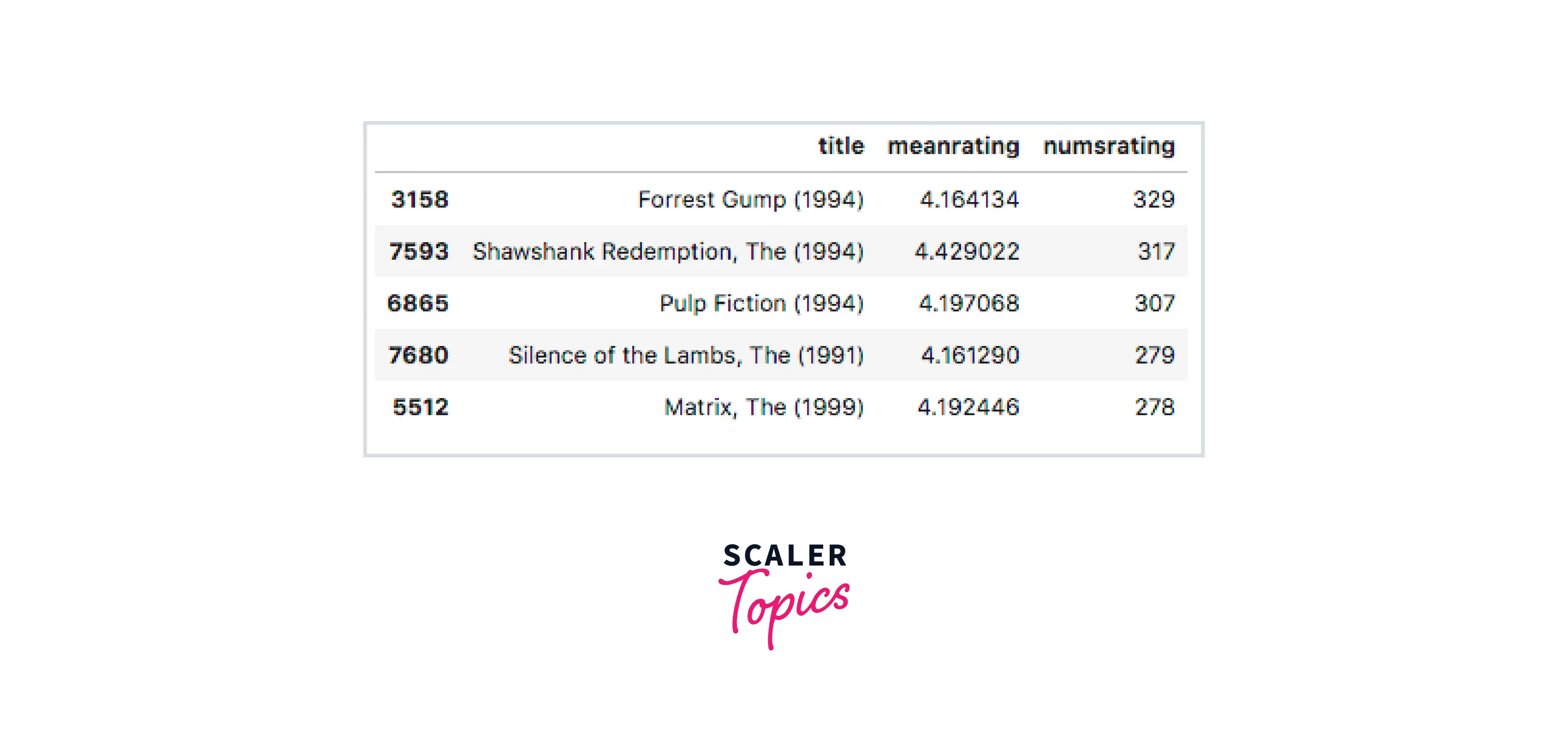
Understanding User Based Filtering with Code
Output -
Output -
Output -
Output -
Output -
Output -
Output -
Output -
Output -
Output -
Output -
Output -
Output -
Output -
Output -
Output -
Content-based Filtering Advantages & Disadvantages
Every method we use has some merits and demerits.
Advantages-
- Content based filtering is easy to use.
- In most cases, it leans on user rating and not user data unless specified.
- It provides accurate results to each distinct user.
- When a bunch of products belonging to a single type are considered, it is the most suitable algorithm (like recommending Horror Movies).
- The system understands the underlying features on its own. Thus it does not require any intervention or input.
Disadvantages-
- Since the products are pretty similar to each other, thus, in small datasets, there is not a diversity of products making the result redundant.
- When adding new products, they need to be classified, which can be a tedious task.
- As mentioned earlier, we need to calculate the product of the items to find similarities between them. This method can quickly fail if the values in the dataset are missing.
Content-Based Filtering vs. Collaborative Filtering
Collaborative filtering makes recommendations by simultaneously comparing similarities between users and items, resolving some of the limitations of content-based filtering.
The features of the objects do not require to be specified for collaborative filtering. A feature vector or embedding represents each user and Item. It generates embedding on its own for both users and items. Users and items are also both embedded in the same embedding space.
Now that we know how Collaborative filtering works, we can compare the aspects of Content-Based and Collaborative filtering.
- User Data or inputs - Instead of relying on user interactions and feedback, a content-based approach needs a great deal of information on the features of the objects. On the other hand, collaborative filtering only requires the user's prior preference for a selection of items to recommend, as it is based on prior data.
- Diversity of Recommendations - Although the machine learning system might not be informed of the user's interest in a particular item, the collaborative filtering model may potentially suggest it because other users who share the user's interests are also interested in it. On the other hand, a content-based model is limited in its ability to build on the user's existing interests because it can only make suggestions based on the user's interests.
- Expertise - Collaborative filtering reduces the need for subject matter expertise because the hidden layers are automatically acquired. At the same time, a content-based approach requires substantial technical knowledge because the feature representation of the items is hand-engineered.
- Parameters - For item suggestions, the collaborative algorithm simply evaluates user behaviour, meanwhile for content based filtering, both the user and the item's attributes must always be identified.
Conclusion
- When making suggestions, Content-based filtering analyzes features of similar products and user information collected over time.
- To provide insights to a particular user, collaborative filtering uses similar users' preferences.
- When we have an extensive database of similar products, we use Content-based filtering, and when we require diversified results, we use collaborative filtering.