Feature Selection in Machine Learning
Overview
Feature selection in machine learning refers to selecting essential features from all features and discarding the useless ones. Having redundant variables present in data reduces the model's generalization capability and may also reduce the overall accuracy of a classifier. Moreover, having too many redundant features increases the training time of the model as well. Hence it is essential to identify and select the most appropriate features from the data and remove the irrelevant or less important features. In this article, we will learn about feature selection in machine learning in detail.
What is Feature Selection?
Feature selection in machine learning is a pre-processing step that is performed before building the model. Training a machine learning model with redundant features increases training time and reduces the model's generalization capabilities. Feature selection in machine learning helps in mitigating this impact by discarding the less essential features. Feature selection in machine learning can be performed using both supervised and unsupervised machine learning algorithms. An unsupervised feature selection algorithm does not use the target variable while performing feature selection in machine learning, whereas a supervised feature selection algorithm uses the target variable to achieve the same.
Why Feature Selection?
- Feature selection in machine learning helps in selecting important features and removing useless ones.
- Removing less important features improves the model's generalization capabilities. The model can focus on only vital features and not try to learn misleading patterns in less important features.
- Feature selection in machine learning helps in improving the training time of the model.
- Sometimes, It helps in reducing the performance of the model.
- In addition, feature selection in machine learning makes code building, debugging, maintenance, and understanding easier.
Feature Selection Methods/Techniques
There are two types of feature selection techniques in Machine Learning -
Supervised Feature Selection technique considers the target variable and can be used for the labeled dataset.
Unsupervised Feature Selection technique ignores the target variable and can be used for the unlabelled dataset. Let's see different methods for each of these categories.
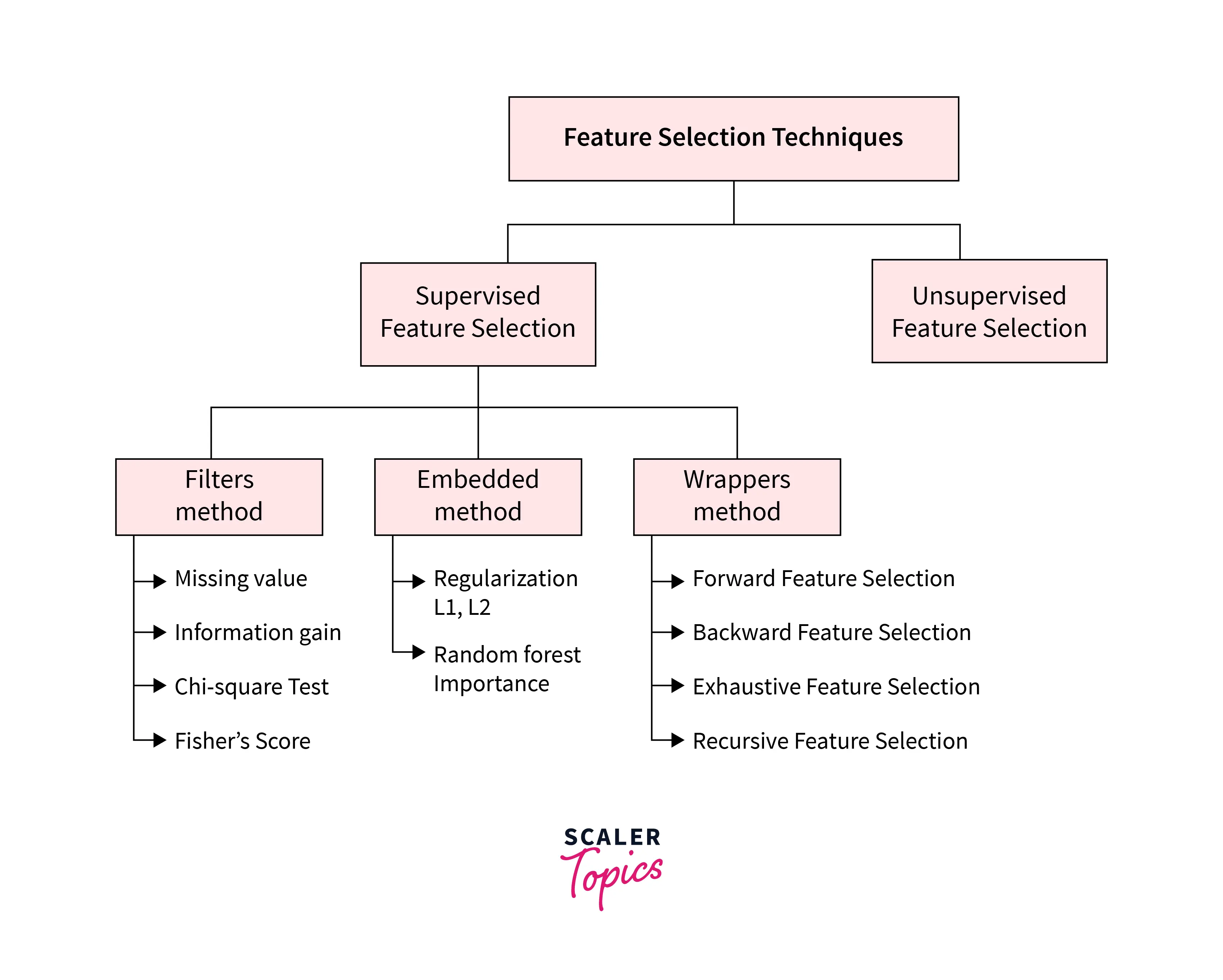
Supervised Feature Selection technique
As shown in the figure above, supervised feature selection in machine learning can be further divided into three categories.
1. Filters Method:
In the Filter Method, features are selected based on statistics measures. The filter method filters out the model's irrelevant features and redundant columns by using different metrics through ranking. Filter methods need low computational time and do not overfit the data. Some standard techniques of Filter methods are as follows:
- Missing Value: Feature having the highest proportion of missing value can be dropped.
- Information Gain: Calculating the information gain of each variable to the target variable helps to discard useless features.
- Chi-square Test: The chi-square value is calculated between each feature and the target variable, and the desired number of features with the best chi-square value is selected.
- Fisher's Score: Fisher's score returns the rank of the variable on the Fisher's criteria in descending order. Then we can select the variables with a significant fisher score.
2. Embedded Method: These iterative methods optimally find the essential features in a particular iteration. Some techniques of embedded methods are:
- Regularization: As we know, regularization adds a penalty term to different parameters. Features with almost zero coefficients can be discarded from the dataset. L1 Regularization (Lasso Regularization) or Elastic Nets (L1 and L2 regularization) are some of these regularization techniques.
- Random Forest Importance: Random Forest is a bagging algorithm that aggregates a different number of decision trees. It ranks the nodes by their performance or decreases in the Gini impurity over all the trees. Nodes are arranged as per the impurity values, and thus it allows the pruning of trees below a specific node. The leftover nodes create a subset of the most important features.
3. Wrapper Methods
In wrapper methodology, feature selection in Machine Learning is considered a search problem. Based on the model's output, features are added or subtracted, and the model has trained again with this feature set. Some popular techniques of wrapper methods are:
- Forward selection: Forward selection begins with an empty set of features. After each iteration, it keeps adding on a feature and evaluates the performance to check whether it is improving the performance or not. The process continues until adding a new feature does not enhance the model's performance.
- Backward elimination: Backward elimination is also an iterative approach. It is also called as opposite of forward selection. This technique starts with all the features and keeps removing the less significant ones. This elimination process continues until removing the features does not improve the model's performance.
- Exhaustive Feature Selection: Exhaustive feature selection in machine learning tries each possible feature combination and returns the best-performing feature set.
- Recursive Feature Elimination: It is a recursive greedy optimization approach where features are selected by recursively taking a smaller and smaller subset of features. Now, an estimator is trained with each set of features, and the importance of each feature is determined to choose the best set of features discarding the redundant ones.
Unsupervised Feature Selection technique
All statistical learning-based techniques are unsupervised in nature. The statistical test is performed for each feature, and a threshold is fixed. Features that violate that threshold are discarded here. Here we will discuss two correlation tests.
- Correlation Test: This test evaluates the extent to which variables are associated with one another. Correlation tests can be applied for both continuous and discrete variables. Pearson correlation coefficient is one of the most widely used metrics for correlation tests.
- Pearson Correlation Coefficient It is used to measure the linear correlation between 2 variables. It is denoted by
.
Here, is the number of pairs of scores.
is the sum of the products of paired scores.
is the sum of x scores.
is the sum of y scores.
is the sum of squared x scores.
is the sum of squared y scores.
One can easily verify that its values lie between -1 and 1. If the value of r is 0, there is no relationship between variables X and Y. If the value of r is between 0 and 1, there is a positive relation between X and Y, and their strength increases from 0 to 1. Positive relation means if X's value increases, Y's value also increases. If the value of r is between -1 and 0, there is a negative relation between X and Y. It means if the value of X increases, the value of Y decreases.
How to choose a Feature Selection Method?
For feature selection in machine learning for a different scenario, we have a different technique. The below figure summarises this information.
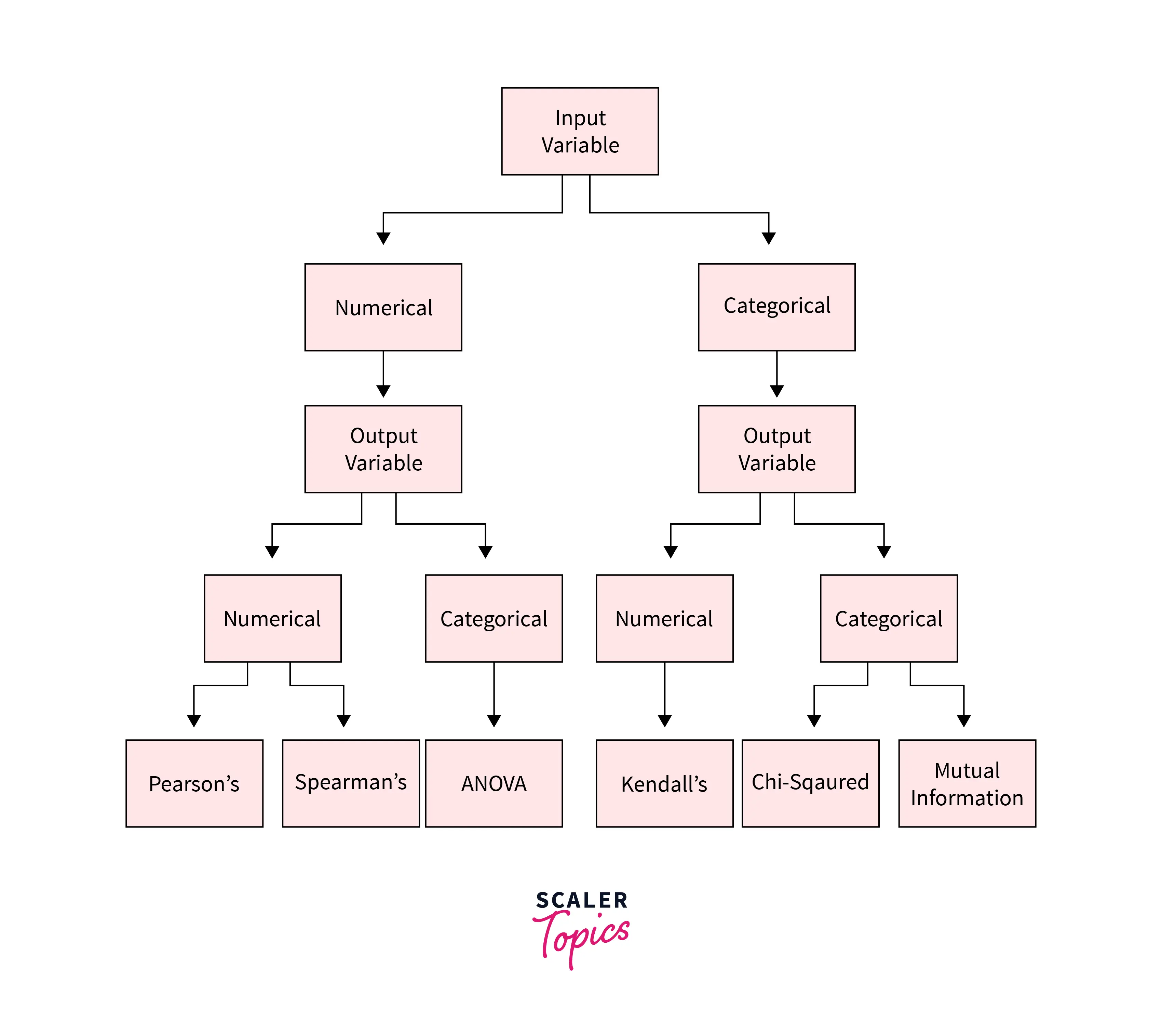
Four situations can arise based on the nature of the feature and the target variable.
- Numerical Feature, Numerical Target: In this scenario, the standard method is the Correlation coefficient. Pearson's correlation coefficient (For linear Correlation). Spearman's rank coefficient (for nonlinear Correlation).
- Numerical Feature, Categorical Target: Correlation-based techniques should also be used here but with categorical output. ANOVA correlation coefficient (linear). Kendall's rank coefficient (nonlinear).
- Categorical Feature, Numerical Target: It is another example of a regression problem. We can use the same measures presented in the above case.
- Categorical Feature, Categorical Target: Chi-Squared Test is a standard method in this scenario. One can also use Information gain.
Feature Selection With Python
Below we will present the feature selection in machine learning code using the sequential feature selection method. This algorithm adds (forward selection) or removes (backward selection) features to form a feature subset greedily. At each stage, this estimator chooses the best feature to add or remove based on the cross-validation score of an estimator.
Output:
The code above prints the shape of X, which is: (150,4)
Output:
As we choose to reduce the number of features to 3, the above code snippet will generate the transformed shape of X, i.e. (150,3).
Conclusion
- In this article, we have covered the definition of feature selection in machine learning, why it is crucial, and different feature selection methods, including supervised and unsupervised methods.
- We have also discussed choosing a feature selection in machine learning from many available ways.
- The article ends after presenting a python code for feature selection in machine learning.
- Here, we haven't covered feature extraction techniques. That will be covered in another article.