Hierarchical Clustering in Machine Learning
Overview
The world of machine learning has primarily two concepts: supervised and supervised learning. Unlike supervised learning, we train our machine with unlabelled data in unsupervised learning. The unsupervised learning algorithms discover hidden patterns and data groupings without any prior information. Hierarchical clustering is an unsupervised learning algorithm.
Introduction
What is Clustering?
In this process, we group similar data points such that the points that appear to be in the same group are closer than the others. The group of similar data points is called a cluster.
What is Hierarchical Clustering?
The hierarchical clustering method works by grouping data into a tree of clusters. The algorithm builds clusters by calculating the dissimilarities between data. The algorithm starts by treating every data point as different clusters and then repeats the two following steps:-
- It recognizes the two clusters that are closest to each other.
- Merges the two closest clusters.
These steps are repeated till we get all the clusters grouped. Hence, in this process, we produce a hierarchical series of nested clusters that are graphically represented through dendrograms. This clustering algorithm is divided into two types:-
- Agglomerative
- Divisive
Why Hierarchical Clustering?
Unlike the other popular clustering algorithms, such as the Kmeans, hierarchical clustering does not require the number of clusters to be specified before training. This algorithm also does not try to create clusters of the same size. It is also easy to understand and implement.
Agglomerative Hierarchical Algorithm
This clustering algorithm is analogous to the hierarchical clustering algorithm. It follows a bottom-up approach to group the data points into clusters. Each data point is treated as a different cluster, and we merge the nearest pair of clusters. It does this until all the clusters are merged into a single cluster that contains all the datasets. We don't need the number of clusters to be pre-defined.
Divisive Clustering Algorithm
This algorithm is the exact opposite of the hierarchical clustering algorithm. It is used less in real-world problems. In this process, we assume all the data points to be in a single cluster, and in each iteration, we separate the data points from the cluster which are not similar. This method follows a top-down approach, and in the end, we are left with n clusters.
How Agglomerative Hierarchical Clustering Works?
The agglomerative hierarchical clustering involves the following steps:-
- Each data point is treated as a separate cluster, so if there are n data points in the data sets, there will be n clusters at the beginning. Here we calculate the proximity of each point.
- Next, we merge two data points that are closest to each other. Hence we are left with n-1 clusters.
- The above step is repeated by calculating the proximity of clusters and combining the closest one.
- The process stops when we have a single cluster available.
- Dendrograms are then used to divide the single big cluster into multiple clusters depending upon the problem.
Python Implementation of Agglomerative Hierarchical Clustering
For this example, we are going to use the sklearn library's AgglomerativeClustering.
Output:-
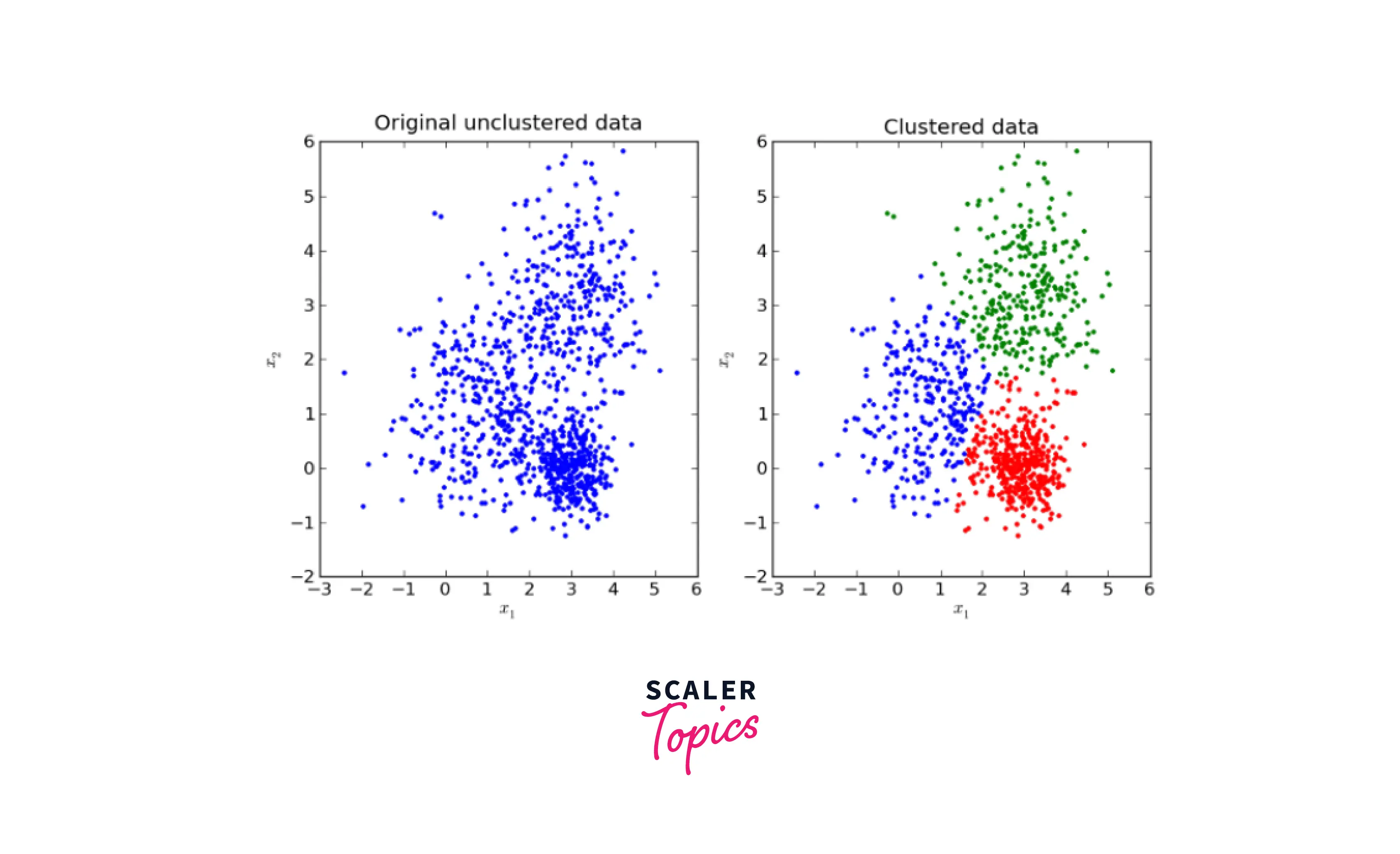
 Since we have set the n_clusters as 3 as the parameter, there are three different colored data points as three different clusters.
Since we have set the n_clusters as 3 as the parameter, there are three different colored data points as three different clusters.
Role of Dendrograms in Agglomerative Hierarchical Clustering
The role of the dendrogram starts once the biggest cluster is formed. A dendrogram splits the big cluster into clusters of related data points as required in the problem.
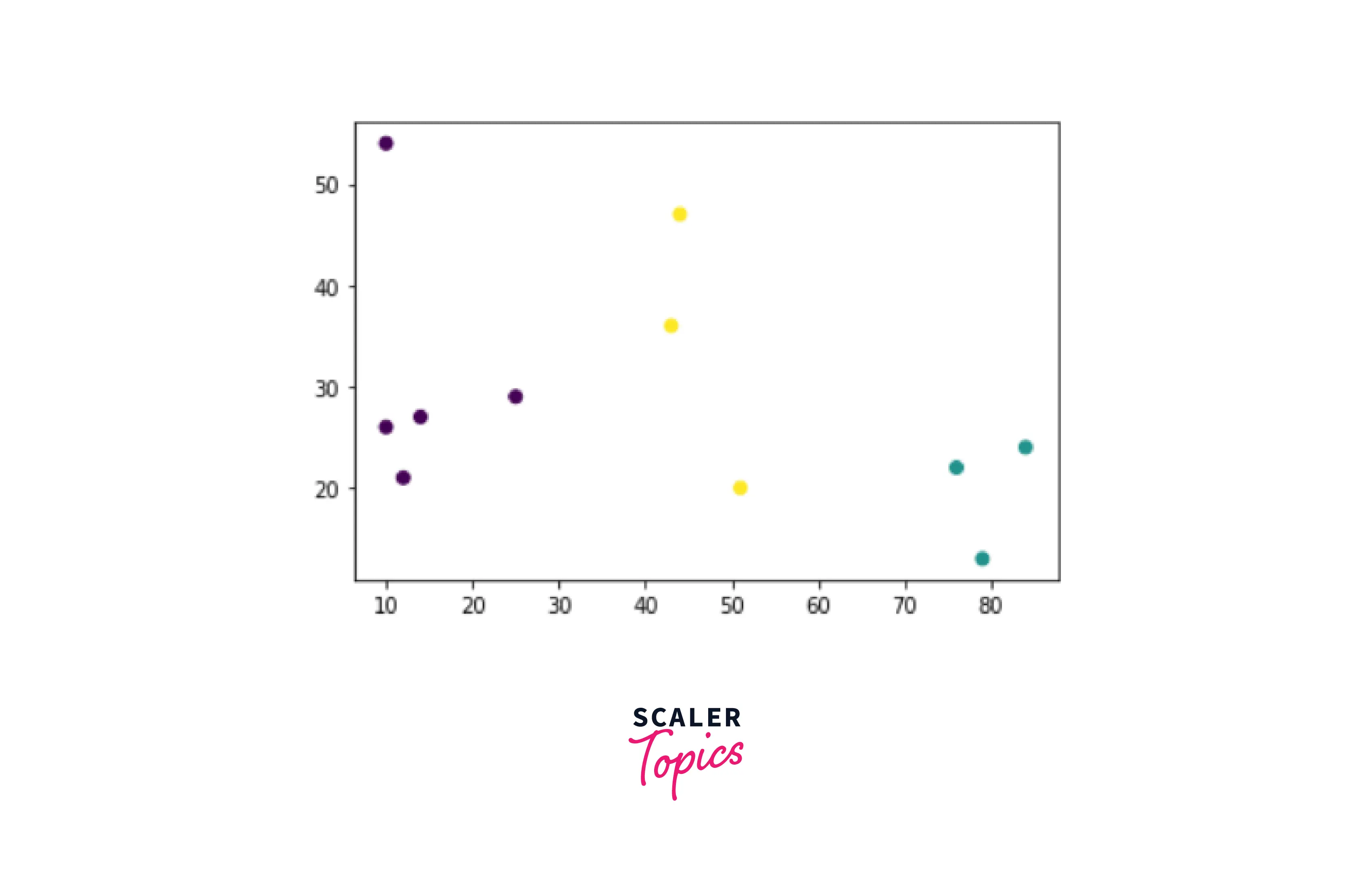
Let's take an example:- First, we take some random data points and plot them.
Output:-
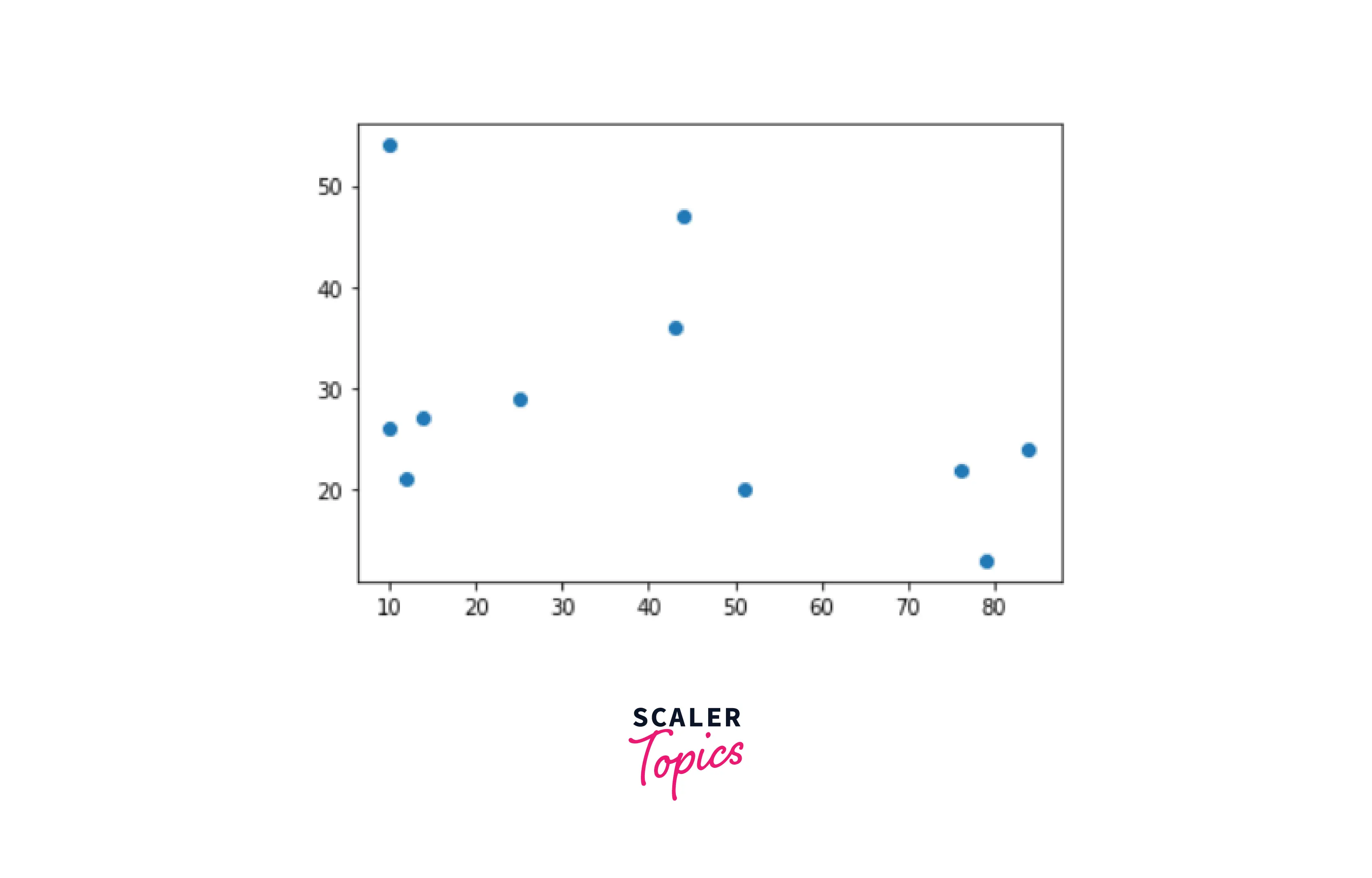
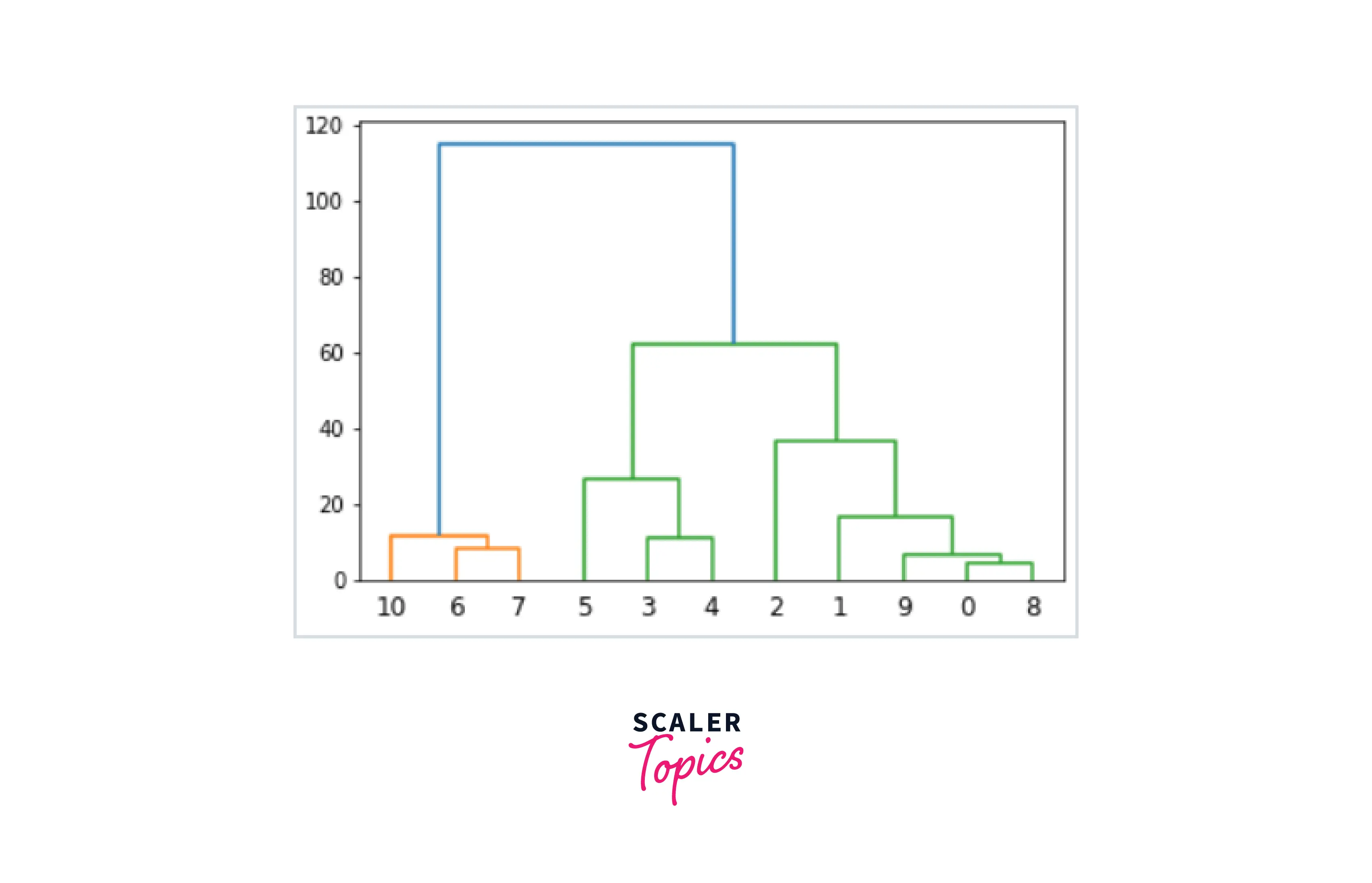
From the above image, we can see three distinct clusters, but in real-life problems, there can be hundreds of different clusters. Hence there is a need for dendrograms which we implement with the help of the `Scipy library.
Output:-
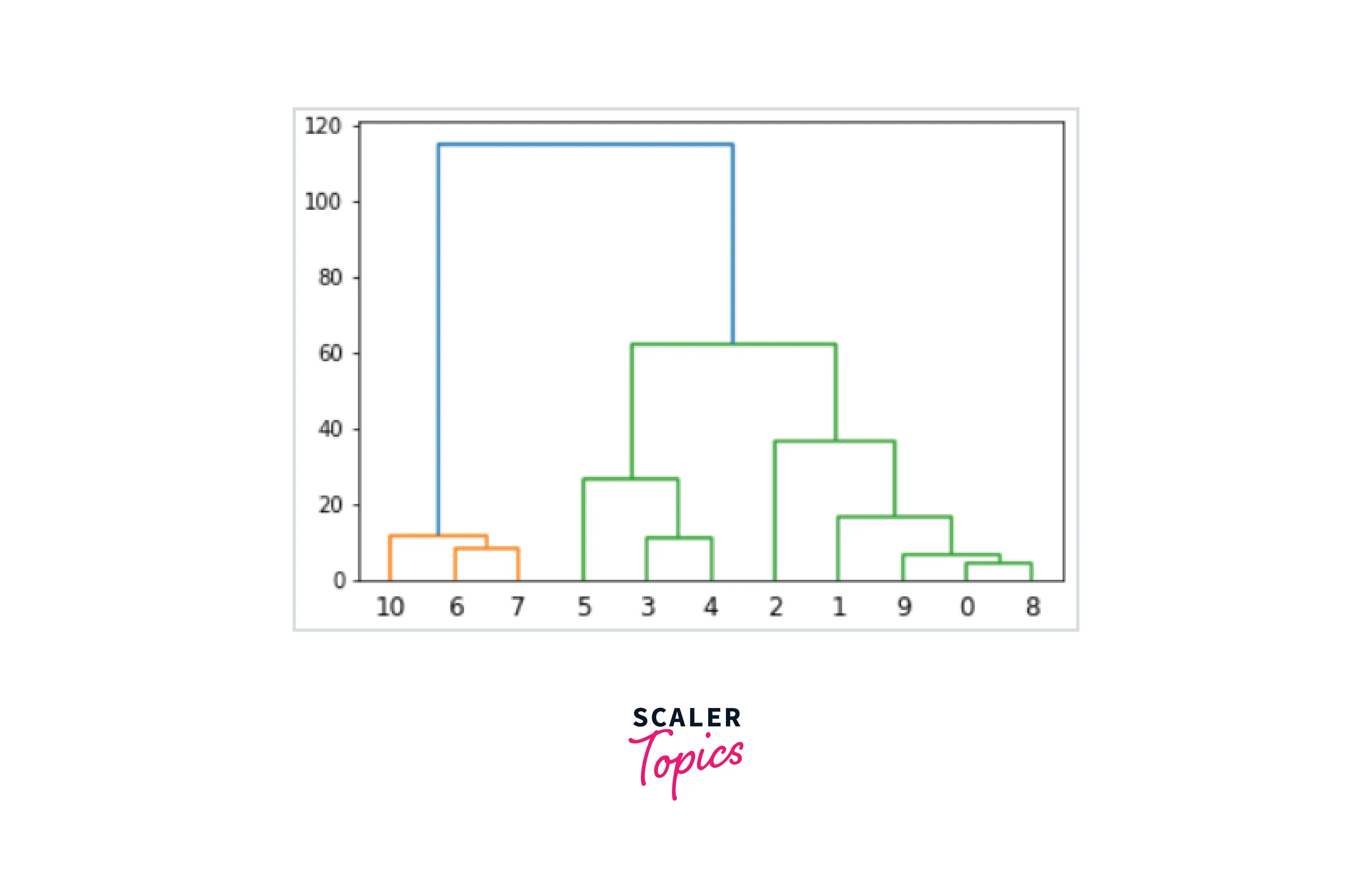 Now, we take the longest vertical line and draw a line across it, and as the horizontal line cuts the blue line once and the green line twice, the number of clusters will be 3.
Now, we take the longest vertical line and draw a line across it, and as the horizontal line cuts the blue line once and the green line twice, the number of clusters will be 3.
Then we predict our clusters through the fit_predict method of the sklearn library's AgglomerativeClustering as shown before.
Conclusion
The key takeaways from this article are:-
- Hierarchical clustering is an unsupervised machine learning algorithm.
- The hierarchical clustering method works by grouping data into a tree of clusters.
- The algorithm is of two types: Agglomerative and Divisive.
- We use the sklearn library's AgglomerativeClustering for implementing agglomerative hierarchical clustering.
- In Agglomerative Clustering, dendrograms are used to divide the single big cluster into multiple clusters depending upon the problem.