Recommender System Using MovieLens
Overview
Have you ever wondered how Hulu or Netflix recommends new movies based on the watch history?
These suggestions or recommendations are made by a recommendation system. This model makes learns patterns from your watch history and uses those patterns to make new suggestions.
What are We Building?
We are building a movie recommendation system that takes in the user and movie ids and generates probable movie preferences for each user. We are using two types of filtering techniques for this purpose: collaboration and content. We will discuss them at a later stage.
Pre-requisites
These are the algorithms that one must know before building the project.
- SVD(): Singular Value Decomposition (SVD) is a method from linear algebra that has been generally used as a dimensionality reduction technique in machine learning. For example, in recommendation systems, SVD() is used for matrix factorization. It finds factors of matrices from the factorization of a high-level (user-item-rating) matrix.
- TF-IDF: TF-IDF, or term frequency-inverse document frequency, is a figure that expresses the statistical importance of any given word to the document collection as a whole. TF-IDF is calculated by multiplying term frequency and inverse document frequency.
How Are We Building This?
- After playing around with the dataset and getting the gist of it, we are going to apply collaborative and content-filtering techniques to it.
- While collaborative filtering, we are going to apply SVD() algorithm to the dataset to get our recommendations.
- For getting our recommendations using content filtering, we are going to use TF-IDF.
Final Output
The final output will be a table that will contain the id of the user, the id of the movie and the corresponding movie name recommended by the model for the user.
Requirements
Python Libraries :-
- Python.
- Pandas.
- scikit-learn.
- Surprise.
Buliding the Classifier
Load the dataset
We choose the awesome Movielens dataset for the purpose of movie recommendation.
The Dataset at A Glance
- movies.csv: It is a tabulated form of the description of the movies: title, tagline, and description. The table contains 21 distinct features and is meant to be used according to the model's needs.
- ratings_small.csv: A table that records all the users’ rating behaviors and the ratings they provided. It also includes a time stamp when they posted the rates.
- links.csv: A table that records each movie’s unique ID on two respective movie databases: IMDB and TMDB.
Code:-
Output:-

Analyze and Visualize the Dataset
Let's play around with the dataset and do some exploratory data analysis.
The total number of movies in the dataset is:-
Output:-
Let's classify the movies based on their genres:-
Output:-
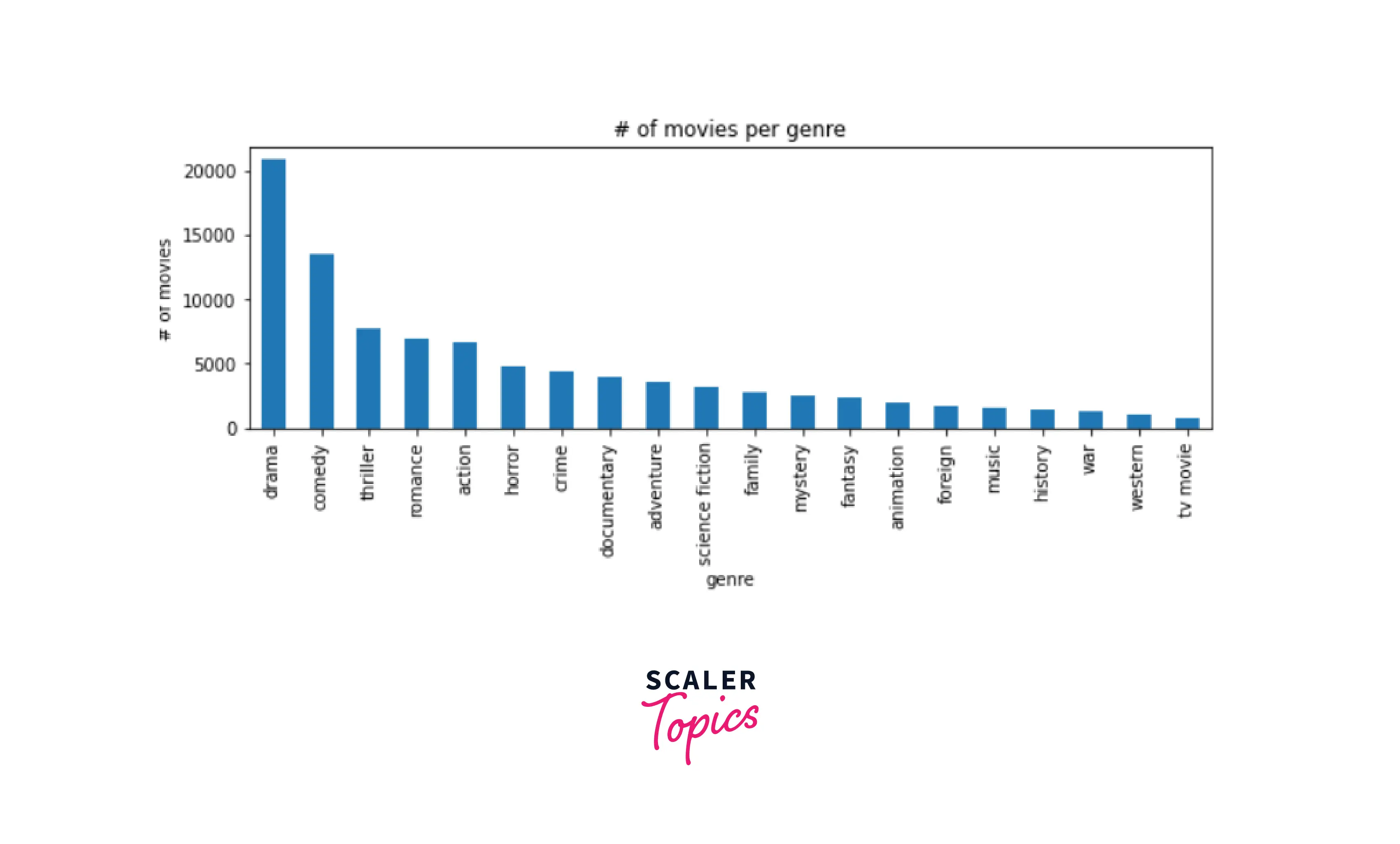
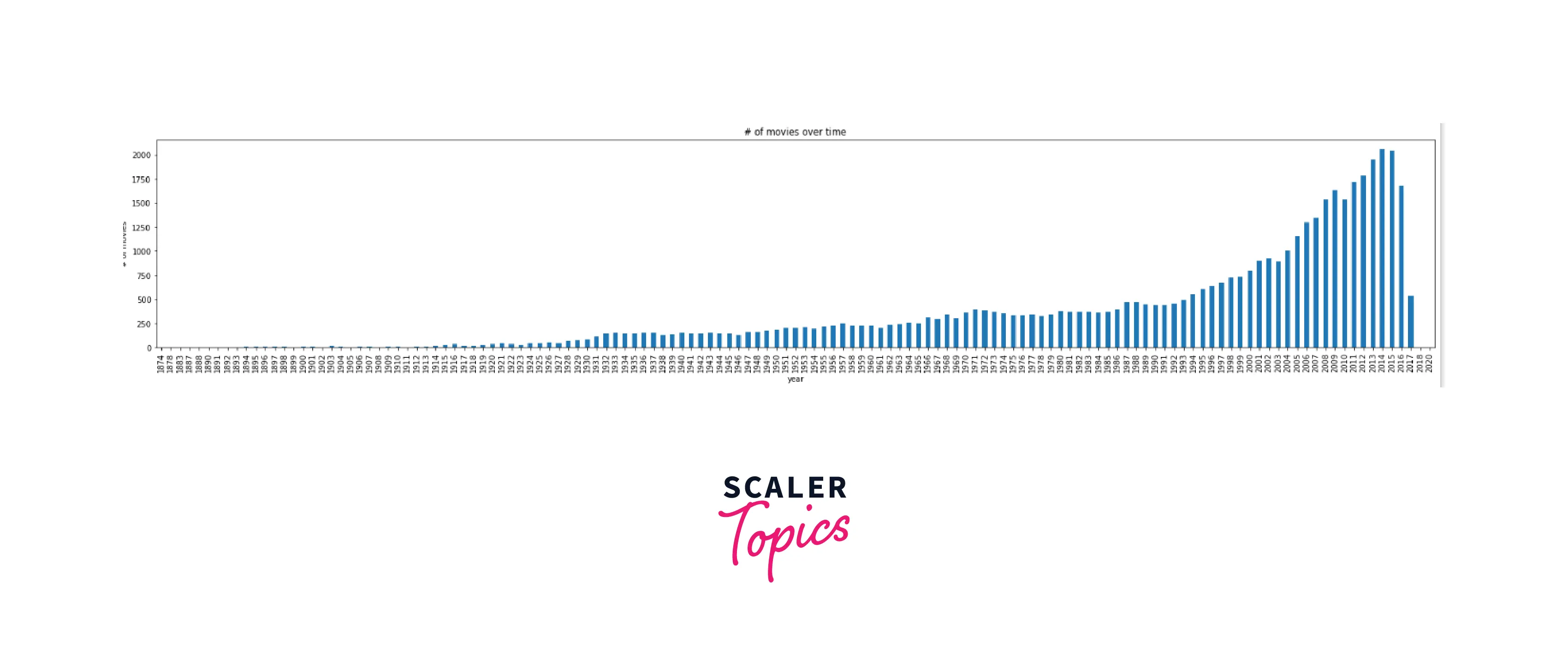
Now, let's move on to see in which year how many movies were released:-
Output:-
Finally, we are going to see what are the most popular movies in the dataset:-
Output:-
Now let's play around with the ratings_small dataset
| index | userID | movieId | rating | timestamp |
|---|---|---|---|---|
| 0 | 1 | 31 | 2.5 | 1260759144 |
| 1 | 1 | 1029 | 3.0 | 1260759179 |
| 2 | 1 | 1061 | 3.0 | 1260759182 |
| 3 | 1 | 1129 | 2.0 | 1260759185 |
| 4 | 1 | 1172 | 4.0 | 1260759205 |
As you can see, the dataset contains the userIDs, movieIDs, ratings and timestamps.
The rating distribution looks like this:-
Output:-
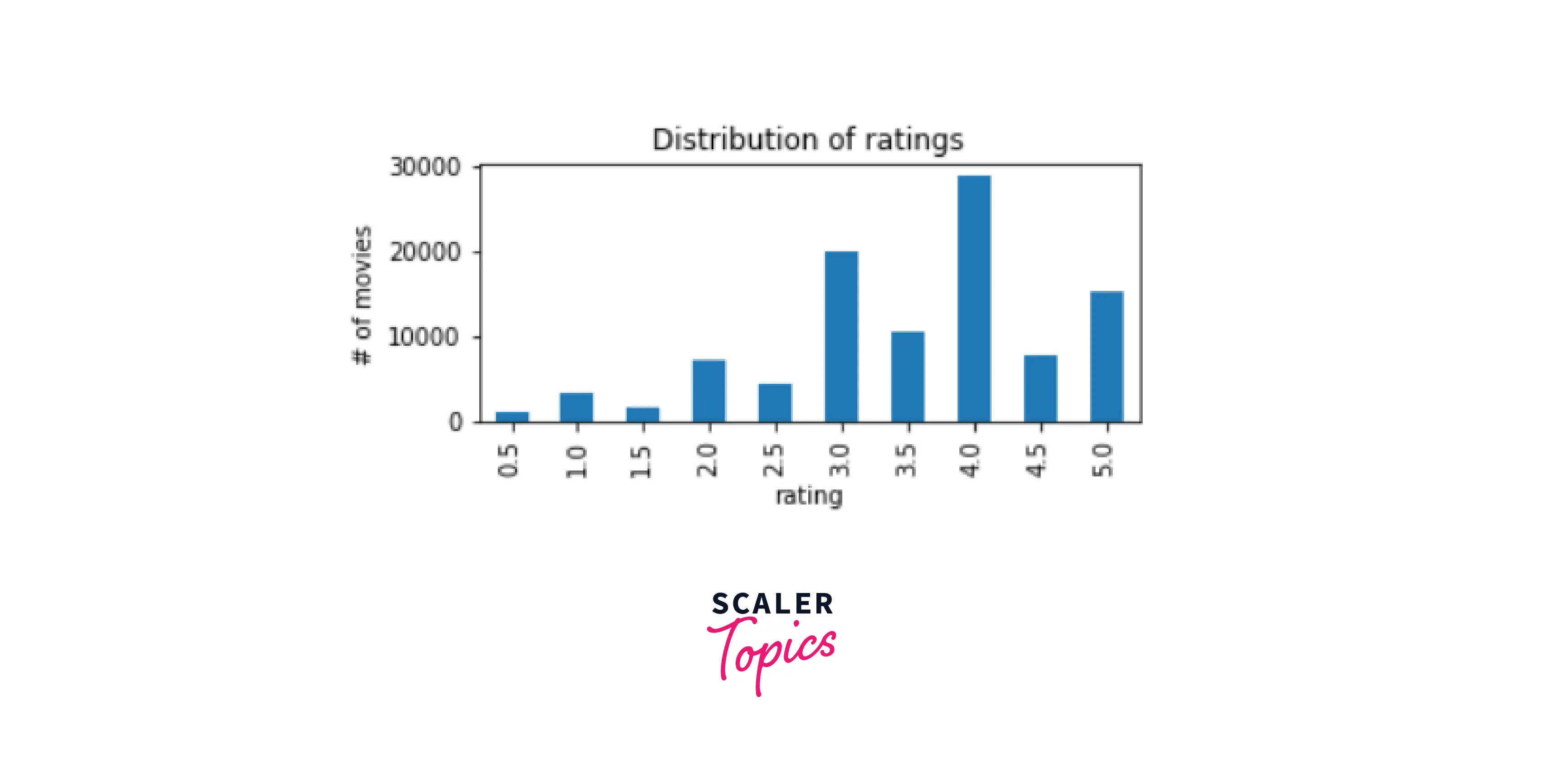
The most active users are:-
Output:-
The most rated movies are:-
Output:-
Collaborative Filtering
This method helps the model to learn the connections/similarity between users so that it can generate the best recommendation options based on user's choices, preferences, or tastes.
Collaborative filtering signifies how much a user has preferred a movie in the past.
To implement this technique, we use the Python Library Surprise. It provides a set of built-in algorithms commonly used in recommendation system development.
Code Implementation:-
We are going to compare 5 different algorithms: SVD(), KNNBasic(), NMF(), CoClustering(), SlopeOne().
Let's plot the performance of each algorithm:-
Output:-
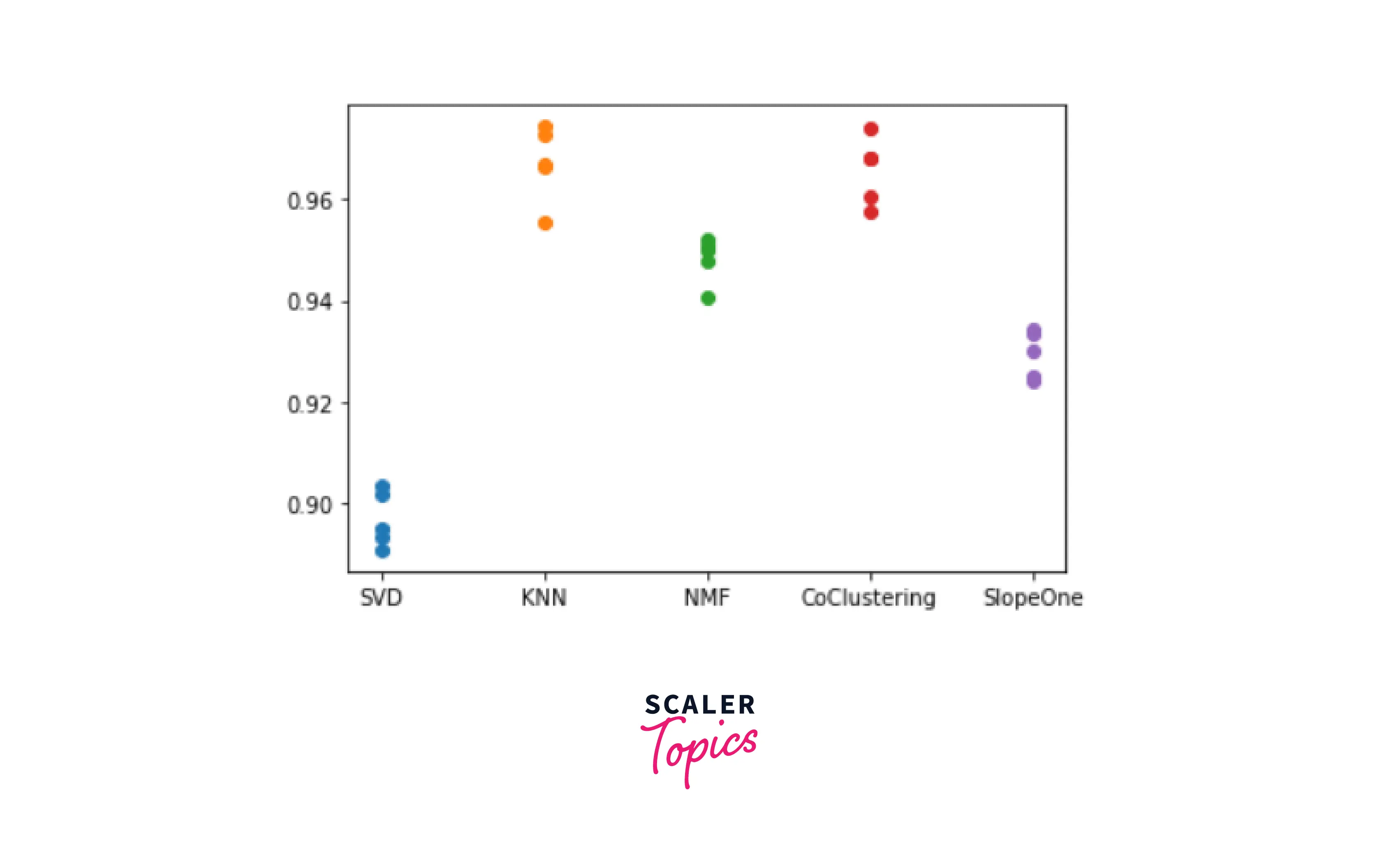
As you can see, SVD() completely outperforms the other four. Hence we will go with it.
Next, we will build a function that will get the top n predictions from a set of predictions.
Let's get the predictions now:-
Ouput:-
UserIDs with corresponding recommended movieids is obtained.
Content Filtering
Content filtering needs the profile of both the users and the items so that the system can determine the recommendation according to the users’ and items’ common properties.
The collaborative filtering technique is very easy to implement and works in a very intuitive way. However, it is susceptible to the "cold start" problem. This means whenever a new item or user is added to the model and the model has no way to either promote the item to the consumers or suggest to the user any available options. The model has no idea of a new user's preference unless the user starts rating.
If a user has horror and thriller movies as his genre, then collaborative filtering may suggest the user some comedy movies based on the preferences of the other users with preferences for crime and horror. Content filtering would overcome this drawback.
- To implement a content-filtering recommendation system, we utilize the TFIDF to reflect the importance of each genre in any movie.
- The sum product of the important weights and users’ preferences towards different genres in the user's profile is calculated. Based on this, we could simply sort movies and suggest the users the top N candidates as the recommendations.
Since we are only considering the feature genre here, we have to make our datasets accordingly.
Output:-
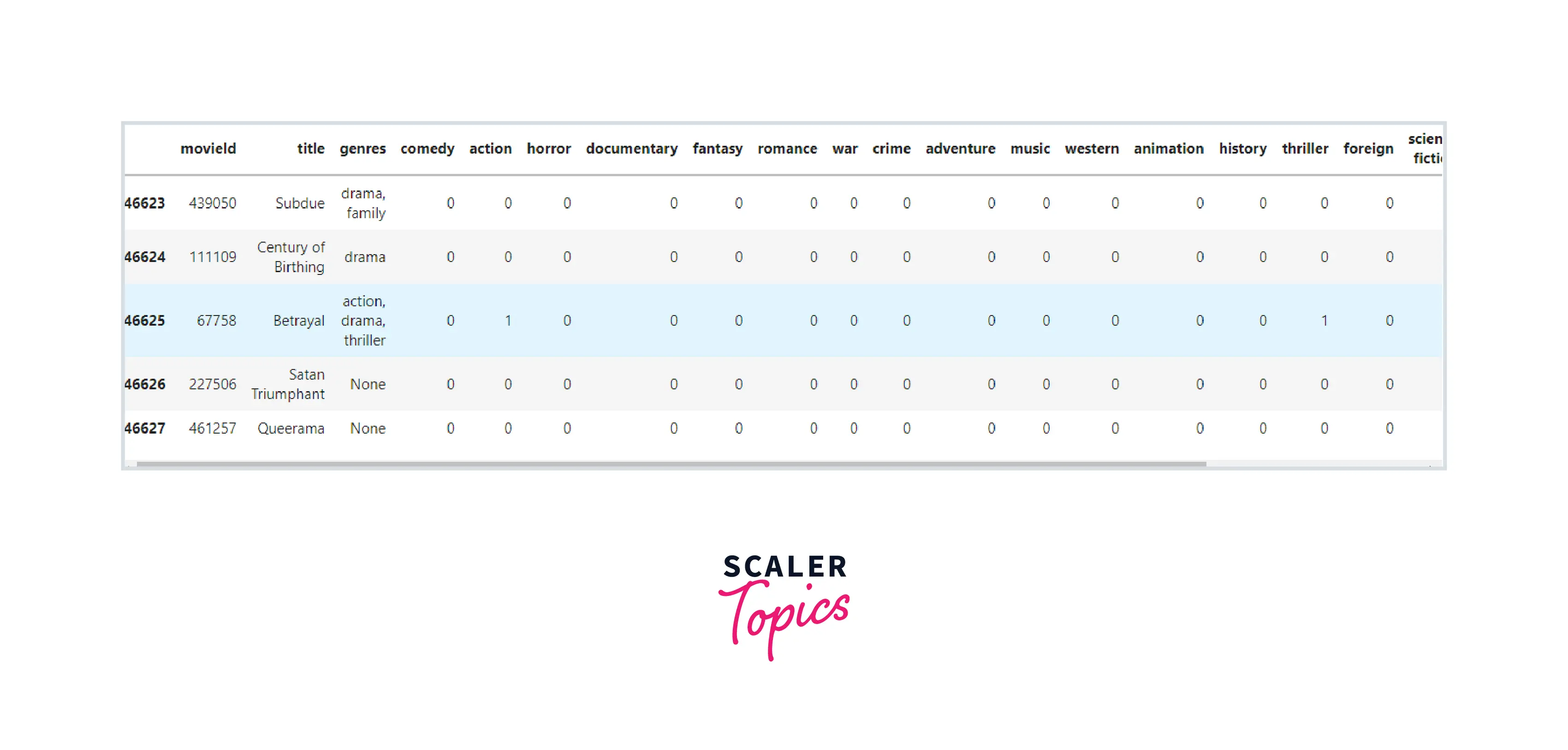
Now, we remove the unnecessary columns:-

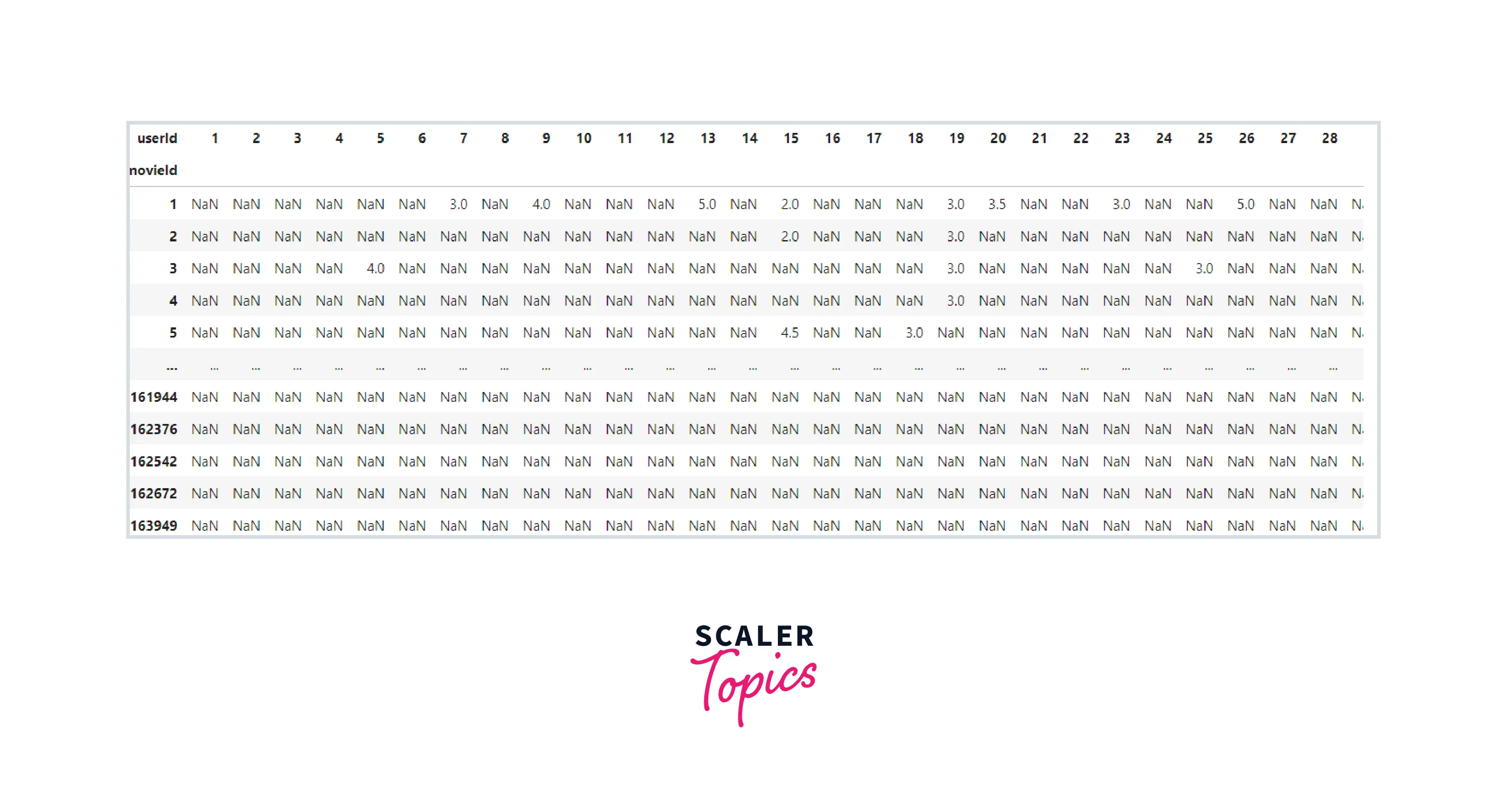
Create the Ratings Dataset
Output:-
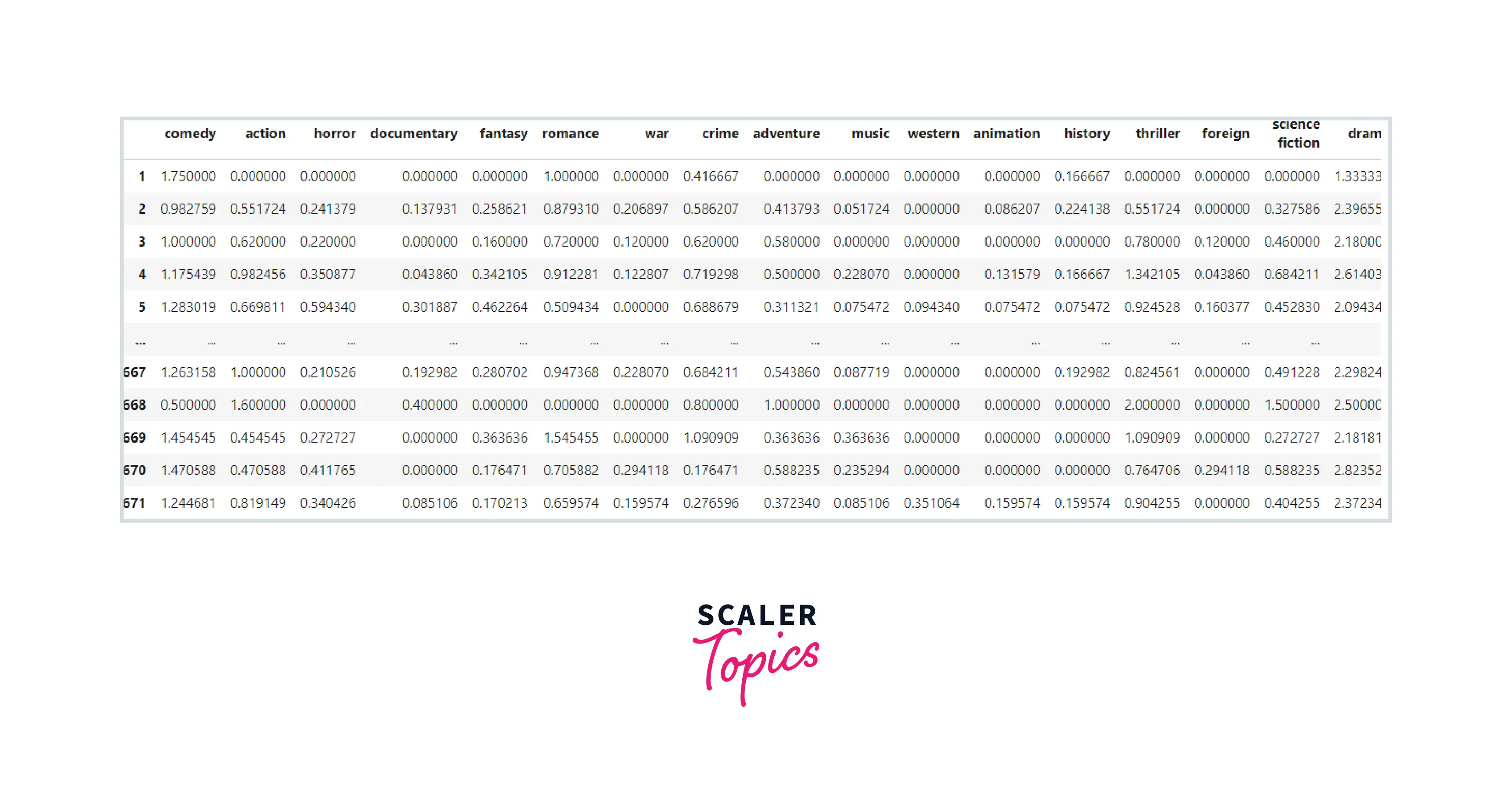
Now we calculate the sum product of the important weights and users’ preferences towards different genres in the user's profile.
Output:-
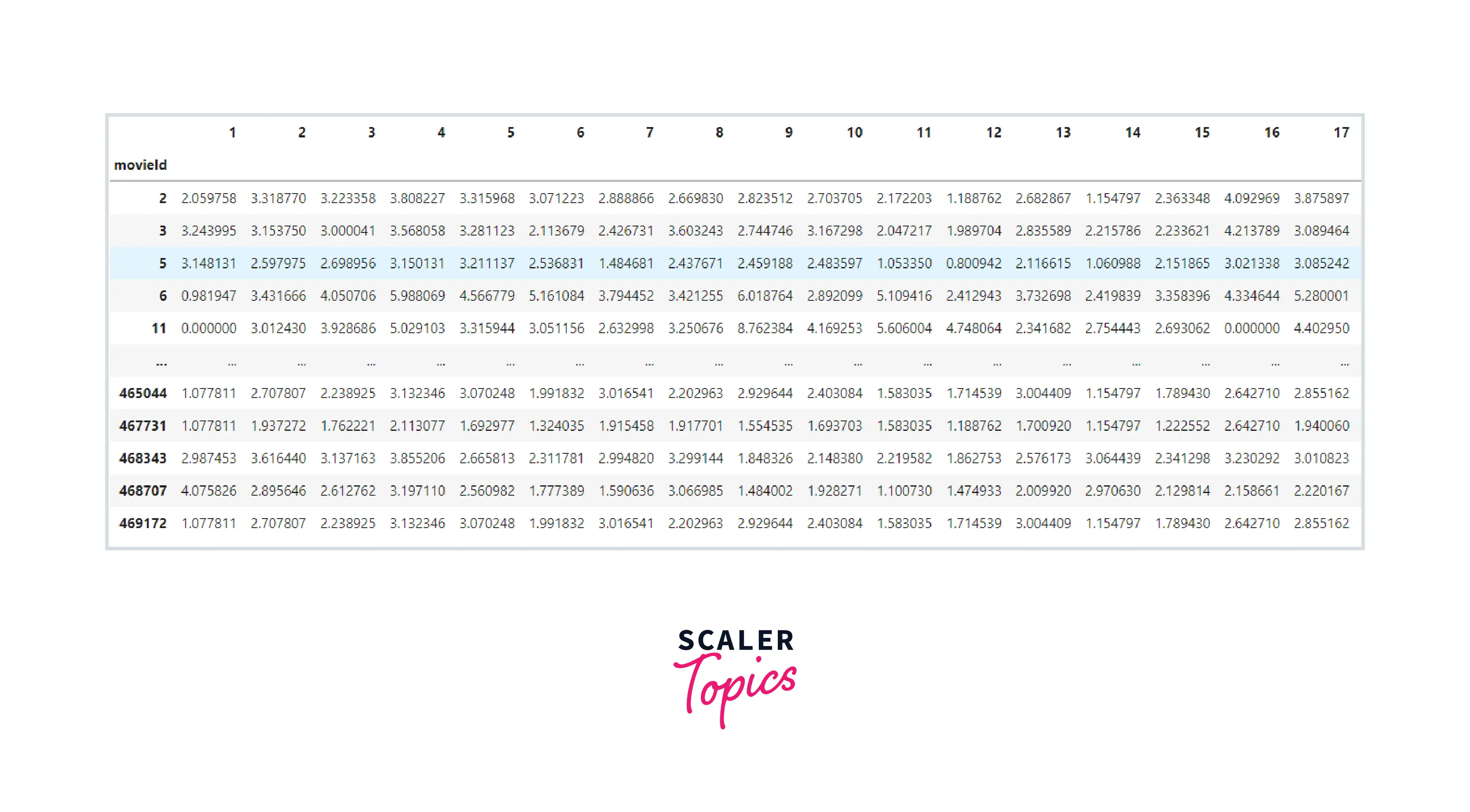
Creating the model (TF/IDF)
Output:-
Build the recommender:-
| index | id | title |
|---|---|---|
| 36332 | 200654 | Raffles |
| 24783 | 70912 | The Advocate |
| 23657 | 64318 | Hide-Out |
| 23797 | 64928 | It All Came True |
| 1333 | 2075 | Prizzi's Honor |
| 18469 | 44589 | The Clan - Tale of the Frogs |
| 42053 | 330399 | Rajathandhiram |
| 2129 | 4912 | Confessions of a Dangerous Mind |
| 39384 | 267428 | Buttwhistle |
| 21973 | 56651 | Kicked in the Head |
We got the userID, the movieID and the corresponding recommendation.
Conclusion
There we go! We got our movie recommendation machine. The key takeaways from this article are:
- There are two types of filtering methods: collaborative and content.
- Collaborative building is very easy to implement but does not take into account the relationship between the user and the item. Hence, it is susceptible to "cold start" errors.
- Content filtering overcomes the drawbacks of collaborative filtering.