What is Stacking in Machine Learning?
Overview
Ensemble learning is a subset of machine learning. It is used to optimize the performance of a model by integrating the outputs of multiple models. Ensemble learning also improves the accuracy of the model.
Stacking in machine learning is an ensemble algorithm used for prediction models where we can get efficient outputs.
Thus, some of the significant advantages of Stacking are enhanced accuracy and layered models having diversified trends.
What is Ensemble Learning in Machine Learning?
Ensemble models in Machine Learning are predictive models that combine the results of two or more models. The combined model has a higher accuracy and efficiency than the individual models.
We can use similar algorithms like a random forest where multiple decision trees are combined, which comes under homogenous ensemble learning, and heterogenous ensemble learning operates with different models like regression and Classification to produce the output.
We can use ensemble models for feature selection and data fusion and to improve function approximation, Classification, regression, prediction, etc.
There are three ensemble learning models - Bagging, Boosting, and Stacking. In this article, we will ponder over stacking.
To know more, check out the article on ensemble learning.
Stacking in Machine Learning
Stacking in machine learning is also known as Stacking Generalisation, which is a technique where all models aggregated are utilized according to their weights for producing an output which is a new model. As a result, this model has better accuracy and is stacked with other models to be used.
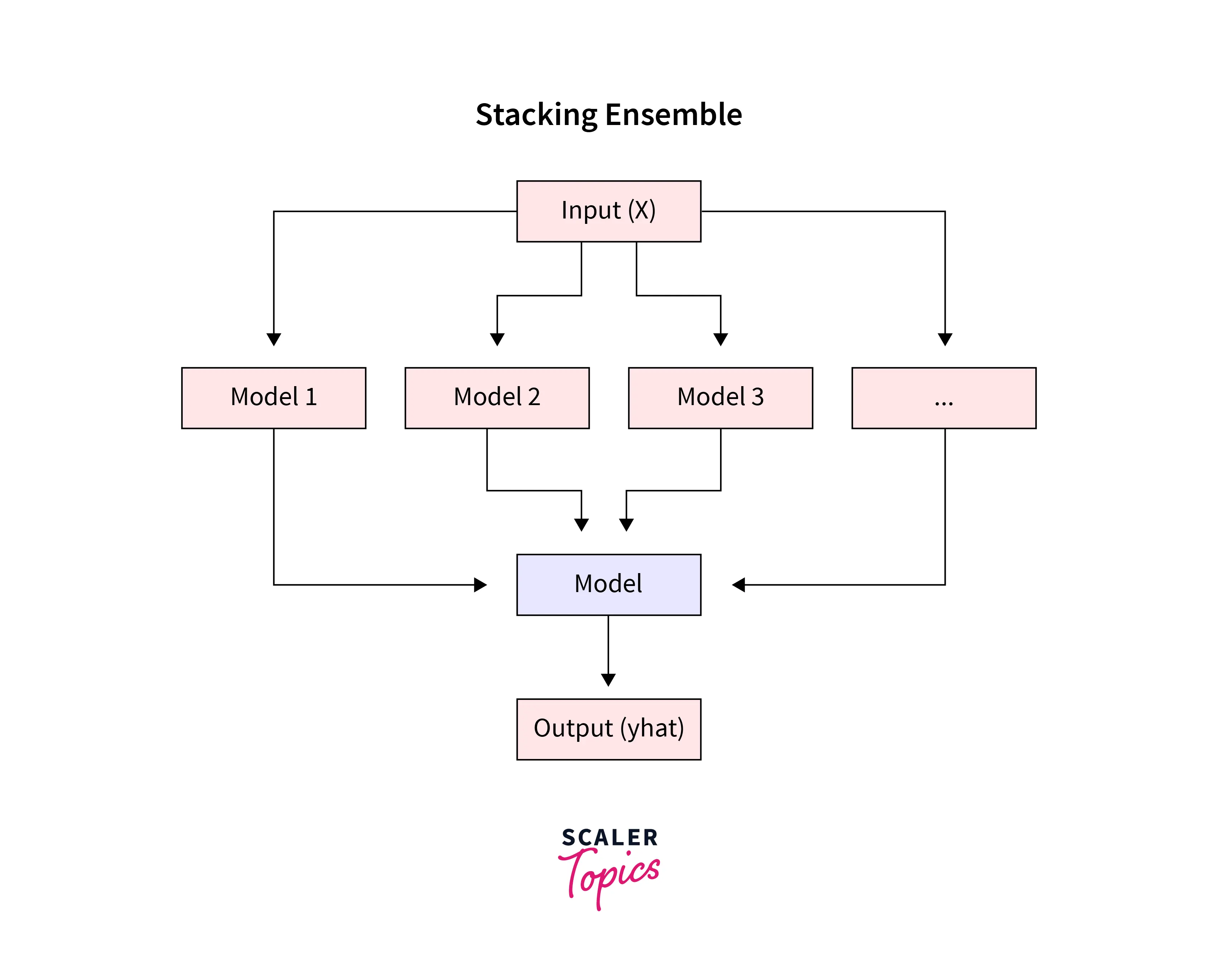
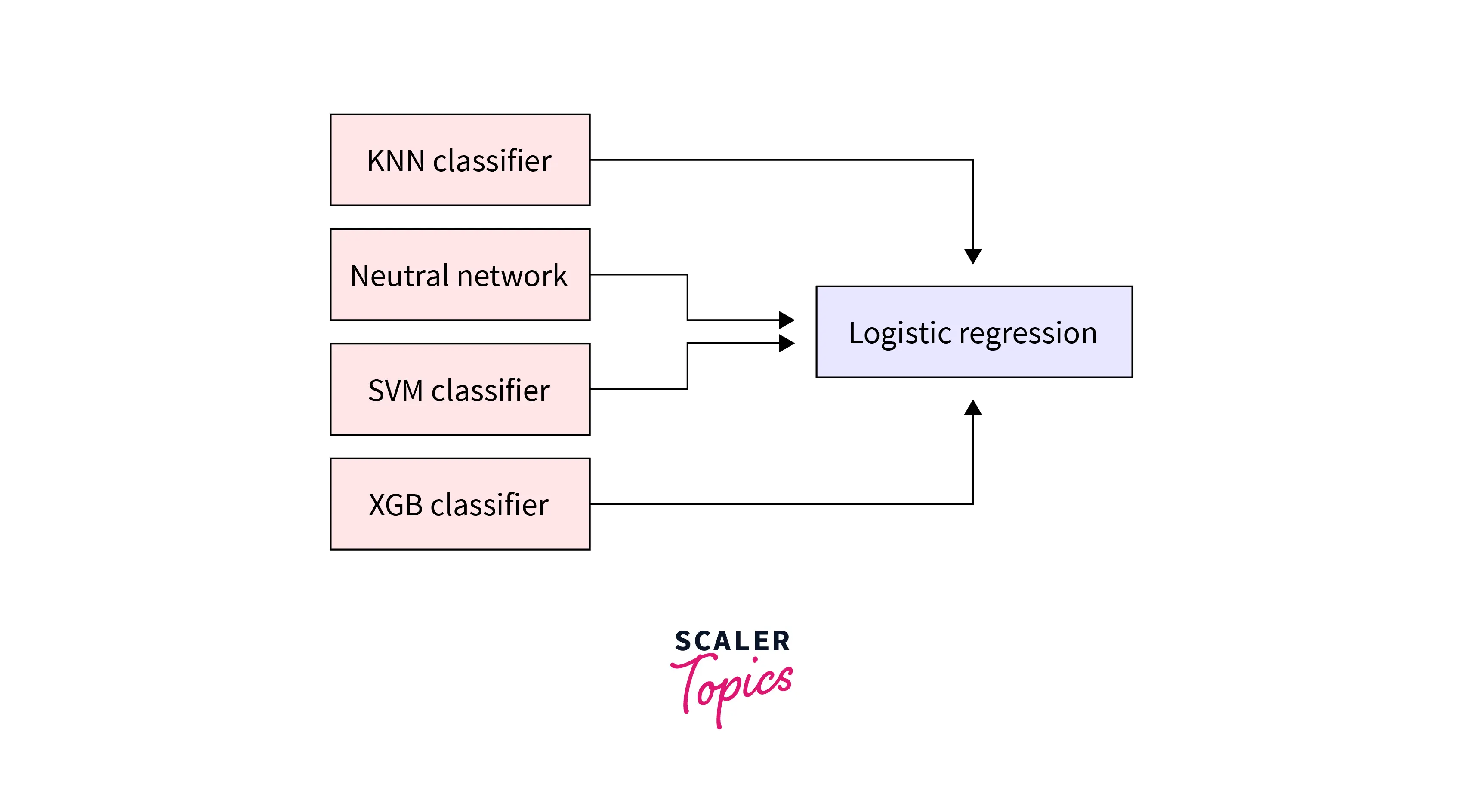
We can envision it as a two-layer model where the first layer incorporates all the models, and the second one is the prediction layer which renders output.
The principle is that you can always tackle a learning issue with various models that can learn a subset of the problem but not the whole problem space. This is where Stacking is used.
Architecture of a Stacking Model
Given below is the architecture of a Stacking model in machine learning -
- Dataset - The Dataset we work on. This Dataset is divided into training and test data.
- Level 0 Models - These are prediction-based models.
- Level 0 Prediction - The prediction that is the resultant of the above models is the level 0 prediction. This is based on the training data.
- Level 1 Model - This is the model which combines the prediction of all the level 0 or base models. It is also known as a meta-model.
- Level 1 Prediction - The level 1 model is trained on multiple predictions given by several base models, and then it optimally integrates the predictions of the base models on the testing data.
Steps to Implement Stacking Models
Now that we understand the architecture of the Stacking model in machine learning, we can understand how it works.
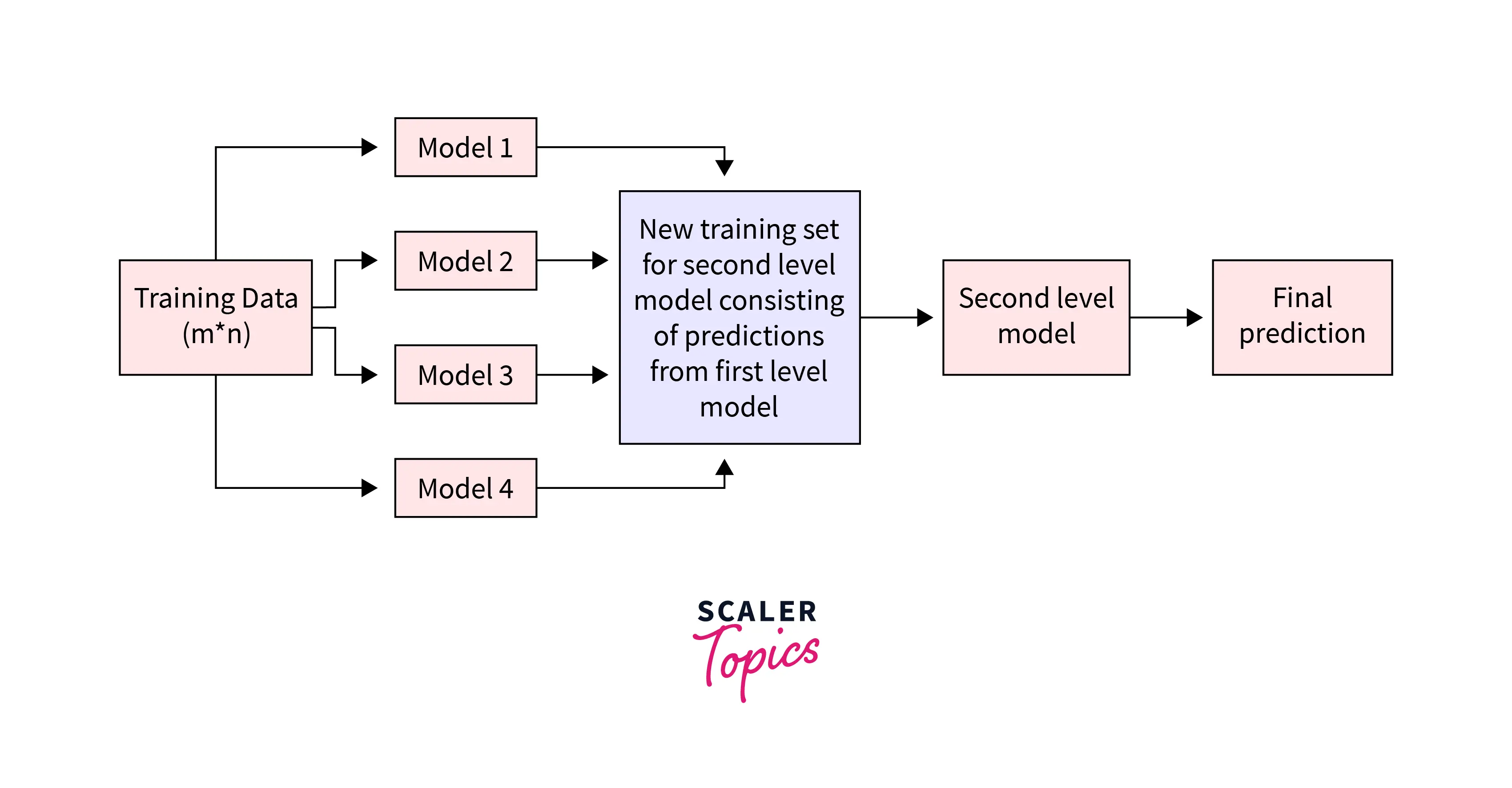
- Data - The Dataset to be used is split into training and testing data into n folds. This is achieved by repeated n-fold cross-validation, a technique to guarantee the efficient performance of the model.
- Fitting data to base model - Based on the above n-fold data, the first fold is assigned to the base model, and the output is generated. This is done for all n folds for all the base models.
- Level 1 model - Now that we have the results for the base models, we train the level 1 model.
- Final prediction - Predictions based on the level 1 model are used as the features for the model, and then they can be tested on the test data for the final results of the stack model.
How to Implement Classification with Stacking
Let us look at an example to work with Classification using Stacking on the Wine Quality dataset.
Output:-
Output:-
Output:-
Output:-
Output:-
Output:-
Output:-
Stacking for Regression
Regression is one of the most common and straightforward techniques to predict continuous outcomes. It maps out dependent and independent variables to compute the output.
When using Stacking, the last layer is always a computer with a regressor for final prediction. This is to compare the individual strength of the model with the final regressor using cross-validation.
The above example depicts using logistic regression as the meta-layer predictor.
Commonly Used Ensemble Techniques Related to Stacking
Various ensemble techniques can be used with stacking -
-
Voting Ensembles -
This is the most fundamental style of stacking ensembling method. This method works with individual models and then, based on the number of votes from individual prediction models, determines the result. In simpler terms, every base model has an output that can be either positive or negative depending on the result since not all models accurately fit the algorithm. We get an aggregate positive or a negative for the final model based on these results.
Compared to the simple stacking ensemble, this method uses statistics to combine the predictions.
-
Weighted Average Ensemble -
As the name suggests, this method uses the average weights of each model based on their predictions. This is slightly superior to the voting ensemble as it considers a wide range of models. We can also use a different dataset for cross-validation to get more efficiency.
-
Blending Ensemble -
Similar to Stacking, blending is another type of machine learning ensemble that uses a third type of testing set - hold out Dataset, a small fragment of the primary Dataset to predict values using n-fold cross-validation.
-
Super Learner Ensemble -
This can be considered a higher level of blending ensemble, where the only change is the change of the hold-out Dataset. Although, this Dataset is used explicitly with the meta or the level 1 model.
Training a Meta-learner on Stacked Predictions
To understand meta-learning with stacks, let us first start with meta-learning.
Meta-learning is a machine learning technique where an algorithm learns from another learning algorithm.
The combined algorithm learns how to get the most accurate prediction for the base learning algorithms when using a meta-learner with the stacked ensemble.
Enhance your machine learning skills by mastering the mathematics behind it. Join our specialized Maths for Machine Learning Certification Course now!
Conclusion
- Ensemble learning uses two or more two models to give accurate predictive outputs.
- Stacking in machine learning is an ensemble machine learning technique that combines multiple models by arranging them in stacks.
- When using Stacking, we have two layers - a base layer and a meta layer.
- Voting ensemble, weighted ensemble, blending ensemble, and super learning ensemble are the techniques used in stacking ensemble.