Successive Halving Search
Overview
Machine Learning in computer science is challenging to ignore. Machine Learning, one of the hottest fields right now, tries to teach a computer to understand things using historical data. Machine learning encompasses many activities, including email filtering, recommender systems, speech recognition, and image recognition.
Since it is an ever-emerging field, there arises a need to improve on existing methodologies. In this article, we will learn about such a method called successive halving search.
Pre-requisites
To get the best out of this article,
- The reader must be well aware of the basics of Machine Learning and classification algorithms in Machine Learning
- In addition, having a small grasp of optimization methods like GridSearch will be quite beneficial.
Introduction
As we discussed earlier in this article, advancements in Machine Learning are at an all-time high. To stay ahead of the curve, we must adapt and learn different optimization techniques. One of the most common problems among Machine Learning Engineers is that they cannot get the best out of their Machine Learning models.
To solve this problem, many techniques were created, like the GridSearch. In this article, we will learn about a faster and more optimal technique than the GridSearch algorithm, the Successive Halving Search Algorithm.
Intuition for Successive Halving
When it comes to Machine Learning algorithms, one should care about optimizing its hyperparameters. Why? Because these hyperparameters could be the thing that is holding our model back. In Machine Learning, as we construct various model pipelines, we frequently discover that ten, twenty, or even more hyperparameters require our attention. With each additional hyperparameter, this space of options expands exponentially, making scientific analysis difficult, if not impossible.
A general and most common approach would be to Grid Seach technique. The downfall of this method is that it might take much time to compute the best hyperparameters for it. There are two ways we can deal with this :
- Using Random Forest
- Successive Halving
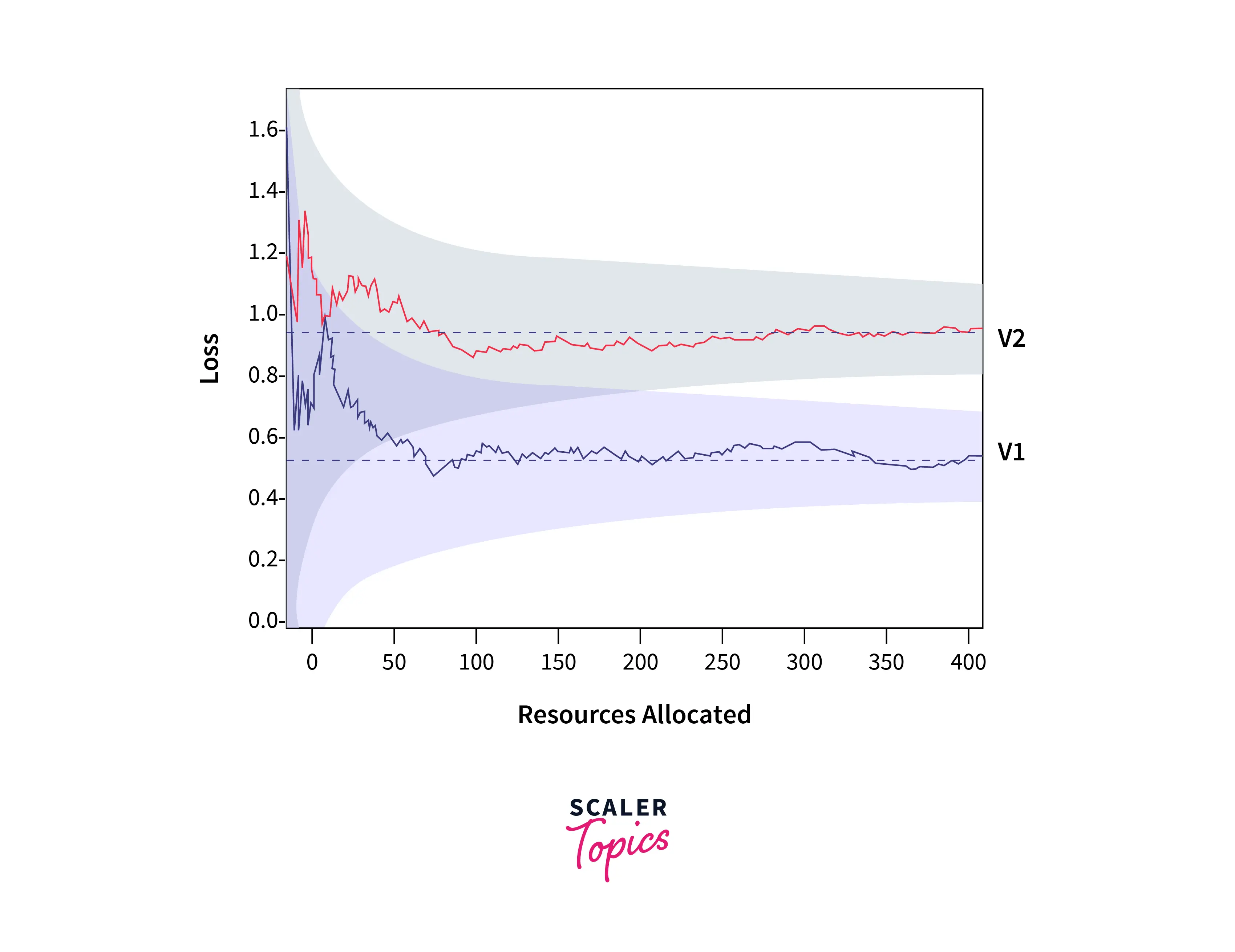
As we can see in the plot above, Even early on in the process, prospective configurations often perform better than the poorest ones. This is what successive Halving is all about!
Here's the intuition behind successive Halving :
- A set of hyperparameter configurations should be sampled at random.
- Analyze the performance of all configurations that are still in use.
- The bottom half of the worst scoring configurations must be discarded.
- Repeat from 2 until only one configuration is left.
Successive Halving makes sure that we don't waste a lot of time in training and returns the best hyperparameter combination as soon as possible.
Successive Halving Search Algorithm
Now that we have understood the intuition behind Successive Halving, let us look at some code and analyze how successive Halving works!
In the code snippet above, we will run it for n configurations. After some successful iterations, we will remove the ones that perform the worst, keeping the best ones. This will go on till we find the most optimum hyperparameter.
The rate at which we increase resources until we use up all of the resources we want to use is what the eta variable represents. Finding the appropriate difference between the number of resources available and the total number of configurations is a significant disadvantage of successive Halving. If the hyperparameter is not present or takes a lot of time, then we would have to refit and redo the model completely, losing time and resources.
Code Examples
Halving Grid Search
-
Checking the best parameters
Using the Halving Grid Search technique, we can find out the best hyperparameters for our model by using the best_params_ method.
Output :
-
Performance on Training Set
Here's how to check the performance of successive grids on the training set :
Output :
-
Performance on Testing Set
Here's how to check the performance of successive grids on the testing set :
Output :
Halving Random Search
-
Checking the best parameters
Using the Halving Grid Search technique, we can find out the best hyperparameters for our model by using the best_params_ method.
Output :
-
Performance on Training Set
Here's how to check the performance of successive grids on the training set :
Output :
-
Performance on Testing Set
Here's how to check the performance of successive grids on the testing set :
Output :
Conclusion
- In this article, we learned about Successive Halving Search, a hyperparameter search technique in which we sample hyperparameter configurations at random, discard the bottom half of the worst scoring configurations, and keep the best ones.
- Apart from this, we understood the intuition behind Successive Halving and the reason why we prefer successive Halving over other techniques like GridSearch.
- To conclude, we went through several code examples in which we saw various methods to find out the best parameters and configurations from Successive Halving.