The Titanic Dataset Project
Overview
We are all acquainted with the Titanic, The Unsinkable Ship, which sailed its first and last voyage in 1912. Even though the Titanic was made not to sink, there weren't enough lifeboats for everyone. Hence, resulted in the death of 1502 out of 2224 passengers and crew.
The Titanic Dataset link is a dataset curated on the basis of the passengers on titanic, like their age, class, gender, etc to predict if they would have survived or not. While there was some element of luck involved in surviving, it seems some groups of people were more likely to survive than others.
What are We Building?
In this article, we are building a predictive model to analyze whether a random passenger will survive based on their age, gender, cabin, Fare, and more. First, we will visualize data and then, based on it, adjust the parameter values according to our requirements.
Pre-Requisites
Below are some pre-requisites-
- Knowledge of Python
- Understanding of Utility Libraries like Pandas, Numpy
- Basic knowledge of visualization libraries like Seaborn, Matplotlib
- Implementable knowledge of SciKit Learn
- Knowledge of concepts like - Data Transformation, Binning, Feature Engineering, Model Training, Model Evaluation, and Model Testing
How Are We Going to Build This?
- Environment - Choosing an IDE or an environment to work on, either online or offline
- Importing - Loading the datasets and libraries required
- Analysing - Understanding the structure of the data like the columns, values, and data types
- Visualisation - Visualising the dataset to understand underlying patterns
- Filling out values - Cleaning the data by completing the dataset and filling out the missing values
- Feature Engineering - Understanding the features and creating new ones according to requirements
- Traning the model - Using algorithms like logistic regression and random forest to train the model
- Evaluation - Evaluating the predictive model
- Testing - Testing the model and getting the accuracy
Final Output
The resultant output will be a prediction measure of Logistic regression and Random Forest accuracy.
| Model | Score | |
|---|---|---|
| 1 | Random Forest | 86.64 |
| 2 | Logistic Regression | 79.24 |
Requirements
- Libraries - Pandas, Numpy, Matplotlib, Seaborn, SciKit Learn
- Algorithms - Logistic Regression, Random Forest
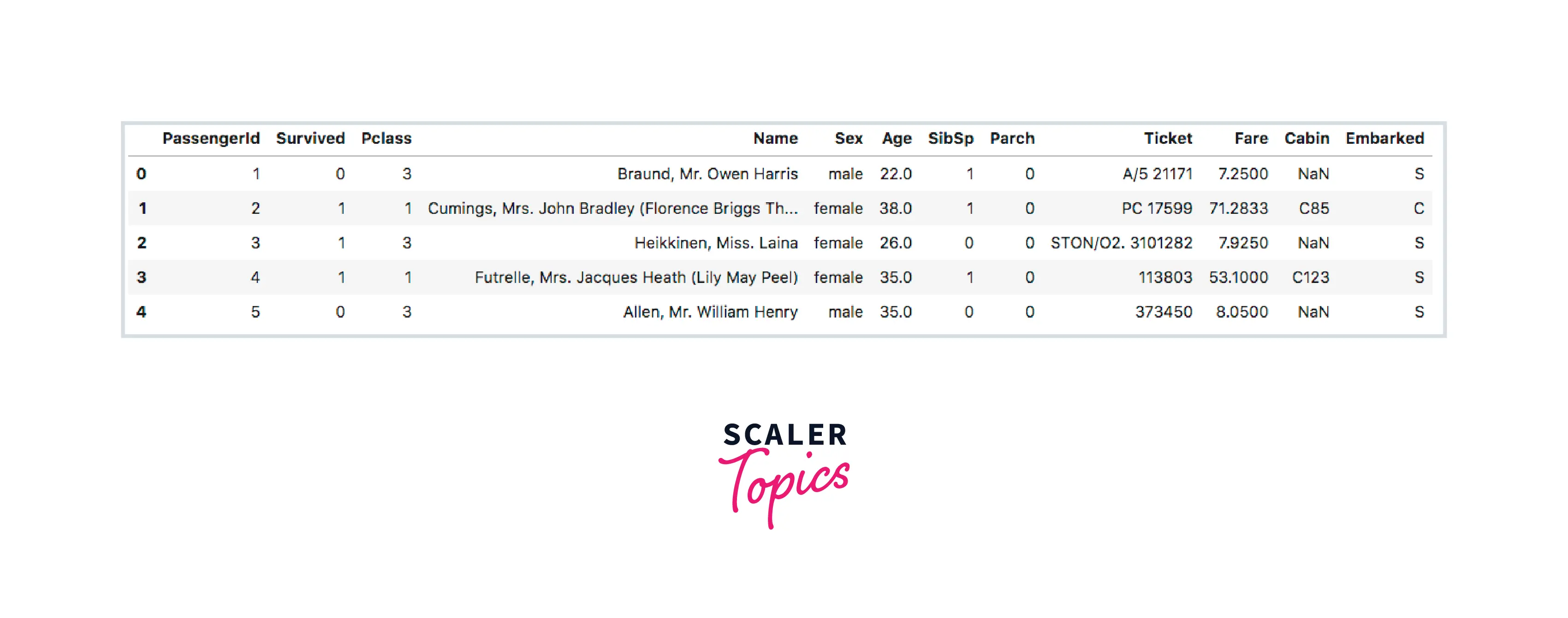
About the Data
We are using the Titanic Dataset here. It contains both numerical and string values. It is pre-distributed over 3 CSV files - Train, Test, and Gender.
The predefined columns are -
- Passenger ID - To identify unique passengers
- Survived - If they survived or not
- P Class - The class passengers travelled in
- Name - Passenger Name
- Sex - Gender of Passenger
- Age - Age of passenger
- SibSp - Number of siblings or spouse
- Parch - Parent or child
- Ticket - Ticket number
- Fare - Amount paid for the ticket
- Cabin - Cabin of residence
- Embarked - Point of embarkment
Building the Classifier
1. Load the Data
Output:
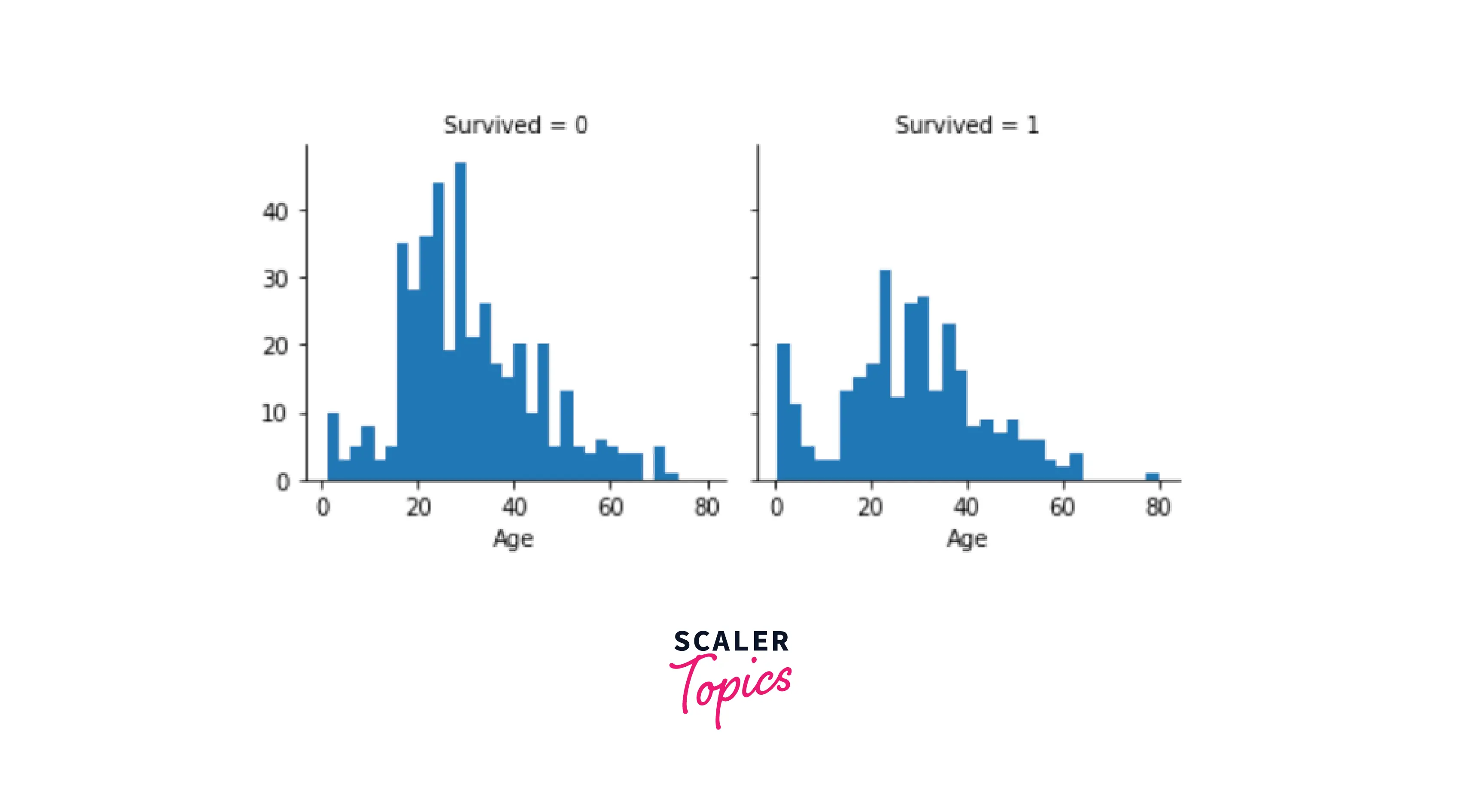
2. Analyze and Visualize the Dataset
Output:
Output:
Output:
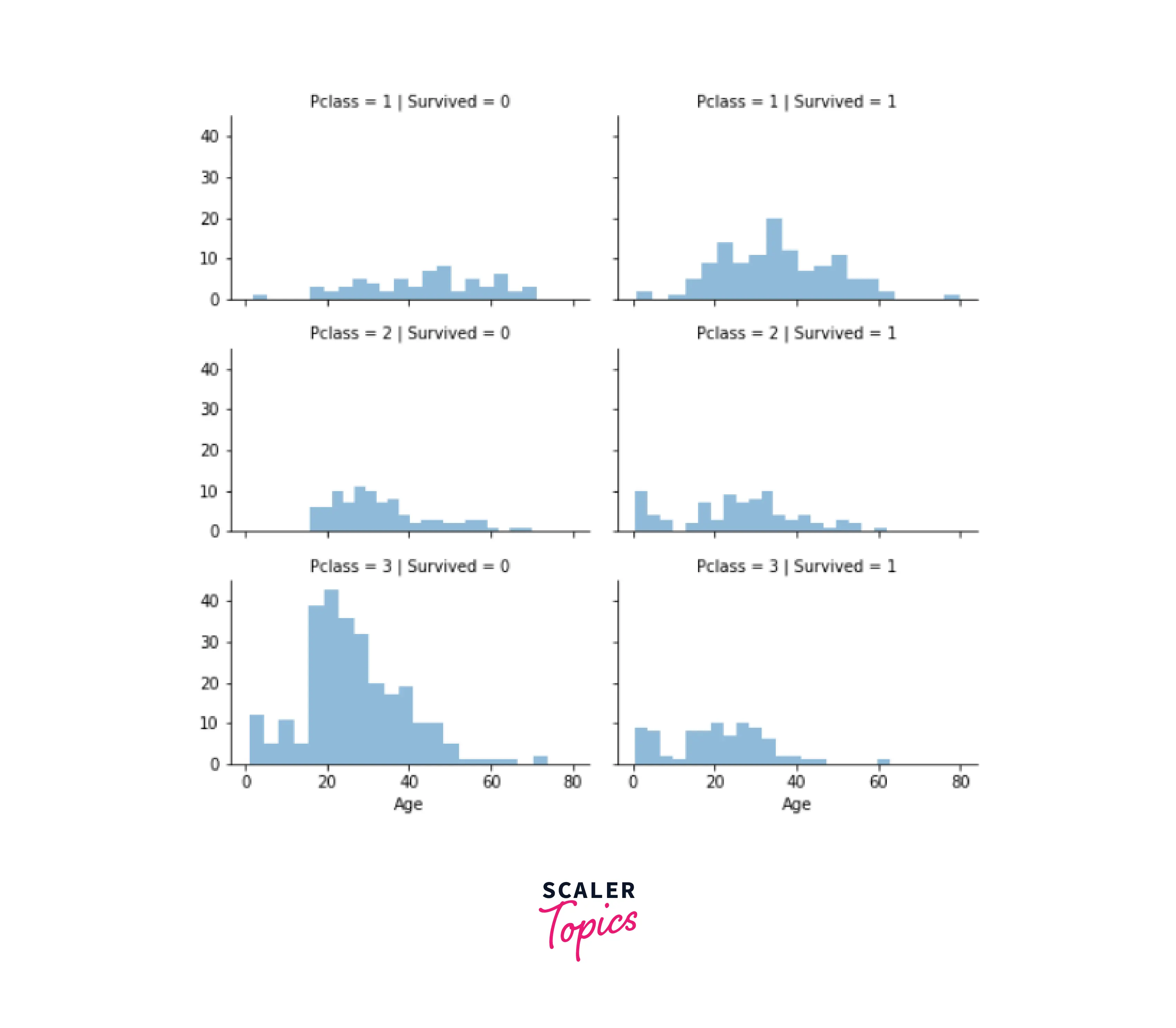
Output:
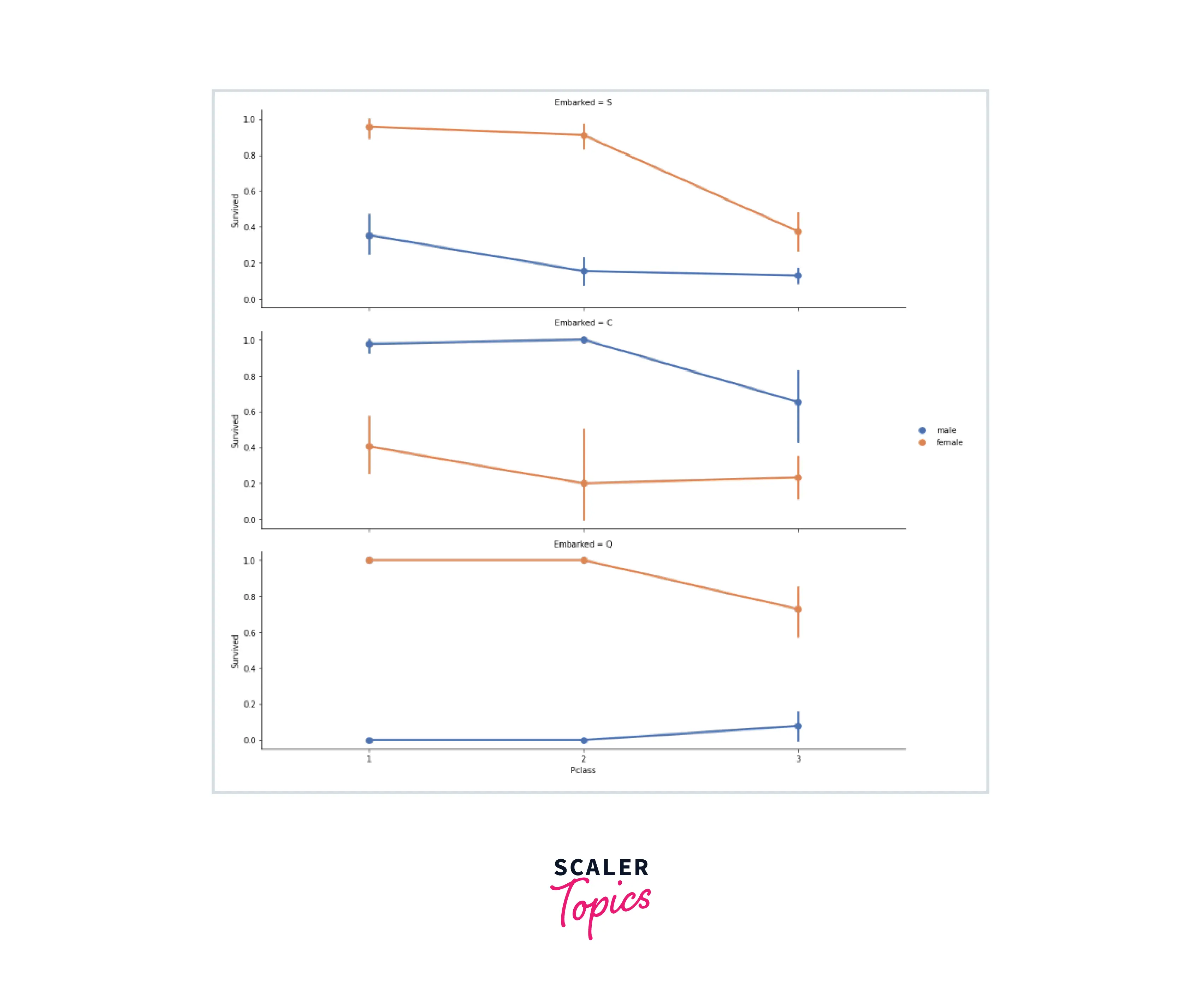
Output:
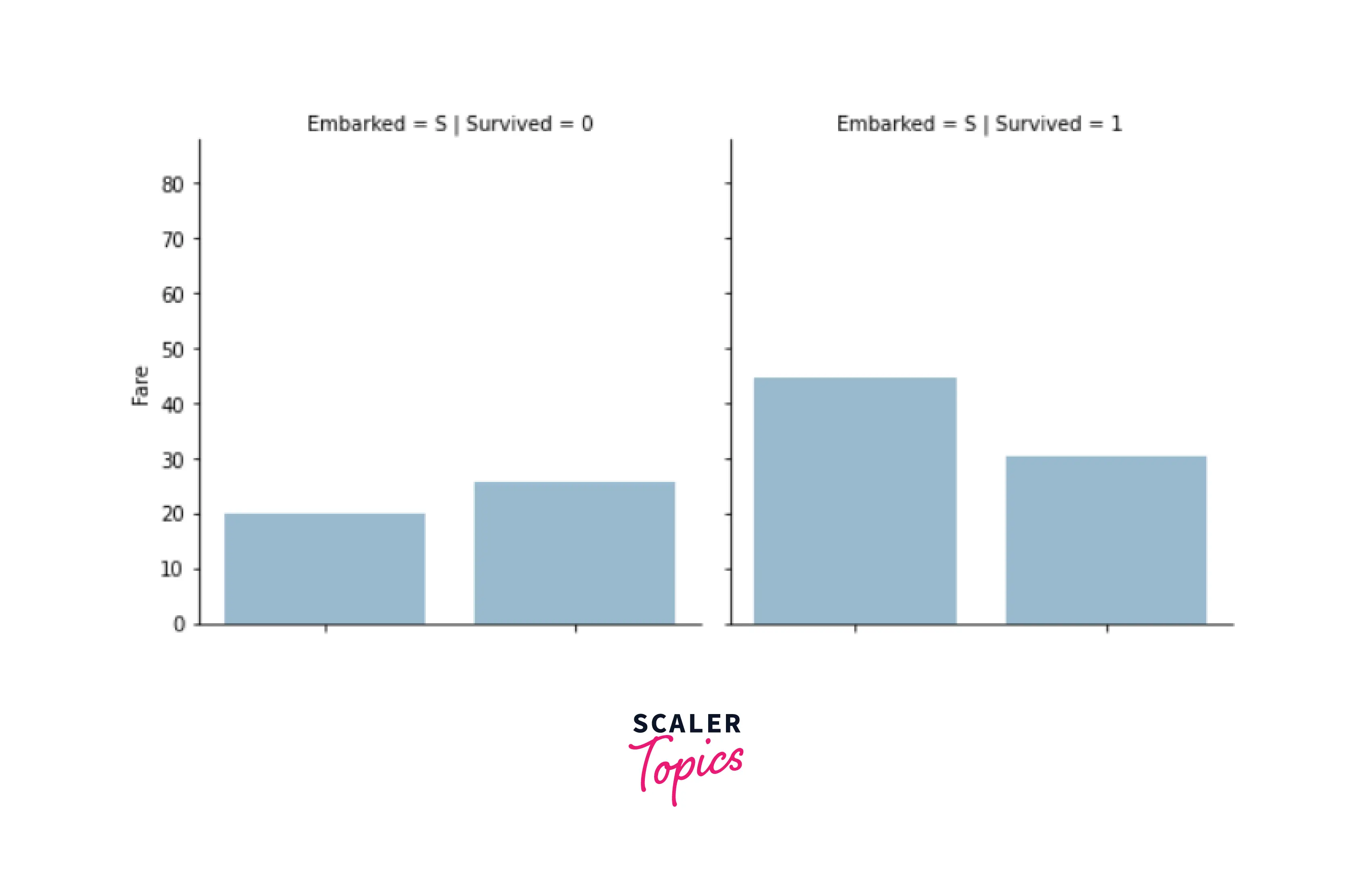
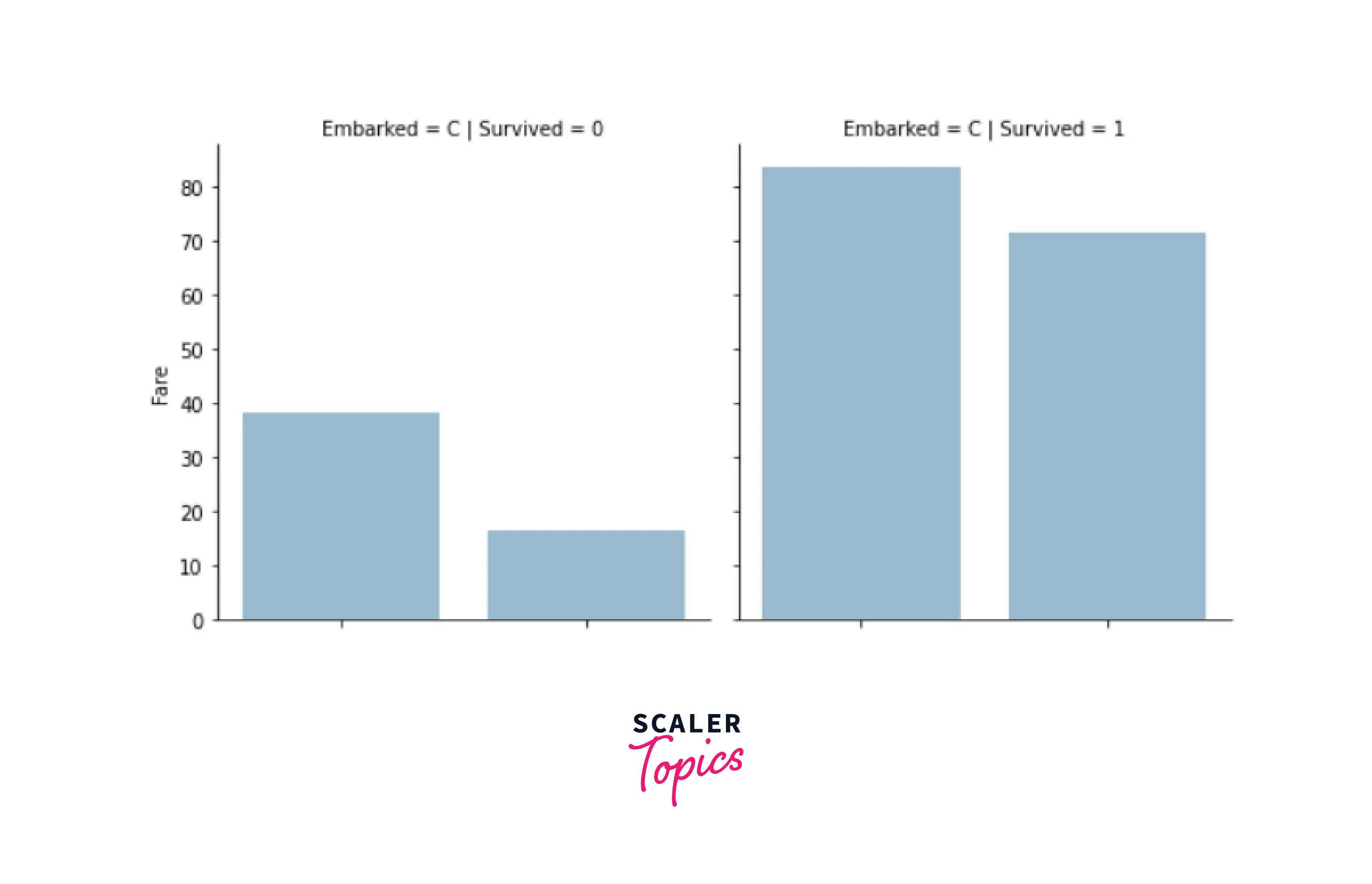
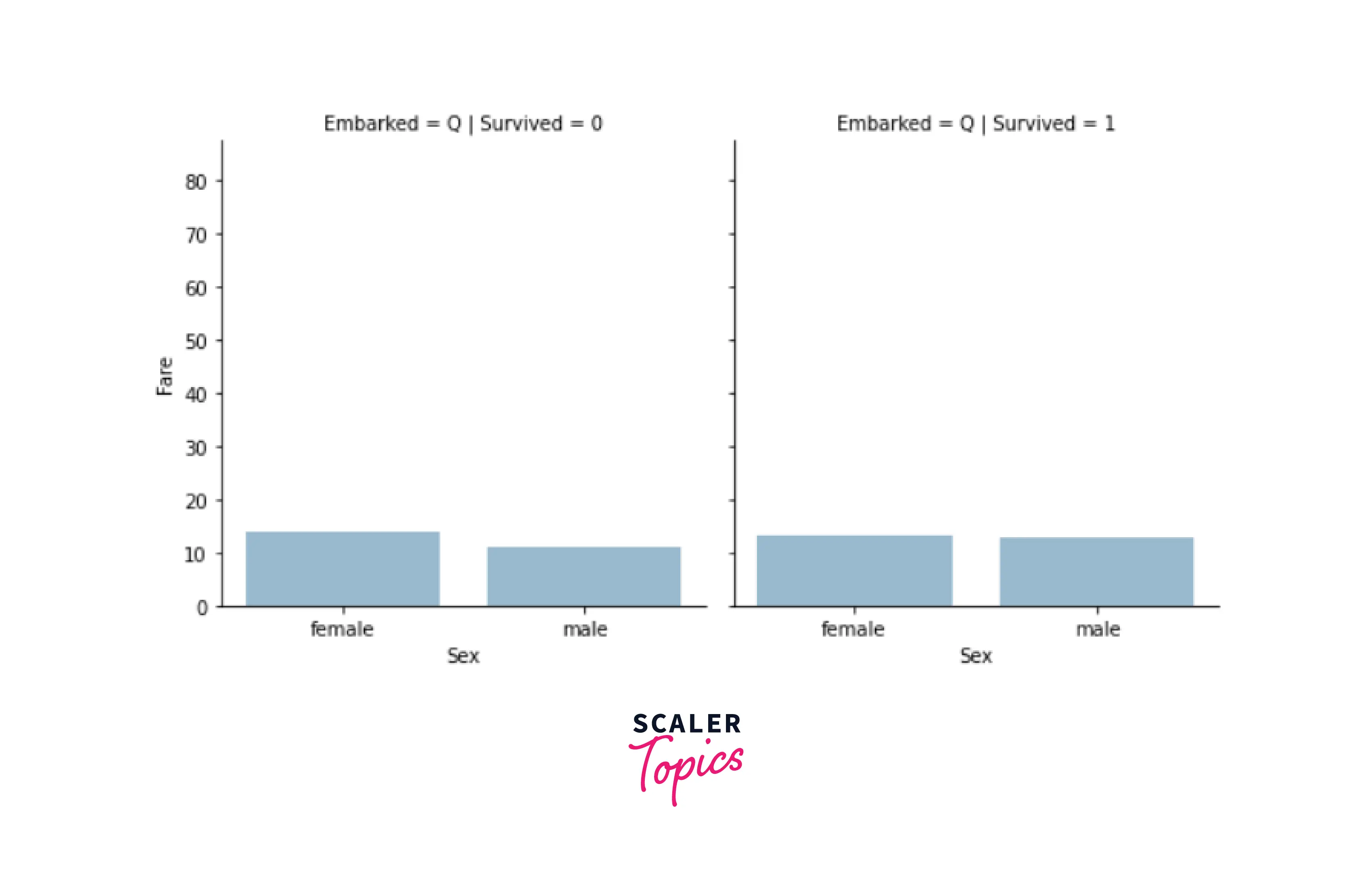
3. Data Transformation
Output:
4. Data Cleaning
Output:
5. Feature Engineering
Output:
Output:
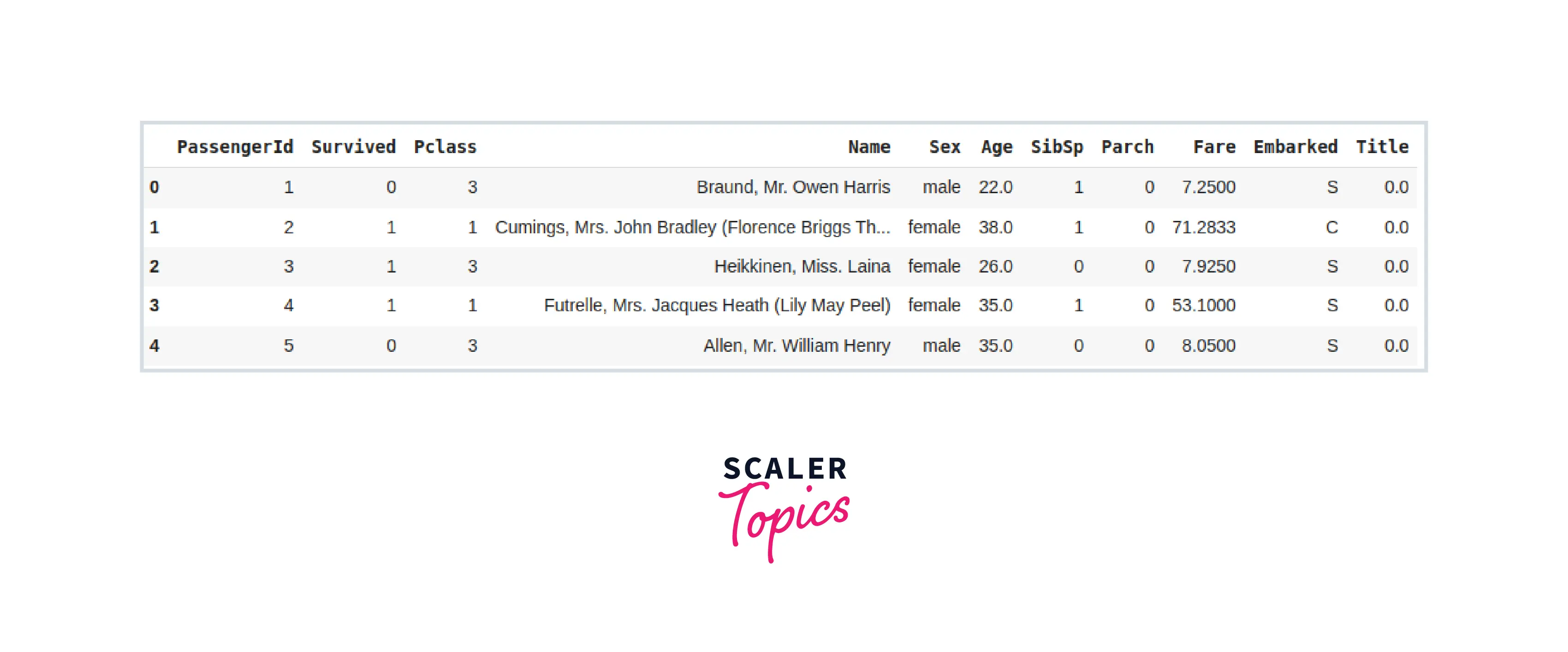
Output:
Output:
Output:
Output:
Output:
Output:
Output:
Output:
Output:
Output:
Output:
Output:
Output:
6. Training and Testing the Model
Output:
Output:
Output:
7. Model Evaluation
Output:
| Model | Score | |
|---|---|---|
| 1 | Random Forest | 86.64 |
| 2 | Logistic Regression | 79.24 |
What’s Next
To expand this project further -
- Flask - To have an interface, we can use Flask.
- Algorithms - Other algorithms like SVM, Perceptron, Gradient Descent, etc., can be used.
- accuracy - The accuracy can be increased by changing features.
Conclusion
- Titanic Dataset is very extensive in terms of numerical content.
- Random Forest Algorithm works best in this situation.