What Is MapReduce? Meaning, Working, Features, and Uses
Overview
In the Hadoop architecture, MapReduce and HDFS are the two core components that make Hadoop so efficient and powerful when it comes to dealing with huge amounts of data. MapReduce works as a programming model in the Hadoop architecture where larger chunks of data are split and parallelly processed in a distributed manner across the various clusters. The input data is split, processed as per requirement, and aggregated to obtain the final result. The MapReduce task is broadly segmented into two phases, the Map Phase and the Reduce Phase.
Introduction
As the amount of data is increasing with each passing minute, traditional RDBMS systems prove to be inefficient in processing the big data to serve the purpose. In traditional systems, you have a centralized single server for storing as well as processing the data. Also, when the amount of data is huge, these traditional models are not suitable for processing the massive volume of data. Scalability is challenging, and it could not be efficiently accommodated by the traditional database servers. The data processing for multiple files like petabytes of data becomes a bottleneck for the centralized system.
To solve the issue, and provide an optimized approach to handle big data, Google introduced the MapReduce algorithm. To offer less overhead across the various cluster networks and significantly reduce the processing power, MapReduce works by mapping every tasks in the map phase, then by shuffling and then Reducer combines and reduces its equivalent tasks as one. In the MapReduce framework, the bigger task is divided into smaller tasks and processed across various systems. It is then aggregated and integrated to obtain the resultant dataset for data analysis.
What Is MapReduce?
In this section, we shall be dep diving into what is MapReduce in big data.
Google solved the big data problem by inventing the MapReduce algorithm to analyze its search results efficiently. It was only then when the question - what is MapReduce in big data became a popular question for all the organizations facing issues with processing and working with big data. Its ability to split and process terabytes of data in a parallel manner and producing faster output gained the attention of various organizations.
To explain with an example, if your company is dealing with terabytes worth of data and wants to analyze the data. Then with the help of the Hadoop cluster consisting of 10,000 affordable commodity clusters, each having 256MB data blocks, we can conveniently process the terabytes of data simultaneously. If this was done sequentially, the amount of time needed would be much huge, which is resolved with the MapReduce algorithm.
In the Hadoop architecture, MapReduce and HDFS are the two core components that make Hadoop so efficient and powerful when it comes to dealing with huge amounts of data. MapReduce works as a programming model in the Hadoop architecture where larger chunks of data are split and parallelly processed in a distributed manner across the various clusters. The input data is split, processed as per requirement, and aggregated to obtain the final result. The MapReduce task is broadly segmented into two phases, that is, the Map Phase and the Reduce Phase.
MapReduce can offer faster results by not only parallelizing the tasks but also eliminating the need for transporting the data to the code's location. Instead, it saves time by directly executing the code on the same cluster where the data resides. The data access and storage are provided using the server disks.
Nowadays, there are also query-based systems like Hive and Pig. These are used for retrieving the data from the HDFS via SQL-like statements. An important point to note, is these are executed along with jobs, written using the MapReduce model. Hence, MapReduce has many unique advantages too.
How Does MapReduce Work?
Let us understand the working of the MapReduce framework. In the MapReduce framework, we have two most important tasks that is divided into multiple smaller tasks.
The two main tasks are Map and Reduce.
With the Map task, the data sets are taken and converted into smaller sets of data. The individual items are then broken down into tuples widely popular as the key-value pairs.
While in the Reduce task, these key-value pairs are taken up from the Map as input. Then the tuple pairs are shuffled and combined based on similar keys into a smaller set of tuples.
It's important to know that the Reduce stage always occurs after the Map stage in the MapReduce framework. Let us understand each of the individual phases of the MapReduce framework with the help of the detailed illustration shown below.
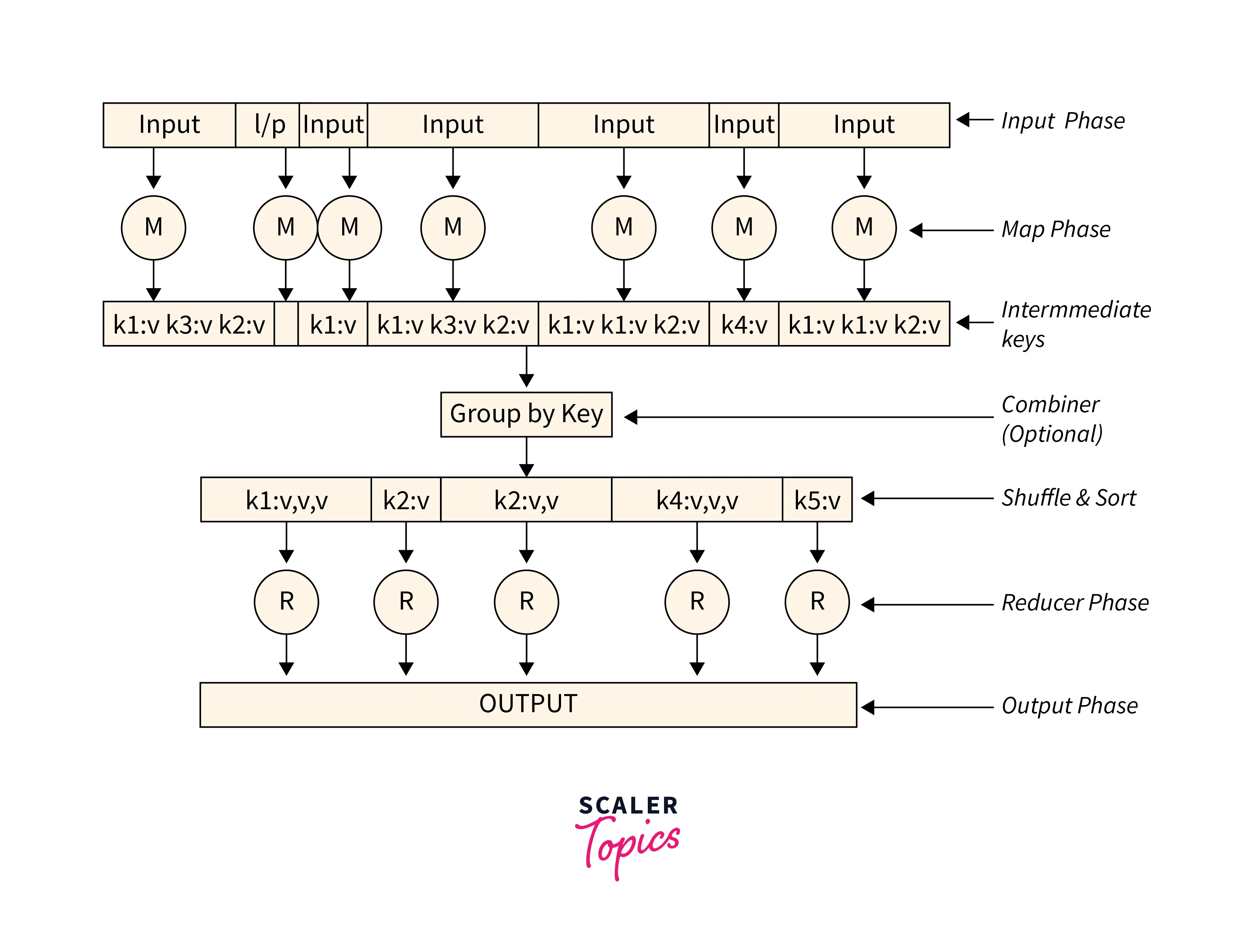
Phases of MapReduce:
-
Input Phase −
With the help of the Record Reader, each data record from the data is translated and sent as the parsed data file to the mapper phase. The data sent is mostly in the form of key-value pairs. As seen in above illustration, the input is in the form of key-value pairs. -
Map −
We define the Map as a logical function created by the developer as per the requirement of processing the data. Here the series of tuple (key-value) pairs are taken and processing happens for each of these pairs to generate either more than one or no key-value pairs as per the data processed. -
Intermediate Keys −
The processed key-value pairs obtained after the map phase are defined as the intermediate keys. -
Combiner −
This is the optional stage in the entire MapReduce framework. The combiner acts as a local Reducer which works to aggregate the similar data collected from the map phase into identifiable data sets. The intermediate keys are the input and combiner, such as aggregation like grouping, is performed on these keys. Then a user-defined code is applied to group the values in a small scope compared to the mapper in the MapReduce algorithm. -
Shuffle and Sort −
Then comes the first phase of the Reducer task. The shuffle stage and the sort stage are the two most important stages of the MapReduce algorithm. The aggregate key-value pairs are taken in the local system, where the pre-defined Reduce tasks are executed. The individual key-value pairs are then shuffled to gather similar keys in different groups and then sorted by their respective key into a massive data list. This data list aggregates the equivalent and similar keys together to allow the values respective to their keys to be easily iterated in the Reducer task. -
Reducer −
The aggregated key-value data is then taken up as the input in the Reduce stage one by one. The value corresponding to individual keys is calculated and aggregated, filtered, and combined in a combination of ways. This is the step where a wide range of processing happens. As seen in the illustration, the execution in the Reducer stage completes, and more key-value pairs in the reduced form are sent for the final stage. -
Output Phase −
Finally, with the help of the output format, the combined and processed key-value pairs are translated as the final key-value pairs. It is then written into a file via a record writer. It is this output that can further be used by the developer for their analysis.
Sometimes it gets difficult to understand how to divide a data processing system as mappers and reducers. The mappers and reducers are the primitives implemented in the MapReduce algorithm. Though MapReduce can be utilized for scaling the data processing over various computing nodes, figuring out how a task would be divided across mapper and reducer is quite tricky. But it is just a configuration away, to scale a system for executing logic over several servers in a cluster if it has been written in MapReduce.
Summing up, MapReduce is a core component of the Hadoop framework. It works by processing the petabytes of data into smaller tasks in parallel, across the various servers. Once done, all the processed data from various servers are aggregated to return a consolidated output for the user's analysis.
The Three Phases in MapReduce Program
With this section of the article, we shall be deep diving into the major operations that are integrated into the Hadoop MapReduce programming framework.
Broadly the MapReduce task is segmented into two main phases as listed below. We shall be understanding each phase in depth.
- The map stage
- The reducing stage (including shuffle and reduce)
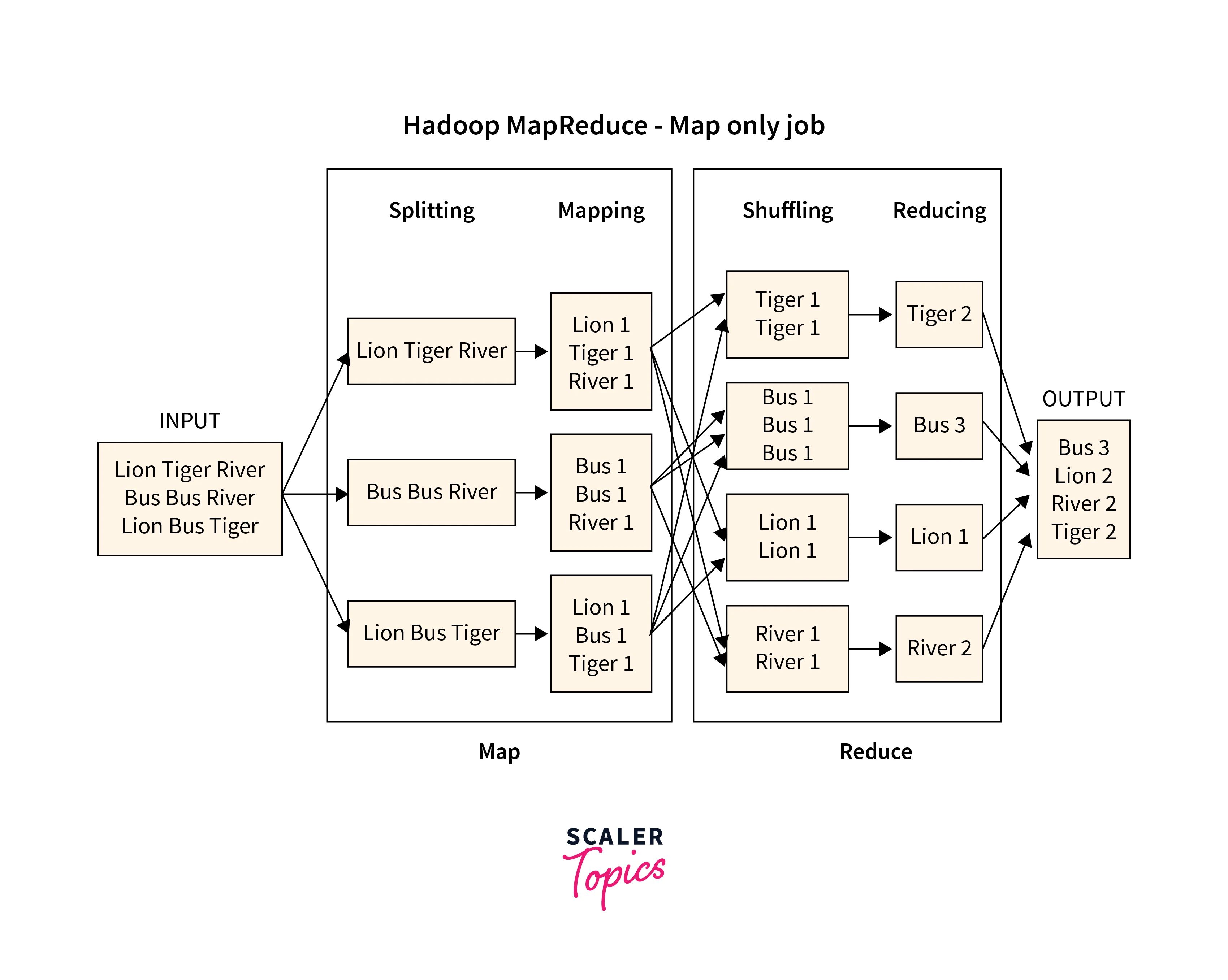
The Map Stage
As seen from the illustration given above, in the Map stage for the MapReduce framework, the data is mapped as key-value pairs. The input that is provided for this key-value pair can be different depending on what data needs to be processed. Mostly, the key is some kind of ID that addresses something, while the value is the actual data corresponding to that key.
As seen in the illustration, the Letter 'L' is the key having a value of 1. Similarly, the letter 'T', 'B', and 'R' have the value of 1. After this pairing is done, the Map() function gets executed in the memory repository for every input key-value pair. Once it is completed, it generates the intermediate key-value pair that is the input of the Reducer or Reduce() function.
Below illustration shows the working of the Map stage:
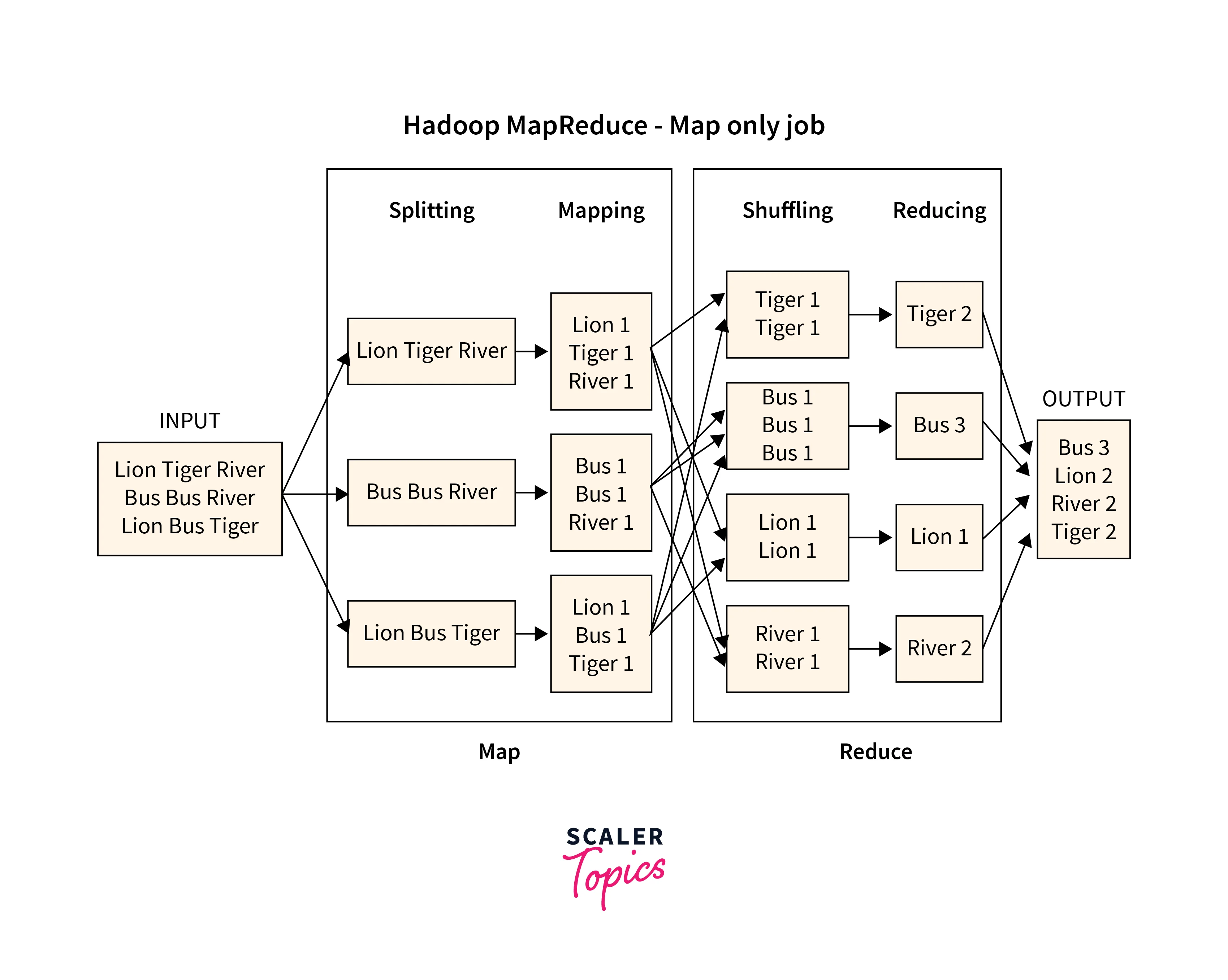
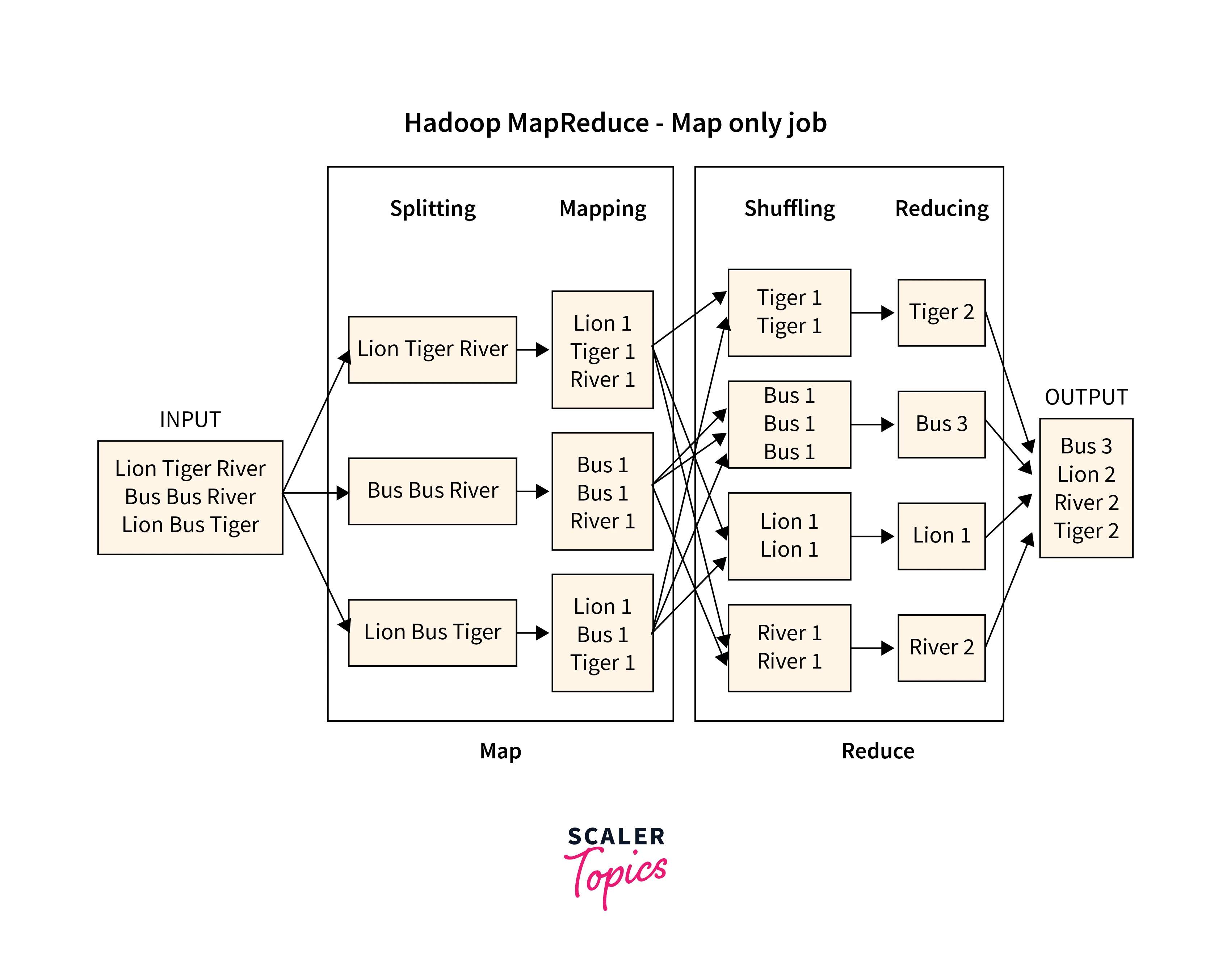
The Reducing Stage (including shuffle and reduce)
In the Reducer stage, the two sub-processes named, shuffle and reduce takes place. Once we reach the reducer stage of the MapReduce framework, the intermediate key-value pairs undergoes shuffling and sorting to align the similar keys at one groups as seen in illustration. Once done, its sent to the reduce() function for combining the like keys together. Here, the key-value pairs are aggregated or grouped depending on the key-value pair. This reduced program is dependent on how the users or the developer has created the code setting its requirements.
In the Shuffle stage as seen in the illustration shown above, similar key-value pairs are grouped and aggregated from each of the previous key-value pairs. Like the number of occurrences of the letter 'T' in the map phase is aggregated in the shuffle and reduce phase. Similarly, the number of times the letter 'L', 'B', and 'R' came up are also aggregated together.
In the Reduce phase of the MapReduce framework, the key-value pairs are reduced to their total value. Like in the illustration, it can be seen that the letter 'T' came 2 times, hence it gets value 2 against it. Similarly, the letter 'L', 'B', and 'R' gets the respective value based on the the number of times it appeared in the shuffle stage.
While the process of Map-Shuffle-Reduce goes on, the Job tracker and the Task tracker also play a significant role.
Job Tracker:
The Job tracker manages all the resources for the jobs running across the entire cluster. The job tracker also helps to schedule each map on the Task Tracker that runs on the same set of data. It ensures that hundreds of data nodes can be available for the same cluster.
Task Tracker:
The Task Tracker is the worker that follows the set of instructions ordered by the Job Tracker. The Task Tracker is part of each of the data nodes available on the cluster which are executing the Map and Reduce task.
With the Job History Server, the historical information is stored. It is a daemon process that captures and stores all the past information related to the working of the task or system. It is similar to the logs generated during or after the job executes to track if any issue comes up.
Below illustration shows the working of the Reducer stage:
Key Features of MapReduce
Listed below are the key features offered by MapReduce in Big Data.
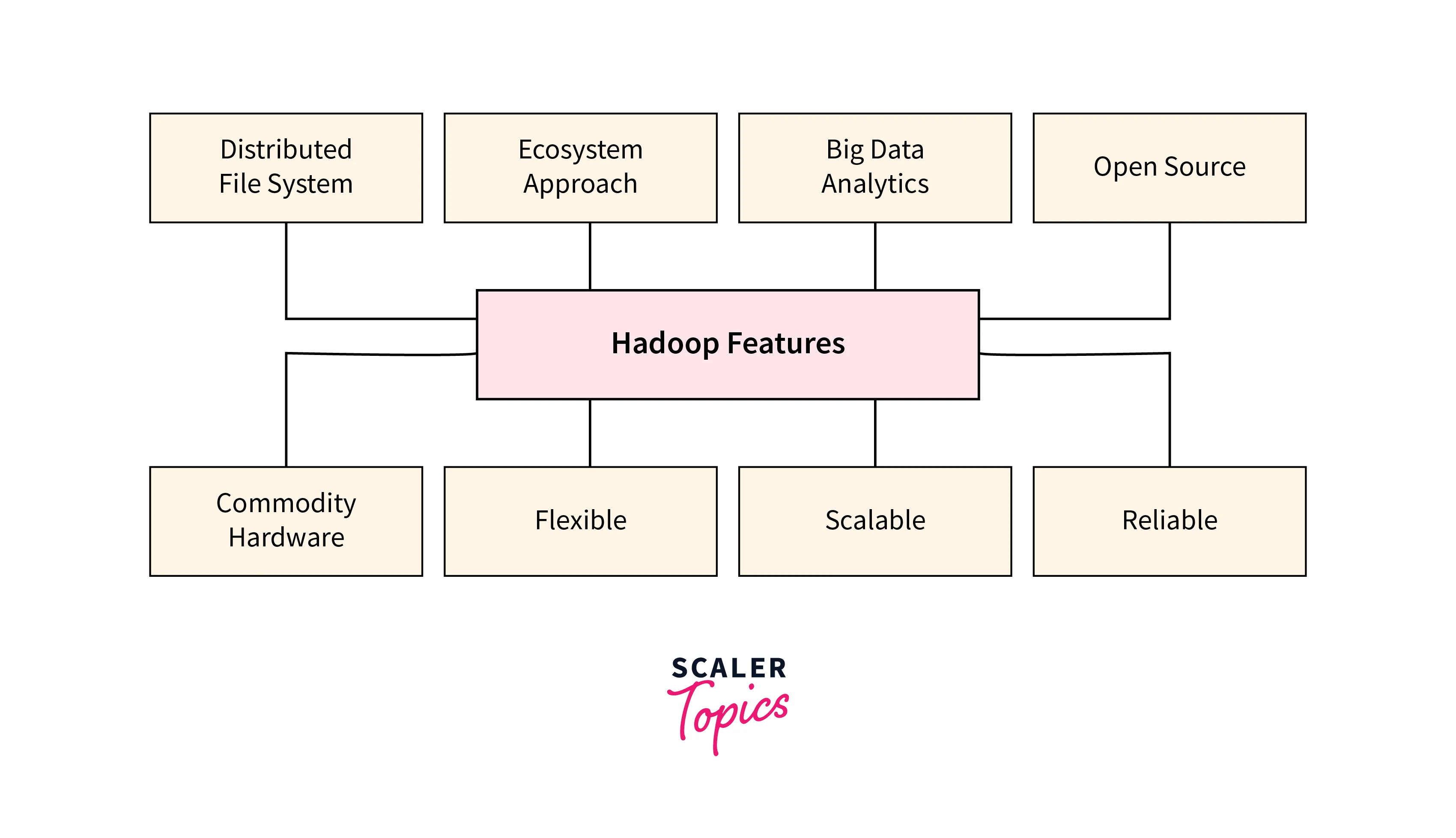
Scalability
The Apache Hadoop MapReduce framework offers high scalability. Several servers can run parallel which helps to distribute and store large amounts of data across various clusters. These servers are reasonably priced, where the addition of more servers as demand increases can be easily done to gain more computing and processing power along with storage. Many times, high computing is obtained by improving the capacity of nodes or adding several nodes (also known as horizontal scalability). With Apache Hadoop MapReduce programming, firms can execute the systems having thousands of terabytes of data from huge sets of nodes.
Data processing was not that scalable with the traditional relational database management systems as organizations had to delete the raw data on the assumption that it would not be required and risk it. While, with the MapReduce programming model, you can easily scale out the entire architecture to suit your needs.
Versatile
For organizations who want to explore new data sources, MapReduce programming is the correct choice for working with new forms of data. With MapReduce, you can use both structured as well as unstructured data, to gain actionable and valuable insights from multiple versatile data sources. Data sources such as social media, clickstreams, and email in various languages are supported by the MapReduce framework. The source code is accessible to users for alternations, analysis, review, and comments which helps organizations alter the code to meet their defined needs.
Secure
The MapReduce programming model is highly secure as it utilizes the HBase and HDFS security approaches. This allows only the authenticated users to view as well as manipulate the data according to their needs. Fault tolerance is also achieved with HDFS via its replication technique in Hadoop 2. While in Hadoop 3, Erasure coding helps to achieve this as it reduces the storage overhead by 50%. Erasure coding in Hadoop can be considered as an alternative storage where the data is split, expanded and encoded. With Hadoop 2, the replication factor enables how many copies shall be created across several systems. This helps the users to access the data from the replica of the same data when any machine goes down across any cluster.
Affordability
Affordability is a very crucial concept when it comes to dealing with big data. MapReduce programming framework along with Hadoop’s scalable design helps to achieve affordable storage and data processing. This makes the system highly cost-effective and scalable for exponentially growing data-driven businesses.
Fast-paced
With the MapReduce framework, massive unstructured and semi-structured data can be processed in a short period. This happens via Hadoop’s distributed data storage, which allows the processing of data to happen parallelly, across various clusters of nodes. MapReduce utilizes the Hadoop Distributed File System, which works as a mapping system for gathering the data to process it. These are placed on the same clusters enabling quicker data processing.
Based on A Simple Programming Model
One of the widely accepted technologies for processing big data is the Hadoop MapReduce. Programmers can create MapReduce applications that can handle the tasks quite efficiently and quickly. Built on a straightforward Java programming model, it is a very well-liked and easy-to-learn programming framework that enables anyone to simply get started to create the data processing model suiting their organization's requirements. As the users are not dependent on the computing distribution, using Hadoop MapReduce is fairly easier as the framework processes the data itself.
Parallel processing-compatible
With MapReduce, processing multiple tasks at the same time is quite easier. The various job parts related to the same dataset are parallelly processed in a manner that reduces the significant amount of time for a task to get completed. The tasks in MapReduce are partitioned to be processed as independent sub-tasks, which helps the program to run faster. This makes the data process easily handle each job. This offers processing of the tasks at a much faster rate.
Reliable
MapReduce in Hadoop is quite reliable as it replicates the datasets to other nodes in clusters every time the data is sent to a single node. This, in turn, enables there to be no downtime even if one node fails. The system can fully recover back, offering high availability and reliability to the users. As MapReduce framework uses Disk Checker, Directory Scanner modules, Block Scanner, and Volume Scanner it offers data trustworthiness. This ensures the users that their data is secure in the cluster as well as accessible from any machine over which the data was copied, even if the data becomes corrupt or your device fails.
Highly Available
In Hadoop, the data is replicated across the various nodes in the cluster, which ensures a fault tolerance feature for its users. When any Data Node fails or any event of failure occurs, the users will not experience any downtime and can easily start to access the data from any Data Node that contains copies of data in it. In the Hadoop cluster, there are more than one active as well as passive Name Nodes that run on hot standby. Here, the active node is the Name Node while the passive node is usually the backup node.
Top Uses of MapReduce
With this section of the article, we will highlight a few of the many use cases of MapReduce. MapReduce utilizes its power of parallel processing across the various nodes which results in merging and reducing the nodes and efficiently handling the huge volume of data.
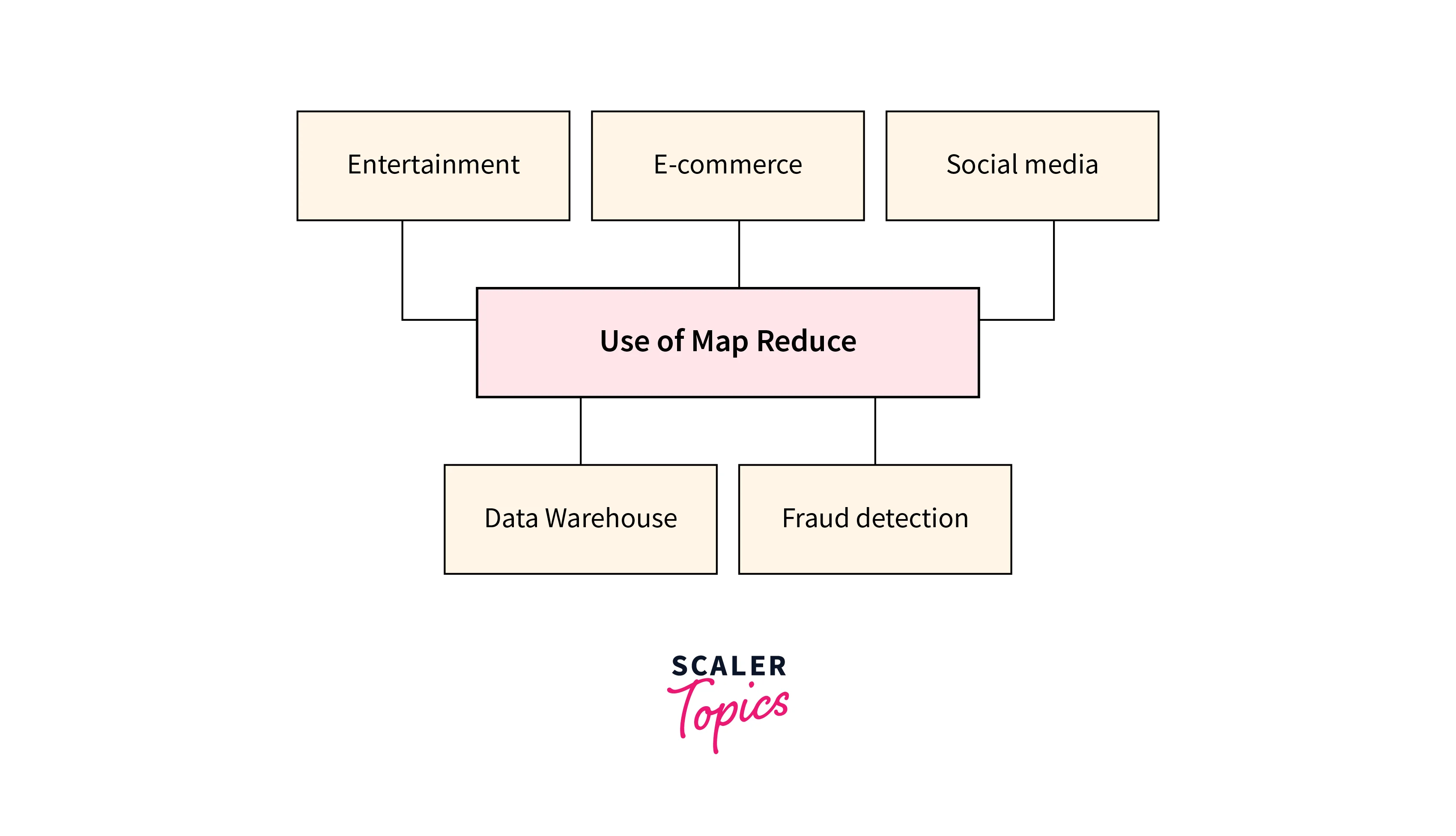
Entertainment
Entertainment platforms like Disney+ and Netflix frequently implement the Hadoop MapReduce framework to assist their end users in recommending them the movies or series based on their previous watch history.
To be able to work with data on an individual level, and offer a personal recommendation to the end users, these OTT platforms are unleashing the power of Hadoop MapReduce and concentrate on end-users' clicks and logs to understand their users and learn what genres they are interested in. It also suggests to the end users the series or movies to watch.
E-commerce
To understand customer buying behavior and recommend products they might have bought, searched or interacted with in the past, various e-commerce firms like Flipkart, Amazon and eBay, unleash the power of MapReduce. With MapReduce programming, customers can capture the popular products being sold based on the user's preference or push behavior that suggests those to them. The e-commerce organization is consistently using a huge volume of data and processing techniques like MapReduce to analyze data, user purchase history, as well as user interaction logs.
Social media
Social media is a crucial part of our society these days. Social media sites like Twitter, and Linkedin are using the Hadoop MapReduce framework for performing operations like filtering, tokenization, aggregate counters, and counting.
Let us understand each one by one.
- Tokenization:
In the tokenization process, the key-value pairs are created from the tokenized tweets/comments from the user's Twitter / Instagram account by mapping the tweets/comments, usually named as maps of tokens. - Filtering:
In the filtering process, all the unwanted data (key-value) are removed from the token maps. - Counting:
In the counting process, the mapped key-value pairs are counted against each distinct word count. - Aggregate counters:
In the aggregate counters, small and manageable pieces are created by grouping the processed comparable counter values.
Once this is done, the social media website can start using these aggregate counters to validate the number of sign-ups received over the past month from various countries. This helps to understand the popularity of social media websites across the globe.
Data Warehouse
As data in the data warehouse is huge, to get started with the data analysis, data analysts use the Hadoop MapReduce model for building customized business logic for tracking the data insights along with scanning the massive data volumes stored in the data warehouses. As storing the massive volume of data over a single node on the cluster is not a feasible solution, retrieving the data from various other nodes is important.
When entire data is loaded into a single cluster, it slows down the system and causes network congestion as well as slow query execution speeds. It is recommended that users replicate the data over various nodes when the dimensions are not too big, as it would maximize the parallelism. With the MapReduce Programming model, users can build specialized and defined business logic for specific data to generate insights while the huge volume of data is being analyzed at scale.
Fraud Detection
Traditional payments systems are audited by humans over a few sets of claims. Here, a user needs to manually go through a defined set of the records submitted. This is done for analyzing if any fraud is detected or not. But with Hadoop MapReduce, handling huge volumes of data is easier to accurately detect fraud by going over the huge amount of data and not just the specific samples submitted. Fraud detection plays a crucial role in banks, insurance companies, and payment gateways. MapReduce can recognize patterns, do an analysis on them, and also check for transaction analysis to perform business analytics.
Conclusion
- In the Hadoop architecture, MapReduce and HDFS are the two core components that make Hadoop so efficient and powerful when it comes to dealing with huge amounts of data.
- Affordability is a very crucial concept when it comes to dealing with big data. And to resolve this, the MapReduce programming framework along with Hadoop’s scalable design helps to achieve affordable storage and data processing.
- MapReduce works as a programming model in the Hadoop architecture where larger chunks of data are split and parallelly processed in a distributed manner across the various clusters. First the input data is split, processed as per requirement, and then aggregated to obtain the final result.
- The MapReduce task is broadly segmented into two phases: the Map Phase and the Reduce Phase.
- With the MapReduce framework, massive unstructured and semi-structured data can be processed in a short period. This happens via Hadoop’s distributed data storage, which allows the processing of data to happen parallelly, across various clusters of nodes.
- The data processing also happens where the data already exists rather than sending it explicitly where the logic resides; this expedites the processing. The input files given for processing contain structured, semi-structured, or unstructured data which once processed, is stored back in the files.