Hadoop MapReduce
Overview
MapReduce in Hadoop is a distributed processing framework that enables efficient processing of large datasets. It divides tasks into mapping and reducing phases, allowing parallel execution across clusters. It's a core component of the Hadoop ecosystem, ideal for batch processing and data analysis on commodity hardware.
What is MapReduce?
MapReduce in Hadoop is a programming model and processing framework used for distributed data processing and computation on large datasets. MapReduce is designed to efficiently process vast amounts of data across a cluster of computers in a scalable and fault-tolerant manner.
Algorithm
The "Map" stage and the "Reduce" stage are the two key phases that make up the MapReduce model.
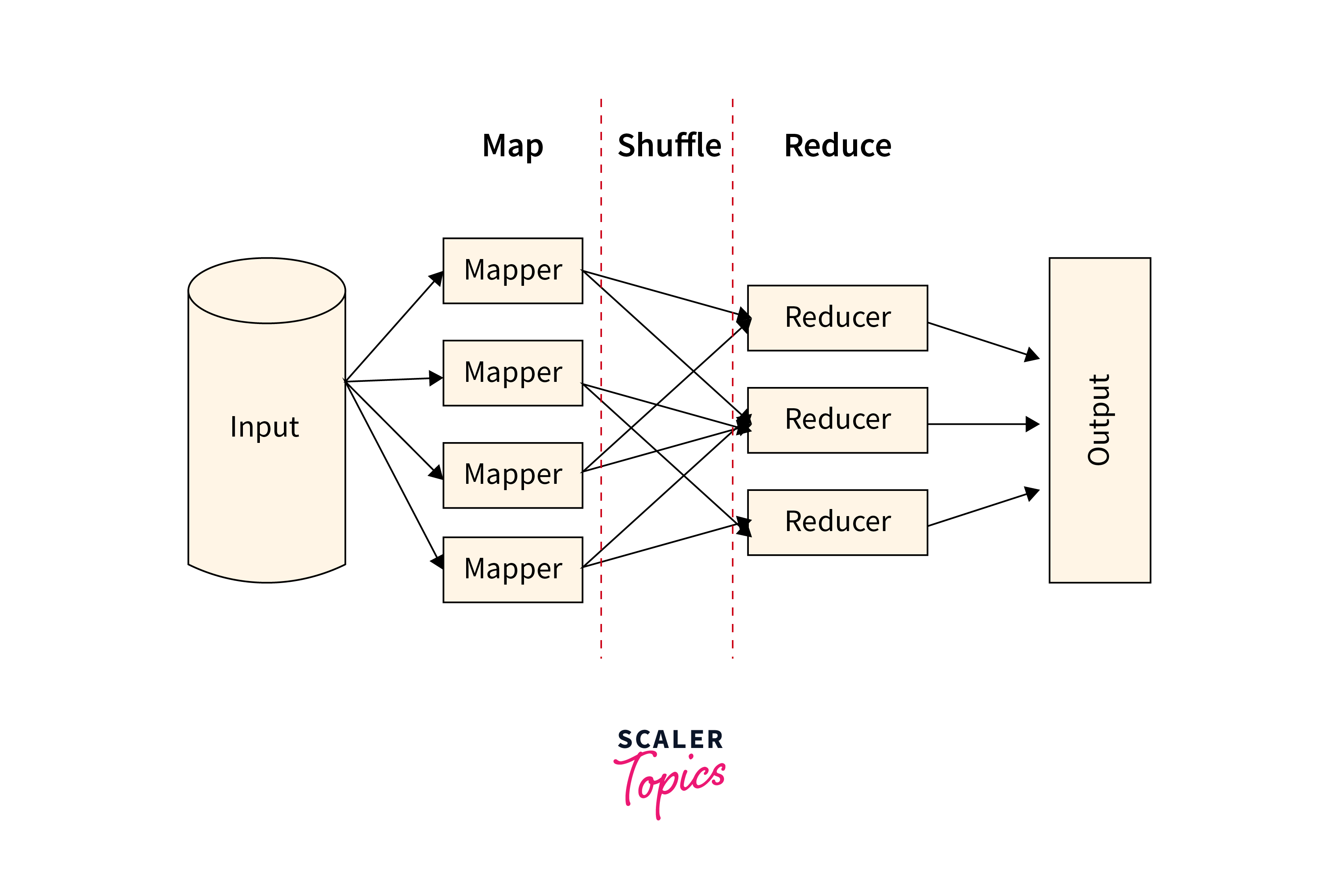
Map Stage
- Input data is divided into smaller chunks or blocks.
- Several worker nodes work in parallel to process each chunk independently.
- A "Map" function is applied to each data chunk, generating intermediate key-value pairs.
- The Map function's goal is to extract relevant information from the input data and prepare it for further processing.
Reduce Stage
- After the Map stage, the intermediate key-value pairs are grouped by key.
- The grouped key-value pairs are then shuffled and sorted based on their keys.
- The purpose of the shuffle and sort phase is to bring together all the intermediate values associated with the same key and make them available to the corresponding Reduce function.
- Once the shuffling and sorting are complete, a "Reduce" function is applied to perform aggregation, analysis, or other computations on the grouped data.
- The output is a set of final key-value pairs from the computation.
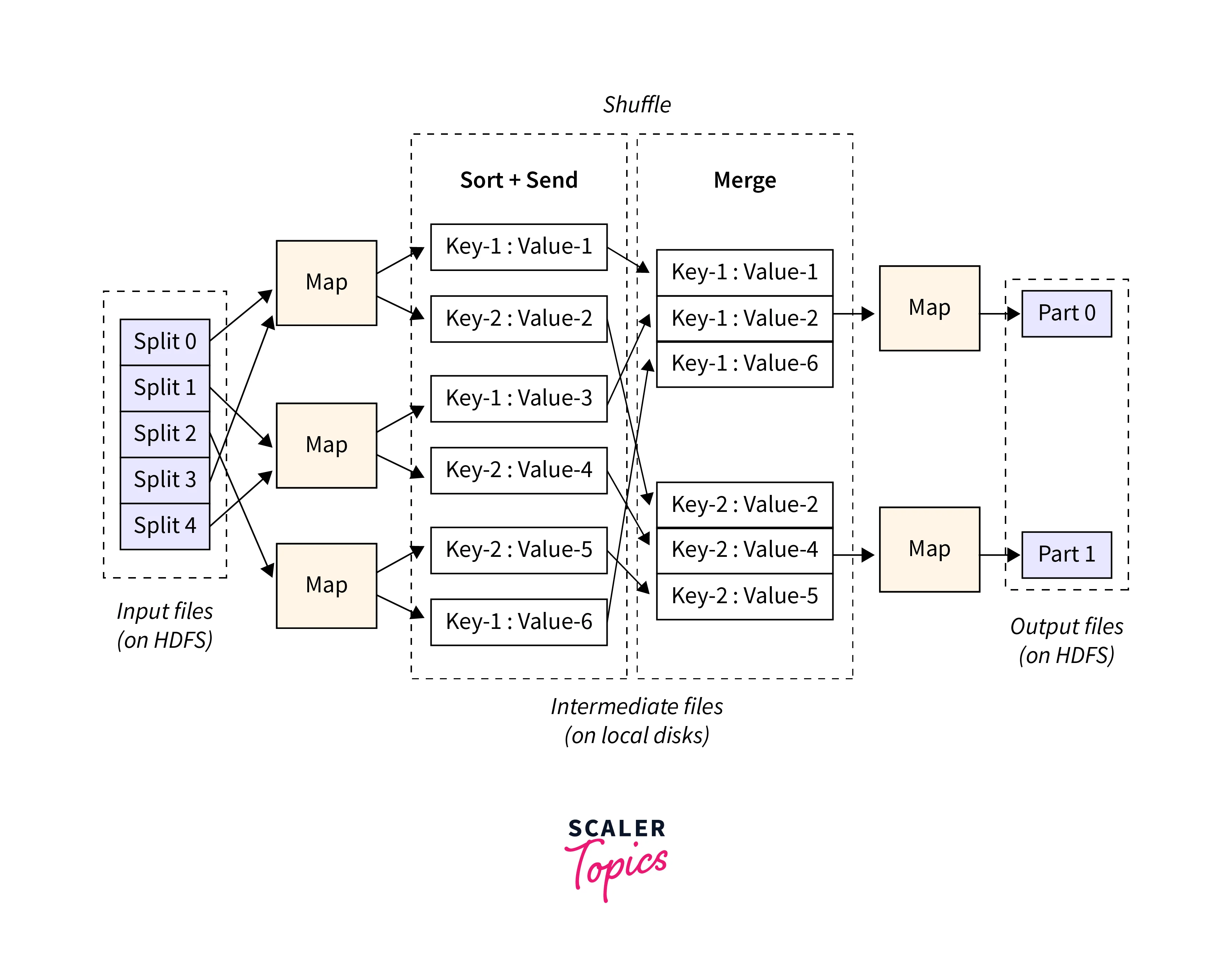
Inputs and Outputs
From a Java perspective, let's discuss the inputs and outputs of the MapReduce programming model.
Inputs:
In a MapReduce job implemented using Java, the inputs are typically represented as key-value pairs, where the keys and values are defined by the types you specify in your program. The input data is divided into smaller splits, and each split is processed by a separate map task. The key-value pairs are processed in the subsequent shuffle, sort, and reduce phases.
For example, in Hadoop's MapReduce framework using Java, the TextInputFormat is commonly used to process text-based input files. The keys represent the byte offset of the line within the file, and the values are the lines of text.
Outputs:
The outputs of the MapReduce job are also key-value pairs, where the keys and values can have different types based on the nature of the computation. The Reduce phase uses the Map phase's output as its input. The key-value pairs outputted by the Map phase are grouped by key during the shuffle and sort phase before being fed into the Reduce function.
In the Java programming model, you define the output types in your Map and Reduce functions. You emit key-value pairs from the Map function, and the framework takes care of grouping and sorting them for the Reduce phase.
The key-value pair in the Hadoop MapReduce framework using Java, the output types can be set using the job.setOutputKeyClass and job.setOutputValueClass methods. The Map and Reduce functions output key-value pairs using the context.write method.
Terminology
PayLoad
The actual data that is processed by MapReduce tasks, comprises input data, intermediate data, and output data.
Mapper
The initial processing unit in the MapReduce framework transforms input data into key-value pairs for further processing.
NamedNode
Also known as the NameNode, it is the central metadata repository in Hadoop's HDFS that manages the file system namespace and regulates access to files.
DataNode
A node in the Hadoop cluster is responsible for storing the actual data blocks and performing data read and write operations.
MasterNode
In the context of Hadoop MapReduce, the master node usually refers to the node running the JobTracker, which manages job scheduling and task distribution.
SlaveNode
In Hadoop, slave nodes are the worker nodes that perform the actual data processing tasks as directed by the master node.
JobTracker
The service is responsible for job scheduling and resource management in Hadoop MapReduce, ensuring efficient task execution across the cluster.
TaskTracker
The service on a slave node manages individual tasks, tracking their progress and reporting status back to the JobTracker.
Job
Represents a complete unit of work in Hadoop MapReduce, consisting of multiple tasks that need to be executed on the cluster.
Task
An individual unit of work within a job, encompassing either a Mapper task or a Reducer task.
Task Attempt
A single instance of attempting to execute a task, whether a Mapper or a Reducer. It captures the execution status and results of that attempt.
Example
Let's consider a simple word count example using Java.
Inputs:
Suppose we have two text files with the following content:
File 1 (document1.txt):
File 2 (document2.txt):

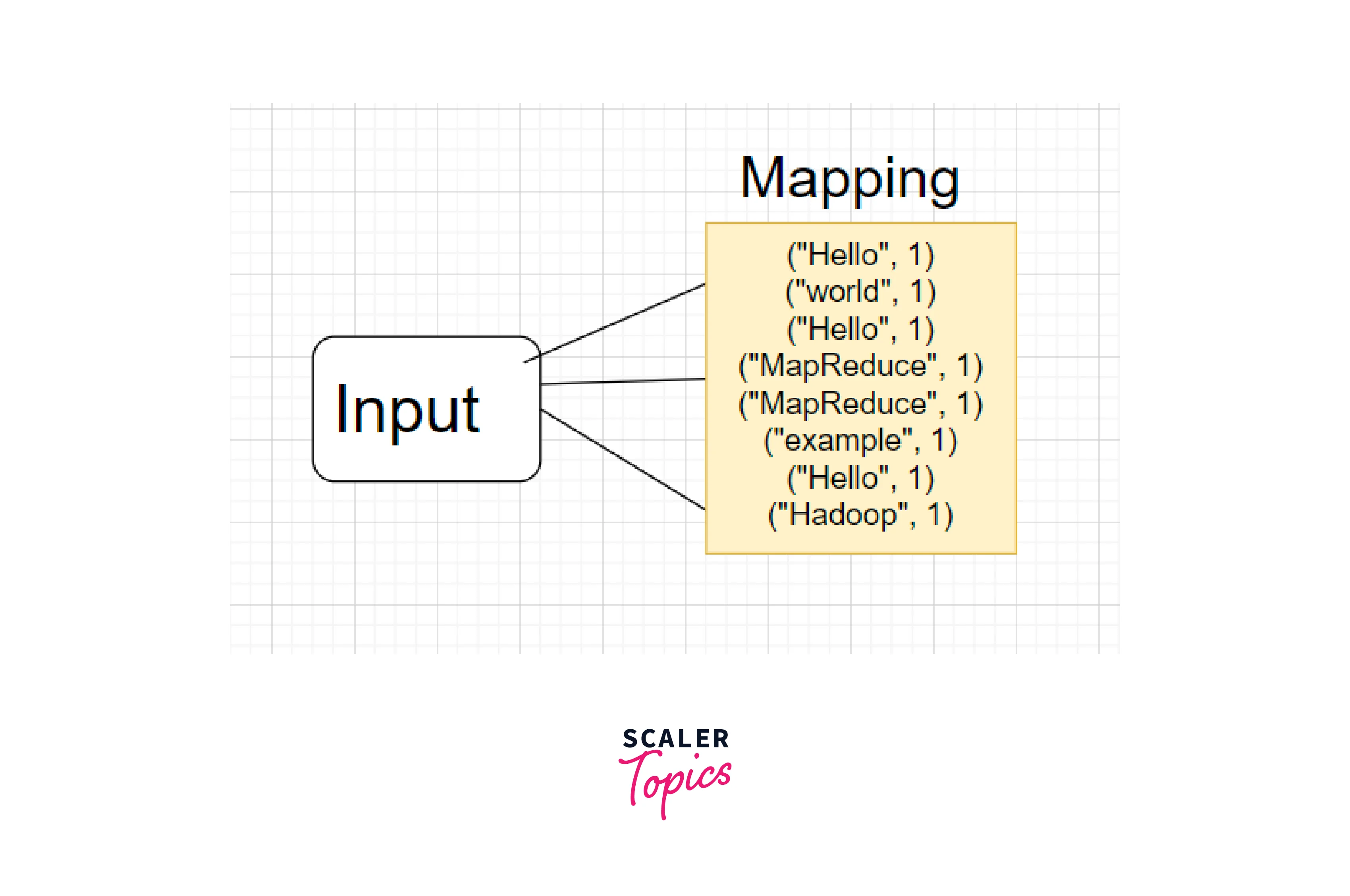
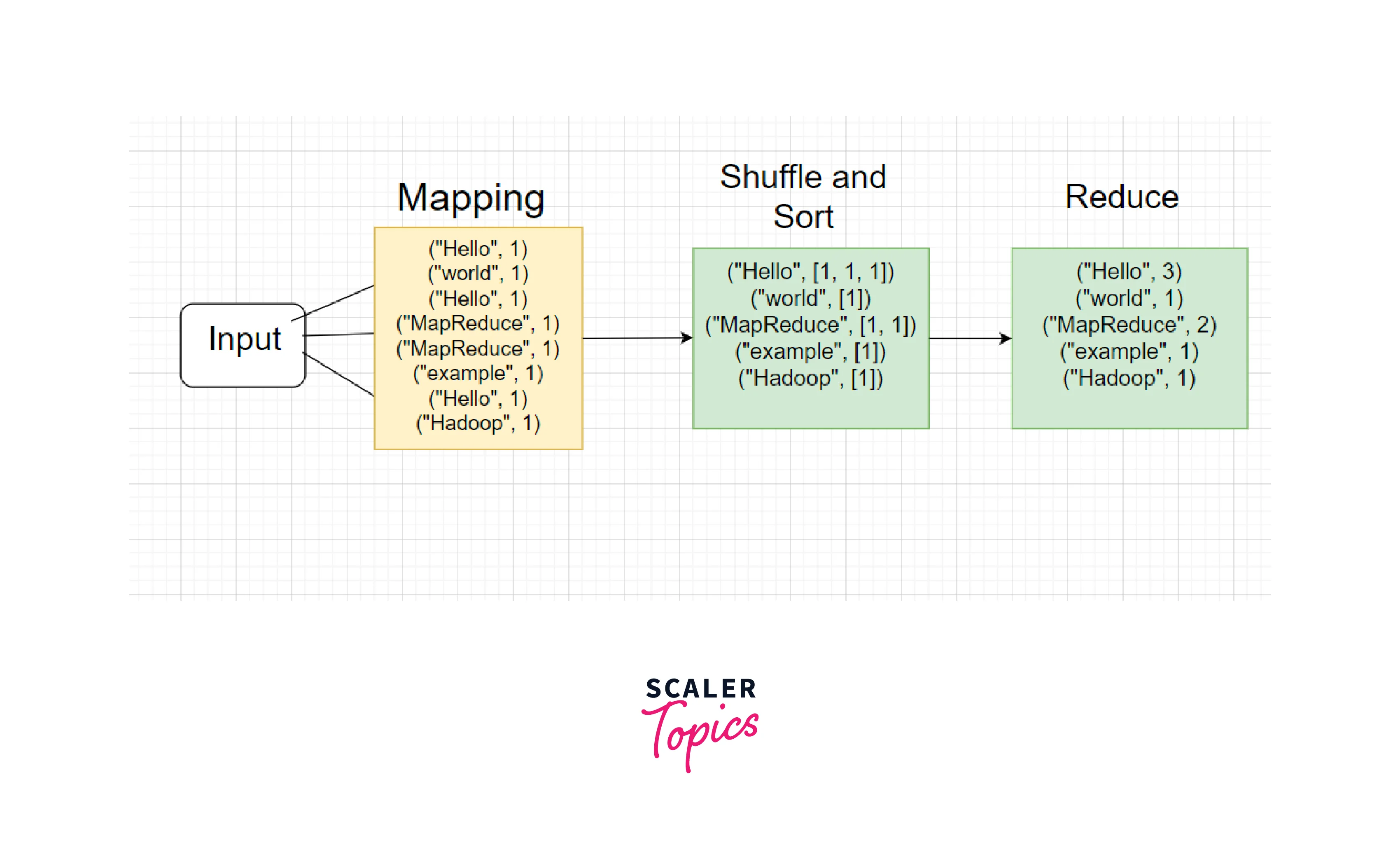
Map Phase:
The input data is processed by applying the Map function to each key-value pair. The Map function extracts individual words from the lines and emits key-value pairs where the word is the key and the value is the count of 1 for each occurrence.
For example, after the Map phase, the intermediate key-value pairs emitted could be:
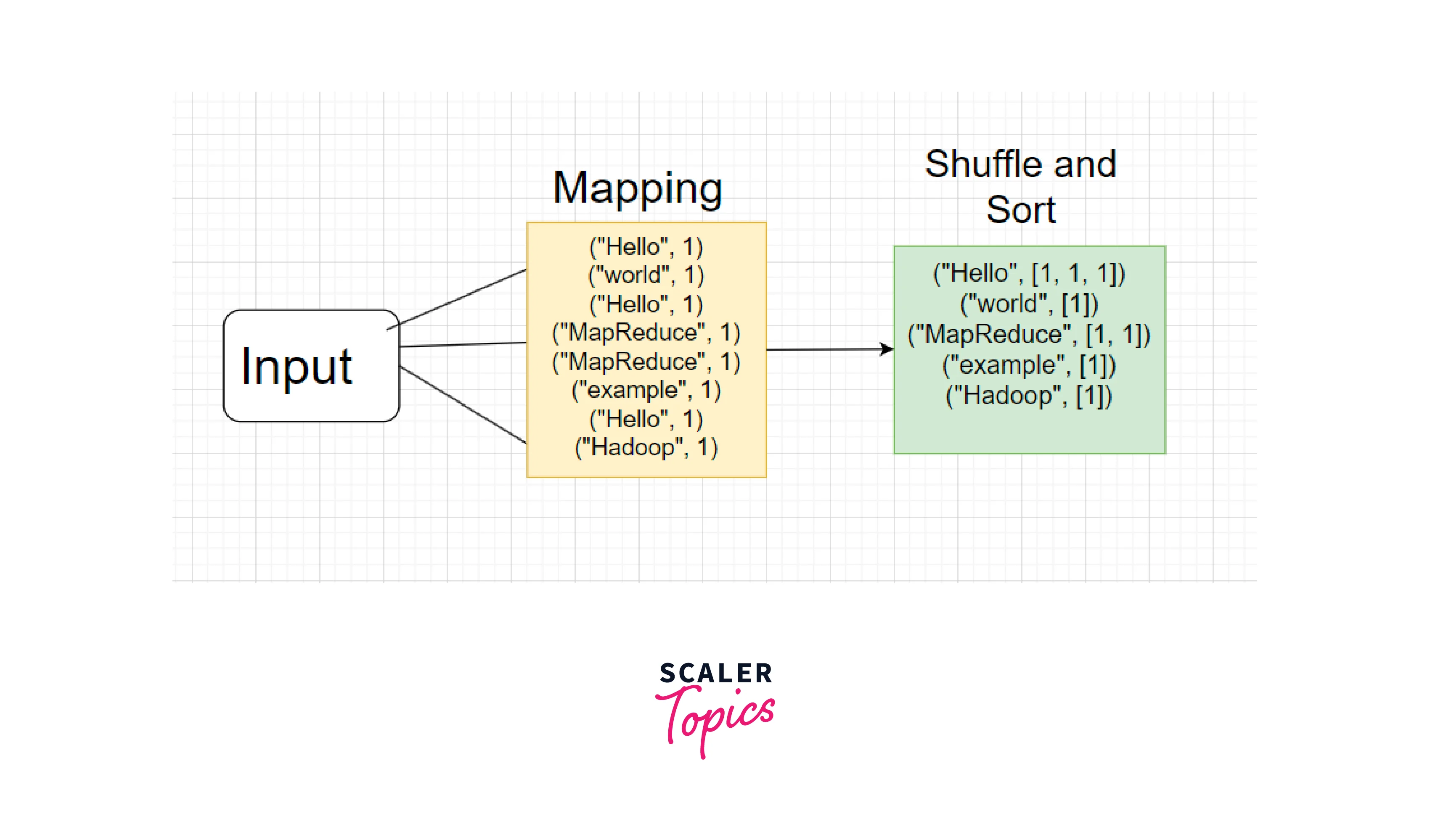
Shuffle and Sort:
The intermediate key-value pairs are grouped by key and sorted based on the keys that prepare the data for the Reduce phase.
Reduce Phase:
The grouped key-value pairs with the same key are aggregated to count for each word and emit the final output key-value pairs, where the sum of counts is the value.
Like below:
Compilation and Execution of Process Units Program
Here we shall use the word count example. Assuming you have Hadoop installed and configured on your system:
Step - 1:
Write the Java Code
First, you need to write the Java code for your Map and Reduce functions. Let's call the Java file WordCount.java.
Step - 2:
Compile the Java Code
Open your terminal and navigate to the directory containing your WordCount.java file. Compile the Java code using the following command:
Step - 3:
Create Input Data
Create a directory named input and place your input text files (document1.txt and document2.txt) inside it.
Step - 4:
Run the MapReduce Job
The following command is used to execute the MapReduce job:
Here, WordCount.jar is the compiled Java class, input is the input directory containing your text files, and output is the directory where the MapReduce job output will be stored.
Step - 5:
View the Output
After the job is completed, you can view the output:
This will display the word frequencies.
Important Commands
Here is a list of some common Hadoop commands, along with their descriptions:
- namenode -format:
Formats the Distributed File System (DFS) filesystem. - secondarynamenode:
Runs the secondary namenode for DFS. - namenode:
Runs the primary namenode for DFS. - datanode:
Runs a datanode for DFS. - dfsadmin:
Runs the DFS admin client for administrative tasks. - fsck:
Runs a DFS filesystem checking utility to validate the filesystem's health. - balancer:
Runs a utility to balance data across nodes in the Hadoop cluster. - jobtracker:
Operates the MapReduce Job Tracker node. - tasktracker:
Runs the MapReduce Task Tracker node.
How to Interact with MapReduce Jobs?
Interacting with MapReduce in Hadoop involves submitting and monitoring jobs, managing their execution, and retrieving the output.
Here are the steps to interact with MapReduce jobs:
- Compile and Package:
Before submitting a MapReduce job, you need to compile your Java code and package it into a JAR file along with any required dependencies. - Submit a Job:
- Use the hadoop jar command to submit a MapReduce job to the Hadoop cluster. Provide the path to your compiled JAR, the main class, and any required input and output paths.
- Example:
- Monitor Job Progress:
- Once the job is submitted, Hadoop provides a Job ID. You can use this ID to monitor the job's progress.
- Use the hadoop job -list command to see a list of currently running jobs.
- To track a specific job, use hadoop job -status <job_id>.
- View Job Logs:
- Hadoop records logs of MapReduce jobs. You can view these logs to troubleshoot issues and monitor progress.
- Use yarn logs -applicationId <application_id> to view logs of a running or completed job.
- Kill a Job:
If a job needs to be terminated prematurely, use the hadoop job -kill <job_id> command. - Retrieve Output:
- Once the MapReduce job is successful, you can retrieve the output from the specified output path.
- Use hadoop fs -cat <output_path> to display the output on the console, or hadoop fs -copyToLocal <output_path> <local_destination> to copy the output to your local machine.
- Monitor Job History:
- Hadoop provides a web-based Job History Server to view details about completed jobs, including their configurations, logs, and statistics.
- Access the Job History Server at http://<historyserver>:19888.
- Advanced Monitoring:
More advanced monitoring and visualization tools can be used, such as Ambari, Ganglia, and third-party solutions like Apache Zeppelin.
Conclusion
- MapReduce in Hadoop is a programming model and processing framework for distributed data processing on large datasets.
- MapReduce consists of two main stages: Map and Reduce. The Map stage processes input data and applies a Map function, and the Reduce stage processes the intermediate pairs and applies a Reduce function.
- DataNode: Stores actual data blocks in HDFS.
- MasterNode: Hosts JobTracker for task orchestration.
- SlaveNode: Executes Map and Reduce tasks.
- Job: Represents complete MapReduce execution.
- Task: Basic unit of computation in Hadoop.