Memory Management in Python

Memory management is pivotal in programming, not just in Python but across all languages. It involves handling the temporary data storage needed during program execution, such as variables and literals. As programs expand, efficient memory management becomes crucial to maintain speed and efficiency, especially in Python, which powers large-scale applications in Artificial Intelligence and Data Science.
Understanding Python's memory management, handled by its internal memory manager, is essential. This article focuses on CPython, a C implementation of Python, offering insights into memory management within an object-oriented context.
Python Memory Allocation
Python Memory Manager is responsible to manage memory allocation and deallocation to various processes that are under execution in python.
Every python process has two types of memory allocated to it
- Static Memory
- Dynamic Memory
All the functions we declare in python code has each of these memory associated with them.
Static Memory Allocation
Whenever a new function or class is declared it is very common to have some variable declaration inside them, these declarations are associated with the function itself and do not change in the runtime. They occupy a fixed memory size. Hence these are stored in the stack area.
So what is tall stack allocation? For every function call in python, there is a structure maintained in the memory of the process. This structure is called a function block. Python memory manager maintains a stack of such function blocks. When a function is called its function block is pushed onto this stack and on return, the same block is popped from the stack.
The below example demonstrates variables that are stored in the stack memory.
Dynamic Memory Allocation
The second type of memory available in a program is called heap memory. The heap memory is separate from the static stack memory, as this memory can be dynamically requested(allocated) and released(deallocated) in runtime. The memory size required for such variables cannot be determined beforehand, and hence it is called dynamic memory.
Here, heap memory has no relation to the data structure known as heap or heap tree, heap word is used as it refers to a block of memory where all data is kept unorganized.
The below code demonstrates the use of dynamic heap memory.
Memory Deallocation in Python
Python manages memory deallocation through reference counting and garbage collection. An object is removed from memory when its reference count drops to zero, releasing its memory back to the heap for future use. Python's garbage collector, which runs periodically, employs a mark-and-sweep algorithm to detect and eliminate objects no longer in use.
The process starts with marking all accessible objects that are still needed by the program. Following this, the garbage collector sweeps through the memory, deallocating all unmarked objects, thereby ensuring efficient memory use and preventing leaks. This system plays a crucial role in maintaining Python's memory efficiency and application performance.
Memory Optimization in Python
Python offers a suite of tools and techniques for optimizing memory usage, which is particularly beneficial for applications dealing with large data sets or requiring high efficiency.
-
Generators and Iterators: These are powerful tools in Python that generate items on the fly without needing to store the entire sequence in memory. This approach is memory-efficient, especially when processing large data streams or files.
-
Optimized Data Structures: Python's standard library includes modules like array and collections, which offer memory-efficient alternatives to standard data structures. For instance, array module allows for the creation of compact arrays, while collections includes specialized structures like deque and defaultdict that are designed for lower memory consumption.
-
The sys Module: This module provides access to some under-the-hood information about the Python interpreter, including functions to query the size of objects and the overall memory usage. This can be useful for identifying memory-intensive parts of the code and optimizing them.
While Python's memory management is largely automatic, leveraging these optimization techniques can lead to more efficient memory usage, especially in complex applications or those handling large amounts of data. In such scenarios, developers might also consider advanced strategies like memory pooling or object caching to further enhance performance.
The Default Python Implementation
Remember that Python itself is written in another language, the primary language used to implement python is C. CPython is the primary python implementation, as we say it is the default python implementation.
To understand memory management in python fully, we should take a deeper look at how Python is implemented in the C programming language. It is quite amusing how a purely object-based language python is implemented using C language, which does not have native support for object orientation.
We all know that everything in python is an object even the basic data types int, float, and string. To achieve this on an implementation level in C there is a struct named PyObject. The PyObject struct is inherited by every other object in python.
PyObject struct contains two essential properties:
- ob_refcnt- count of the total number of references to the current object
- ob_type - a pointer to the data type class of the current object
The reference count is used by the garbage collector to free up space for unreferenced objects. The type pointer points to the struct that contains the definition of the corresponding Python object like str or float.
All the objects created in Python have their corresponding memory allocators and deallocators that request memory whenever required and free it after the need is over.
As we speak about allocating and deallocating memory, it is important to know that memory is a shared resource, and there can be devastating results if two processes try to access the same memory location. To avoid such situations there is a rule in place known as the Global Interpreter Lock.
The Global Interpreter Lock (GIL)
The python interpreter has a multi-threaded model. It means that there can be more than one function executing parallel with each other. This brings into attention one of the biggest problem in computation, the concurrency.
Suppose two threads execute in parallel under the python interpreter, what happens when both these threads try to access the same memory location and at the same time. The result is called a race-around condition, where the output is completely unpredictable, and of no use.
To get around this problem of concurrency the python interpreter uses a concept called Global Interpreter Lock. The GIL locks the interpreter for one thread accessing a critical part of memory, while the lock is acquired no other thread can access the interpreter let alone perform any memory operations.
In CPython, the GIL is used to perform shared memory operations without any conflicts.
Python Garbage Collector
Recall that in CPython PyObject is the base for all other objects. It contains an attribute that has a total reference count for the object. This reference count is used to free up unused objects.
In python when garbage collection occurs all the objects with reference count zero are deallocated from the memory. This memory is thus freed and is now available inside the program heap.
The reference count increases in the following scenarios:
- on assigning a new name to the object
- on passing the object to a function as an argument
- on using the object inside a container like a dictionary or a tuple
The reference count decreases when:
- a function to which the object was passed returns
- the object is removed from its container
- execution flow goes out of the scope inside which the object was declared
A routine function called garbage collector is executed frequently to perform the memory cleanup.
Reference Counting in Python
In python, reference counting means how many references are currently present to the current object from other objects. As discussed previously the reference count increases after the operations that add more references to the current object. Similarly, the count decreases on the operations of dereferencing the current object. The memory is freed when the count becomes zero.
To understand the concept of reference count look at the example below.
The Python memory manager is of greedy nature, whenever we assign a variable to another variable, the interpreter does not allocate new memory space into the private heap of the python. Instead, it adds a new reference to the existing object in the heap.
The output of the above code is x and y refer to same object.
Take a look at the modified code below.
The output of the above code is x and y do not refer to the same object.
Here the variable y is allocated a new block of memory when an operation of addition is performed on it.
Transforming the Garbage Collector
In the previous section, we can see that reference count can be easily used to free up the memory occupied by those objects that have zero reference count. But there is a slight drawback to this method, the reference count does not allow us to resolve cyclic references. Thus the objects that are not used but have interdependency will never be disposed of from the memory.
To get around this python has introduced the concept of Generational Garbage Collector (GC).
The Generational Garbage Collector categorizes all the objects in three generations, for each generation there is a threshold value. The threshold value corresponding to a generation tells us the number of objects in that generation that are allowed to be present before the garbage collection occurs.
The garbage collector promotes an object to a higher generation whenever it survives a garbage collection cycle.
GC module in python allows us to manipulate and tweak the internal Garbage Collector. This module allows us to view the current number of objects in each generation using get_count() function. To manually trigger the garbage collection collect() function is used. To view and change the thresholds of each generation use the get_threshold() and set_threshold() function.
The example below demonstrates the use of gc module:
In the above example, we set the threshold values to 1200, 25, and 25 for the first, second and third generations respectively. This makes the garbage collector perform the collection cycle less frequently.
Learn more about Count() in python.
CPython Memory Management
CPython implements its own memory manager which can be used on top of the existing malloc available in the C language. This memory manager gives python an upper hand while allocating the memory to any new object that is created. The CPython's memory manager is optimized for small-sized data at a time. Since the data that is inserted or deleted in python is usually a single object or part of a collection like a list or a dict. The efficiency of CPython's Memory manager proves a great advantage over the traditional malloc.
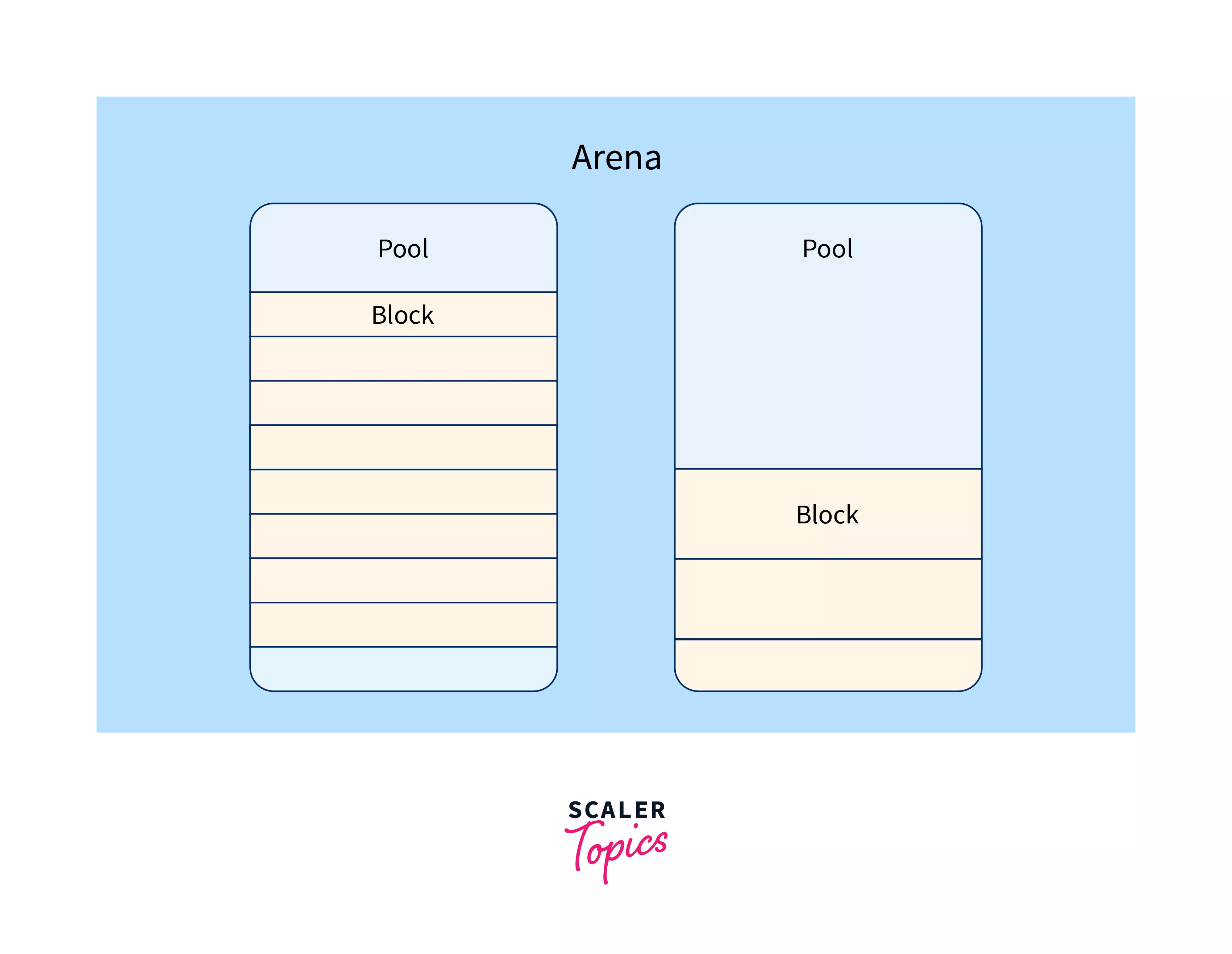
To achieve this efficiency the memory manager divides the memory available to the python process into three kinds of pieces
- blocks - being the smallest possible division of memory
- pools - is the set of a fixed number of blocks
- arenas - are the largest chunk of memory under which multiple blocks exists.
Applications of Memory Management in Python
Memory management plays a crucial role in Python programming, ensuring efficient memory use and preventing issues like memory leaks. Here's how it applies in various scenarios:
-
Optimizing Memory Usage: Python's garbage collector helps by freeing up unused memory, but it's also important to write memory-efficient code and choose appropriate data structures to minimize your program's memory footprint.
-
Preventing Memory Leaks: While Python's garbage collector typically manages memory well, avoiding cyclic references and ensuring proper memory release is key to preventing memory leaks, which can degrade performance.
-
Managing Large Datasets: In data science and machine learning, handling large datasets efficiently is essential. Using memory-efficient data structures and algorithms helps in processing these datasets without exhausting available memory.
-
Creating Efficient Web Applications: For scalable web applications, managing memory efficiently is vital. It ensures the application can handle numerous requests smoothly by optimizing memory usage and implementing effective caching strategies.
Conclusion
In the above article, we have completed the study of the following topics
- Execution processes utilize static stack memory and dynamic heap memory, with Python's default implementation in C.
- The Global Interpreter Lock (GIL) in Python ensures thread safety by preventing simultaneous memory access and mitigating collision risks.
- Python employs reference counting and generational garbage collection methods with adjustable thresholds to optimize program performance.
- CPython's memory management is structured into blocks, pools, and arenas, facilitating efficient memory allocation and management.