MongoDB Cluster
Overview
MongoDB Cluster mainly refers either to a sharded cluster or a replica set. Replication of MongoDB servers group having the same data copy is known as a replica set. Sharded Cluster in MongoDB is also called horizontal scaling, and in this, there is the distribution of data among multiple servers.
What is Database Clustering?
Database clustering is defined as the procedure of the connection of different instances or servers to a single database. A data cluster is needed when a large amount of data or the number of requests is not handled by a single server. Processes and memory collections that interact with the database are known as instances.
Advantages of Database Clustering
- Data Redundancy:
Database clustering allows different computers to get together for storing data amongst themselves. Data redundancy benefit is provided by it. Every computer has data similar to the data of all other nodes because all the nodes are synchronized. The redundancy feature provided by the clustering is guaranteed due to this synchronization. If in case any one computer fails then we have the same copy of data available to all other computers. - Load Balancing:
By default, scalability or load balancing is not included in the database. We can achieve it with the help of clustering regularly. The workload is divided among different nodes of the cluster in the load balancing. By this, a large number of users and high spike traffic can be easily handled. In all these situations handling becomes difficult if it is done by a single machine. The particular machine becomes overworked if there is no load balancing. And load balancing feature has a direct relation with the high availability. - High Availability:
The database is called accessible if we can access it. High availability is referred to as the time required for database access. And high availability can be easily achieved with the help of clustering of the database via extra machines and load balancing. - Monitoring & Automation:
Multiple processes of the database can be automated due to the database clustering and it also rules creation for potential issues alerts. By this, the requirement to go back and check everything manually is eliminated. Automation is also with database clustering; it enables notifications at the time of overloading of the system.
What is Database Clustering in MongoDB?
MongoDB Cluster mainly refers either to a sharded cluster or a replica set. Replication of MongoDB servers group having same data copy is known as a replica set, and it is considered as the fundamental feature for the production deployments as redundancy and high availability features are ensured by it and these features are considered very crucial for having in place in the planned maintenance periods and failover situations. Sharded cluster is also called horizontal scaling, and in this, there is the distribution of data among multiple servers. Reading and writing scaling along with different shards is the main object of the sharded MongoDB.
Replica Set Cluster
Replication is ensured by the MongoDB replica set by providing high availability and data redundancy over multiple MongoDB servers. All the data is available on the single server if there is a lack of replica set in the MongoDB deployment. And all the data would be lost if there is a failure of the server. And data loss can be avoided by the MongoDB replica set. And this is a requirement of the cluster for the MongoDB deployment. Apart from the fault tolerance feature provided by the replica set, extra read operation capacity is also provided by the replica set for the MongoDB Cluster and also reduces the MongoDB Cluster workload by directing clients to the other servers. Distributed applications have also benefited from the replica set because of the data locality feature provided by it as a result parallel and quick read operations can be performed to the replica set in place of going through the single main server.
How does it work?
For considering the MongoDB Cluster as the replica set there must be a primary node and a group of secondary nodes.
There is at most one primary node and that primary node work is receiving all the write operations to be performed. There is a special capped collection in which all the modifications of the data set of the primary node are stored and this collection is known as an operation log.
And the work of secondary nodes is to do the primary node operation log replication to ensure that the data set reflected is similar to the data set of the primary node.
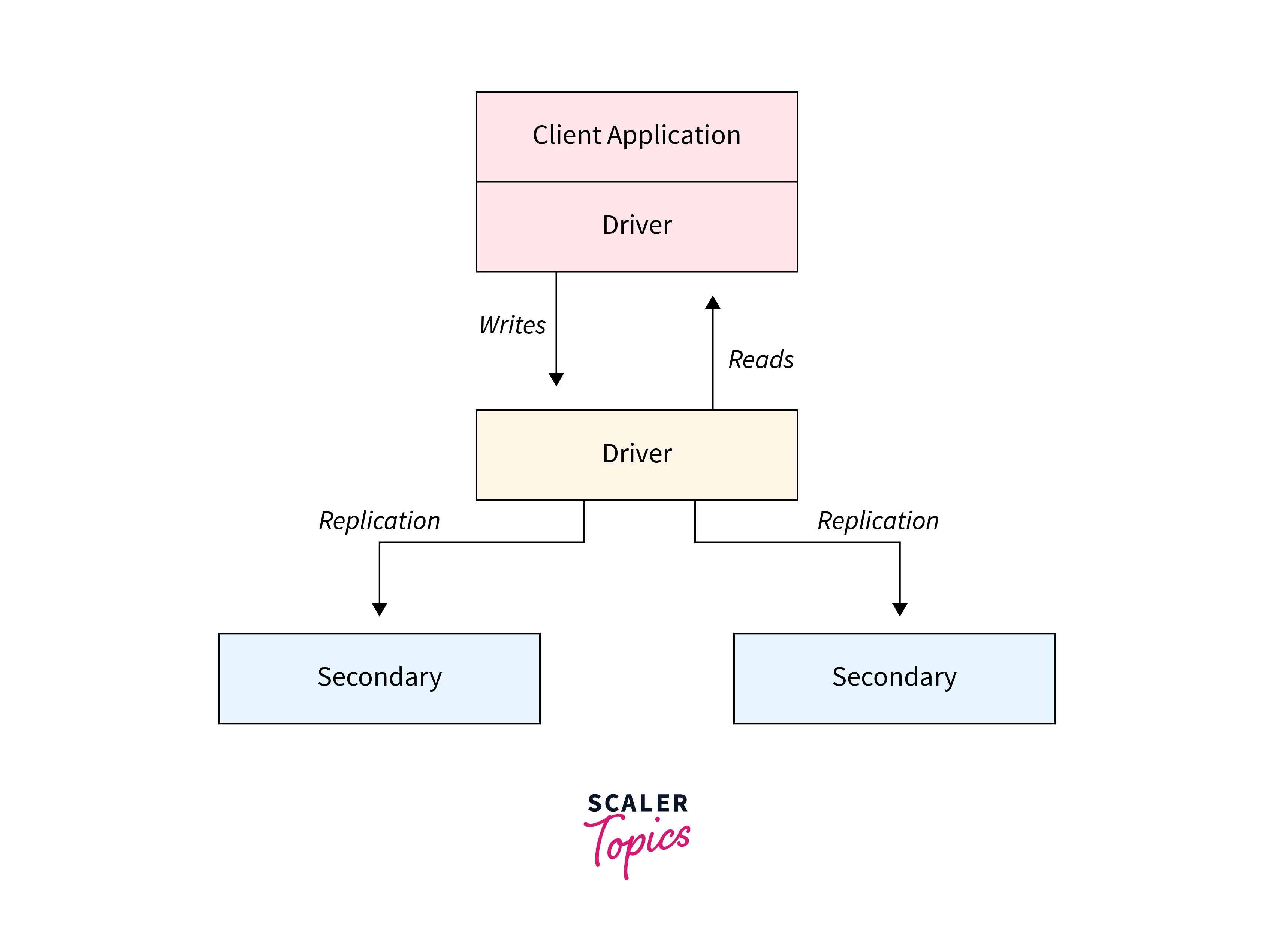
There is asynchronous replication of the oplog of the primary node to the set of secondary nodes by which the replica set is allowed to continue its work instead of one or more than one members failure. There is a location for selecting the new primary node in case the present primary node becomes unavailable. The replica set election does not only occur due to the failure of the primary node. It may occur due to some other reasons also such as the addition of new nodes in the replica set, the secondary node lost the connection with the primary node for more than the specified period (by default it is 10 sec), etc.
Write and Read Operations in Replica Sets
In the MongoDB Cluster, the replica set is transparent to the user as the user can not determine whether the replica set is enabled in the MongoDB Cluster or a single deployment server is used to run it.
Apart from that, extra read and write operations are also provided by MongoDB on top of standard IO commands. Optionally clients are also allowed to directly address the replica set for which the read operation is required to be performed. All the read operations are by default directed towards the primary node and we can also configure particular routing for the secondary nodes this is known as read preference.
While writing data in a MongoDB replica, you can also add some additional options to make sure that write will be run successfully. You can add a right concerned property with an insert operation.
And here write concerns refer to the acknowledgment level we want to have from the MongoDB Cluster on every write operation and the following options are included in it:
We can set the value of w to zero which means that no acknowledgment is required for the write operation and by default, the value of w is 1 which indicates that only primary node acknowledgment is required for the write operation. And if the value of w is greater than 1 then secondary nodes acknowledgment along with primary node acknowledgment is required. For instance, if the value of w is 6 then the write operation requires acknowledgment of 5 secondary nodes along with primary node acknowledgment. And the value of j indicates that in the write operation whether the MongoDb has written on the disk in the special area known as journal. wTimeout is the specified time for which the command should wait before providing any result and in the condition that it is not defined and if there is some network issue then the command will be blocked. So, It's better to set this value. Its value is measured in milliseconds.
Sharded Cluster
The sharded Cluster in MongoDB provides a horizontal scaling method by distributing your data on different replica sets. The request is sent by the client to the router if any read-and-write operation is required. And then the configuration server is used by the router to find the shard in which data is stored and then the request is sent to the appropriate MongoDB Cluster. The method of storing data records on various machines is known as sharding. Sharding makes it easy to manage large amounts of data. Let us make it understandable by an example. Suppose, you have a laptop that can store data up to 250 GB but if you store files of large size then it may affect the performance of your system. And the performance of the laptop degrades as more storage space is required. As commercial databases store the data, our application's data is also stored in the same way. Data stored on machines. We Use sharding to maintain the performance of these machines and also allow them to respond quickly. As the machine will grow over time. So, it will be unable to provide write and read throughputs and in the end, it provides the solution to the horizontal scaling problem. Throughputs are just a piece of data or units of information that can enter or exit a system. We can also define throughput as a unit of data that a system can process in a given period.
MongoDB Atlas Cluster
We can define the MongoDB Atlas cluster as a NoSQL database-as-a-service available in the public cloud (such as Amazon Web services, Google cloud platform, etc). You can set up a working MongoDB Cluster within a few clicks. It is a managed MongoDB facility and can be accessed from any web browser. If you want to connect with MongoDB then you do not need to install any software on your system as you can directly connect with it using the web user interface On the other hand, if you want to work with the command line, then you can create a connection with the help of the Mongo shell. And for this purpose, you have to configure the firewall present in the web portal so that it can accept your IP. Move to the security from the homepage and then move to network access. At last click on the “Add IP Address” option and finally, you can add your IP After that write the configuration settings given below in the Mongo shell command line.
How to Create Cluster in MongoDB?
It may be the possibility that your first intention is to plan for a production environment or design proof for application. But it is better if we first design a MongoDB Cluster on the MongoDB Atlas. The default setup is the deployment of the MongoDB Cluster along with the replica set in the case of the free tier. If you also want to enable sharding, then for this you have to separately enable this feature and also need to specify the number of shards you want.
- For creating MongoDB Cluster first of all login by entering your email id and password, and if you are a new user then log in after signing up with your details.
Refer to the below image for the login page.
- After login, a page will appear in which you have to click on the create button.
Refer to the below image for the page that appeared after login.
- Page that appeared after clicking the create button is given below. Now you select options according to your requirement.
Refer to the below image for the page that appeared after the create button.
Conclusion
- Database clustering is defined as the procedure of the connection of different instances or servers to a single database.
- Data Redundancy, Load Balancing, High Availability, and Monitoring & Automation are the advantages of database clustering.
- MongoDB Cluster mainly refers either to a replica set or a sharded Cluster in MongoDB.
- Replication of MongoDB servers group having the same data copy is known as a replica set.
- Sharded Cluster in MongoDB is also called horizontal scaling, and in this, there is the distribution of data among multiple servers.
- Replication is ensured by the MongoDB replica set by providing high availability and data redundancy over multiple MongoDB servers.
- MongoDB Atlas cluster is a noSQL database-as-a-service available in the public cloud (such as Amazon Web services, Google cloud platform, etc).
FAQs
Q. How is sharding different from replication?
A. Replication is the copying of the data set of the primary node to the secondary nodes and it leads to an increase in data availability. And sharding provides a horizontal scaling method by distributing your data on different replica sets.
Q. How sharding makes the management of large data sets easier? A. Sharding makes it easy to manage large amounts of data by storing data records on various machines.