Deploy, Run, and Install MongoDB on Kubernetes
Overview
MongoDB is a document-oriented database server. It is an open-source database server product that is used to store documents. Each component needed to use MongoDB on Kubernetes is described as making the collection accessible outside of Kubernetes. Moreover, how to use MongoDB's fundamental functions.
Creating distinct portions while comprehending the procedures is a terrific method to learn about Kubernetes and MongoDB as a newbie. In this article, we'll explore how to run, deploy, and install MongoDB on Kubernetes.
MongoDB and Kubernetes
The MongoDB Kubernetes operator enables the deployment and administration of MongoDB on Kubernetes by managing MongoDB resources like StatefulSets, Services, ConfigMaps, and Secrets. Kubernetes is a widely used container orchestration platform that can be used to manage MongoDB clusters on any distribution and infrastructure, whether on-premises or in the public cloud. The MongoDB Kubernetes Operator simplifies running and scaling clusters, regardless of your team's level of expertise with Kubernetes.
Integration
The MongoDB Kubernetes operator uses the Kubernetes API to manage MongoDB resources. It also integrates with other Kubernetes features like persistent volumes, network policies, and security contexts.
The MongoDB Enterprise Operator for Kubernetes allows self-management of MongoDB instances in Kubernetes, regardless of the deployment location, and can be supplemented with MongoDB Ops Manager or Cloud Manager for automation, backups, and monitoring.
MongoDB Kubernetes Operator
The MongoDB Kubernetes operator is a custom Kubernetes operator that manages MongoDB clusters on Kubernetes. With the help of these operators, we can use MongoDB on Kubernetes in a better way.
The MongoDB Kubernetes operator provides several benefits, including:
- Automated deployment and management of MongoDB clusters
- Simplified configuration and scaling of MongoDB clusters
- Integration with Kubernetes features such as persistent volumes, network policies, and security contexts.
Supported Features
Some of the key features supported by the Kubernetes MongoDB operator are:
- Standalone Instances: The operator keeps deploying standalone instances of MongoDB on Kubernetes.
- Replica Set Deployments: The operator supports deploying MongoDB replica sets on Kubernetes. Replica sets provide high availability and data redundancy by replicating data across multiple nodes.
- Sharded Clusters: Sharded clusters provide scalability by partitioning data across multiple nodes.
- Custom Resource Definitions: The operator defines custom resource definitions (CRDs) for MongoDB resources such as standalone instances, replica sets, and sharded clusters. These CRDs provide a declarative way to define MongoDB clusters and their associated resources.
- Rolling Updates: The operator supports rolling updates, allowing you to update MongoDB instances without downtime.
Prerequisites
Before you deploy MongoDB on Kubernetes, you'll need to have the following:
- A Kubernetes cluster with kubectl installed and configured.
- The MongoDB Kubernetes operator is installed on the Kubernetes cluster.
- A persistent volume provider such as AWS EBS or Google Cloud Persistent Disks.
Deploying a Standalone MongoDB Instance on Kubernetes
Deploying MongoDB on Kubernetes as a standalone instance is not recommended for production, only for testing and development purposes.
Follow the steps below to deploy MongoDB on Kubernetes standalone instance.
Step 1: Label the Node
Assign a label to the node for MongoDB deployment to later assign pods to that node. To do this,
- List the nodes on your cluster:
- Now, you have to choose the deployment node from the list.

- Now, label the node using kubectl with a key-value pair.
The output will be:

Step 2: Create a StorageClass
StorageClass helps in persistent pods provision.
To create a StorageClass, follow the following steps:
- To store the storage class configuration, you can use a text editor to create a YAML file.
- Include in the file the configuration for your storage class. The mongodb-storageclass is described in the following example:
- Save the changes now.
Step 3: Create Persistent Storage
For storing data for the MongoDB deployment by creating a persistent volume:
- To configure a persistent volume, create a YAML file.
- Use the previously established storage class to allocate space in the file. The node for pod deployment should be specified in the nodeAffinity section using the label made in Step 1 as its identifier.
- Create a new YAML file for the permanent volume claim configuration:
- Define the mongodb-pvc claim and tell Kubernetes to claim the mongodb-storageclass volumes.
Step 4: Create a ConfigMap
Pods' non-encrypted configuration data is stored in the ConfigMap file.
- To store deployment configuration, make a YAML file:
- Use a ConfigMap file to hold system paths, users, and roles. Here's an illustration:
Step 5: Create a StatefulSet
A Kubernetes controller called StatefulSet is used to deploy stateful apps that demand distinct identities for inter-pod communication.
For making a StatefulSet
- Make a YAML file using a text editor:
- Add information about MongoDB deployment, such as the Docker image and references to the ConfigMap and PersistentVolumeClaim files that were previously established, to the YAML file.
Step 6: Create a Secret
Sensitive information regarding the deployment is kept in the Secret object.
- Use your text editor to create a Secret YAML.
- Give instructions on how to access the MongoDB database.
- Save the changes now.
Step 7: Create a MongoDB Service
Following are the steps to create MongoDB Service:
- Make a headless service object first. Users can immediately connect to pods thanks to it.
- Include the service definition and name in the YAML file.
- Save the changes now.
Step 8: Using Kustomize to Apply the MongoDB configuration
To easily apply the MongoDB configuration files, we can use Kustomize.
- Make a kustomization.yaml file first:
- List all the YAML files produced in the preceding steps in the resources section:
In the same directory as the other files, save the file.
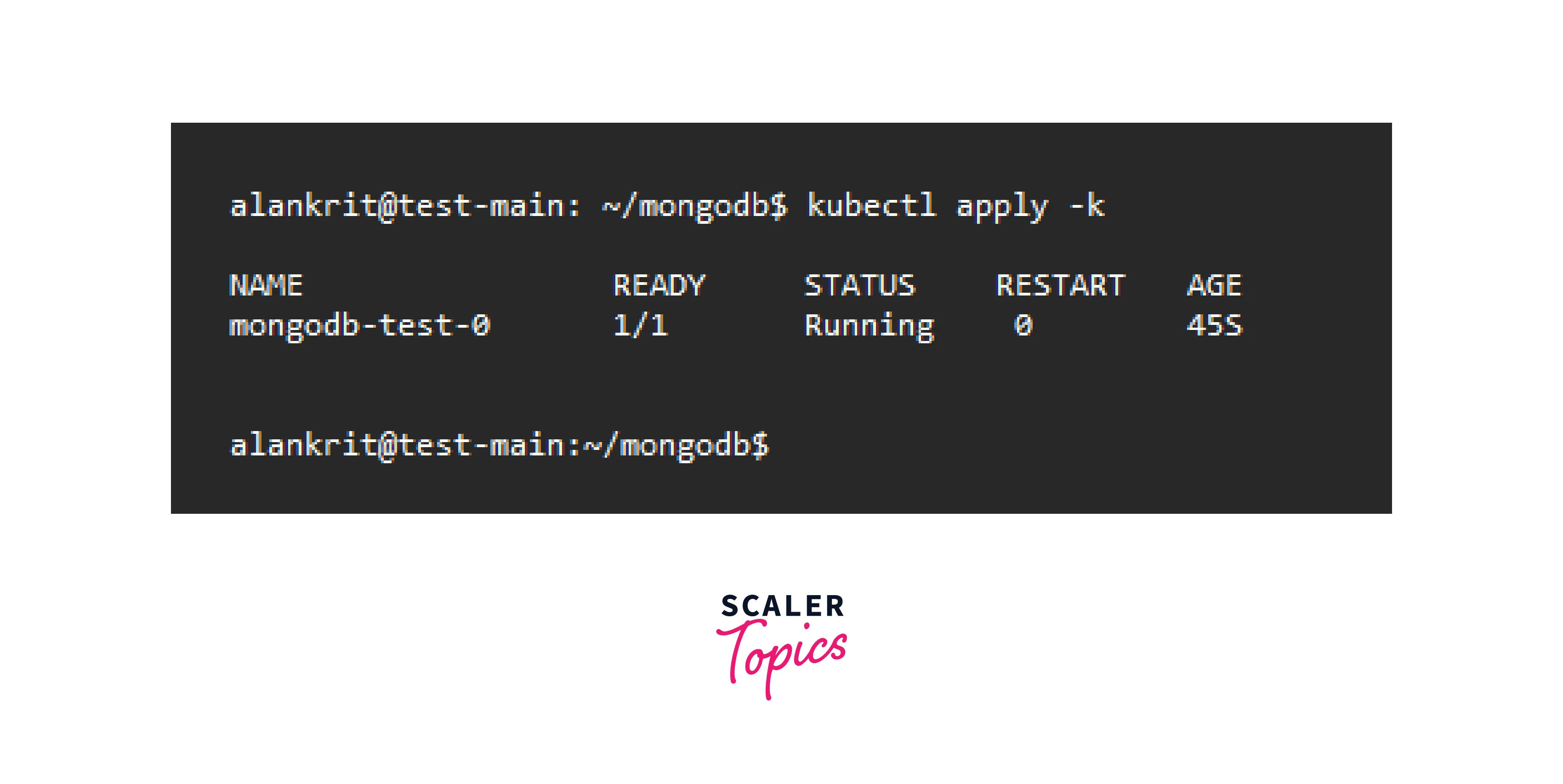
3. Use the following command to deploy MongoDB:

- Check whether the pod is prepared using kubectl.
Go to the next step when the pod displays 1/1 in the READY column.
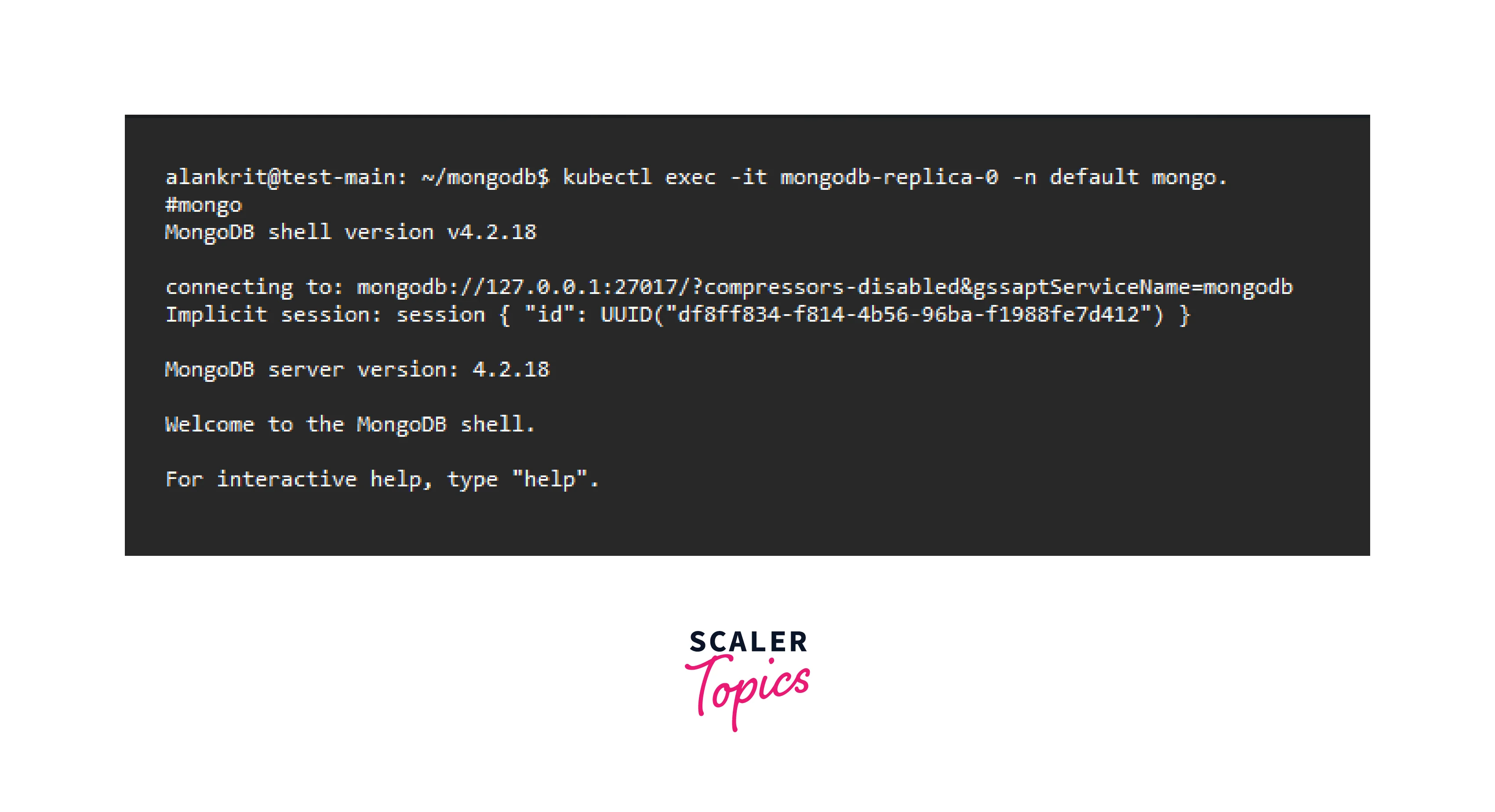
Step 9: Connect to a Standalone MongoDB Instance.
- Connect to the MongoDB pod by using the following kubectl command:
- When the # prompt appears, type:
MongoDB shell will load.
- Now Change to the test database:
- Use the following command to authenticate:
Number 1 in the output confirms the successful authentication.

ReplicaSet Deployment
Use a ReplicaSet to deploy MongoDB in production as it ensures a specified number of pods are always running.
Step 1: Set up Role-Based Access Control (RBAC)
RBAC is a Kubernetes security best practice that limits user permissions to only what is necessary, promoting better security.
To set up RBAC:
- Create a YAML file with a text editor.
- Access rules for MongoDB deployment using RBAC YAML file:
- Save the file and apply it with kubectl:
Step 2: Create a StatefulSet Deployment
- Create a StatefulSet deployment YAML:
- Specify replica count, MongoDB image, and volume claim template for dynamic volume provision in the file.
- Save the file and use kubectl apply to create a deployment:
Step 3: Create a Headless Service
To create a headless service:
- Create a service YAML file:
- Define a service that enables direct communication with pods:
- Apply the YAML with kubectl.
Step 4: Set up Replication Host
To set up pod replication:
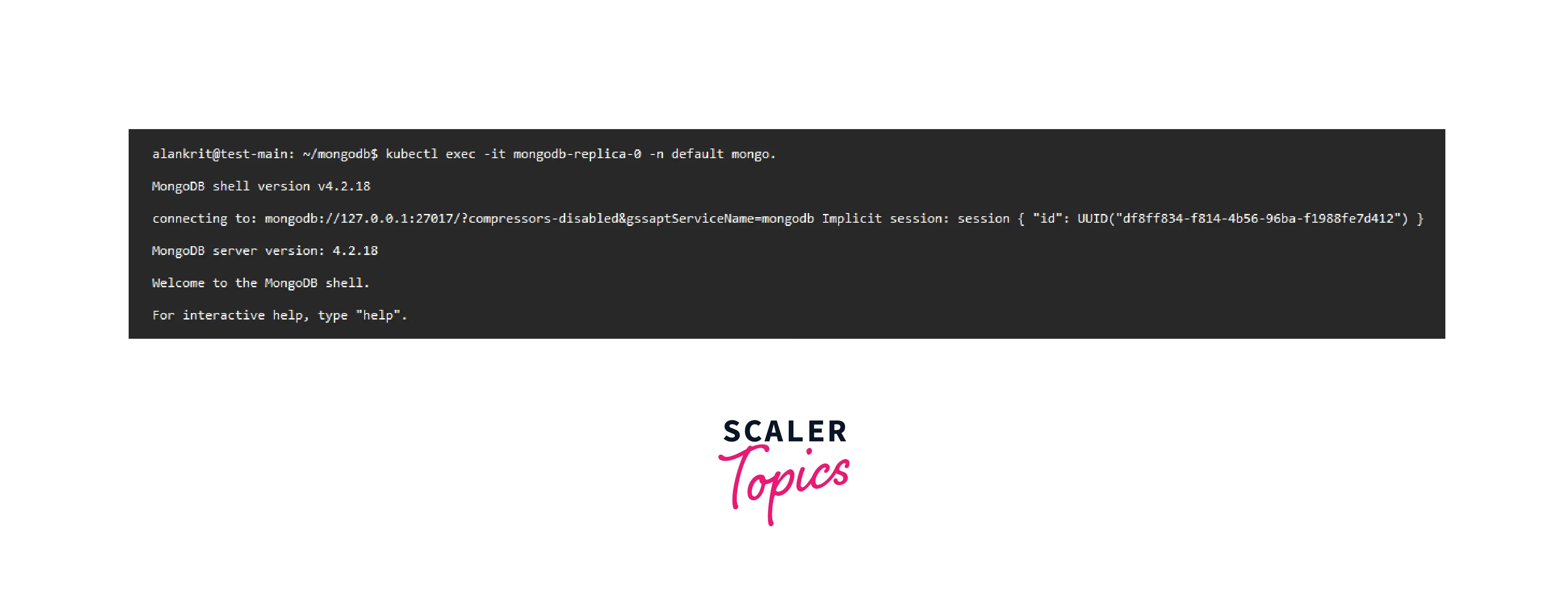
- Enter the pod usingkubectl exec:
Now, The message you’ll see on the MongoDB shell will appear.
- Initiate the replication by typing the following command at the MongoDB shell prompt:
The "ok" : 1 line shows that the initiation was successful.
- Initiate the replication by typing the following command at the MongoDB shell prompt:
The "ok" : 1 line shows that the initiation was successful.

- Define the variable called cfg.The variable executes rs.conf().
- Use the variable to add the primary server to the configuration:
The output shows the name of the primary server.

- Confirm the configuration by executing the following command:
The"ok" : 1 line confirms the configuration was successful.

- Use thers.add()command to add another pod to the configuration.
The output shows the replica was added.

- Check the status of the system by typing:
The members section should show two replicas, with the primary listed at the top.

The secondary replica is below the primary replica.
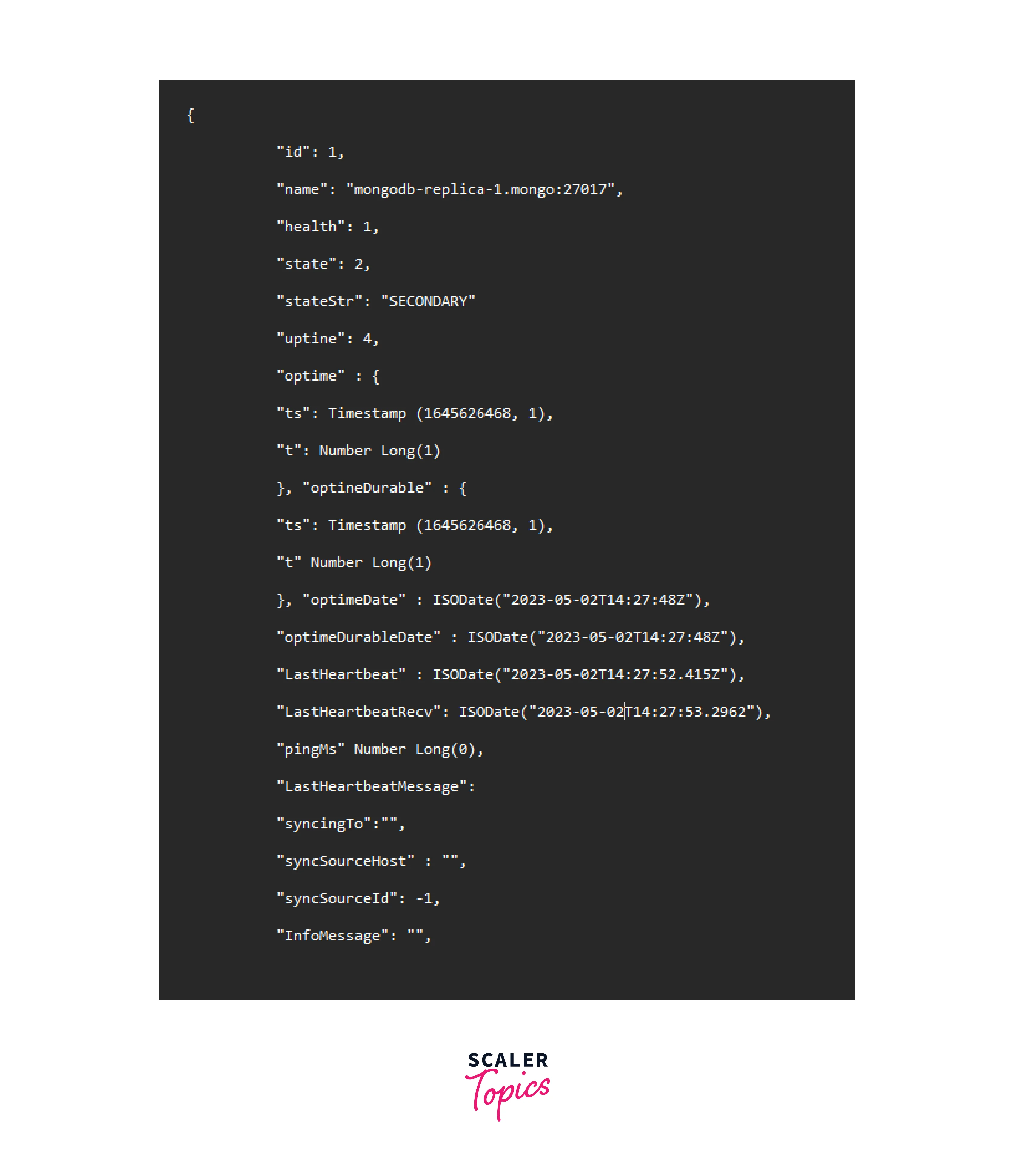
The ReplicaSet deployment of MongoDB is set up and ready to operate.
How to Connect MongoDB From Outside
To connect to MongoDB externally, expose the MongoDB service via a LoadBalancer or NodePort Kubernetes Service and connect using the service IP and port.
To access the database without a collection, create another Kubernetes Service. Services in Kubernetes are used for pod communication, and there are two types of ClusterIP services:
- Headless Services
- Services
Kubernetes standard services serve as load balancers and use round-robin distribution, while Headless services are not load balancers and do not have assigned IPs. Headless services are often used with statefulset applications.
For our MongoDB feed, create a NodePort-type service with port 32000 for shipping. Download the MongoDB service YAML as mongodb-nodeport-svc.yaml.
The mongo-nodeport-svc file will look like:

Create an svc file.
To connect to the Kubernetes cluster from outside, use the IP address of the cluster node or load balancer. For Minikube, use "minikube IP" to identify the IP address or service URLs.
Connect command:
At last, you'll see

FAQ
Q: What is the MongoDB Kubernetes operator?
A: The MongoDB Kubernetes operator is a custom Kubernetes operator that manages MongoDB clusters on Kubernetes.
Q: What features does the MongoDB Kubernetes operator support?
A: The MongoDB Kubernetes operator supports standalone MongoDB instances, replica set deployments, sharded clusters, custom resource definitions, and rolling updates.
Q: How do I connect to MongoDB from outside the Kubernetes cluster?
A: You can expose the MongoDB service using a Kubernetes Service of type LoadBalancer or NodePort and connect to the MongoDB instance using the service IP and port.
Q: What are the prerequisites for deploying MongoDB on Kubernetes?
A: Prerequisites for deploying MongoDB on Kubernetes include a Kubernetes cluster with kubectl, the MongoDB Kubernetes operator, and a persistent volume provider like AWS EBS or Google Cloud Persistent Disks.
Conclusion
- In this article, we covered how to install and deploy MongoDB on Kubernetes using the MongoDB Kubernetes operator, including prerequisites, deployment steps, and external connectivity.
- By using Kubernetes and the MongoDB operator, managing MongoDB clusters becomes easy.
- MongoDB and Kubernetes integration provides scalable and reliable solutions for managing MongoDB clusters in Kubernetes environment.
- MongoDB Kubernetes Operator simplifies deployment and management of MongoDB instances on Kubernetes.
- The operator supports automated backups, monitoring, and rolling updates.
- Before deploying MongoDB on Kubernetes, meet prerequisites like having a Kubernetes cluster and necessary permissions.
- Deploying a standalone MongoDB instance on Kubernetes using the MongoDB Kubernetes Operator involves several steps, including creating a MongoDB resource and a Kubernetes PVC, defining a Kubernetes pod, and exposing the MongoDB service.
- Deploying a MongoDB replica set on Kubernetes requires similar steps as standalone instance deployment, but with additional steps.
- Connecting to MongoDB from outside the Kubernetes cluster can be done using various methods, such as port forwarding, load balancers, or NodePorts.