Data Modeling in MongoDB
Overview
Data modeling plays a crucial role in MongoDB, a popular NoSQL database. MongoDB data modeling involves designing a structured representation of data and its relationships. It helps in organizing and managing data effectively within MongoDB, ensuring data consistency and optimizing performance. The data modeling in MongoDB includes identifying entities, attributes, and relationships and defining the schema. By leveraging MongoDB's flexible schema, data modeling in MongoDB allows for dynamic and scalable data storage. It supports various data modeling techniques, including document modeling, embedding, referencing, and denormalization. MongoDB data modeling enables efficient querying, data manipulation, and storage in MongoDB databases.
Introduction
Data modeling in MongoDB is creating a conceptual representation of data and its relationships to understand and organize information in a structured manner. It is a crucial step in the database design and development process, as it helps define the structure, rules, and constraints that govern the data within a system.
The primary goal of data modeling in MongoDB is to create a blueprint that captures the essential components of the data, its attributes, and the relationships between different data entities. This blueprint serves as a guide for designing and building a database or any other data management system.
Data models provide a high-level view of the data and its organization, allowing stakeholders to understand the data requirements and make informed decisions. They also act as a communication tool between business users, data analysts, database administrators, and software developers, ensuring that everyone involved has a common understanding of the data and its structure.
Data modeling involves several key components and techniques, such as:
- Entities: Represent real-world objects, such as customers, products, or orders. Entities in data modeling represent real-world objects, including tangible (physical) and intangible (abstract) entities. Tangible entities are observable and measurable, such as customers, products, or orders. Intangible entities are conceptual and represent relationships or rules, like the customer-order relationship or business constraints. Both tangible and intangible entities are vital for creating a comprehensive data model that accurately represents the system or domain. They define the structure, relationships, and rules within the data model, enabling effective data management and application development.
- Attributes: Describe the properties or characteristics of entities, such as name, age, or price.
- Relationships: Define the associations and dependencies between entities, such as a customer placing an order.
- Keys: Identify unique identifiers for entities, such as primary keys, which ensure each record has a distinct identity.
- Cardinality: Describes the number of instances in a relationship, such as one-to-one, one-to-many, or many-to-many.
- Normalization: The process of organizing data to minimize redundancy and ensure data integrity by eliminating data anomalies.
Data modeling can be performed using various notations and tools, such as Entity-Relationship (ER) diagrams, Unified Modeling Language (UML), or specialized data modeling software.
What does Data Modeling Mean?
Data modeling refers to creating a structured representation of data and its relationships. It involves designing a blueprint that captures the essential components of the data, such as entities, attributes, and relationships. Data modeling helps stakeholders understand and organize data effectively, facilitating communication and collaboration. It plays a crucial role in database design, ensuring data integrity, and supporting application development. By providing a visual representation of data requirements and constraints, data modeling aids in maintaining consistency, optimizing storage, and enabling efficient data management and analysis. It is a fundamental step in the data management lifecycle, promoting effective data governance and decision-making.
Why is Data Modeling Used?
Data modeling is used for several reasons in the field of data management. Here are some key reasons why data modeling is essential and widely used:
- Understanding and Documentation: It helps stakeholders understand and document the structure of data, facilitating communication and comprehension of complex systems.
- Database Design: It provides a blueprint for designing databases, ensuring well-structured and optimized data storage and retrieval.
- Data Consistency and Integrity: It maintains data consistency and integrity by defining relationships and enforcing constraints, improving data quality.
- Application Development: It supports the development of data-driven applications, aligning functionality with the underlying data structure.
- Data Integration and Interoperability: It enables data integration and seamless data exchange between systems by modeling data sources and relationships.
- Data Analysis and Reporting: It aids data analysis and reporting activities by providing a structured representation of data.
- System Maintenance and Evolution: It assists in maintaining and evolving data systems, ensuring consistent and controlled modifications.
What are the Steps of Data Modeling?
Data modeling steps can vary depending on the specific methodology or approach being followed. However, in general, the data modeling process typically involves the following steps:
- Requirement Gathering: Gather information from stakeholders to understand the data requirements, purpose, scope, and objectives of the data model.
- Conceptual Data Modeling: Create a high-level model that represents business concepts, entities, and relationships without implementation details.
- Logical Data Modeling: Refine the conceptual model into a detailed representation by identifying entities, attributes, and relationships and normalizing the data to ensure integrity. Use modeling techniques and notations to document the model.
- Validation and Review: Review the logical data model with stakeholders, validate it against real-world scenarios and business rules, and make necessary revisions based on feedback.
- Physical Data Modeling: Translate the logical data model into a physical data model that considers the implementation aspects of a specific database management system. Define tables, columns, and data types and optimize the model for performance.
- Implementation: Collaborate with database administrators and developers to create the actual database schema, tables, and relationships based on the physical data model.
- Documentation: Document the data model comprehensively to facilitate future understanding, maintenance, and modification.
- Iterative Refinement: Continuously review and update the data model as new requirements or changes emerge, ensuring it reflects any updates in business processes, data sources, or application needs.
What is an example of data modeling?
Let's consider a simplified example of data modeling for a university's student management system. We'll focus on a few key entities, attributes, relationships, and their representations using an Entity-Relationship (ER) diagram.
ER Diagram Representation:
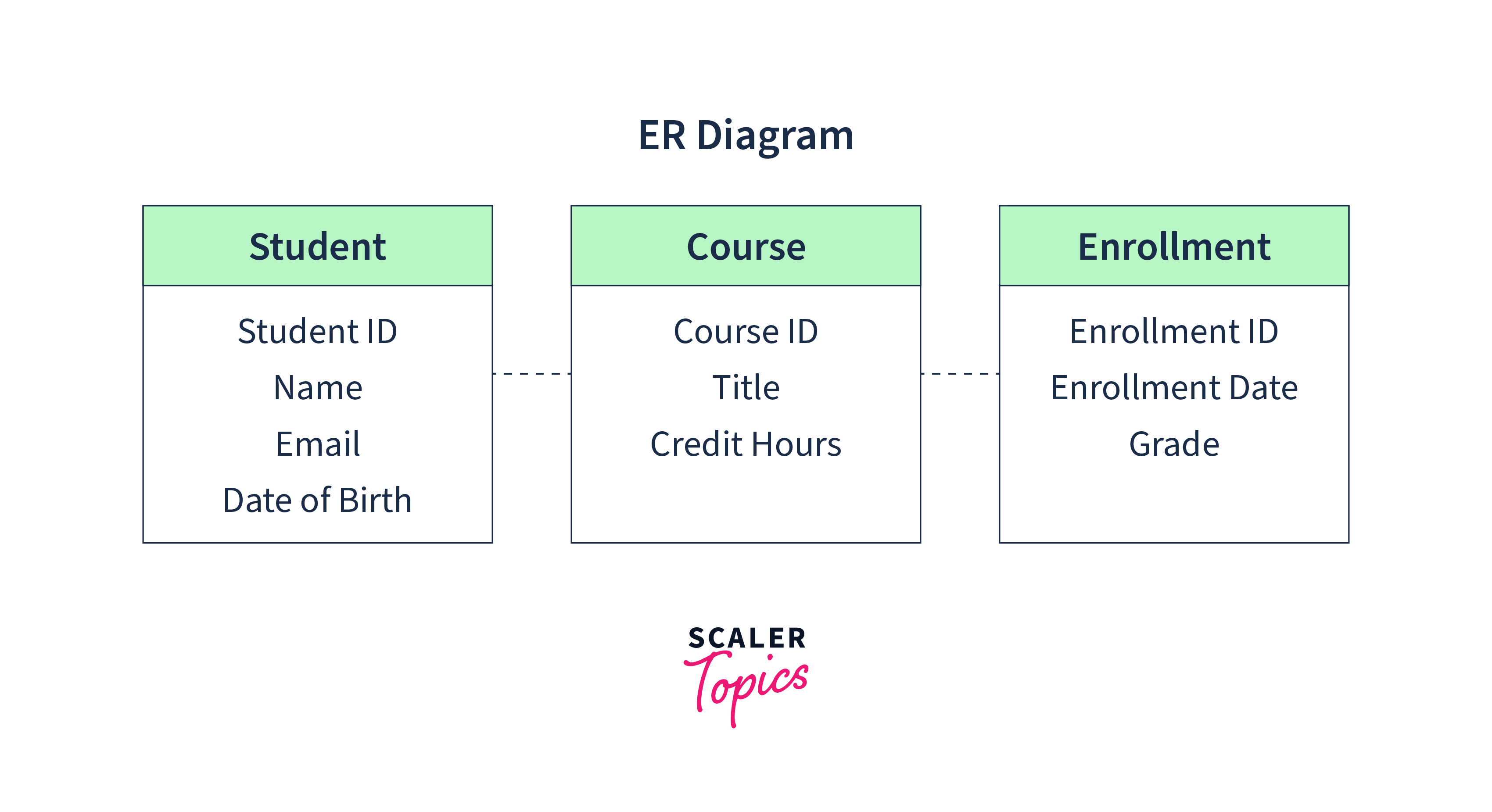
Entities:
- Student: Contains attributes like student ID, name, email, and date of birth.
- Course: Includes attributes like course ID, title, and credit hours.
- Enrollment: Represents the enrollment of a student in a course and contains attributes like enrollment ID, enrollment date, and grade.
Relationships: Many-to-Many Relationship: A student can enroll in multiple courses, and a course can have multiple students enrolled. This relationship is mediated through the Enrollment entity.
Attributes: Primary Keys: Each entity will have a primary key attribute (e.g., student ID, course ID, enrollment ID) that uniquely identifies each record in the respective entity. Foreign Keys: The Enrollment entity will have foreign keys referencing the Student entity (student ID) and the Course entity (course ID).
Normalization: Normalization ensures data integrity and eliminates redundancy. In this example, we can ensure that student information is stored in a separate table to avoid duplicating student data for each course enrollment.
In this example, the data model represents the relationships between students, courses, and enrollments. It captures the entities, attributes, and relationships involved in the student management system. This data model serves as a guide for designing the database schema, ensuring data consistency, and supporting various operations such as querying student information, course enrollment, and grade management.
Different Types of Data Model Designs
There are several types of data model designs that are commonly used in the field of data management. Here are some of the most widely recognized types:
- Hierarchical Data Model: Organizes data in a tree-like structure with parent-child relationships.
- Network Data Model: Allows for complex relationships with many-to-many connections.
- Relational Data Model: Organizes data into tables with rows and columns, establishing relationships between tables using keys.
- Entity-Relationship (ER) Model: Represents relationships between entities using entities, attributes, and relationships.
- Object-Oriented Data Model: Represents data as objects with properties and behaviors used in object-oriented database systems.
- Object-Relational Data Model: Combines relational and object-oriented features to store and manipulate structured and unstructured data.
- Dimensional Data Model: Specifically designed for data warehousing and business intelligence, organizing data into dimensions and fact tables.
- NoSQL Data Model: Designed to handle large volumes of unstructured or semi-structured data, with flexible schemas for dynamic storage.
Conclusion
- Data Modeling in `MongoDB, or MongoDB Data Modeling, is crucial for efficient data management and application development.
- Following best practices in MongoDB Data Modeling optimizes performance and scalability.
- Different data model designs and MongoDB's flexible schema contribute to well-structured data models.
- Proper MongoDB Data Modeling techniques, such as document modeling and denormalization, enhance performance and data integrity.
- Continuous refinement of data models in MongoDB ensures alignment with evolving requirements.
- `MongoDB Data Modeling empowers organizations to leverage their data effectively and make informed decisions.