MongoDB Aggregation Pipeline
Overview
The MongoDB aggregation pipeline is a powerful feature that enables efficient data management and querying. It is a framework for data aggregation that allows you to process and analyze large volumes of data flexibly and efficiently. This article provides a comprehensive introduction to the MongoDB aggregation pipeline using MongoDB aggregation pipeline examples and will help users to leverage its power for scalable and reliable data analysis.
Understanding Aggregation Pipeline in MongoDB
MongoDB aggregation pipeline is a powerful framework for processing and analyzing data in MongoDB. It allows you to filter, group, sort, project, and perform a variety of other operations on your data to generate meaningful insights. In this article, we'll take a closer look at the Aggregation Pipeline and its different stages.
Examples
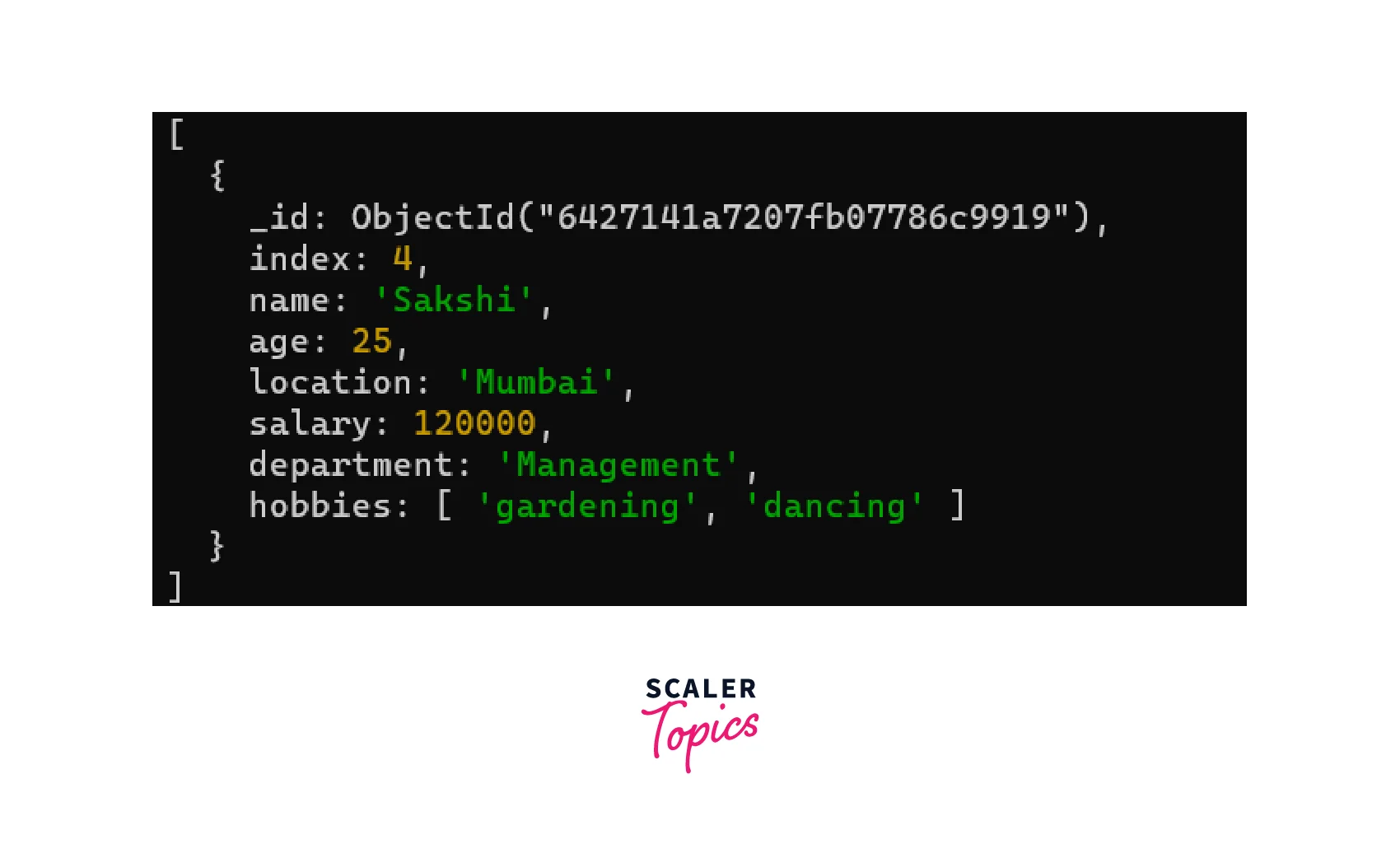
Let's say we have a database called Employee and a collection called Records. To populate our database, we will use the insertMany operation. The insertMany() method is used in MongoDB to insert multiple documents into a collection. Its syntax takes an array of documents as its parameter, with each document represented as a JavaScript object. Let's populate our database with the document given below:
The aggregate function in MongoDB is used for data processing and aggregation. Its syntax consists of an array of stages that define the processing pipeline. Each stage is represented as a JavaScript object with a key-value pair that represents the stage's operation and its corresponding parameter(s). The pipeline is executed in order, with the output of each stage passed to the next stage. The final stage returns the result of the aggregation.
Here's an example syntax of the aggregate function in MongoDB:
This syntax represents a sample pipeline with some of the most common stages used in the aggregation framework. The $match, $group, $sort, $project, $limit, and $skip stages are used to filter, group, sort, project, limit, and skip the results of the aggregation, respectively.
Let's find the total number of employees in each department. We can do that using the $group operator to group the documents by the department field and the $sum operator to calculate the total count of documents in each group.
Here's the query:
The output we get is:

In this example, we used the $group operator to group the documents by the department field and calculate the count of documents in each group using the $sum operator. The id field in the $group operator specifies the field to group by, and the count field in the $group operator specifies the name of the field that will contain the count for each group.
Here's another simple example of the same collection that demonstrates the usage of the $match and $project stages in the MongoDB aggregation pipeline:
Let's say we want to find all employees who are located in Hyderabad and have a salary greater than or equal to 80,000. We can use the $match operator to filter the documents that match the criteria, and the $project operator to project only the required fields in the output. In the $project stage, 1 and 0 are used to indicate whether to include or exclude a particular field. In the given query, the "_id: 0" indicates that the "_id" field should be excluded from the output document. Similarly, "name: 1", "location: 1", and "salary: 1" indicate that these fields should be included in the output document.
Here's the query:
The output is:

Aggregation Pipeline Operators in MongoDB
MongoDB provides a wide range of operators that can be used in different stages of the aggregation pipeline. The expressions take the form of { operator: [argument1, argument2, ...] }, where the operator is the specific aggregation operator being used and the arguments are the values passed to the operator. If the operator only requires a single argument, then the array can be omitted, and the expression will take the form { operator: argument }.
-
Arithmetic Expression Operators: MongoDB aggregation pipeline has several arithmetic expression operators such as $add, $subtract, $multiply, and $divide that can perform basic arithmetic operations.
-
Array Expression Operators: MongoDB aggregation pipeline offers array expression operators like $size, $slice, and $concatArrays to perform operations on arrays.
-
Boolean Expression Operators: MongoDB aggregation pipeline has several Boolean expression operators like $and, $or, and $not that are used for logical operations.
-
Comparison Expression Operators: MongoDB aggregation pipeline offers comparison expression operators like $eq, $ne, $gt, $gte, $lt, and $lte, which are used to compare values of two fields in documents.
-
Conditional Expression Operators: MongoDB aggregation pipeline has several conditional expression operators like $ifNull, $cond, and $switch, which are used to return values based on specific conditions.
-
Date expression Operators: These allow performing date-related operations on date fields. These operators include $dayOfYear, $dayOfMonth, $dayOfWeek, $year, $month, $hour, $minute, $second, $millisecond, and $dateToString.
-
Literal expression Operator: They are used to return a value without parsing it as an expression. It is useful when you want to include a static value or an expression that cannot be parsed in the pipeline, such as a regular expression or a JavaScript function. The syntax of this operator is { $literal: <value>} .
-
Set Expression Operators: Set expression operators in MongoDB aggregation are used to perform set operations such as union, intersection, and difference on arrays. These operators include $setUnion, $setIntersection, $setDifference, $setIsSubset, $anyElementTrue, and $allElementsTrue. They take one or more arrays as input and return a new array that contains the results of the set operation.
-
String expression Operators: They are used to perform string operations on fields. These operators include $concat, $substr, $toLower, $toUpper, $indexOfBytes, $split, $strLenBytes, $trim, and $regexMatch. They take one or more string inputs and return a new string that contains the results of the string operation.
Here's a MongoDB aggregation pipeline example using the $toUpper String Expression Operator on the name field of the employee's collection:
The output is:

Let's see an example of a Boolean expression operator. Let's say we want to find all the employees who have a salary greater than or equal to 90,000 and whose location is either "Kolkata" or "Mumbai". We can use the $and and $or operators to combine these conditions:
The output for the above query is:
Stages of Aggregation in MongoDB
The MongoDB aggregation pipeline consists of stages that are used to process and transform data. Each stage performs a specific operation on the input data and passes the transformed data to the next stage. Here are some of the commonly used stages of aggregation in MongoDB:
-
$match stage: This stage is used to filter the documents in the input stream based on a specified condition. For example, the following pipeline stage will filter documents where the "department" field is "Engineering".
-
$group stage: This stage is used to group documents based on a specified key and perform aggregation operations on the grouped data. For example, the following pipeline stage groups documents by the "department" field and calculates the average salary for each department.
-
$sort stage: This stage is used to sort the output of the previous stage based on a specified field. For example, the following pipeline stage will sort the documents in descending order based on the "salary" field. The values 1 and -1 are used to specify the sorting order for a given field. If you use 1, the field will be sorted in ascending order, and -1 is in descending order.
-
$project stage: This stage is used to reshape the documents in the input stream and include or exclude fields as needed. For example, the following pipeline stage will exclude the hobbies field from the output. The 0 and 1 in the $project stage specify whether to include or exclude a particular field in the output document.
-
$limit stage: This stage is used to limit the number of documents in the output stream. For example, the following pipeline stage will limit the output to the first 2 documents.
These are just a few of the many stages available in the MongoDB aggregation pipeline. By combining these stages in different ways, complex data processing operations can be performed efficiently and effectively.
Expressions of Aggregation Pipeline in MongoDB
In MongoDB, expressions are used in the aggregation pipeline to process and transform data. Expressions consist of one or more operators that can take input values and return computed output values. These operators can be used to transform and manipulate data in various ways as it passes through the pipeline. Here's an example of using expressions in the aggregation pipeline with the employee's collection:
Suppose we want to create a new field in our documents that concatenates the name and location fields together, separated by a hyphen. We can use the $concat string expression operator to achieve this. Here's a MongoDB aggregation pipeline example:
The output is:

Optimizing Performance in MongoDB Aggregation
Optimizing performance in the MongoDB aggregation pipeline is essential to achieve faster and more efficient data processing. We have to consider different factors here to optimize performance, consider the 100MB RAM limit for pipeline stages and use allowDiskUse to write data to temporary files. Results can be returned as a cursor or stored in a collection, but each document must not exceed 16MB. It's best to minimize the documents that need to be sorted by using $match before $sort. We can also optimize performance by using indexes, limiting data size, using projections, using explain(), and looking into sharding approaches.
FAQs
Q. What is the difference between MongoDB Aggregation and Query?
A. MongoDB Query returns the exact data matching the query criteria, whereas Aggregation processes the data and returns computed results based on the pipeline stages.
Q. Can MongoDB Aggregation handle large datasets?
A. Yes, MongoDB Aggregation can handle large datasets, but pipeline stages have a limit of 100 megabytes of RAM. To handle large datasets, you can use the allowDiskUse option to write data to temporary files.
Q. What are the different stages available in MongoDB Aggregation Pipeline?
A. The different stages in MongoDB Aggregation Pipeline are $match, $project, $group, $sort, $limit, $skip, $unwind, $lookup, and $facet.
Conclusion
- MongoDB Aggregation Pipeline is a framework for performing complex data manipulations and analytics on MongoDB collections.
- MongoDB provides a wide range of operators for building expressions and implementing various types of data transformations.
- Overall, the MongoDB Aggregation Pipeline provides a powerful set of tools for data processing and analytics, making it an essential tool for businesses and organizations dealing with large volumes of data.