Replica Set
Overview
To ensure high availability, fault tolerance, and data redundancy, MongoDB replication refers to the process of maintaining numerous copies of data across various servers, known as replica sets. Data availability and durability for applications are basic capabilities of MongoDB.
Introduction
The significant feature of replication in MongoDB offers data redundancy, high availability, and scalability. MongoDB ensures that your data is accessible and robust even in the event of failures by duplicating it over several nodes. Automatic failover, distributed read operations, and extra features like flow control and change streams are all made possible via replication. Replication in MongoDB enables you to create dependable systems that can withstand the demands of your applications.
Redundancy and Data Availability
To ensure fault tolerance and reliability, redundancy is the practice of maintaining numerous copies of data or system components. Redundancy in databases refers to keeping several copies of the data on various servers or storage systems.
The ability of a system or application to access and retrieve data when required is referred to as data availability. High data availability refers to the capacity to consistently access data, despite errors or maintenance tasks.
Replication in MongoDB
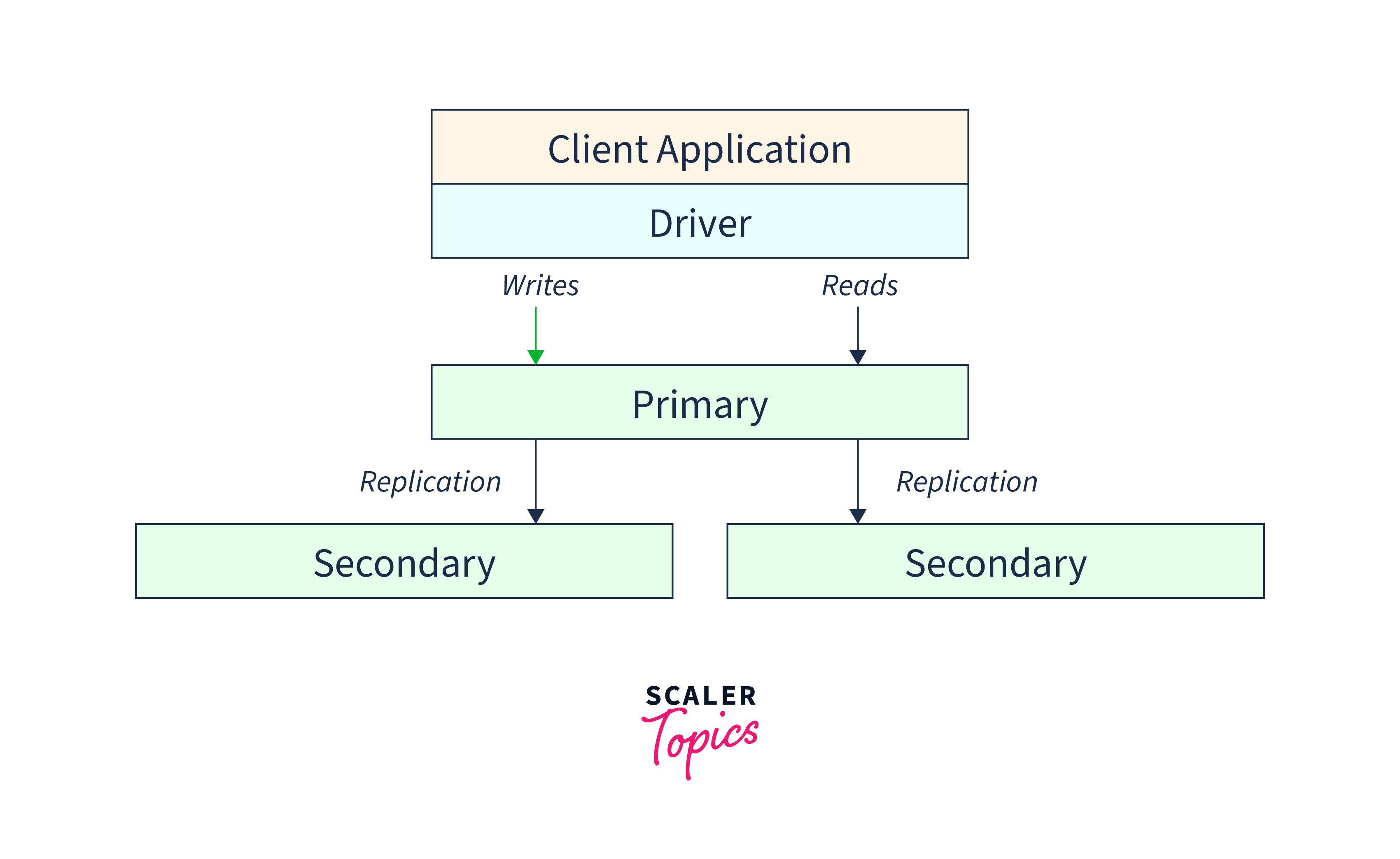
In a MongoDB replica set, multiple mongod instances (MongoDB servers) work together to maintain the same dataset, providing data redundancy and high availability. The replica set includes data-bearing nodes, which store the actual data, and an optional arbiter node, which participates in elections but does not store data.
Among the data-bearing nodes, only one node is designated as the primary, while the others are secondary nodes. The primary node handles all write operations, meaning it is responsible for receiving and confirming writes from client applications. It maintains the authoritative copy of the dataset.
To ensure data consistency across the replica set, the primary node keeps a record of all changes made to its data sets in an operation log called the oplog. The oplog serves as a sequential record of write operations applied to the primary node's data. The secondary nodes continuously pull the oplog entries from the primary and apply them to their own data sets, keeping themselves in sync with the primary.
In certain situations where cost constraints or resource limitations prevent adding another secondary node to a MongoDB replica set, an arbiter can be added instead. An arbiter is a special type of mongod instance that participates in replica set elections but does not store any data. Its role is solely to contribute to the voting process during elections.
Asynchronous Replication
Changes made on the primary node are delayed and transferred to the secondary nodes using the data replication technique known as asynchronous replication, which is employed in databases like MongoDB. In other words, the primary node does not hold out on recognizing a write operation as successful until the secondary nodes have verified the replication of data.
Slow Operation
Starting from MongoDB version 4.2, secondary members of a replica set now generate log entries for slow oplog operations that exceed the defined threshold. These log messages specifically pertain to the secondary members and are recorded in the diagnostic log. They appear under the REPL component with the information "applied op: <oplog entry> took <num>ms," indicating the duration of the slow operation.
It is important to note that these slow oplog log messages are independent of the log levels set at the system or component level and are not affected by the profiling level. However, their handling may differ based on the version of MongoDB:
In MongoDB 4.2, slow oplog entries are logged without considering the slowOpSampleRate. This means that all slow oplog entries are recorded regardless of the sample rate.
In MongoDB 4.4 and later versions, the slowOpSampleRate does affect the logging of slow oplog entries. The sample rate determines which entries are captured and logged.
Additionally, it is worth mentioning that the profiler feature does not capture or record slow oplog entries.
Replication Lag and Flow Control
Replication lag in MongoDB refers to the delay in replicating write operations from the primary node to the secondary nodes. MongoDB 4.2 introduced flow control, allowing administrators to regulate the write application rate on the primary to keep the replication lag within the defined flowControlTargetLagSeconds threshold. Flow control requires a feature compatibility version of 4.2 and read concern majority enabled. By obtaining tickets and limiting the rate of write operations, flow control helps prevent excessive replication lag and maintains a balanced replica set.
Enabling flow control in MongoDB ensures that the replication lag stays within acceptable limits. Administrators can control the write application rate on the primary node, preventing issues like cache pressure. It is crucial to meet the conditions of having MongoDB 4.2's feature compatibility version and read concern majority enabled for flow control to take effect. By managing the replication lag through a ticket-based write application, flow control improves the overall efficiency of the replica set.
Automatic Failover
MongoDB's ability to detect primary node failures and automatically transition the workload to a secondary node without requiring any operator intervention is known as automatic failover. The high availability and fault tolerance of MongoDB is made possible by this essential feature.
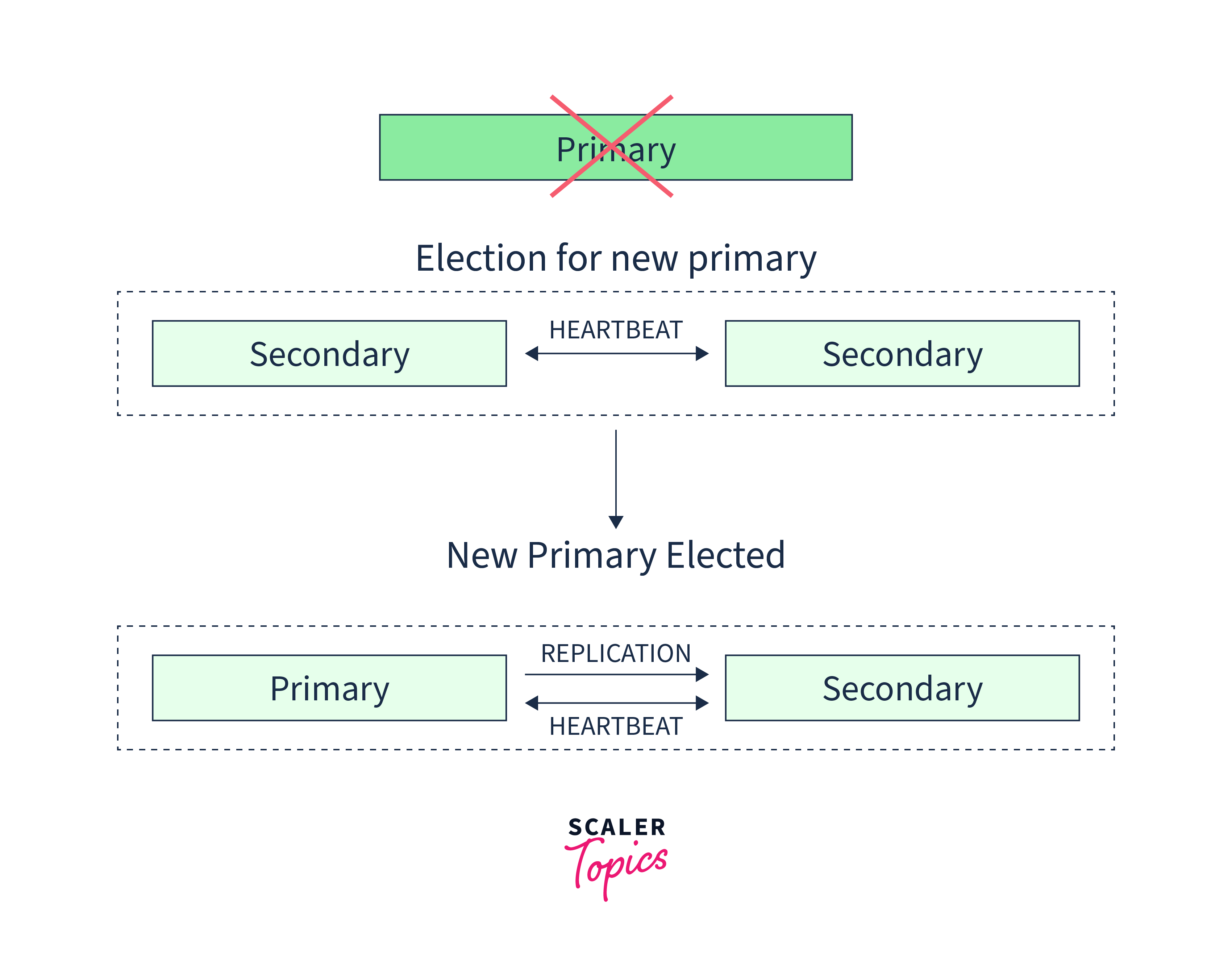
Automatic failover in MongoDB refers to the process where, in the event of a primary node failure or unresponsiveness, the replica set selects a new primary node automatically. During this failover process, write operations are temporarily halted, while read queries can still be serviced if configured to run on secondary nodes.
The time it takes for a replica set to complete a successful election and select a new primary node typically averages around 12 seconds, assuming default configuration settings. This includes the time to mark the primary as unavailable, initiate the election, and finalize the selection. The duration can be adjusted by modifying the electionTimeoutMillis replication configuration option. However, network latency and cluster architecture can affect the election time and the cluster's ability to operate without a primary.
Lowering the electionTimeoutMillis option from its default value of 10,000 milliseconds (10 seconds) can help detect primary failures faster. However, it may also result in more frequent elections due to factors like temporary network latency, potentially causing increased rollbacks for write operations with a w: 1 write concern.
To handle automatic failovers and elections, it is recommended to implement application connection logic that can tolerate such events. MongoDB drivers have features that detect primary node loss and automatically retry certain write operations once, providing built-in support for handling failovers and elections.
Starting from MongoDB version 4.4, there is a feature called "mirrored reads" that helps restore performance more quickly after an election. It accomplishes this by pre-warming the cache of electable secondary nodes with the most recently accessed data, ensuring that they have up-to-date data readily available.
Read Operations
READ PREFERENCE
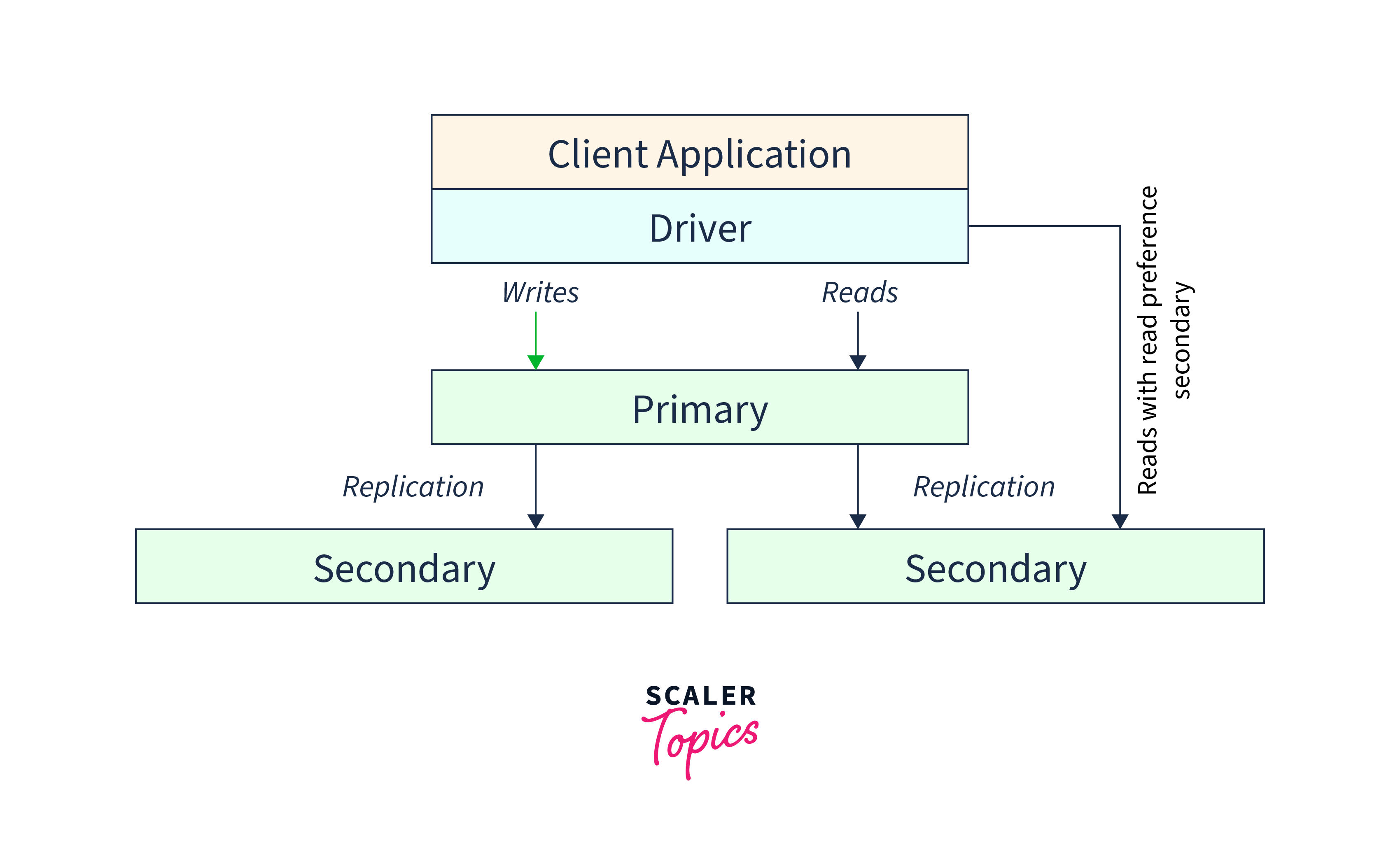
The data on secondary nodes may not always be current with the state of the data on the primary node in MongoDB due to asynchronous replication to secondaries. This means that it is possible to read data from secondary nodes that do not accurately reflect the most recent changes made on the primary.
The read preference "primary" must be used, meaning that all activities inside the transaction must be directed to the primary node, for multi-document transactions that contain read operations. In other words, to ensure the transaction uses the most up-to-date data, the "primary" read preference should be used for read operations in a transaction. This guarantees that the transaction reads from the primary node, preventing the use of outdated data from secondary nodes.
DATA VISIBILITY
Multi-document transactions are available for replica sets in MongoDB 4.0 and later. The read preference primary must be used and all operations inside a transaction must be directed to the same member (node) of the replica set when using multi-document transactions that entail read operations.
The modifications performed within a transaction are not noticeable outside of the transaction itself until the transaction is committed. However, not all external read operations must wait for the whole transaction to be committed to view the changes across all shards when a transaction writes to several shards (in a sharded environment).
Suppose a transaction is successfully committed, and as a result, write 1 becomes visible on shard A, but write 2 is not yet visible on shard B. In such a situation, if an external read operation with a "local" read concern is performed, it can read the outcome of write 1 without needing to observe write 2. This implies that external readers can access the changes made within the transaction on each shard, without waiting for the entire transaction to be completely visible across all shards.
Mirrored Reads
Mirrored reads in MongoDB aim to minimize the impact of primary elections that occur during failures or planned maintenance. When a failover happens in a replica set, the new primary needs time to update its cache as new queries are executed, which can affect performance.
Starting from version 4.4, MongoDB introduces the concept of mirrored reads to proactively warm up the caches of electable secondary replica set members. Mirrored reads involve the primary replicating a subset of the supported operations it receives to these electable secondaries. By doing so, the caches of these secondary members are pre-loaded with relevant data.
The subset of electable secondary replica set members that receive mirrored reads can be adjusted using the mirrorReads parameter. This allows administrators to configure the number of secondary members that participate in the pre-warming process.
Transactions
Starting from MongoDB 4.0, replica sets offer support for multi-document transactions, enabling atomic operations involving multiple documents.
In these transactions, read operations must use the primary read preference, and all operations within the transaction must be directed to the same replica set member.
Changes made within a transaction are not visible outside of it until the transaction is committed. This ensures data consistency by preventing the exposure of incomplete or inconsistent data.
In scenarios where a transaction writes to multiple shards, not all external read operations need to wait for the entire transaction to be visible across all shards. For instance, if a transaction is committed and write 1 is visible on shard A but write 2 is not yet visible on shard B, an external read operation with a "local" read concern can access the results of write 1 without requiring write 2 to be visible.
Change Streams
Since MongoDB 3.6, a feature called change streams has been introduced for both replica sets and sharded clusters. Change Streams allow applications to access real-time data changes without manually tracking the oplog. Applications can subscribe to collections and receive continuous streams of insert, update, and delete events, simplifying real-time data processing and enabling reactive systems.
Additional Features
MongoDB replica sets provide a range of choices to meet the needs of varied applications. Deploying a replica set across various data centers is one such solution. This enhances availability and performance by enabling data redundancy and dispersion among geographically distributed locations.
Furthermore, replica sets give users the ability to influence how elections—which choose the primary node—turn out. Administrators can alter the probability that a given node will become the primary by changing the members[n].priority value of individual members within the replica set. Based on particular requirements, this control aids in optimizing the behavior and performance of the replica set.
Dedicated members that perform specific tasks like reporting, disaster recovery, or backup are also supported by replica sets. These members can be put up to carry out functions unrelated to primary activities, giving the replica set infrastructure more flexibility.
Conclusion
- Automatic failover is provided through replica sets, ensuring ongoing operation even if the primary node is down.
- MongoDB reduces the risk of data loss by duplicating data across several nodes to maintain data redundancy.
- MongoDB enables read-intensive workloads to scale horizontally by allowing read operations to be dispersed across secondary nodes.
- Multi-document transactions are supported by MongoDB, enabling the grouping of several operations while preserving atomicity and consistency.
- Administrators can prevent replication lag and ensure data consistency by limiting the rate at which writes are applied to the primary node using flow control.
- Replica sets provide flexibility and customization choices by offering a variety of additional features, such as hidden members, delayed members, arbiter members, and read concern levels.
- Reactive and event-driven architectures are made possible by change streams, which allow for real-time monitoring and capture of data changes.