Save the Aggregate Output in a New Collection
Overview
MongoDB is a popular NoSQL database used in modern web applications for its flexibility and scalability. In MongoDB, an aggregation pipeline is a framework for processing and modifying data from one or more collections in a customizable series of stages. One of the most critical stages in the pipeline is the out stage. We can use the out stage to save the aggregate output in a new collection in MongoDB. We can use the out stage in the Mongo Shell and the Aggregation Editor. We can also use the insert function to insert documents in a new collection.
Introduction
It might be difficult to derive valuable insights from vast amounts of data in the MongoDB database. An aggregation pipeline is a powerful tool for performing complicated searches and transformations on our data to obtain the information we require. One of the key stages in the pipeline is called out.
The out stage allows us to save the aggregate output in a new collection in MongoDB by taking the pipeline's output and writing it to a new collection. This can be beneficial for a variety of purposes, such as backing up our data or generating a subset of our data that meets the specified criteria. The out stage can also be used to overwrite an existing collection with the results of the pipeline. It is important to remember that the out stage is used as the last stage in a pipeline since it creates a new collection that cannot be changed further. Moreover, using out to overwrite an existing collection can result in data loss. By using the out stage, we can define the destination collection in numerous ways, including creating a new one or overwriting an existing one. We can optionally give other parameters, such as the maximum size of the output collection or the operation's write concern.
Therefore, the out stage is an effective tool for managing and evaluating data in MongoDB, but it must be used with caution to prevent any dangers. Understanding the syntax and options of the out stage allows us to fully use its capabilities and extract more value from our MongoDB data.
How to Save the Aggregate Output in a New Collection in MongoDB?
The aggregation framework in MongoDB is a data processing pipeline that is used to filter, group, and analyze the data present in a collection. It offers an efficient way to perform complex operations in multiple stages. We can use the out stage to save the aggregate output in a new collection in MongoDB. The out stage should always be the last stage of the pipeline. It takes input from the previous stage of the pipeline and saves it into a new collection. When the out stage is executed, it overwrites any existing collection with the same name as the one specified. We should choose a unique name for the new collection to avoid overwriting any existing data.
Using $out
out is used to save the aggregate output in a new collection in MongoDB.
Properties of $out:
- The out stage creates a new collection in the existing database. The new collection is visible only after aggregation is complete. A new collection is not formed if the aggregation process fails. It can also save the data in a new collection in a new database.
- The pipeline will fail to complete if the created document violates any unique indexes, including the index on the _id field of the original output collection.
- If the specified collection already exists, the out stage replaces it atomically with the new collection. This does not alter any existing indexes in the collection. If the aggregate fails, the out operation leaves the existing collection unchanged.
- It is the last stage of the pipeline.
- It does not return any output, it is used to save the aggregate output in a new collection in MongoDB.
- It takes the output of the previous stage as input.
- Necessary permissions are required to create a new collection in the database.
- The newly generated collection can be accessed and queried like any other collection in MongoDB.
The $out stage
The out stage is the last stage of an aggregation pipeline, and it is used to save the aggregate output in a new collection in MongoDB. The out stage does not return any output. The specific collection nameshould be unique to avoid overwriting pre-existing data. The out stage allows the aggregation framework to return result sets of any size. After completion of the out stage, the newly generated collection is like any other collection in MongoDB, and we can perform operations or queries on it.
$out Syntax The out stage has the following syntax:
| Field | Description |
|---|---|
| db | The output database name. If the output database does not exist, out can also create the database. For a replica set or a standalone, if the output database does not exist, out also creates the database. For a sharded cluster, the specified output database must already exist. |
| coll | The output collection name. If the output collection does not exist, out can also create the collection. |
In the above syntax, "
If we want to save the data in a new collection in the same database, the following syntax is used:
Here, "
$out in Aggregation Editor
We can use the Aggregation Editor in the Studio 3T to aggregate the data, and save the aggregate output in a new collection in MongoDB.
We can install Studio 3T from their official website and then connect the MongoDB database to Studio 3T using the following steps:
- We have to navigate to the "Clusters" page after logging into our MongoDB Atlas account.
- Next, we will select the cluster which we want to connect to Studio 3T and click on the "Connect" button.
- From the connection options, we will choose "Connect with MongoDB Compass".
- We will copy the connection string displayed in the dialogue box.
- We will launch Studio 3T and select "Connect" in the upper left corner.
- Then we will Select "MongoDB" from the list of available databases in the "Connect" window.
- We should paste the connection string which had been copied previously into the "URI" field in the "Connection Details" section.
- In the "Authentication" tab, we should specify the "username" and "password" of the MongoDB Atlas user.
- To ensure that the connection is working properly, we will click on the "Test" button.
- If the test is successful, we will click on "Save" to remember the connection information.
- Next, we will select the database we have added and click on the "Connect" button.
After the connection is successful, we can see all the databases present in our cluster.
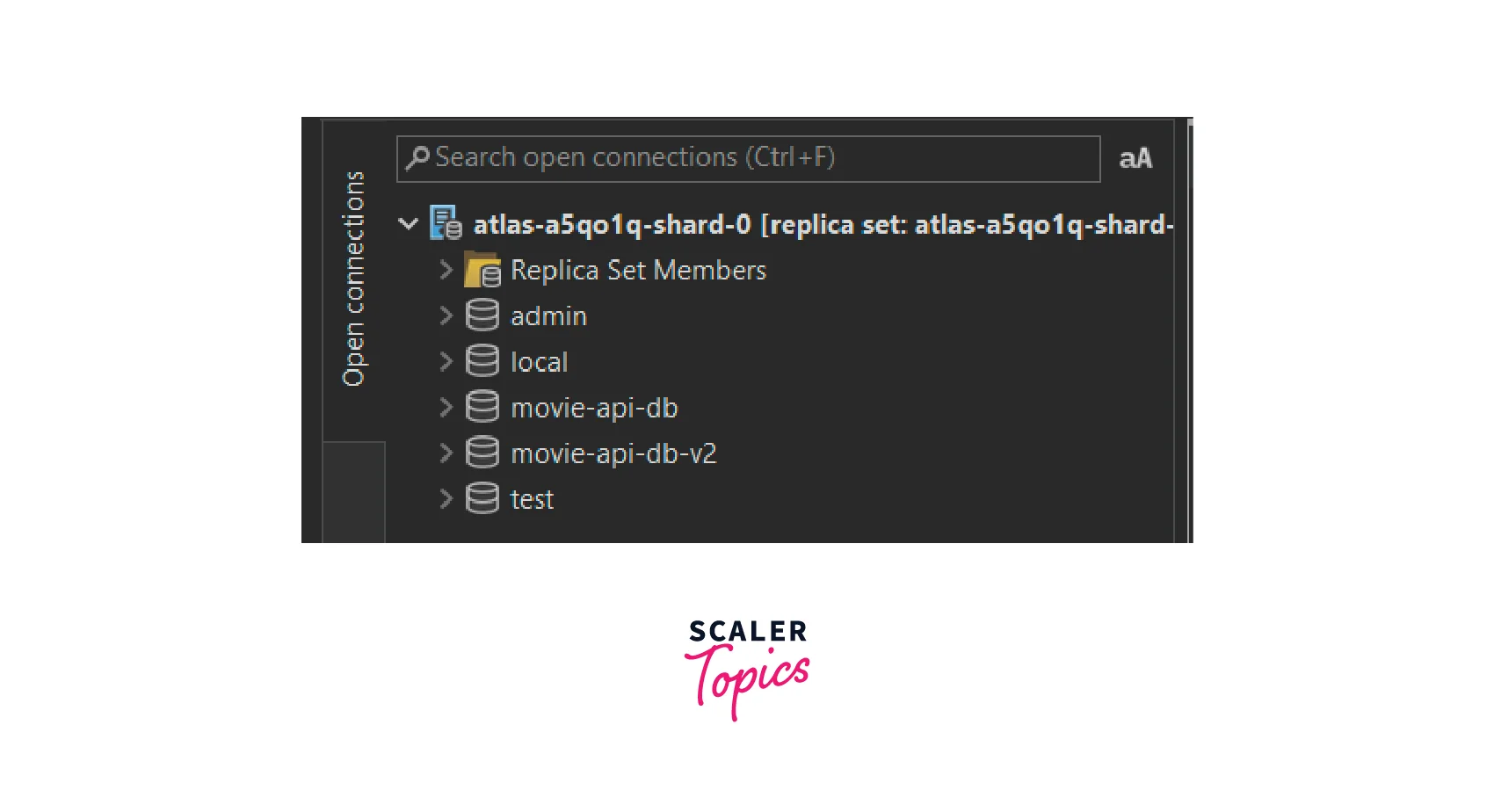
Example 1: We have a collection named "movies", inside the "movie-api-db" database. It contains seven documents, and each document has the following fields:
- _id
- imdbId
- title
- releaseDate
- productionCompany
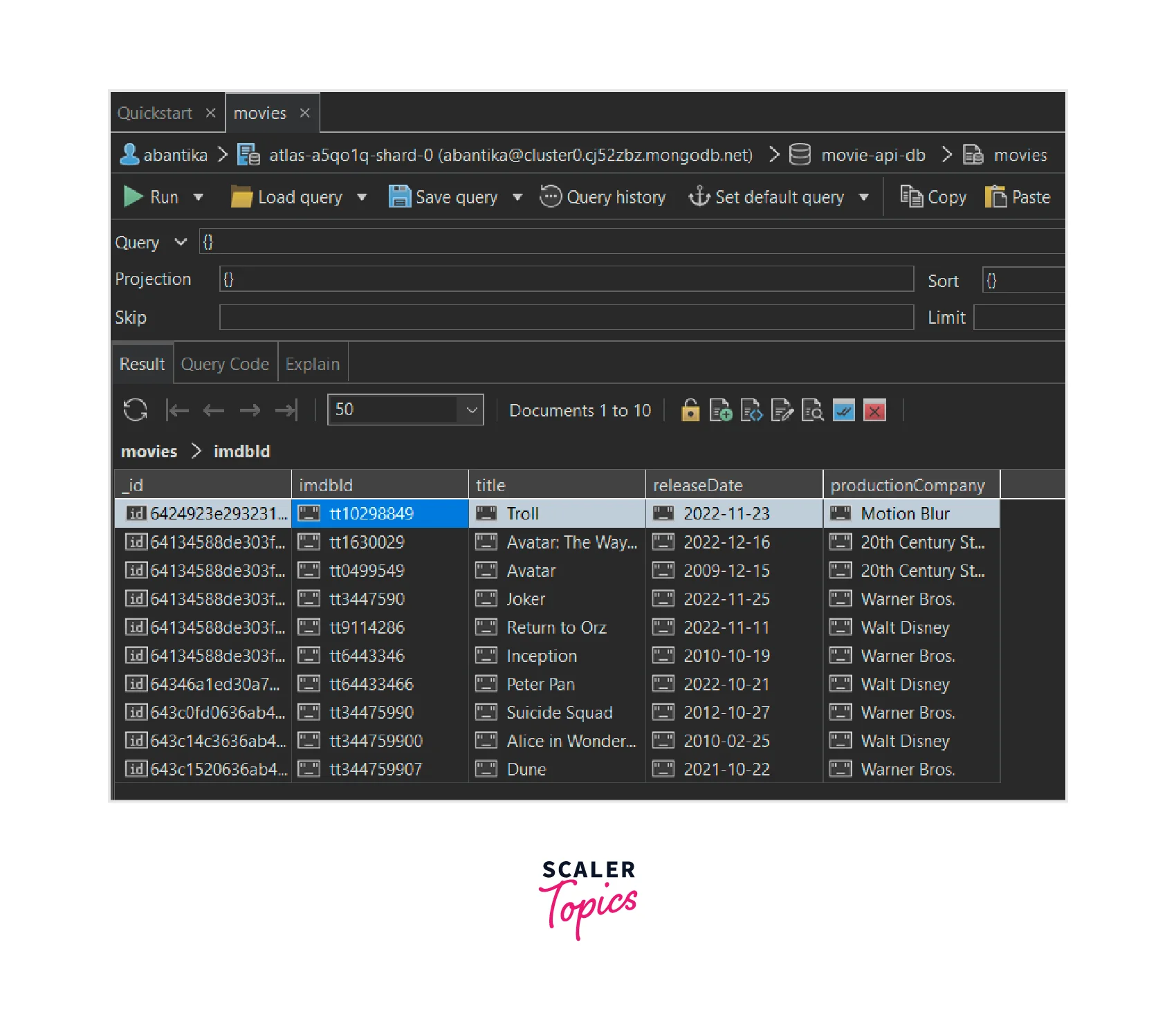
To understand how a full aggregation query works with an out stage, we should build some other stages first. In this example, we will build the group stage first.
We want to group the documents according to their "productionCompany".
This aggregation operation pivots the data in "movies" collection to have "title" grouped by "productionCompany" and then the out stage is used to save the aggregate output in a new collection in MongoDB, in this case, the results are written into the "newMoviesAggregate" collection in the database.
- Select the collection "movies" from the "movie-api-db" database, and then click on the "Aggregate" button, present on top.
- Go to the "Aggregation: movies" tab.
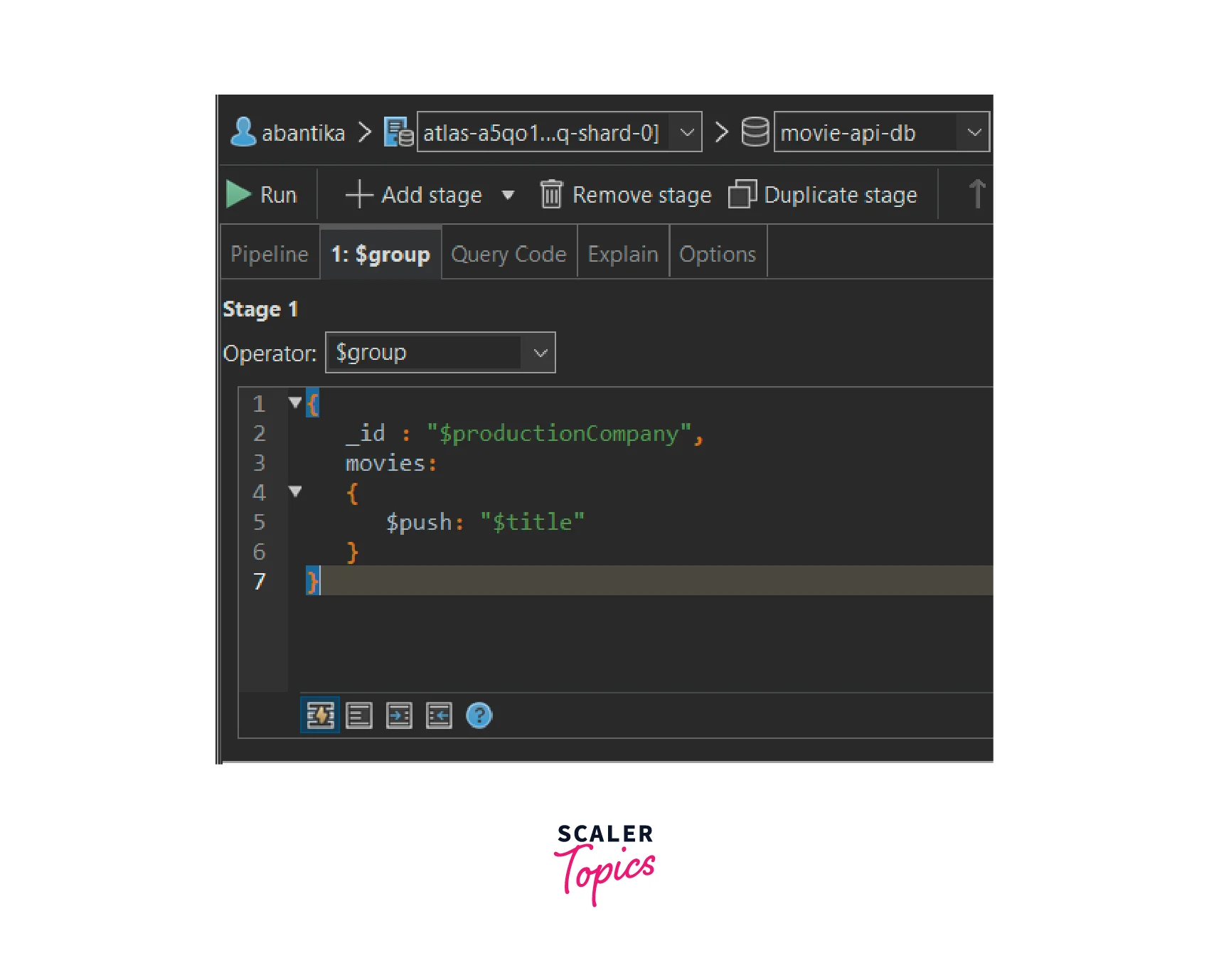
- Now, we will add the group stage by clicking on the "Add Stage" button and selecting the "group" stage operator.
Write the following syntax for the group stage:
Syntax:
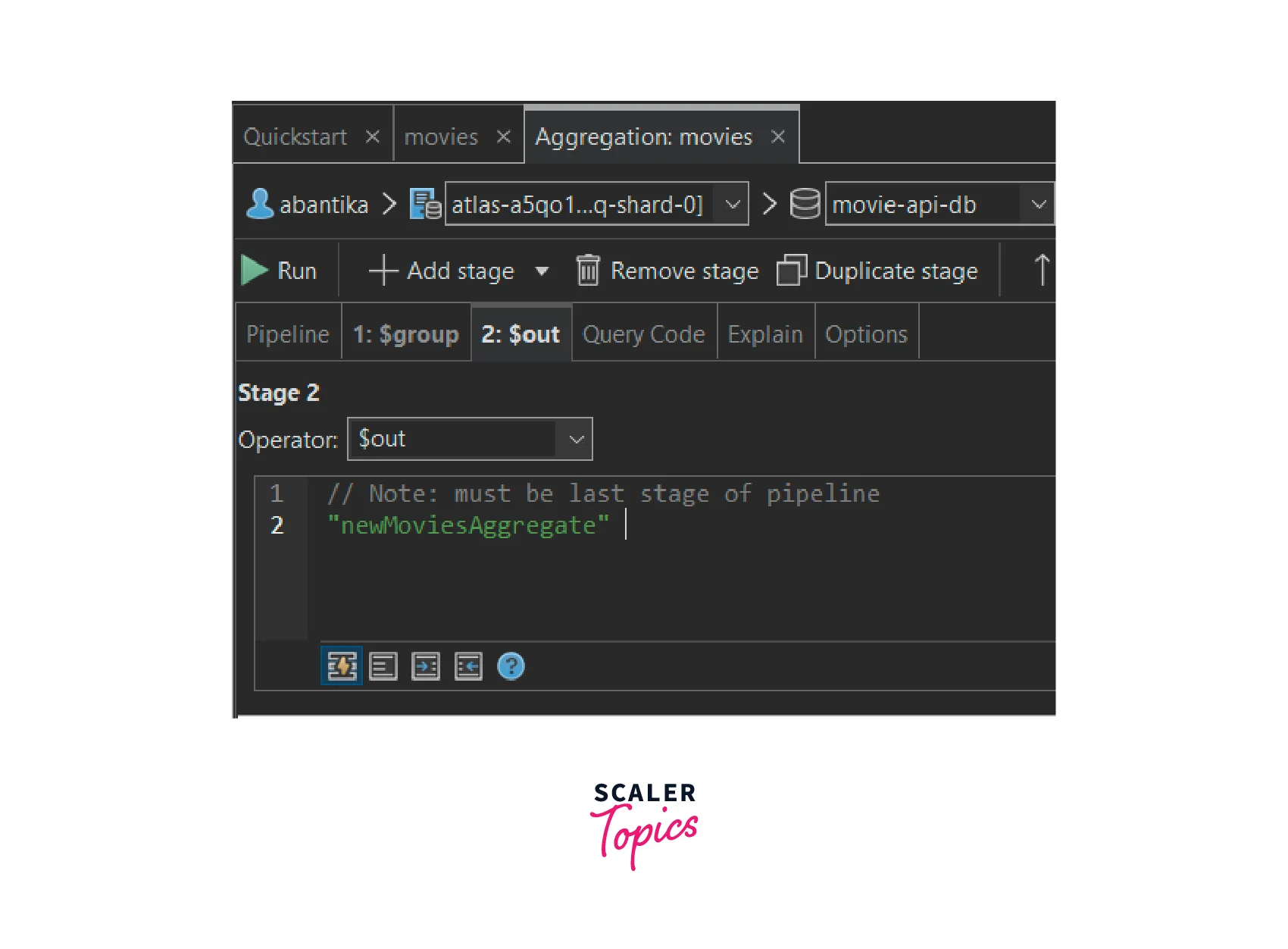
- Now, we will add the out stage by clicking on the "Add Stage" button and selecting the "out" stage operator.
Write the collection name in which you want to save the aggregate data for the out stage:
Syntax:
NOTE: If you want to save the aggregate data in a new collection in a separate database, for e.g., we want to save the aggregate data in a collection named "newMoviesAggregate" in a database named "movie-api-db-v2" database, the syntax for the out stage should be:
Syntax:
- We will click on the "Run" button present on top to run the aggregation query pipeline.
The group stage aggregates the data, and the out stage is used to save the aggregate output in a new collection in MongoDB.
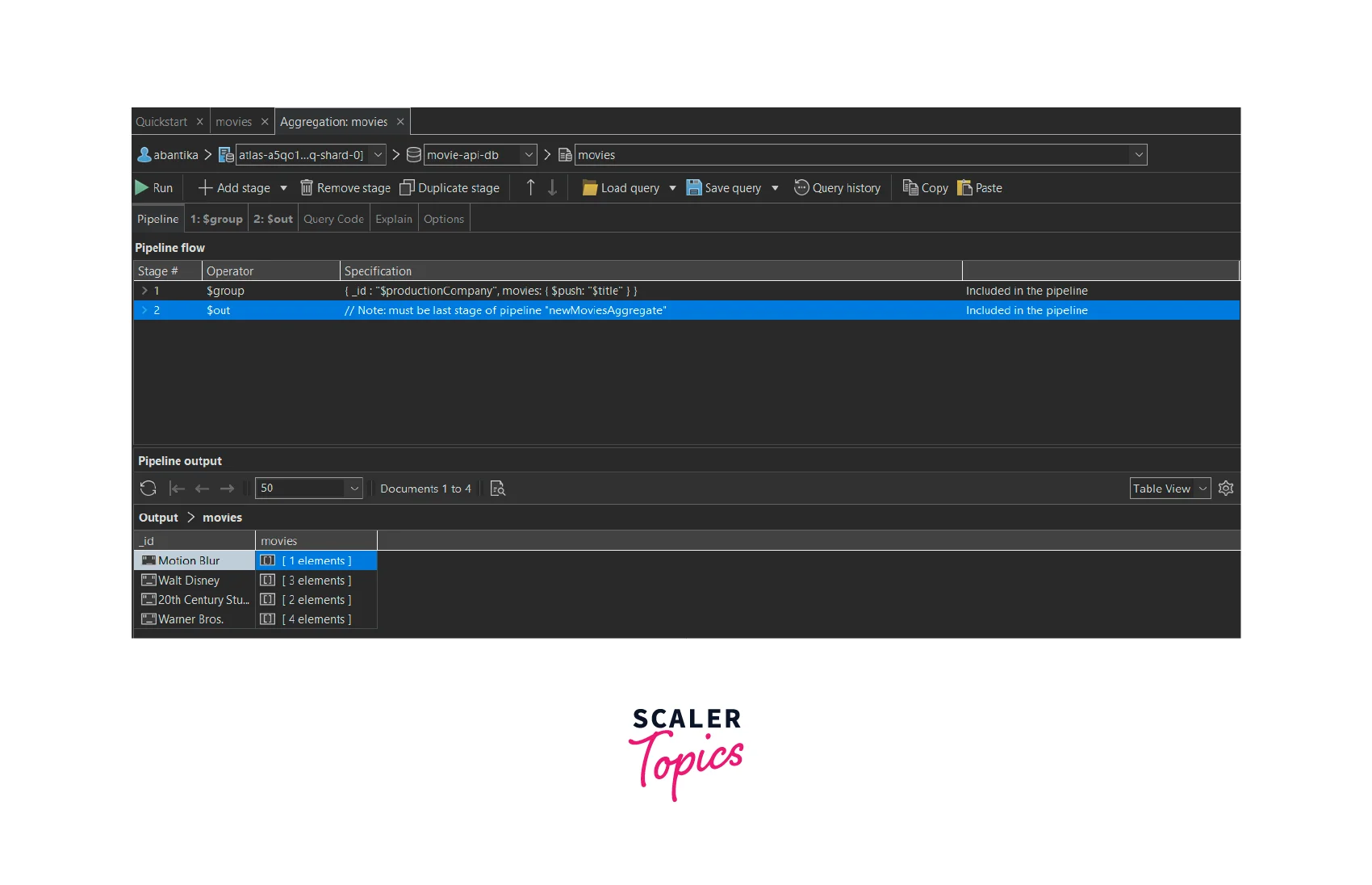
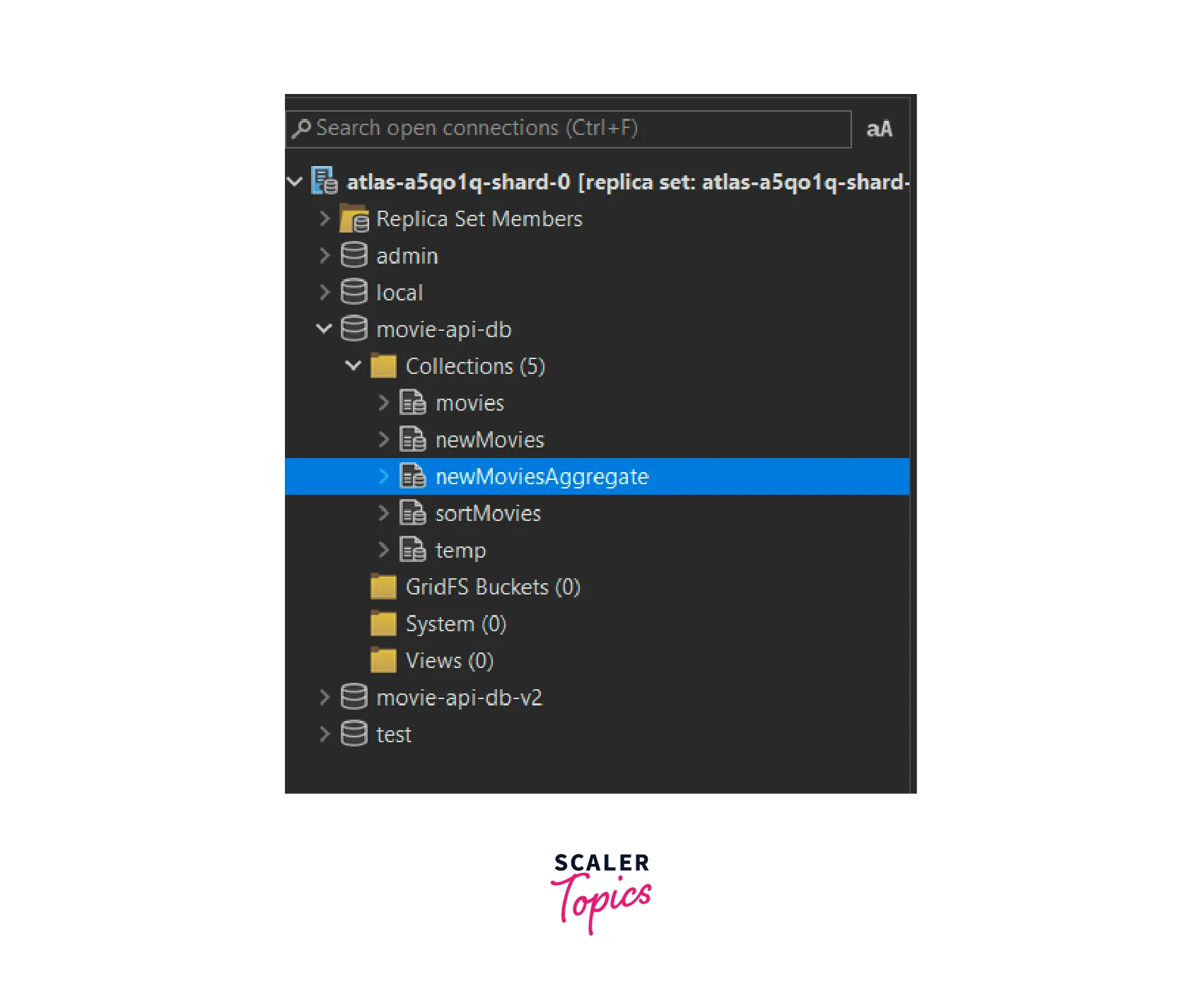
Thus in the image shown above, we can see that the collection has four documents. The documents have been grouped according to their "productionCompany". Each document's "_id" field represents their "productionCompany" and the "movies" field is an array of the movie "titles" which belong to the same "productionCompany".
- Right-click on the "movie-api-db" and click on "Refresh All" and we can see that a new collection named "newMoviesAggregate" has been added to the database.
$out in the Mongo Shell
Let us see a few examples to understand how out is used in Mongo Shell.
Example 1: We have a collection named "movies". It contains seven documents, and each document has the following fields:
- _id
- imdbId
- title
- releaseDate
- productionCompany

We want to group the documents according to their "productionCompany".
This aggregation operation pivots the data in "movies" collection to have "title" grouped by "productionCompany" and the out stage is used to save the aggregate output in a new collection in MongoDB, in this case, the results are written into "newMovies" collection in the database.
Syntax:
The group stage aggregates the data, and the out stage is used to save the aggregate output in a new collection in MongoDB.
First Stage ($group):
The group stage groups by the "productionCompany" and uses $push to add the "title" to a "movies" array field:
Second Stage ($out):
The out stage outputs the documents to the "newMovies" collection in the database.
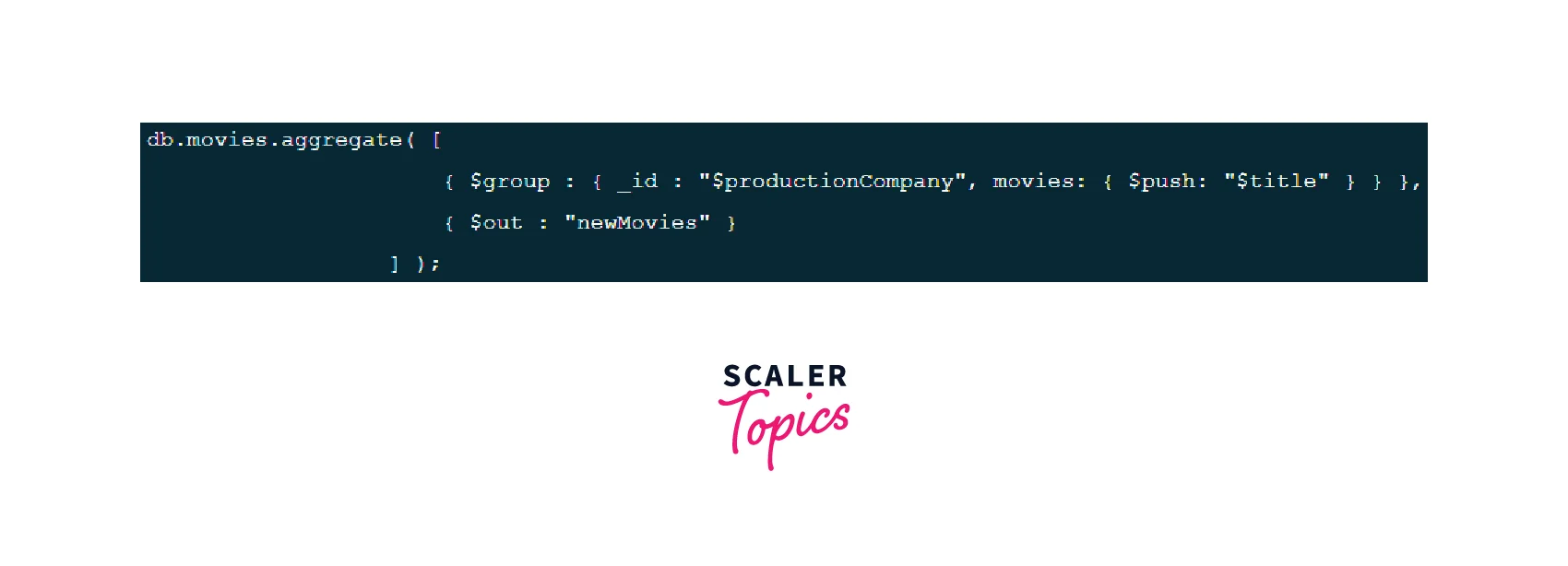
We can see that after running the command in the Mongo Shell, a new collection named "newMovies" in the "movie-api-db" database has been created.
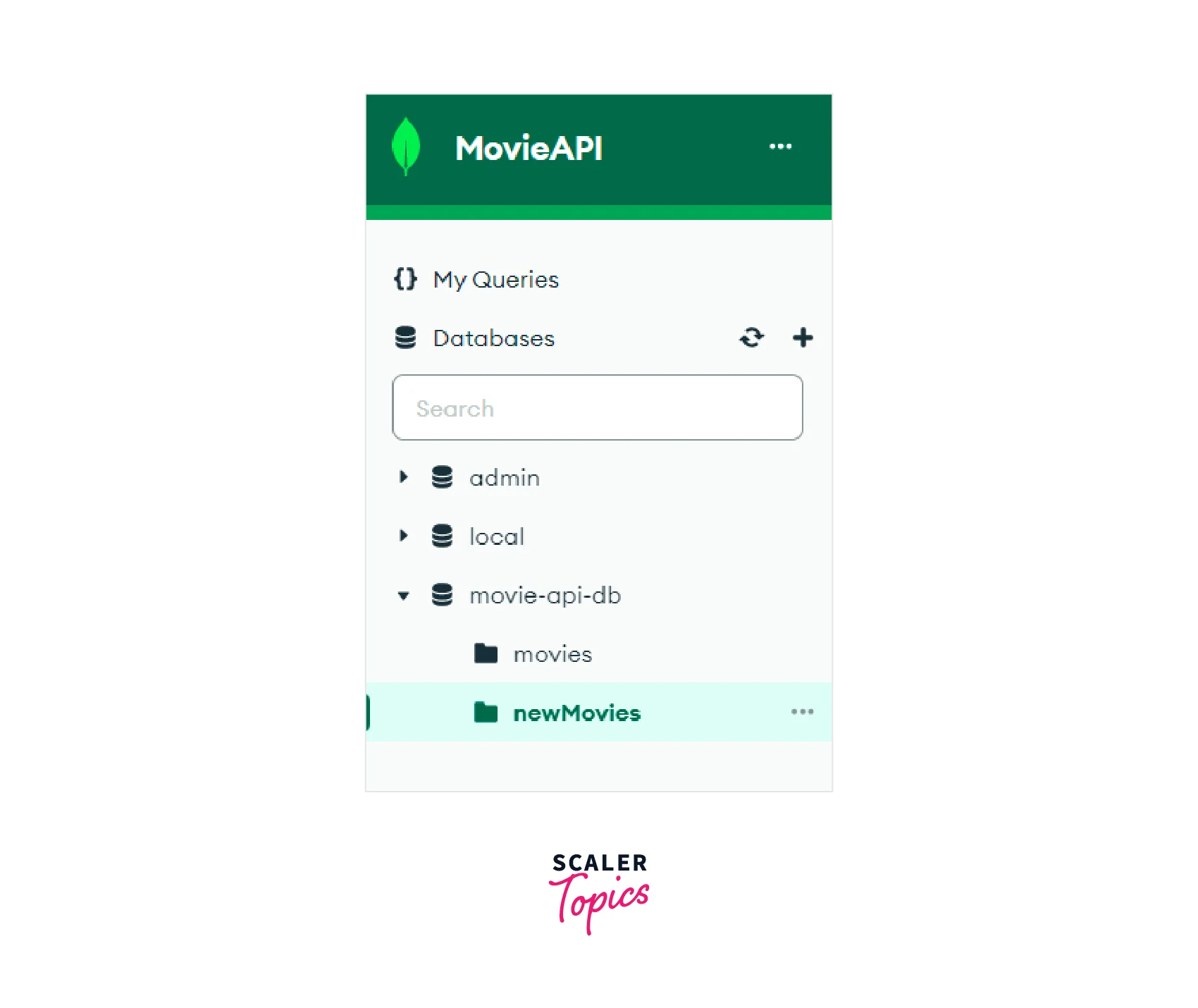
Thus in the image shown below, we can see that the "newMovies" collection has four documents. The documents have been grouped according to their "productionCompany". Each document's "_id" field represents their "productionCompany" and the "movies" field is an array of the movie "titles" which belong to the same "productionCompany".

Example 2:
In Example 1, we created a new collection named "newMovies" inside the same database, that is, "movie-api-db". In this example, we will see how to create a new collection in a different database.
The following aggregation operation pivots the data in "movies" collection to have "title" grouped by "productionCompany" and then the out stage is used to save the aggregate output in a new collection in MongoDB, in this case, the results are written into the "newMoviesV2" collection in the "movie-api-db-v2" database.
Syntax:
The group stage aggregates the data, and the out stage is used to save the aggregate output in a new collection in MongoDB.
First Stage ($group):
The group stage groups by the "productionCompany" and uses $push to add the "title" to a "movies" array field:
Second Stage ($out):
The out stage outputs the documents to the "newMoviesV2" collection in the "movie-api-db-v2" database.

We can see that after running the command in the Mongo Shell, a new collection named "newMoviesV2" in the "movie-api-db-v2" database has been created.
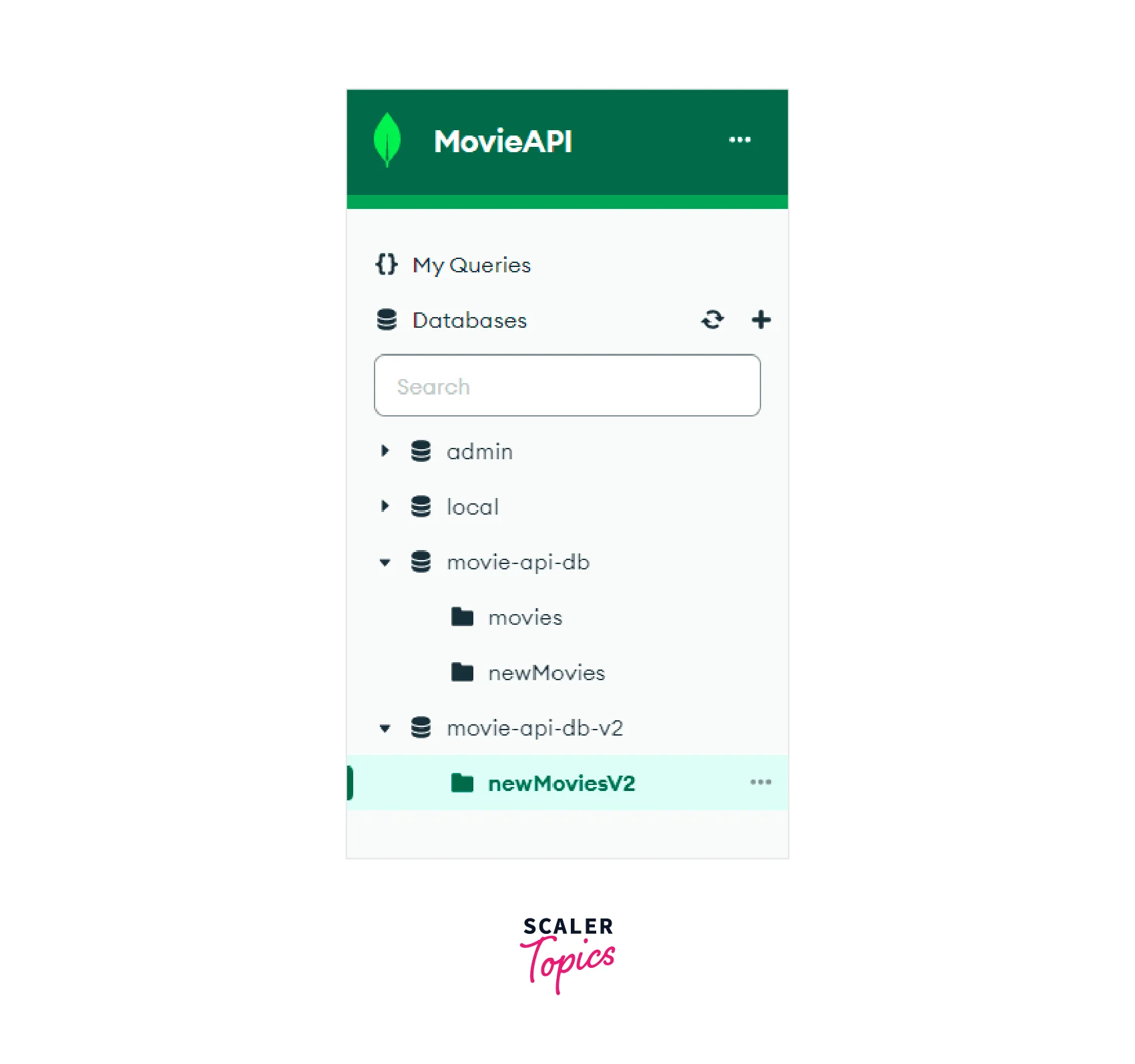
Thus in the image shown below, we can see that the "newMoviesV2" collection has been created in the "movie-api-db-v2" database. The collection has four documents. The documents have been grouped according to their "productionCompany". Each document's "_id" field represents their "productionCompany" and the "movies" field is an array of the movie "titles" which belong to the same "productionCompany".

Example 3:
We will now see how to use the out stage after getting aggregation output from the sort stage and save it in a new collection in the same database.
The following aggregation operation sorts the data alphabetically in the "movies" collection according to the "title" of the movies and then writes the results to the "sortMovies" collection in the "movie-api-db" database.
Syntax:
The sort stage sorts the data, and the out stage is used to save the aggregate output in a new collection in MongoDB.
First Stage ($sort):
The sort stage sorts the "title" alphabetically.
Second Stage ($out):
The out stage outputs the documents to the "sortMovies" collection in the "movie-api-db" database.

We can see that after running the command in the Mongo Shell, a new collection named "sortMovies" in the "movie-api-db" database has been created.
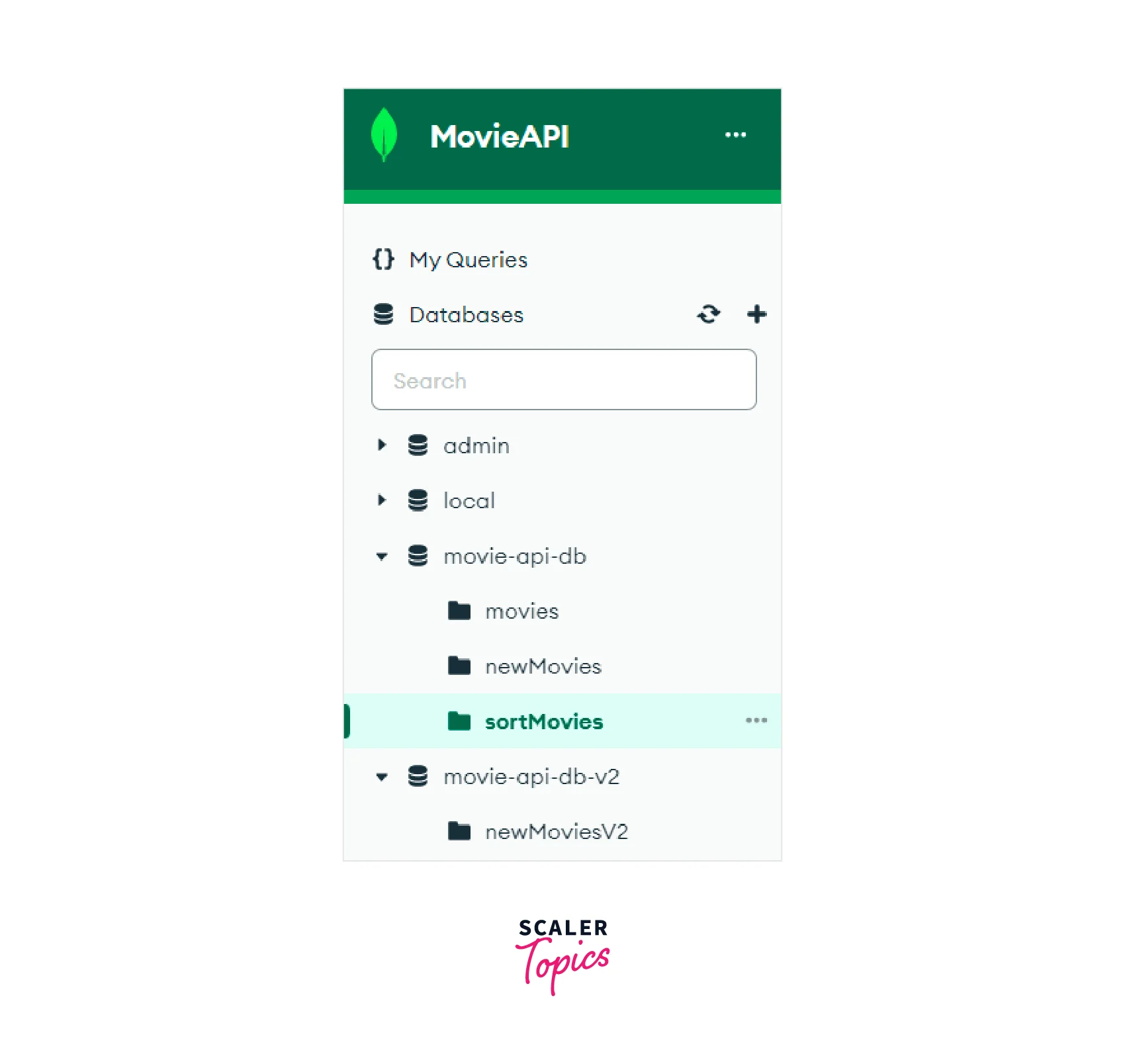
Thus in the image shown below, we can see that the "sortMovies" collection has been created in the "movie-api-db" database. The collection has all ten documents. The documents have been sorted alphabetically according to their "title" fields.

Through the Classic Insert Function
We can also use the insert function to save the aggregate output in a new collection in MongoDB.
Example 1: We want to group the documents present in the "movies" collection according to their "productionCompany".
This aggregation operation pivots the data in "movies" collection to have "title" grouped by "productionCompany" and then the out stage writes the results to the "newMoviesInsert" collection in the database.
Syntax:
Thus, we store the result of the aggregation query in the "result" variable.
Now, we will convert the "result" variable into an array and insert it into a new collection named “newMoviesInsert”.

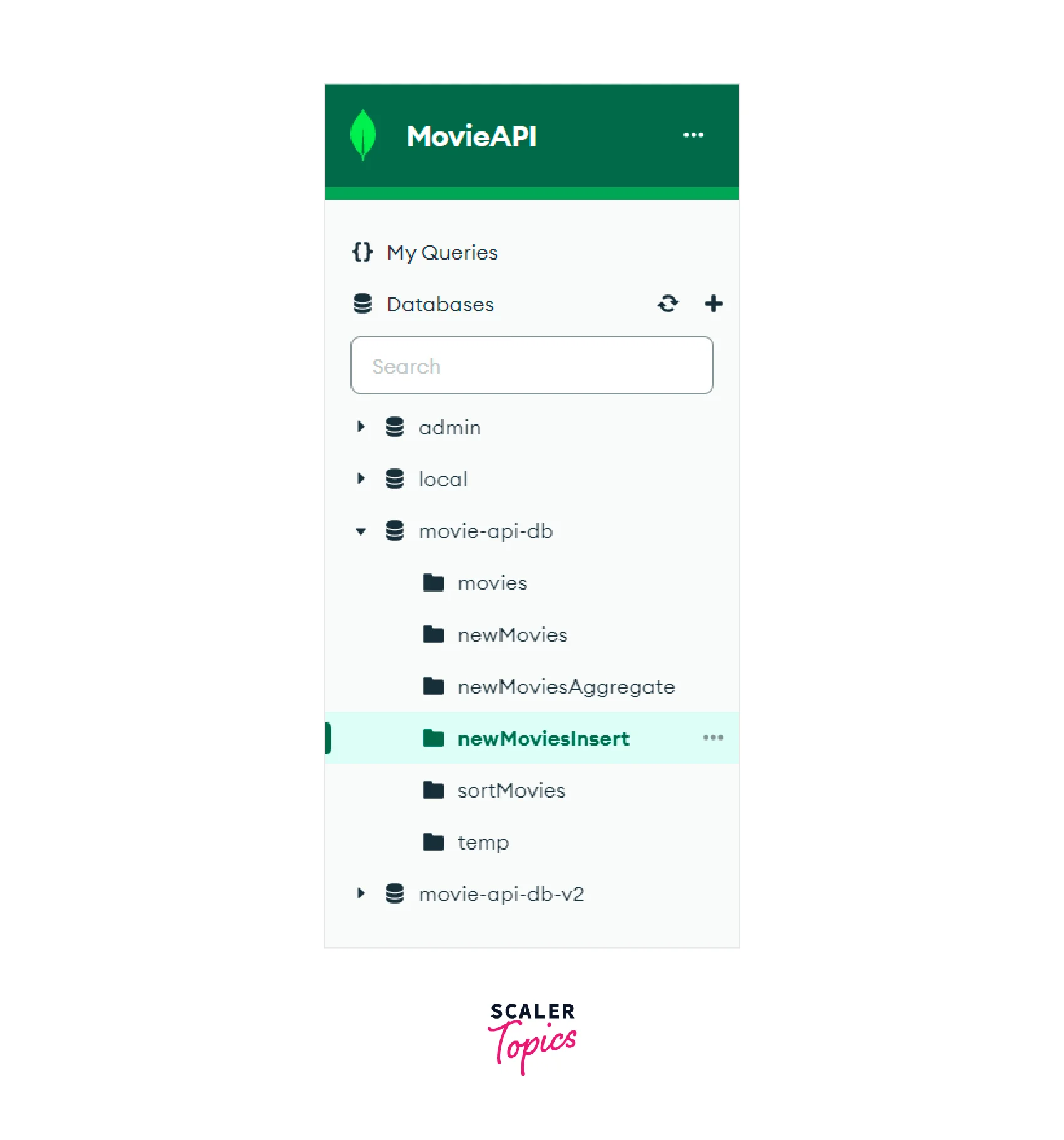
Thus, we can see that the “newMoviesInsert” collection has been created.
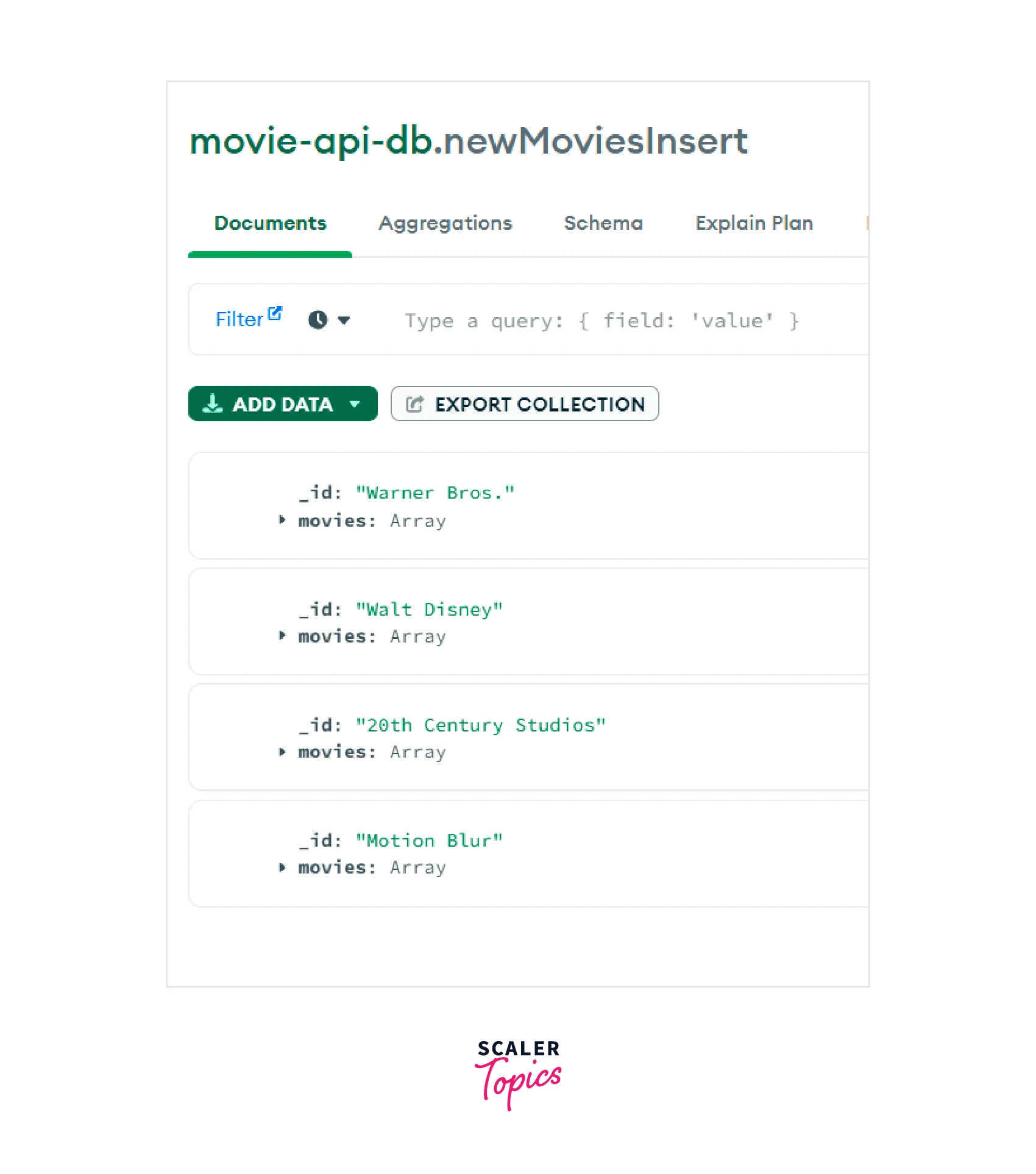
In the image given above, we can see that the "newMoviesInsert" collection has four documents. The documents have been grouped according to their "productionCompany". Each document's "_id" field represents their "productionCompany" and the "movies" field is an array of the movie "titles" which belong to the same "productionCompany".