BERT Model in NLP
Overview
BERT is one of the most influential technologies introduced by Google Research in recent years, which has had a massive effect on the field of NLP. BERT model has achieved state-of-the-art results in 11 different NLP tasks with minimal fine-tuning of the pre-trained model. This ease of use and contextual understanding of languages is well received in the Deep Learning community.
Introduction to BERT
BERT stands for Bi-directional Encoder Representation from Transformers. As the name states, it is based on the Transformer Architecture(See the paper “Attention is all you need”. The BERT model is made to be pre-trained and form deep bi-directional connections between words to encapsulate the word's entire context.
The BERT model is designed to learn the language and the context. BERT is pre-trained on a large set of unlabelled text, which includes the entire Wikipedia(2500 million words) and Book Corpus(800 million words). It takes all the words simultaneously and uses them to get the embeddings of the word.
The Bi-directional understanding of a sentence is important as it’s difficult to obtain the language's true meaning without considering the whole sentence.
Example:
We will meet at the park.
You can park the car on the roadside.
Here the word park has two different meanings. Without the rest of the sentence, it is impossible to find the meaning of the word park. A bi-directional model solves this.
How does BERT Work?
As we saw earlier, the BERT model requires a robust contextual understanding of Language. A BERT architecture has an Encoder and a Decoder. The Encoder part is responsible for processing the input words and understanding the context, while the decoder performs specific tasks such as translation or next-word prediction. BERT also incorporates the word position information when it forms word embeddings sent to the training phase.
Now we are going to see how text processing happens in the Encoder.
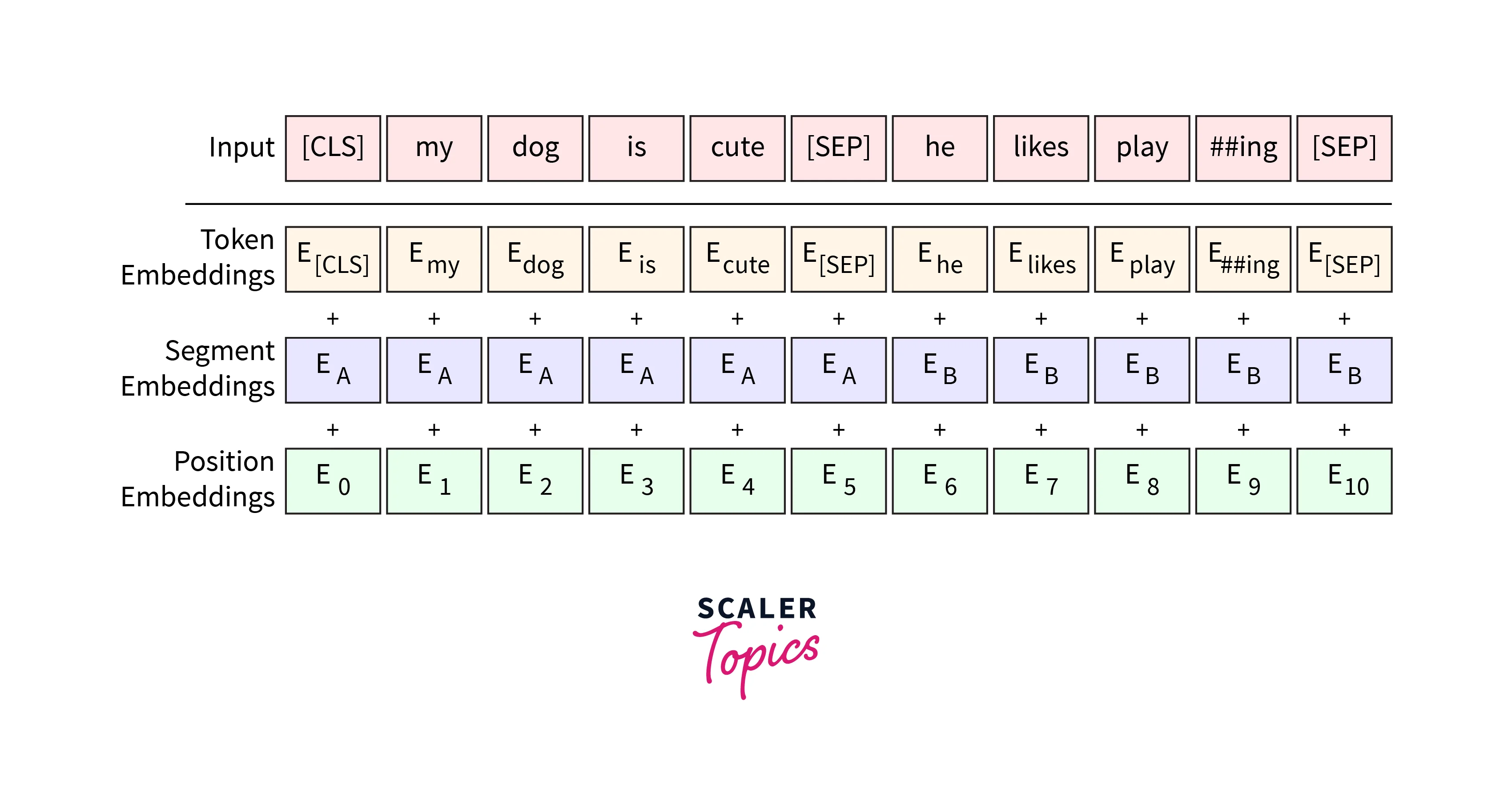
The process of converting words to a more accessible format for the system to understand is called embedded.
There are three parts to embedding:
- Position Embedding: This value represents the word's position in the sentence. This is extremely important for the model to be Bi-directional.
- Segment Embedding: BERT model can take multiple sentences. Segment Embedding lets the model know the sentence order as well. This is very important in the pre-training phase.
- Token Embedding: This gets embeddings for each word from the Wordpiece Tokenizer Vocabulary. It maps different values to different words.
These values are summed up and fed into the model. The BERT model can encapsulate the positional and word information and pass it to the model.
The next phase is the Pre-training of the model.
BERT architecture is trained on two main tasks:
- Masked Language Modelling(MLM)
- Next Sentence Prediction
Masked Langauge Modelling is a training technique where a word is masked, meaning the word is replaced with the token [MASK]. The system will try to find the original word that was Masked. It is like 'fill in the blanks, where the model tries to predict the word in the blank. This training technique will help to build strong Language knowledge for the model.
Next Sentence Prediction is also a pre-training technique where two sentences are fed to the model, and the model asks whether the second sentence should follow the first sentence. Now, the model can establish connections between sentences and check if they are related. This technique helps build a contextual understanding of the Language. These two techniques are done simultaneously. This returns excellent results.
What is BERT Used For?
The BERT NLP model is used in a variety of NLP tasks.
- BERT architecture can perform Sentiment Analysis on product reviews.
- Text Prediction when typing emails or texts.
- Can do Question-Answering like Alexa or Siri.
- Can perform para-phrasing and summarization.
And so much more. Most of our voice-operated devices and Translation tools use a BERT NLP model to perform.
BERT's Model Size and Architecture:
BERT architecture works using attention heads or blocks to enable NLP.
There are two structures:
BERT Base: Number of Transformers layers = 12, Total Parameters = 110M
BERT Large: Number of Transformers layers = 24, Total Parameters = 340M
BERT's Performance on Common Language Tasks:
SQuAD v1.1- Stanford Question Answer Dataset is a collection of 100k crowdsource Question Answer Pairs. A data point includes a query and a text from Wikipedia that answers the query. The aim is to answer the query with a word from the passage. The top leaderboard system outperforms the best-performing BERT model by a 1.5 F1-score in an ensemble and a 1.3 F1-score when used alone.
SQuAD v2.0- is an improved dataset which uses the same passages but different queries, where the answers to the queries may not be in the passage. This increases the complexity of the task much more. In this task, BERT NLP alone doesn't match human-level performance. But the later models that could match human-level performance and more were all based on BERT.
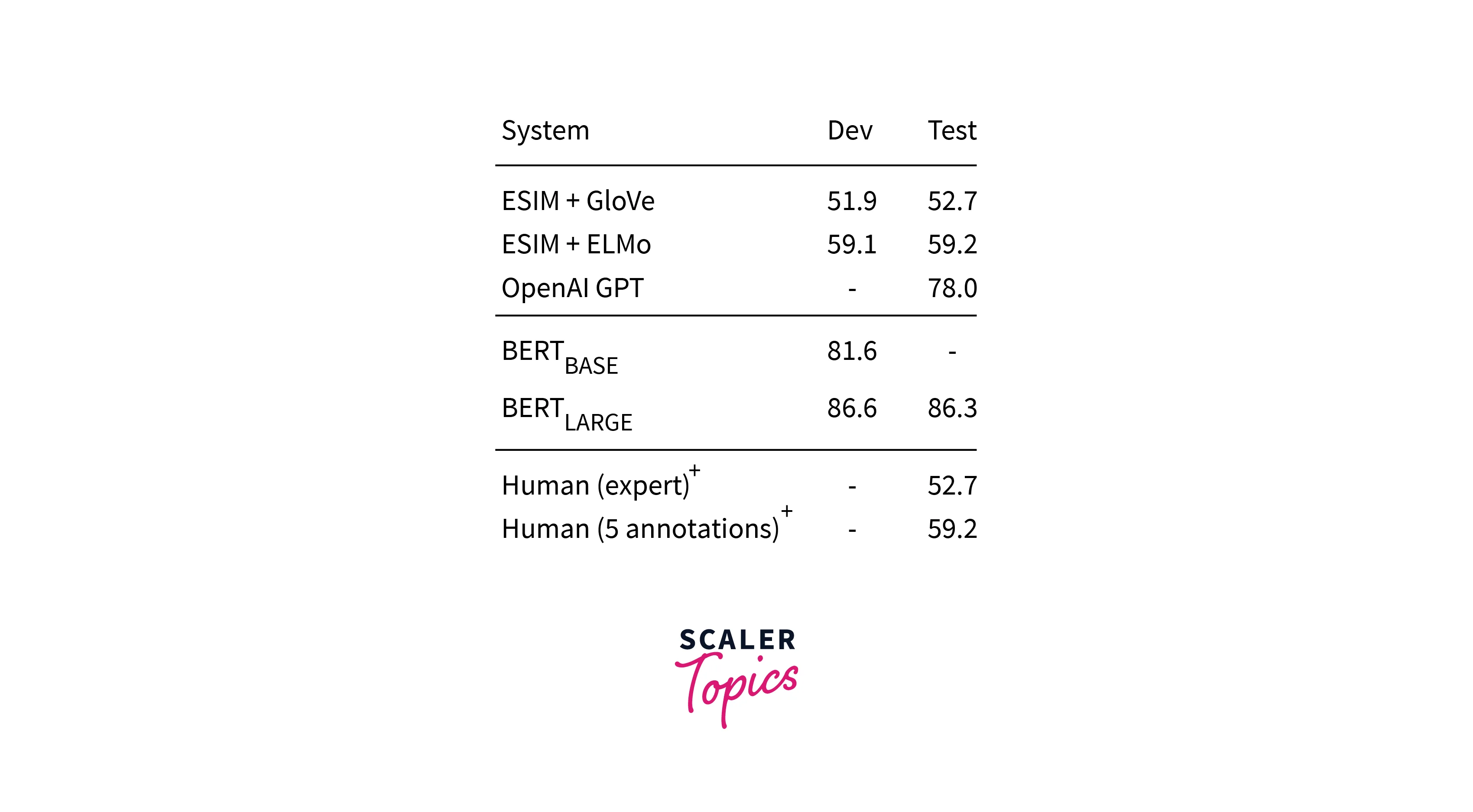
SWAG- Situations With Adversarial Generations is a data set containing 113k sentence completion tasks. Given a sentence, the model should choose the most likely continuation of the sentence among the four choices. In this task, BERT outperforms expert human levels. The results are given below.
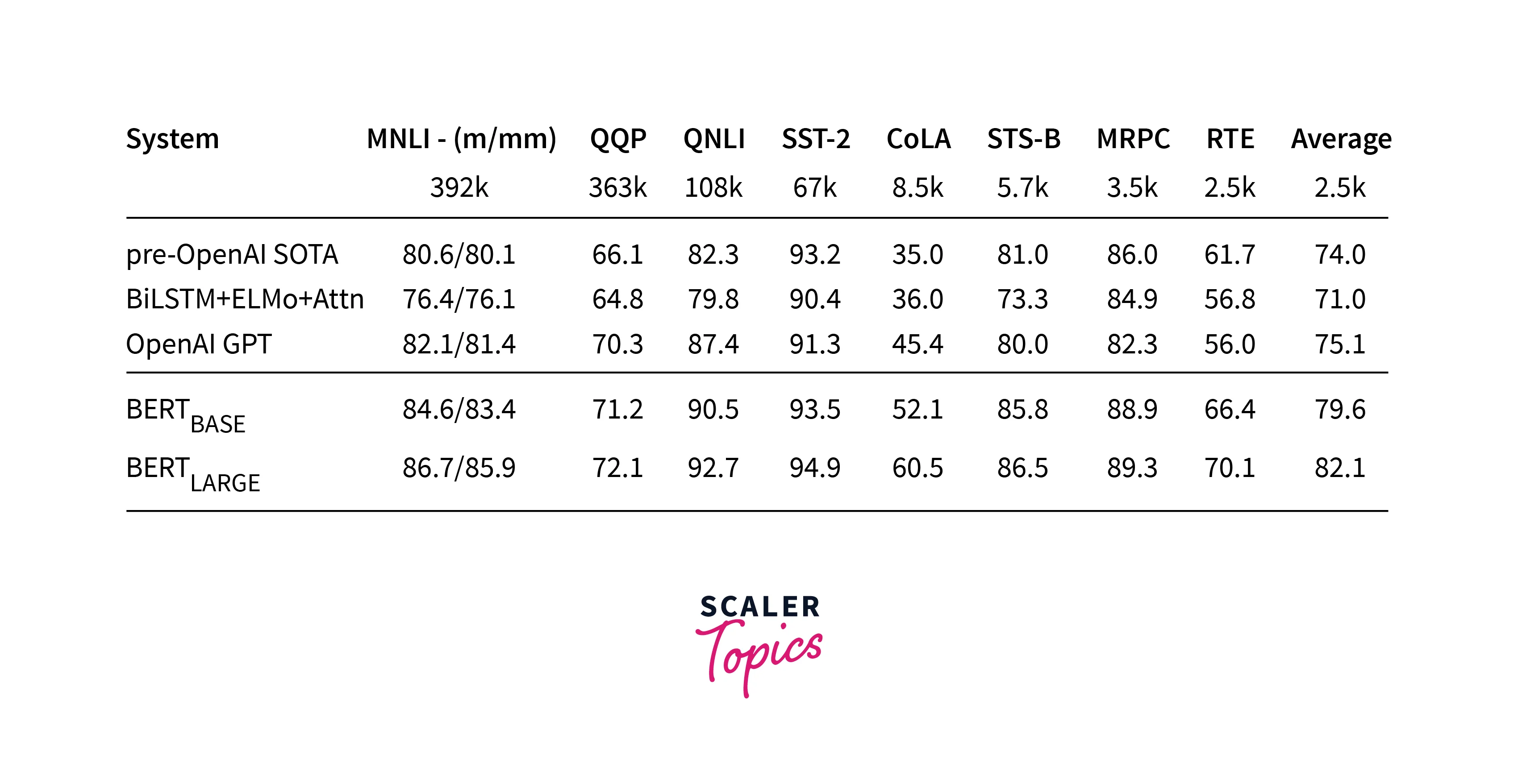
Glue Benchmark-, A variety of Natural Language Understanding tasks are included in the General Language Understanding Evaluation(GLUE) assignment. These include QQP (Quora Question Pairs), MNLI (Multi-Genre Natural Language Inference), SST-2 (The Stanford Sentiment Treebank), CoLA (Corpus of Linguistic Acceptability), and QNLI (Question Natural Language Inference). BERT outperforms all previous models by some margin.
BERT’s Source Code (The Open Source Power of BERT):
BERT is open-source and is free to use by any individual, unlike other large models like GPT-3. Anyone can build state-of-the-art models for different tasks by leveraging the open-source power of BERT. So now, the users can focus on fine-tuning the model for the respective tasks. This saves users a lot of time that might've been wasted in training.
This link will take you to the source code Source Code.
Getting Started with BERT
The first step to using BERT NLP is to open a new notebook(Google Colab, Jupyter etc.) and install transformers.
The Transformers package contains the pre-trained BERT model we will use.
The Transformer Library has a section called Pipeline which we will import. Pipelines are pre-trained models which are trained for a specific task. In our case, we will use a fill-mask pipeline, which is a fill-in-the-blank task. The following lines of code will download the following pipeline.
After mapping the model to the unmasker function, we can now use the model by entering a sentence with the word we want to predict under the keyword [MASK].
The model will return a list of sentences with predicted words that the model thinks are most suited instead of [MASK].
The above code should give similar output:
Conclusion
- BERT is a deep learning model that has delivered better performance than all its predecessors in NLP tasks.
- BERT architecture has an Encoder and a Decoder, which enables a contextual understanding of language.
- BERT model is pre-trained with a large vocabulary of words, so training for specific tasks becomes much easier as it only requires fine-tuning the model.
- The Open Source nature of BERT NLP has enabled any individual to use the amazing power of this model.