Next sentence prediction with BERT
Overview
BERT Next sentence Prediction involves feeding BERT the inputs "sentence A" and "sentence B" and predicting whether the sentences are related and whether the input sentence is the next. The BERT model is trained using next-sentence prediction (NSP) and masked-language modeling (MLM). Now, training using NSP has already been completed when we utilize a pre-trained BERT model from hugging face.
Prerequisites
Before practically implementing and understanding Bert's next sentence prediction task. You must:
- Ensure you install transformers, which provide thousands of pre-trained models to perform tasks.
- The main aim of Bidirectional Representation for Transformers(BERT) is to understand the meaning of the queries related to google searches.
- Here, we will use the BERT model to understand the next sentence prediction though more variants of BERT are available.
Introduction
Bidirectional Encoder Representations from Transformers, or BERT, is a paper from Google AI Language researchers. By offering cutting-edge findings in a wide range of NLP tasks, such as Question Answering (SQuAD v1.1), Natural Language Inference (MNLI), and others, it has stirred up controversy in the machine learning community.
The primary technological advancement of BERT is the application of Transformer's bidirectional training, a well-liked attention model, to language modeling. In contrast, earlier research looked at text sequences from either a left-to-right or a combined left-to-right and right-to-left training perspective.
Researchers have consistently demonstrated the benefits of transfer learning in computer vision. That involves pre-training a neural network model on a well-known task, like ImageNet, and then fine-tuning using the trained neural network as the foundation for a new purpose-specific model. Researchers have recently demonstrated that a similar method can be helpful in various natural language tasks.
What is Next Sentence Prediction (NSP)?
Next sentence prediction involves feeding BERT the words "sentence A" and "sentence B" twice. Then we ask, "Hey, BERT, does sentence B follow sentence A?" True Pair or False Pair is what BERT responds.
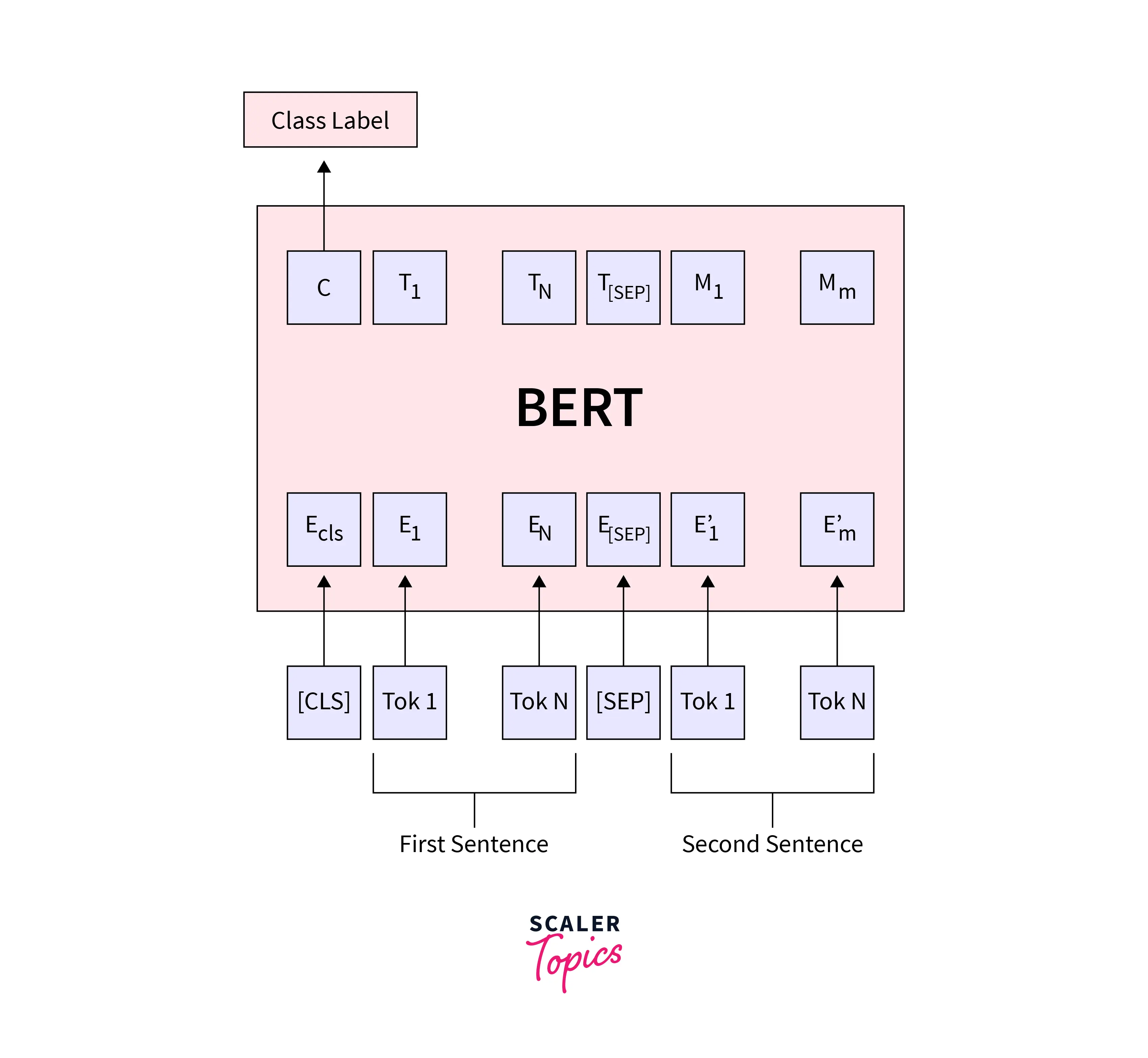
Let's consider three sentences:
- The Sun is a huge ball of gases. It has a diameter of 1,392,000 km.
- The Bhagavad Gita is a holy book of the Hindus. It is a part of the Mahabharata.
- It is mainly made up of hydrogen and helium gas. The surface of the Sun is known as the photosphere.
When we look at sentences 1 and 2, they are completely irrelevant, but if we look at the 1 and 3 sentences, they are relatable, which could be the next sentence of sentence 1. Our pre-trained BERT next sentence prediction model does this labeling as "isnextsentence" or "notnextsentence".
Methods to Finetune the BERT Model
Three different methods are used to fine-tune the BERT next-sentence prediction model to predict.
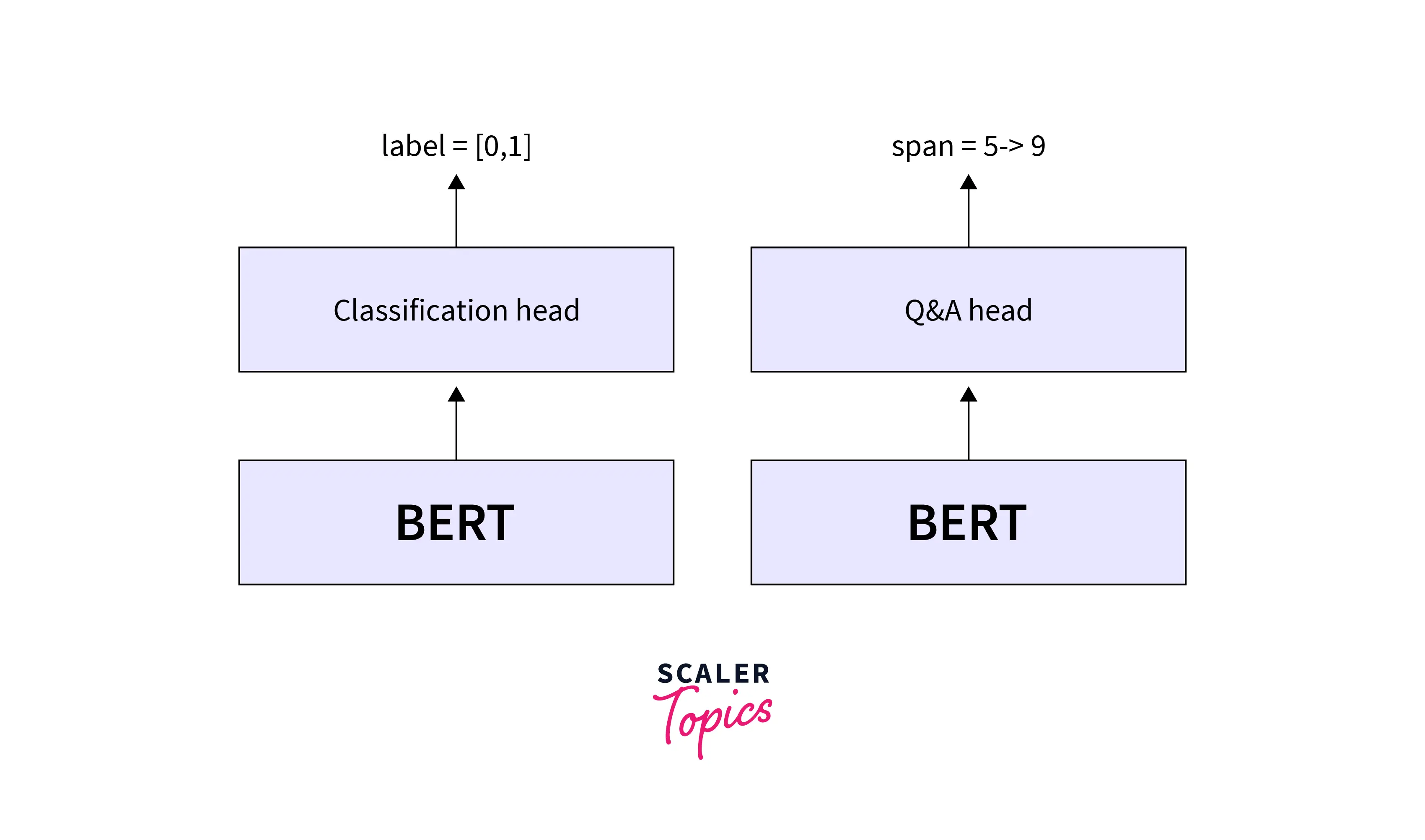
-
Output with one class
- A significant classification task is MNLI (Multi-Genre Natural Language Inference). We have provided a couple of sentences for this challenge. The objective is to determine if the second statement implies the first, contradicts it, or is neutral.
- QQP (Quora Question Pairs), the objective is to establish whether two questions are semantically equivalent.
- QNLI (Question Natural Language Inference) model must decide if the second sentence answers the query posed in the first sentence.
- 113k sentence classifications can be found in the dataset SWAG (Situations With Adversarial Generations). The challenge is to decide whether or not the second sentence continues the first.
-
The second type requires one sentence as input, but the result is the same as the label for the next class.**
- The Stanford Sentiment Treebank, or SST-2, is a binary sentence classification task that uses sentences taken from movie reviews and annotated to show how they felt at the time.
- CoLA (Corpus of Linguistic Acceptability) determines whether a given English sentence is grammatically correct.
-
In the third type, a question and paragraph are given, and then the program generates a sentence from the paragraph that answers the query. The datasets used are SQuAD (Stanford Question Answer D) v1.1 and 2.0.
Implementing Next Sentence Prediction in Python
Along with the bert-base-uncased model(BERT) next sentence prediction model, we'll be utilizing HuggingFace's transformers, PyTorch. To begin, let's install and initialize everything:
We implemented the complete code in a web IDE for Python called Google Colaboratory, or Google introduced Colab in 2017.
Make sure you install the transformer library
Let's import BertTokenizer and BertForNextSentencePrediction models from transformers and import torch
Now, Declare two sentences sentence_A and sentence_B
Let's start Tokenization.
Tokenization
We tokenize the inputs sentence_A and sentence_B using our configured tokenizer.
Output
Our two sentences are merged into a set of tensors. There are two ways the BERT next sentence prediction model can the two merged sentences.
- A [SEP] token is added between the sentences. In our input_ids tensors, it was represented as 102.
- With the token_type_ids tensor where sentence_A was represented by 0 adn sentencce_B by 1.
Output
Creating the classification label
The last step is basic; all we have to do is construct a new labels tensor that indicates whether sentence B comes after sentence A. True Pair is represented by the number 0 and False Pair by the value 1.
Output
Calculate Loss
We finally get around to figuring out our loss. We begin by running our model over our tokenized inputs and labels. Losses and logits are the model's outputs.
Output
Prediction Using a Pretrained Model
We can also decide to utilize our model for inference rather than training it. As there would be no labels tensor in this scenario, we would change the final portion of our method to extract the logits tensor as follows:
Output
Get argmax to get out prediction
Output
From this point, all we need to do is take the argmax of the output logits to get the prediction from our model. In this instance, it returns 0, indicating that the BERTnext sentence prediction model thinks sentence B comes after sentence A.
Conclusion
- Unquestionably, BERT represents a milestone in machine learning's application to natural language processing. Future practical applications are likely numerous, given how easy it is to use and how quickly we can fine-tune it.
- This article illustrates the next sentence prediction using the pre-trained model BERT.
- We can also optimize our loss from the model by further training the pre-trained model with initial weights.