Question-answering with BERT
Overview
Language representations are pre-trained using the BERT approach (Bidirectional Encoder Representations from Transformers). We can use the pre-trained memory of sentence structure, language, and text grammar from a massive corpus of millions or billions of annotated training samples that it has trained by using pre-trained BERT models. When used for small-data NLP tasks like sentiment analysis and question answering, the pre-trained model can be adjusted, yielding significant accuracy gains over training on these datasets from scratch.
Pre-requisites
- Python: You must install Python on your machine to use BERT. You can download Python from the official website (https://www.python.org/ "{rel=noopener nofollow}") and install it following the instructions provided.
- Libraries: You will need to install the following libraries to use BERT question answering:
- transformers: This library provides access to a wide range of pre-trained language models, including BERT, and tools for fine-tuning these models for various natural language processing tasks. You can install it using pip install transformers.
- torch: This library supports various tensor and neural network operations and is required by the transformers library. You can install it using. pip install torch
- Data: You will need to gather and pre-process a dataset of context-question-answer pairs that you want the model to be able to handle. This typically involves cleaning and pre-processing the data to make it suitable for training a machine learning model. You may also need to split the data into training and validation sets for training and evaluating the model.
- Hardware: Training and fine-tuning a BERT model can be computationally intensive and require a powerful machine with a good GPU. You may need to use a cloud-based solution or a powerful desktop machine to run BERT question answering.
- Basic knowledge of machine learning and natural language processing: It is helpful to have a basic understanding of machine learning and natural language processing concepts to use BERT question answering. This includes understanding how to fine-tune a pre-trained model, evaluating the model's performance, and pre-processing and preparing data for training.
Introduction
BERT (Bidirectional Encoder Representations from Transformers) is a powerful pre-trained language model developed by Google that can be fine-tuned for various natural language processing tasks, including question-answering, language translation, and text classification. BERT is based on transformer architecture, which uses self-attention mechanisms to process input sequences in a parallel and efficient manner. BERT is trained on a large dataset and can capture long-range dependencies and contextual relationships in text, allowing it to achieve state-of-the-art results on a wide range of natural language processing tasks. BERT is widely used in industry and academia and is effective for many applications.
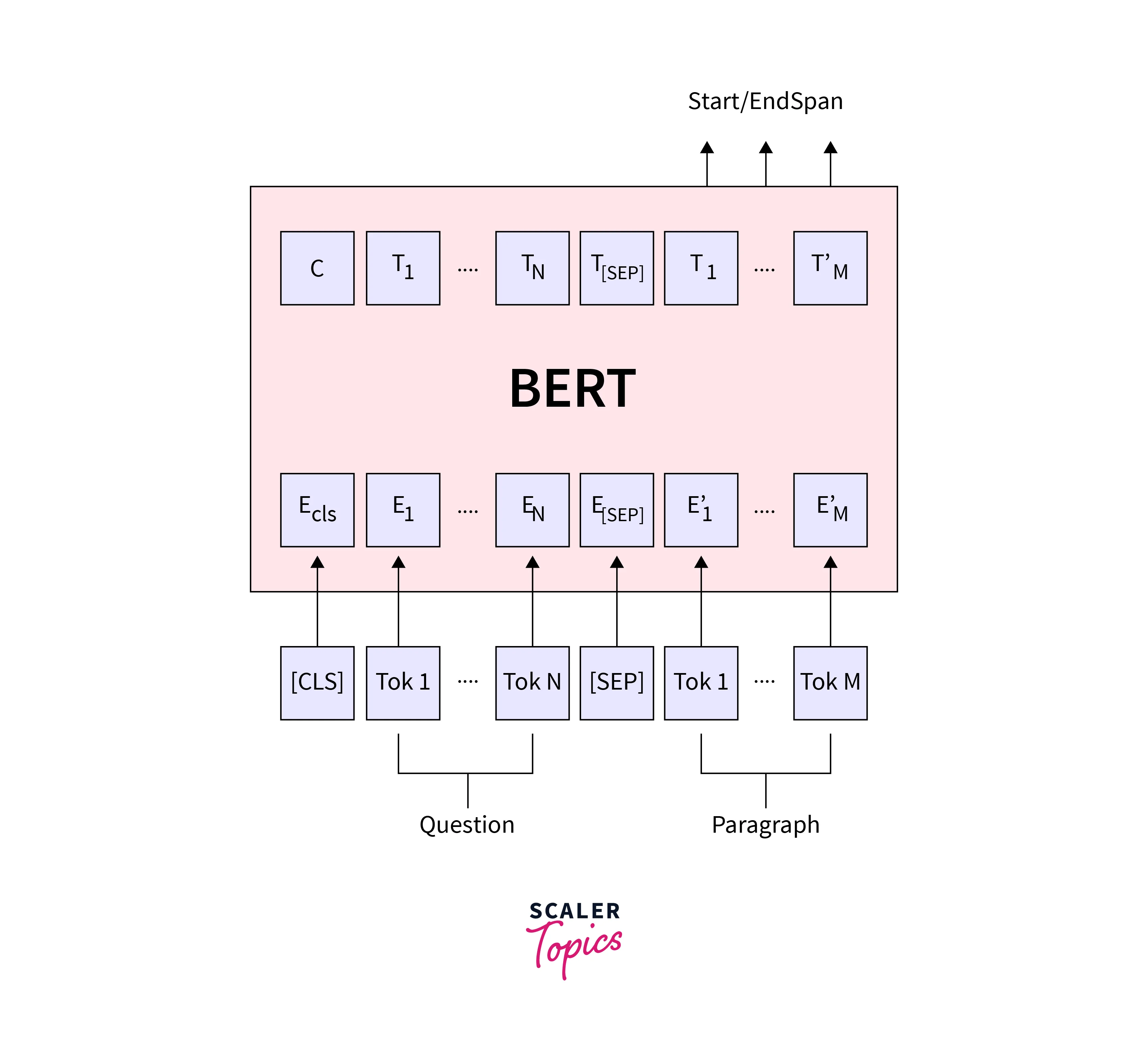
Using BERT for Question-answering
To use BERT question answeringon a small paragraph, you first need to fine-tune the BERT model on a dataset that includes similar paragraphs and question-answer pairs. This can be done by feeding the model a batch of context-question-answer triplets and optimizing the model's parameters to maximize the likelihood of predicting the correct answers given the context and questions.
Once the model has been fine-tuned, you can use it to answer questions by inputting a context (in this case, a small paragraph) and a question and getting the model's predicted answer as output. BERT is typically trained on large datasets and is designed to handle long input sequences, so it should also be able to handle question-answering tasks based on small paragraphs. The model's performance may vary on the complexity and specificity of the questions and the context of the questions.

SQuAD2.0
SQuAD2.0 (Stanford Question Answering Dataset) is a dataset for training and evaluating question-answering systems. It consists of a collection of Wikipedia articles and a set of questions about each article, and the corresponding answers. The questions are designed to test a system's ability to understand and reason about the articles' content and to find the relevant information needed to answer the questions.
The SQuAD2.0 dataset is often used to evaluate the performance of question-answering systems, including those based on language models such as BERT. To use the dataset, you would need to fine-tune a language model on the dataset by adjusting the model's parameters to fit the specific task of answering questions based on a given context. Once the model has been fine-tuned, you can use it to answer questions by inputting a context and a question and getting the model's predicted answer as output.
SQuAD2.0 is an updated version of ** the original SQuAD dataset, which was released in 2016.** It includes many articles and questions and introduces several new features, such as unanswerable questions and additional context for some questions. These changes were made to make the dataset more challenging and better reflect real-world question-answering scenarios' complexities.
Sample JSON file Information Used in the SQuAD Data Set
In the SQuAD2.0 dataset, each sample is represented as a JSON file with the following format:
The "data" field in this JSON file is a list of dictionaries, where each dictionary represents a document. The "title" field gives the title of the document, and the "paragraphs" field is a list of dictionaries, where each dictionary represents a paragraph in the document.
The "context" field in the paragraph dictionary gives the text of the paragraph, and the "qas" field is a list of dictionaries, where each dictionary represents a question-answer pair. The "question" field gives the text of the question, and the "answers" field is a list of dictionaries, where each dictionary represents an answer to the question. The "text" field in the answer dictionary gives the text of the answer, and the "answer_start" field gives the starting index of the answer in the context. The "is_impossible" field is a boolean value that is set to "True" if it is not possible to find an answer to the question in the context and "False" otherwise.
How to run Question Answering Model with BERT
1. Importing and loading the model and tokenizer: In this code, we first import the BERT tokenizer and model from the transformers library. We then use the from_pretrained() method to load a pre-trained version of the BERT model and tokenizer. The specific version that is being loaded is 'deepset/bert-base-cased-squad2', which is a fine-tuned version of BERT for question answering using the SQuAD dataset.
- Performing Question Answering: After loading the model and tokenizer, we define the input text and question that we want to use for question answering. We then use the tokenizer to encode the input text and question and get the scores for each word in the text. This will be passed as input to the model and it will give the start and end indices of the token which will be used to extract the span of words as the answer. We use torch.no_grad() to prevent the computation of gradients. Finally, the extracted span of words is decoded and printed as the answer.
Output
Extending BERT as Chatbot for Specific Data
To extend BERT as a chatbot for a specific dataset, you would need to follow these steps:
Data Preparation
You need to gather and pre-process the data that you want the chatbot to handle. This typically involves gathering large conversation logs or transcripts datasets and then cleaning and pre-processing the data to make it suitable for training a machine learning model. You should also split the data into training and validation sets for training and evaluating the model
Training and prediction
Next, you need to fine-tune the BERT model on the dataset you have prepared by adjusting the model's parameters to fit the specific task of generating responses to input queries. This can be done by feeding the model a batch of input-output pairs (where the input is a query and the output is a response) and optimizing the model's parameters to maximize the likelihood of predicting the correct responses given the queries. Once the model has been fine-tuned, you can generate responses to input queries by inputting a query and getting the model's predicted response as output.
Output
To make prediction
Ouput
Pros
- BERT is a powerful and widely used language model trained on a large dataset and can understand complex language and context.
- Using BERT as a base model for a chatbot allows you to leverage the existing capabilities of BERT and focus on fine-tuning it for your specific data and use case.
- Extending BERT as a chatbot allows you to build a chatbot that can understand and respond to specific questions or topics.
Cons
- BERT requires a lot of data and computing resources to train, so it may not be practical for smaller projects or datasets.
- BERT may need help understanding and responding to out-of-domain questions or topics on which it has not been trained.
- BERT may not be able to understand and respond to more complex or abstract questions or topics, even if it has been trained on similar data.### Pros
Conclusion
- To use BERT question answering, you can first gather and pre-process a dataset of context-question-answer pairs and
- Then, fine-tune a BERT model on the dataset by adjusting the model's parameters to fit the specific task of answering questions based on a given context.
- Once the model has been fine-tuned, you can use it to answer questions by inputting a context and a question and getting the model's predicted answer as output.
- To evaluate the model's performance, you can compare the model's predicted answers to the ground-truth answers in the dataset and calculate various evaluation metrics.
- BERT is a powerful tool for question answering and can achieve state-of-the-art results on various datasets.