Continuous Bag of Words (CBOW) Model in NLP
Overview
The continuous bag-of-words (CBOW) model is a neural network for natural languages processing tasks such as language translation and text classification. It predicts a target word based on the context of the surrounding words and is trained on a large dataset of text using an optimization algorithm such as stochastic gradient descent. Once trained, the CBOW model generates numerical vectors, known as word embeddings, which capture the semantics of words in a continuous vector space and can be used in various NLP tasks. It is often combined with other techniques and models, such as the skip-gram model, and can be implemented using libraries like gensim in python.
Introduction
Word2vec is a widely used natural language processing technique that uses a neural network to learn distributed representations of words, also known as word embeddings. These embeddings capture the semantics of a word in a continuous vector space, such that similar words are close together in the vector space. Word2vec has two main model architectures: continuous bag-of-words (CBOW) and skip-gram. CBOW predicts the current word based on the context of the surrounding words, while skip-gram predicts the surrounding words given the current word. Word2vec can be trained on a large text dataset and is commonly used in various natural language processing tasks, such as language translation, text classification, and information retrieval.
What is the CBOW Model
The continuous bag-of-words (CBOW) model is a neural network for natural language processing tasks such as language translation and text classification. It is based on predicting a target word given the context of the surrounding words. The CBOW model takes a window of surrounding words as input and tries to predict the target word in the center of the window. The model is trained on a large text dataset and learns to predict the target word based on the patterns it observes in the input data. The CBOW model is often combined with other natural language processing techniques and models, such as the skip-gram model, to improve the performance of natural language processing tasks.
Understanding CBOW Model
CBOW (Continuous Bag of Words) model predicts a target word based on the context of the surrounding words in a sentence or text. It is trained using a feedforward neural network where the input is a set of context words, and the output is the target word. The model learns to adjust the weights of the neurons in the hidden layer to produce an output that is most likely to be the target word.
The embeddings learned by the model can be used for a variety of NLP tasks such as text classification, language translation, and sentiment analysis. It's fast and efficient in learning the representation of context words and predict the target word in one go, which is also known as one pass learning. Its method is widely used in learning word embeddings, where the goal is to learn a dense representation of words, where semantically similar words are close to each other in the embedding space.
CBOW Architecture
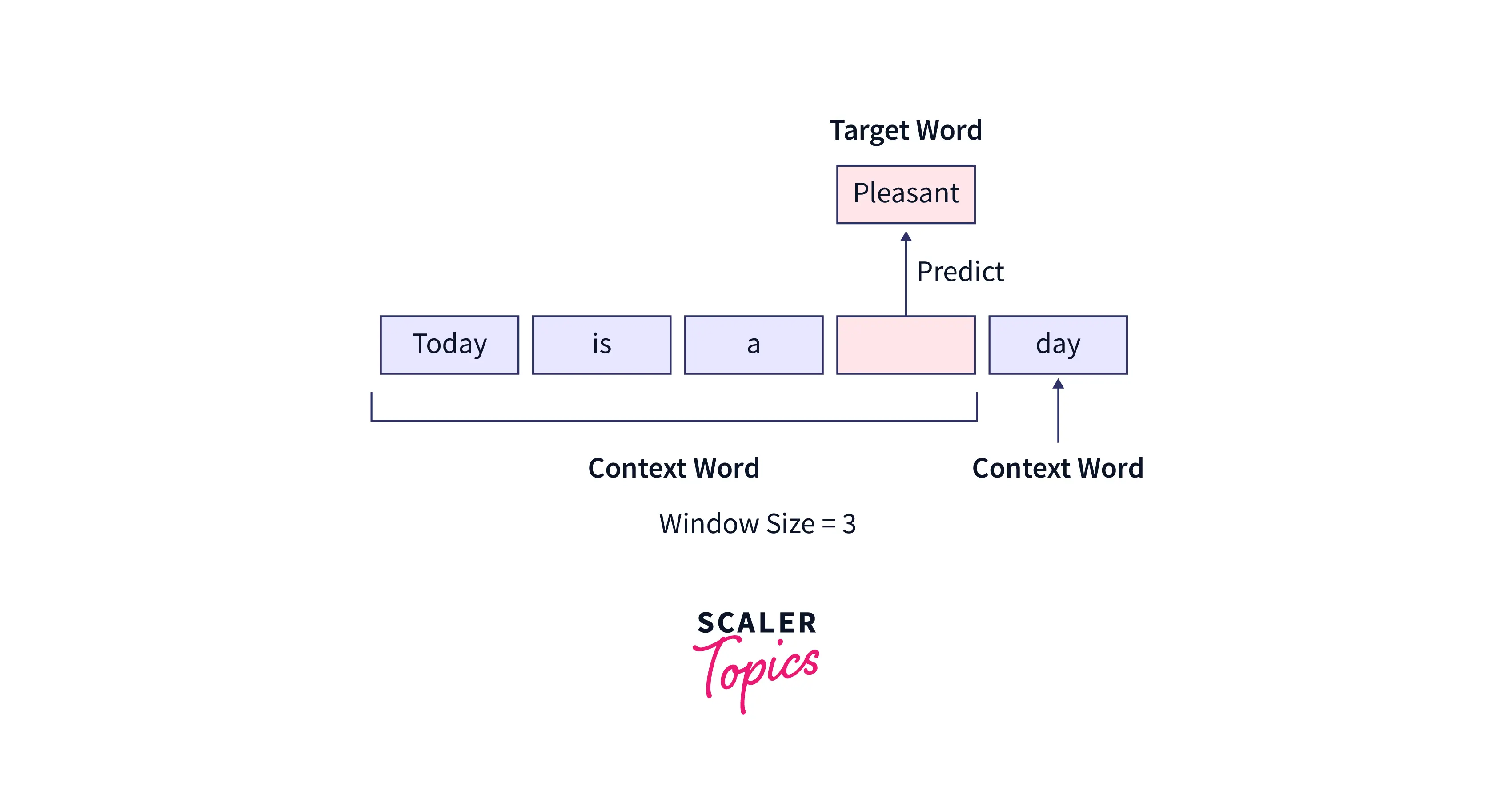
The CBOW model attempts to comprehend the context of the words around the target word to predict it. Consider the previous phrase, "It is a pleasant day." The model transforms this sentence into word pairs (context word and target word). The user must configure the window size. The word pairings would appear like this if the context word's window were 2: ([it, a], is), ([is, nice], a) ([a, day], pleasant). The model tries to predict the target term using these word pairings while considering the context words.
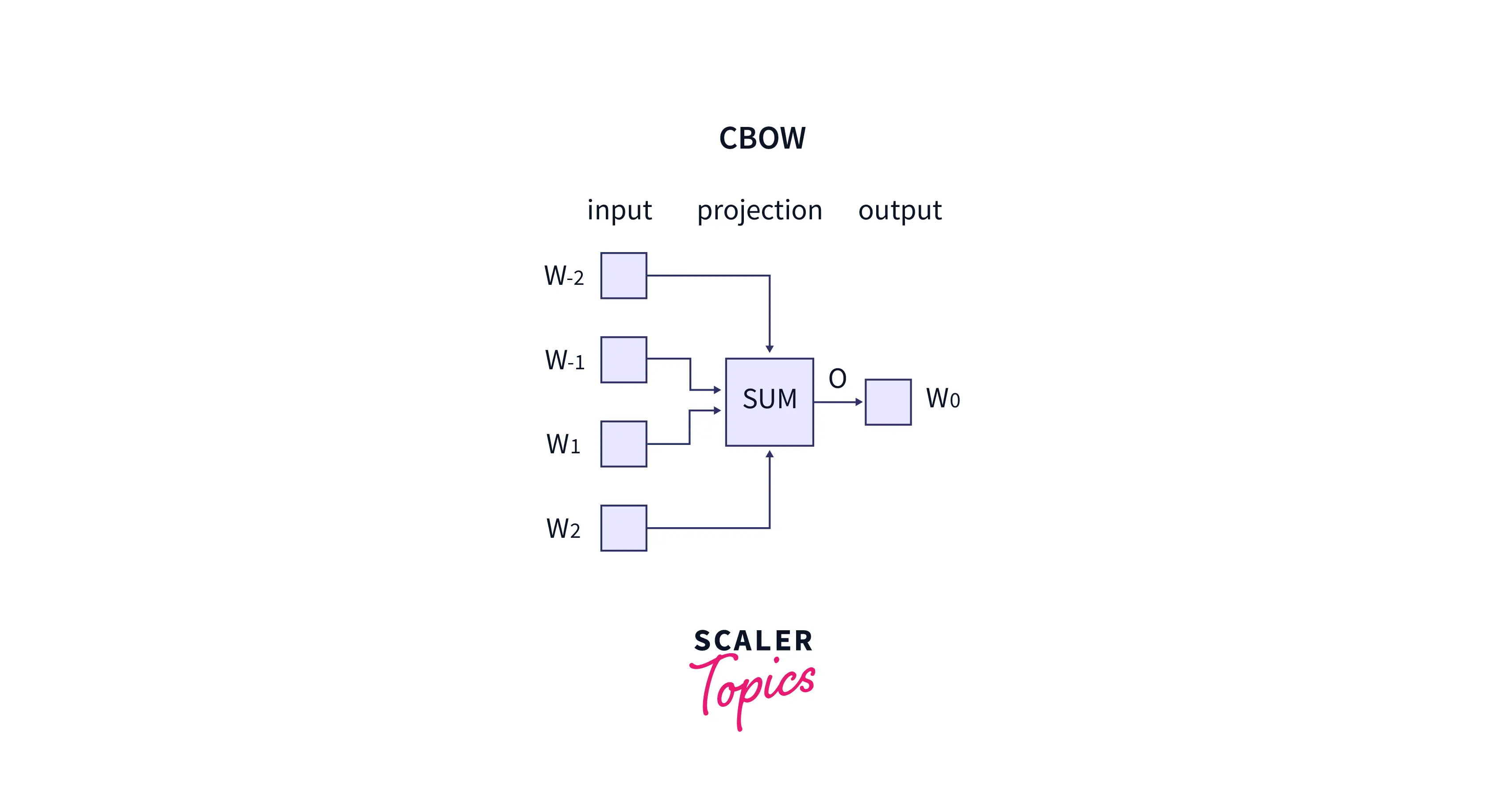
Four input vectors will make up the input layer if four context words are utilized to predict one target word. The hidden layer will receive these input vectors and multiply them by a matrix. The output from the hidden layer finally enters the sum layer, where the vectors are element-wise summed before a final activation is carried out and the output is obtained.
Vocabulary in Word2Vec
In word embedding models such as word2vec, the vocabulary refers to the set of unique words on which the model has been trained. The vocabulary is typically created by preprocessing the input text data and selecting a subset of words to include based on certain criteria, such as frequency of occurrence or length.
For example, the word2vec model can create the vocabulary by building a dictionary of all the unique words in the input text data and filtering out words that occur too infrequently or are too long. The vocabulary size is typically determined by the parameter min_count, which specifies the minimum number of occurrences of a word in the input data for it to be included in the vocabulary.
The vocabulary is used to create numerical vectors, also known as word embeddings, for each word in the vocabulary. These word embeddings capture the semantics of the words in a continuous vector space, so similar words are close together in the vector space. The word embeddings are then used as input to the word2vec model, which processes the input data and learns the relationships between words.
Implementation of CBOW Model
The gensim library is a popular Python library for natural language processing that provides implementations of various word embedding models, including the continuous bag-of-words (CBOW) model. Here is an example of how the CBOW model works using gensim:
First, you will need to install the gensim library using pip:
Import Required Libraries
This section imports necessary libraries such as Word2Vec from gensim and brown corpus from nltk.
Data Preprocessing
We download the brown corpus in this section and use it as the sample data.
Model
In this section, we instantiate a CBOW model using the gensim library's Word2Vec class and set some of the model's hyperparameters, such as minimum word count, size of the embedding vectors, window size, and training algorithm (CBOW = 0)
Train
In this section, the model is trained on the data with a specified number of epochs.
During training, the CBOW model processes the input data and adjusts the values of the weights and biases of the neurons in the hidden layers and the output layer to minimize the error between the predicted target word embedding and the true target word embedding. This process is called backpropagation.
Word Embeddings
The model in this section learns the embeddings.
To improve the model, train the model with a large dataset as language input.
Cosine Similarity
In this section, we calculate the cosine similarity between two words, 'woman' and 'man', this measures how similar the two words are in meaning.
Output:
Visualize
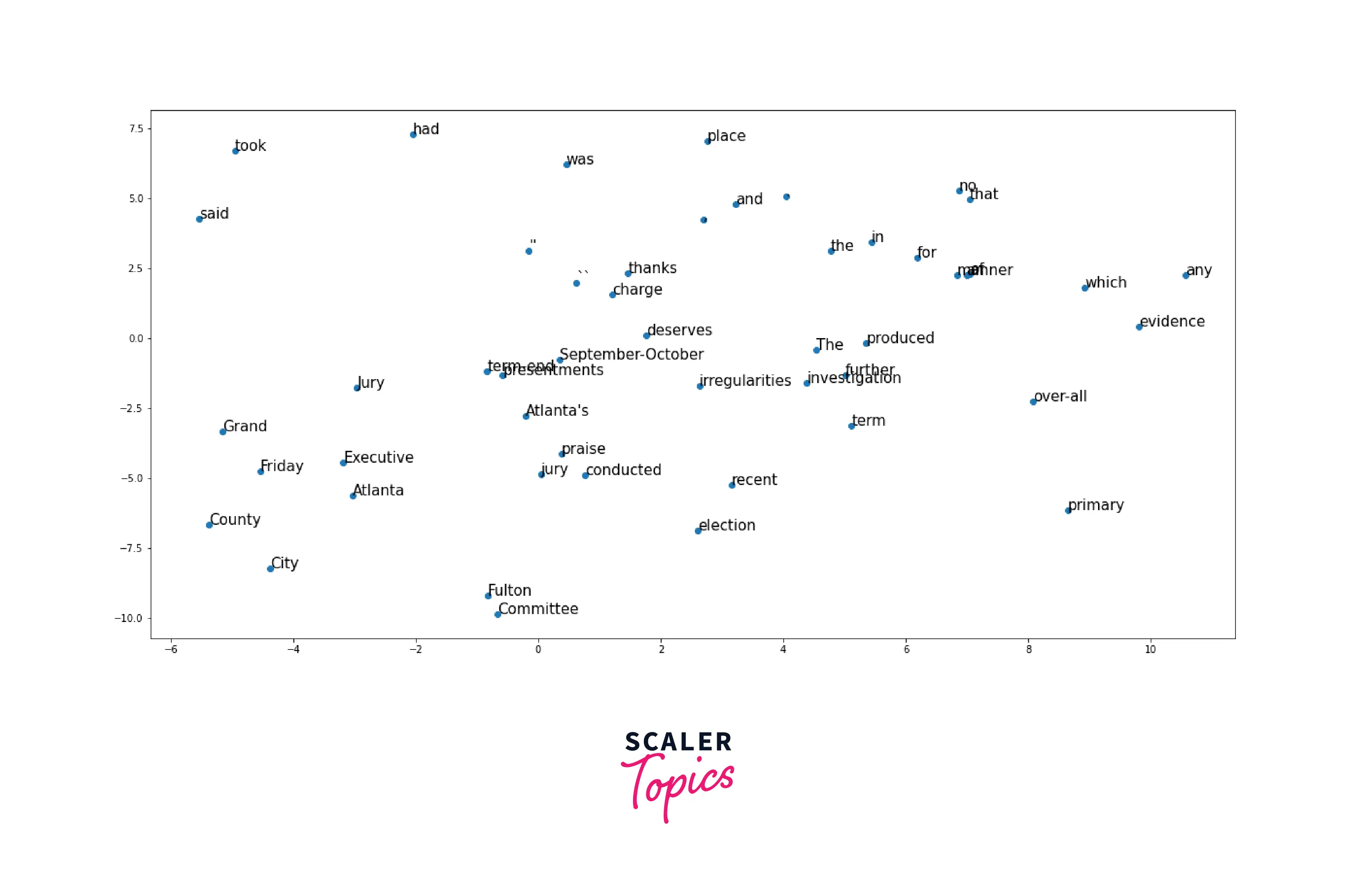
Here, we use sklearn's PCA to plot the word vectors which is visualize only 100 words in 2-Dimensional space.
Conclusion
- The continuous bag-of-words (CBOW) model is a neural network for natural language processing tasks such as translation and text classification.
- It is based on predicting a target word given the context of the surrounding words.
- CBOW models are trained on a large dataset of text and adjust the weights and biases of the neurons during training to minimize the error between the predicted target word embedding and the true target word embedding.
- In conclusion, the CBOW model is a powerful tool for natural language processing tasks and can be easily implemented using the gensim library in python.
- By understanding the principles of the CBOW model and how to use it with gensim, you can improve your knowledge of this topic and apply it to a wide range of applications.