How to create your Own NLP Module?
Overview
Natural language processing has functionalities that can be performed by using off-the-shelf tools either commercial or open source for simplicity / using state-of-the-art or configuring, building, and maintaining custom NLP modules for better control and usage.
What are We Building?
Natural language processing and its associated tools help act as a bridge between humans and computers to communicate their own language and scale to other language-related tasks.
- Different NLP modules tackle different tasks and functions like text mining, text classification, text analysis, sentiment analysis, word sequencing, speech recognition & generation, machine translation, and dialogue systems, etc.
- A module is a building block for the creation of the experiments and helps with all the tasks we intend for it to work on in our problem statement. Every module may have specific functionalities like machine learning algorithms or functions that are used across different modules.
Description of the Problem Statement
One of the problems associated with machine learning modules and NLP, in particular, is that often organizations do not want their data to cross country borders, or vest in some commercial cloud environment where it is hard to enforce laws pertaining to the protection of person information.
- In such cases, one needs to know how to create their own nlp modules to bypass data restrictions and this also provides other advantages like cost saving and complete control over fine-tuning and bringing any nuances of business into the context of in-house modules quickly.
- This article provides an overview of the different tasks associated with building a custom NLP module with an example implementation with step by step approach.
Pre-Requisites
-
Out-of-the-box Tools: It is generally established that the process is cumbersome and time-consuming process for building solutions, particularly for text-based analytics and modeling. We need to spend hours sorting through the text corpora of documents to analyze the associated text, and then label the keywords or sentiment in the data set which is cumbersome and not the best use of the NLP practitioner's time to look after this whole pipeline.
- Out-of-the-box tools or pre-trained NLP models when compared to building your own nlp module automate the various tasks in this whole process. Out of the box libraries and models provide tremendous advantage when one have limited time or do not have data to train these models for particular problem statements.
- They are effective for quick proofs of concept and have a high return on investment especially when one's need is to understand higher-level items like categories or concepts within the documents. Pre-built models are often trained on general-purpose data sources and tend to be not tailored to any one industry or domain.
-
Custom Modules: One main disadvantage with out of box models is that when the use case contains specific industry language, pre-trained models may only meet a certain portion of the needs. These kinds of problems can be rectified by building their own custom modules and fine-tuning for the desired task at hand.
- Entities like people, places, events, etc. will have different meanings across different industries, so an out-of-the-box model may not be able to pick up on these nuances depending on the context.
- Example: The word premium can mean the top end of a product range or it may mean the payment made in exchange for a user policy in the insurance domain.
- We will make the improvements that ensure the model’s effectiveness by specific nudges in design like defining specific entities for extraction from a document or the relationships between them through model training. For custom building your own nlp modules, as an additional step, the notations created on the documents provide the system with specific examples that serve as the ground truth for the model.
-
SME in process of NLP model building: A subject matter expert (SME) can define what information matters in the model, upload documents for training, and then select examples often called annotations within those documents. In our example from above, we can teach the model what the word premium means in the context of that particular business we are interested in.
- Custom models can be trained to understand the underlying nuances, meaning, and relationships specific to one's use case and industry domain. These models can be built in different ways with either the help of data scientists and software developers or use no code low code tools to create them. One caveat is to rely on subject matter expertise heavily for code-free tooling generally.
-
Invest in a custom model vs. out of box solution: It is recommended to train a custom model generally to understand simple components first such as locations or organizations. This way, the NLP model hones in on the pieces that matter to the business to ultimately drive smarter decisions and save costs simultaneously.
- Once we get an idea of the overall scenario, we can make the decision to switch between custom building your own nlp module in-house solution vs. a state-of-the-art pre-built solution which is typically costly after the analysis. We can even combine an out of box NLP models with custom NLP models to get the best of both worlds.
How Are We Going to Build This?
The kind of custom NLP module we develop on our own depends on the problem statement we have and the different types of tasks we want to perform with the said NLP module. Generic examples of tasks includes NLP applications like machine translation, text classification, named entity recognition, chatbot for customer service etc. among others. Let us now look at the different steps involved commonly in the process of building an NLP module.
- Data Collection and Pre-Processing: The initial step of building the module post-requirement gathering is to collect the data and preprocess it so that we can develop and train NLP-related models or simply clean and utilize data for downstream applications.
- Common pre-processing steps on text data: Some common pre-processing steps are following are all types of models and analysis immaterial of the use case as it helps in better performance and understanding of the text we are dealing with.
- Tokenization and Stop word Removal: This involves tasks such as tokenization which involves splitting the text into individual words or smaller units, and stop word removal which is removing common words that don't add meaning to the text.
- Stemming and Lemmatization: These tasks reduce the words to their base form or base form as defined by their part of speech which helps in reducing the dimensionality of the data and simplify further analysis.
- Text Cleaning: This includes steps like lower casing, punctuation removal, special characters removal such as emojis, signs etc., and numeric data removal depending on the use case we are dealing with.
- Vocabulary building: This step is to create a vocabulary of the words in the text data to convert the text into numerical form that can be fed into downstream models.
- Pre-processing for machine learning models: We also perform some additional processing steps while dealing with machine learning or statistical or deep learning models in particular while custom building your own nlp module.
- Feature Engineering and Input Representation: One of the important steps in models dealing with text is to represent text in some numerical form. This can be done in multiple ways like one hot encoding, bag of words representation, TF-IDF vectorization, n-grams, or some kinds of dense presentation like word embedding. After we pick some suitable representation, we may need to do some dimensionality reduction steps or create some additional features as such kind of engineering will mostly augment model performance. Some models based on deep learning automatically take care of extracting features inherently and do not need feature engineering steps.
- Normalization: We scale the data so that it has zero mean and unit variance, this helps to improve the training process and prevent certain specific features from dominating the model.
- Data augmentation and data balancing: Data augmentation is when we generate new data samples from existing ones by applying various techniques to help prevent overfitting and improve the generalizability of the model. Sometimes we also need to ensure data is balanced across different classes or categories to present model bias towards the more prevalent classes, this step is called data balancing.
- Outlier removal: In this step, we identify and remove data points that are significantly different from the rest of the data as they can be detrimental to the model's performance.
- Feature selection: This step is to identify and selecting the most important features in the data for the model to use which helps in reducing the dimensionality of the data and improve the model's performance. Some models do this inherently without any additional feedback while building your own nlp module.
- Train-Test Split: We also need to split the data into training and testing sets and some times validation sets.
- Model Selection: We need to choose a model and its associated architecture that is suitable for the NLP task under consideration. There are many factors we need to consider like selecting a linear vs. non-linear model, choice of feature representation, the complexity of the model, and size of the training data.
- Choice of Linear vs. non-linear models: While linear models are simpler and faster to train, they may not be able to capture complex relationships in the data. Nonlinear models like neural networks can capture more complex relationships but are slower to train and prone to overfitting.
- Model complexity: Simpler models are less prone to overfitting but they may also be less accurate. Complex models in general will be able to capture more complex relationships in the data but also be more prone to overfitting. In general, when there are not a lot of differences in accuracy between simpler and complex models, we can prefer simpler models as they are easier to maintain and explain to stakeholders.
- Training data size: With a larger training dataset, we can train complex models like deep learning models more accurately with enough computational resources.
- Model Training: We will train the NLP models using the data prepared from earlier steps. As part of model training, we need to fine-tune and experiment with model architecture, and hyperparameters, and adjust the model's weights and biases to minimize the error between the predicted output and the true output iteratively to make accurate predictions on the training data.
- Model Evaluation: Evaluating the performance of the custom-built NLP model is one of the most important steps before proceeding with deploying the model in downstream applications. The evaluation step needs the modeler to choose the metrics, and prepare the test data to give you an idea of how well model generalizes to new unseen data.
- Model Deployment: We need to finally deploy the NLP model in a production environment and monitor its performance over time to ensure it continues to perform well while.
Final Output
The final output of this project is a tool - your NLP module that can be used to perform basic natural language processing tasks. To view the output, scroll down to the "Testing" section to view the output of trivial nlp tasks.
Requirements
Here are the libraries that are required for this project:
- Modules present in the standard library of python:
- os, sys, gc, warnings, logging, math, re
- Modules that are to be downloaded via a python package manager:
- pandas, numpy, seaborn, matplotlib, plotly, tqdm, tensorflow, transformers, keras, sklearn
To run the code written in this tutorial, you require a development environment that runs ipython files such as - google colab, jupyter notebook or an IDE such as dataspell IDE.
Building Your Own NLP Module
Setting Up the Jupyter Notebook
Jupyter notebook can be installed from the popular setup of anaconda or jupyter directly. Reference instructions for setting up from the source can be followed from here. Once installed we can spin up an instance of jupyter notebook server and open a python notebook instance and run the following code for setting up basic libraries and functionalities.
If a particular library is not found, they can simply be downloaded from within the notebook by running a system command pip install sample_library command. For example to install searborn, run the command from a cell within jupyter notebook like:
Getting the dataset
For this particular article, we are working on a custom model that can perform the named entity recognition (NER) problem, we will be getting the data set from Kaggle datasets related to Annotated Corpus for Named Entity Recognition which can be found here.
- The dataset is a corpus of text which is an extract from the GMB corpus which is tagged, annotated, and built specifically to train the classifier to predict named entities such as name, location, etc.
- The goal of a named entity recognition (NER) system is to identify all textual mentions of the named entities. The task can be broken down into two sub-tasks, identifying the boundaries of the named entity, and identifying its type.
- Named entity recognition is a task that is well-suited to the type of classifier-based approach. In particular, a tagging classifier based on machine learning can be built that labels each word in a sentence using the IOB format, where chunks are labeled by their appropriate type.
- There are two datasets one with fully engineered features ner.csv based on the corpus and other file ner_dataset.csv which is the data itself. The file has to be keep in the same location in the place where jupyter notebook with the code which we run here is there.
Loading the Dataset in Jupyter
Let us load the dataset and make it ready for preparing the features. Since this is a dataset of corpus that is already tagged and annotated, we can directly load the file.
Brief Description of the Features
The dataset contains four columns sentence#, word, pos, and tag. Let us look at a few sample records from the dataset for better understanding.
| Sentence # | Word | POS | Tag | |
|---|---|---|---|---|
| 0 | Sentence: 1 | Thousands | NNS | O |
| 1 | Sentence: 2 | Families | NNS | O |
| 2 | Sentence: 3 | They | PRP | O |
| 3 | Sentence: 4 | Police | NNS | O |
| 4 | Sentence: 5 | The | DT | O |
- The sentence column shows which sentence the tags came from and the second word shows the associated words within that sentence, the POS column tells the parts of speech relevant to the tag.
- The target column in the dataset is 'Tag' and it contains a set of unique values pertaining to different entities.
- The definitions and meaning for different entites is as follows:
- Info about entities:
Exploratory Data Analysis
Let us do some exploratory data analysis to understand the text in the dataset further and the association of the target with the features.
- First, we will look at the unique tags for the target and then plot the distribution of the tags in the target variable. This can be done using a pie chart.
- We can then do a pie chart that looks at the distribution of parts of speech in one of the columns.
Let us look at the output of the distribution to see how the tags are trending:
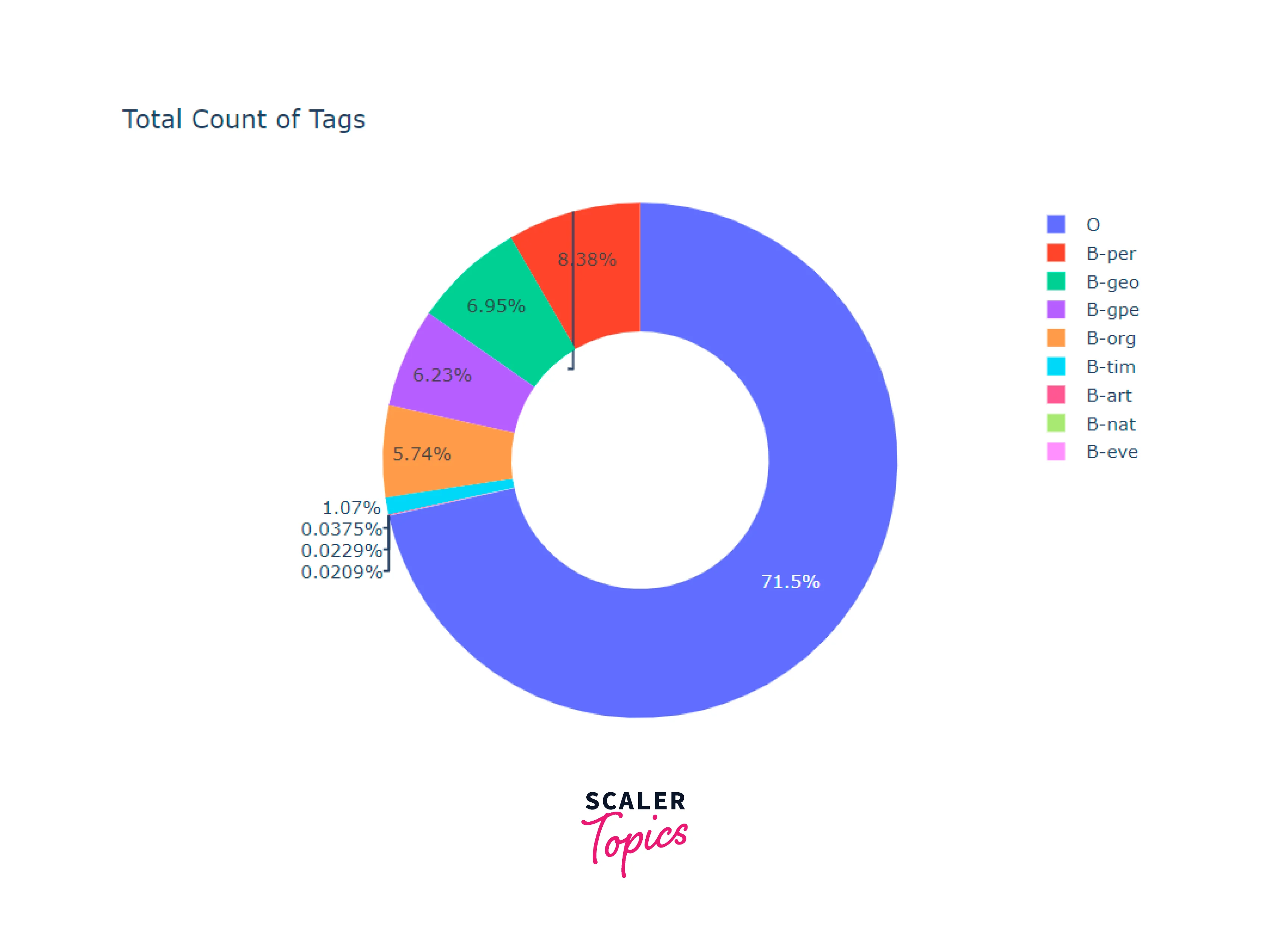
It can be seen that the tag O is the most frequent which contains all the articles, so that are the most occurring in the dataset. Let us also look at the top sample words from each tag ordered by their frequency.
Standardization of the Features
We need to perform some standardization steps like grouping, tokenization, and padding.
- We need to perform grouping at sentence level based on the sentence column so that we can collect the words as a list and send to the label encoder for further processing.
- We will be using a tokenizer based on Bert model. We will use the inbuilt tokenizer from the hugging face library for this.
- BERT model accepts only 512 tokens as input at a time, so we need to specify the associated truncation parameter and this give as True. The add special tokens parameter is just for BERT to add tokens like the start, end, [SEP], and [CLS] tokens.
- We will also do padding which is another operation and is a special form of masking where the masked steps are at the start or the end of a sequence. Padding comes from the need to encode sequence data into contiguous batches in order to make all sequences in a batch fit a given standard length, it is necessary to pad or truncate some sequences.
- Splitting the dataset into train and test sets and applying the tokenization
Build the Model
- We will build a custom deep learning customized on top of pre-trained Bert model for our NER task we have chosen to implement. We will have a couple of input layers, then add a Bert layer on top of this, then a MLP dense layer, and close the network with an output dense layer.
- BERT stands for Bidirectional Encoder Representations and is based on Transformers in which every output element is connected to every input element and the weightings between them are dynamically calculated based upon their connection.
- BERT is also an open-source machine learning framework for natural language processing (NLP) and is designed to help computers understand the meaning of ambiguous language in text by using surrounding text to establish context.
- The BERT framework was pre-trained using text from Wikipedia and can be fine-tuned with question and answer datasets.
- Bert model is based on the concept of masked language modeling which works by inserting a mask token at the desired position where we want to predict the best candidate word that would go in that position. These tokens are processed in the previous step.
- Bert Model for Masked Language Modeling predicts the best word or token in the vocabulary that would replace that word. The logits are the output of the BERT Model before a softmax activation function is applied to the output of BERT.
- We apply a softmax onto the output of BERT to get probabilistic distributions for each of the words in BERT’s vocabulary. The words with a higher probability value will be better candidate replacement words for the mask token.
Output:
Train and Evaluate the Model
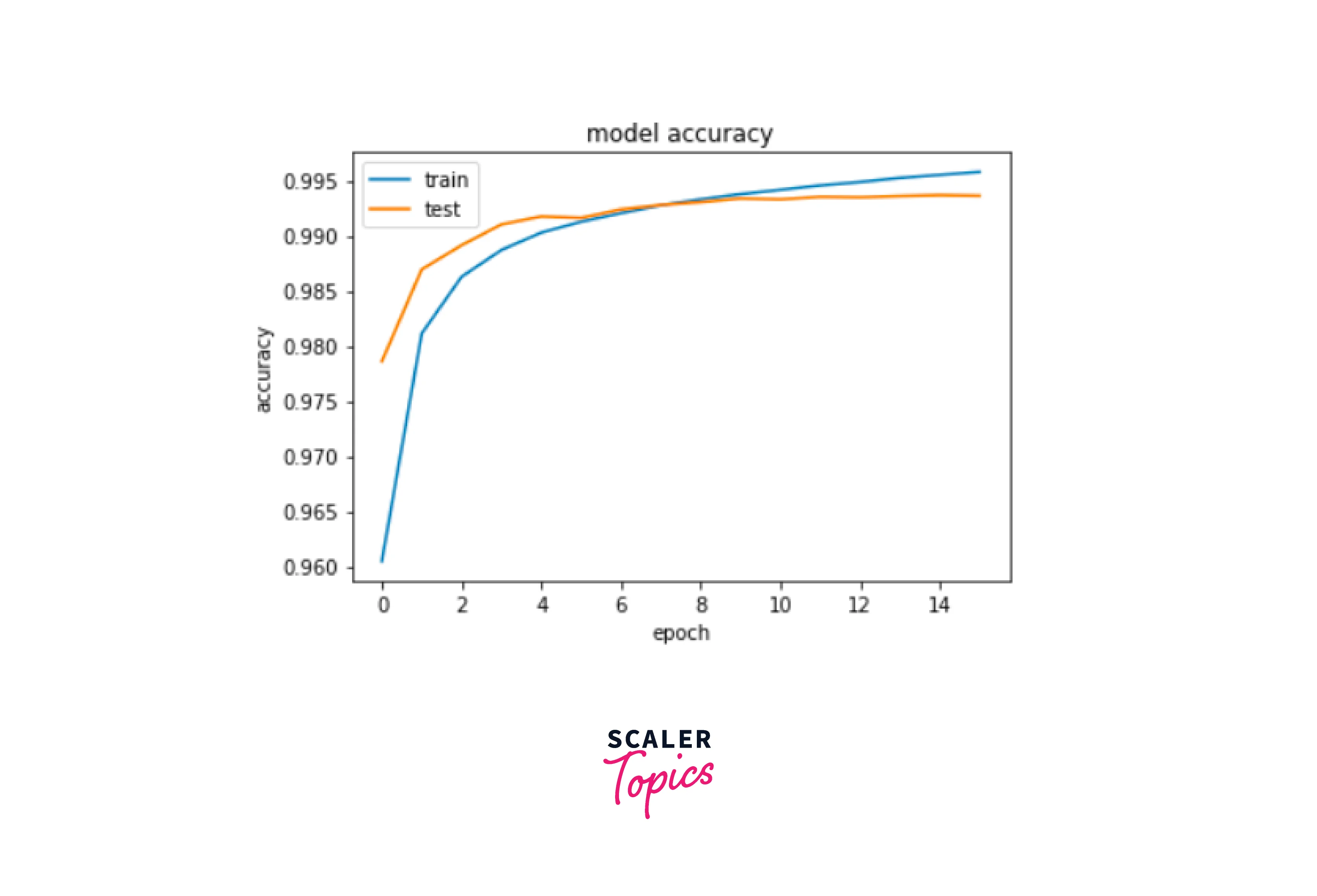
Testing
- The ouput of the above testing code looks like below:
- Original Text :
- Original Tags :
- Predicted Tags :
Conclusion
- NLP module are a set of components or code pieces for different tasks combined of a larger system that is designed to perform one or more NLP use cases.
- NLP modules are used in a wide range of applications like machine translation, chatbots, voice assistants for speech recognition, language translation and text classification systems etc.
- We can either use pre-trained or off the shelf libraries for performing different kind of tasks, the choice of when to use what depends on level of complexity and requirements of the task.
- Out of the box libraries and models provide advantage when one have limited time or do not have much data to train for desired problem statements.
- Building your custom NLP module from scratch gives more control and flexibility over different parts of the project.
- Building custom modules depends on the type of problem being tackled, the business requirements, the data available, and the overall constraints of the development environment.