Advanced Methods for Decoding
Overview
We come across various applications in real life where we get assistance while writing as autocompletion or autosuggestions. Examples could be searches on Google search, writing emails in various email applications, or typing a message in Whatsapp or any other messaging platform, etc. In all these applications, the AI system is trying to assist the writer by generating the next word or phrase while writing. This is possible because of natural language generation techniques. In this article, we are going to discuss one of the techniques called Decoding in detail.
Pre-requisites
- This article requires the reader to have basic knowledge of statistical modeling in machine learning and sequence modeling in NLP.
- An understanding of deep learning architectures such as RNN, LSTM, and Transformers would make this article a comfortable read.
Introduction
Predicting the future is difficult, but how about predicting the next few words someone is going to say? What word, for example, is likely to follow: I am going to sit....
Most probably down. Seems easy? Now let's predict the next word in the following: I am going to.... Will it be sit down or bath or some other task like sleep? It could be different. The person might even I am going to market or I am going to Mumbai. Here's where it gets confusing.
Trying to find the next word or sentence from a given set of words or sentences is called Language Generation. It depends upon the context, which most could be previous words/sentences or next words/sentences. In most of the real use cases, the context is usually past. For example, in Google Search we start typing a query, and it starts predicting the next words or autocompletes our query.
Depending upon the context and number of words to be predicted, the task could be difficult or easy. In our previous example, we were super confused when we got I am going to but as soon as the word sit appeared, it was easy to predict down.
NLG:
A very popular definition of NLG is the one by Reiter and Dale, which states that "Natural Language Generation is concerned with the construction of computer systems that can produce understandable texts in English or other human languages from some underlying non-linguistic representation of information".
In natural language generation, predicting the next word is mathematically expressed by formulating equations or architecture which can assign probabilities to various possible next outcomes. These mathematical equations or architectures, or approaches are called Language Models.
Assigning probabilities to sequences of words is also essential in machine translation. Suppose we are translating a Chinese source sentence:
他 向 记者 介绍了 主要 内容
He to reporters introduced main content
As part of the process, we might have built the following set of potential rough English translations:
He introduced reporters to the main contents of the statement.
He briefed reporters on the main contents of the statement.
He briefed reporters on the main contents of the statement.
A probabilistic model of word sequences could suggest that briefed reporters on are a more probable English phrase than briefed to reporters (which has an awkward to after briefed) or introduced reporters to (which uses a verb that is less fluent English in this context), allowing us to correctly select the boldfaced sentence above.
There are various other approaches have been built which use the models built for generating language called language models, which could be used in text classification or information extraction or visual document understanding. This is one of the most important topics which has got huge attention from academia and industry in terms of research and application both. With that, we have seen many great advancements in recent times.
In recent years, we have seen the prominence of large transformer-based language models such as OpenAI’s GPT3 model, Google's BERT, and then various other architectures like LayoutLM from Microsoft for various other applications.
To generate high-quality output texts from such language models, various decoding methods have been proposed. In this article, we will discuss various decoding strategies: Greedy search, Beam search, Sampling, Top-K sampling, and Top-p (nucleus) sampling.
End-to-End Natural Language Generation Systems
The rise of deep learning techniques in NLP has significantly changed the way natural language generation (NLG) systems are designed, developed, and trained with data. Traditional, rule- or corpus-based NLG systems typically modeled decisions at different levels of linguistics processing explicitly and symbolically. In contrast, recent neural network architectures for generation can be trained to predict words directly from linguistic inputs or non-linguistic data, such as database records or images. For this reason, neural generators are commonly referred to as “end-to-end systems”. The development of a neural architecture for generation involves many steps and aspects, starting from the definition of the task, the collection and preparation of data, the design of the model and its training, and the evaluation.
Language Model
A language model is a probability distribution over sequences of words. Given any sequence of words of length m, a language model assigns a probability P(w1, w2,......) to the whole sequence. Language models generate probabilities by training on text corpora in one or many languages.
Decoding
Neural network architecture for language generation can be trained to predict the words, but they are restricted to modeling word probability distributions, whereas the generation of output sequence is not handled by the model itself. With all these probabilities, it might seem a good approach to select the word with the highest probability. This approach is called the Greedy approach, which has its pros and cons. Thus, Natural Language Generation system generally needs an additional decoding strategy that defines how words are stitched together to form sentences and texts.
In a neural NLG system, the decoding method defines the way the system handles its search space over potential output utterances when generating a sequence. Generally, in neural language generation, this search space is infinite, i.e., it grows exponentially with the length of the output sequence. Therefore, the decoding procedure is an important part of the neural NLG pipeline where non-trivial design decisions are taken by the developer of the NLG system.
Formally put, Decoding is the process of generating a sequence or selecting words to be generated next based on a search space created by those probability distributions.
Decoding Strategies
Decoding can be broadly categorized into two categories:
Search:
Decoding is most commonly viewed as a search problem, where the task is to find the most likely utterance y for a given input x:
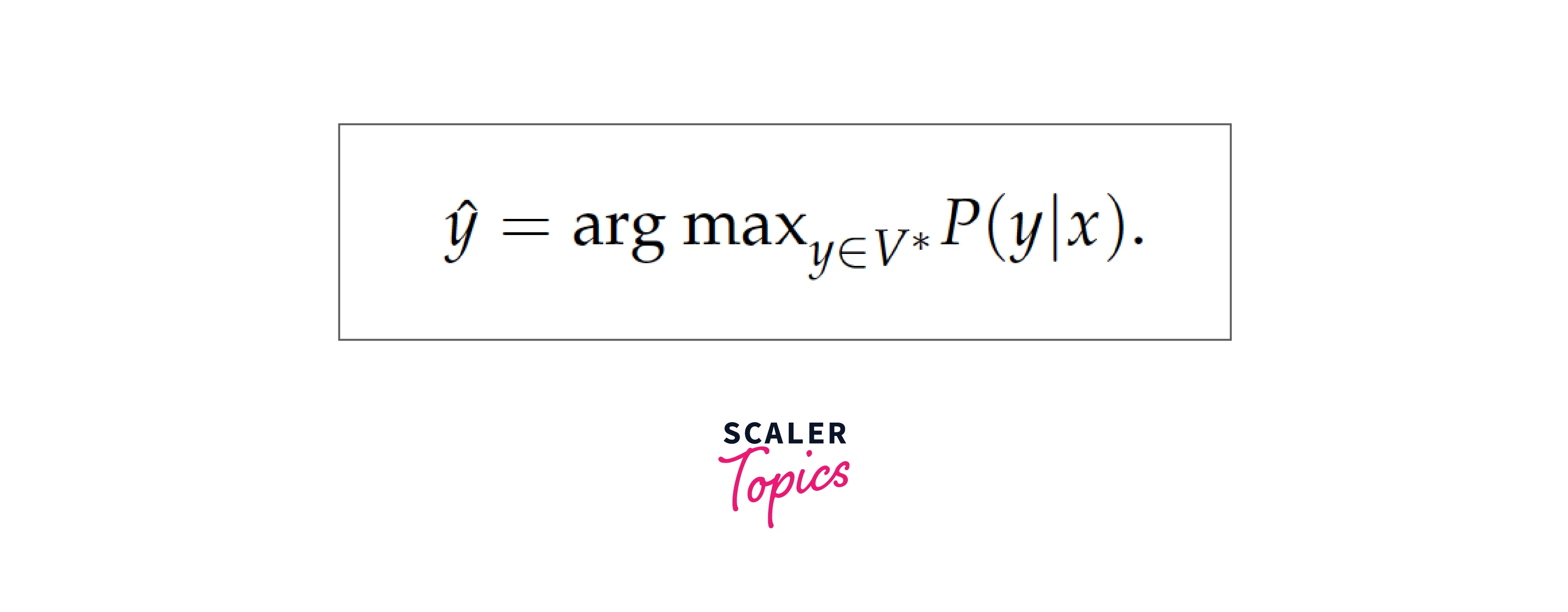
Simply put, considering all the possible words and their probabilities. Creating a search space with words as nodes, the edge between node to and node sit with weight as the probability of sit occurring after I am going to in the sequence i.e. P(sit|I am going to).
Seaech-based strategies are often limited to generating repetitive sentences and getting stuck in the loop.
Diversity:
Alternate approaches which have been defined to break the repetition are based on diversity. One of the ways to do so is by sampling. Sampling means randomly picking the next word according to the conditional word probability distribution extracted from the language model. As a consequence, with this decoding method, text generation is not deterministic.
Search Strategies
Greedy Search
Greedy search selects from the language model the word with the highest probability as the next word. Suppose the language model is predicting a possible continuation to a sentence with “I am going to..”, choosing from the words “sit” and “bath” with their associated probabilities 0.6 and 0.4 respectively. The greedy approach will select the next word as “sit”.
It would seem that this is entirely logical — and in many cases, it works perfectly well. However, for longer sequences, this can cause some problems where we can get stuck in a repeating loop of the same words. The major drawback of greedy search is that it’s not optimal in producing high-probability sentences, as it focuses on maximizing the probability of one word than a complete sequence.
Beam Search
The most well-known and de-facto standard decoding procedure in NLG is beam search, a general and traditional search algorithm that dates back to Lowerre’s work on speech recognition. Beam search is designed to maximize the likelihood of the generated sequence. Being the likelihood-based approach, bean search is a task-independent approach.
Beam search allows us to explore multiple levels of our output before selecting the best option. So whereas greedy decoding and random sampling calculate the best option based on the very next word/token only — the beam search checks for multiple words/tokens in the future and assesses the quality of all of these tokens combined.
From this search, we will return multiple potential output sequences — the number of options we consider is the number of ‘beams’ we search with.
Sampling Strategies
Random Sampling
Using directly the probabilities extracted from the language models often leads to incoherent text. A trick is to make the probability distribution sharper (as in increasing the likelihood of high-probability words and decreasing the likelihood of low-probability words) by applying a softmax over the probability distribution and varying its temperature parameter to make it sharper or smoother. With this trick, the output is generally more coherent.
Top-K Sampling
In Top-K sampling, the K most likely next words are filtered, and then the next predicted word will be sampled among these K words only.
The produced text is often more human-sounding than the text produced with the other methods seen so far. One concern, though, with Top-K sampling is that it does not dynamically adapt the number of words that are filtered from the next word probability distribution, as K is fixed. As a consequence, very unlikely words may be selected among these K words if the next word probability distribution is very sharp.
As a consequence, Top-p sampling has been created.
Top-p Sampling
Top-p sampling (or nucleus sampling) chooses from the smallest possible set of words whose cumulative probability exceeds the probability p. This way, the number of words in the set can dynamically increase and decrease according to the next word probability distribution.
While Top-p sampling seems more elegant than Top-K sampling, both methods work well in practice.
Conclusion
- Language models are restricted to modeling word probability distributions, whereas the generation of the output sequence is not handled by the model itself.
- Natural Language Generation systems generally need an additional decoding strategy that defines how words are stitched together to form sentences and texts.
- Decoding can be broadly categorized into search and diversity based strategies.
- Search-based strategies can be repetitive, which is taken care of by diversity-based approaches like sampling.