How to Extract Information from Text in NLP?
Overview
In Natural Language Processing (NLP) or Natural Language Understanding (NLU), Information extraction is the technique to locate and extract relevant and important information from the structured text.
Introduction
Imagine working in an insurance firm that is planning to launch insurance plans for pets, and you’re doing market research for the same and going through a lot of market reports to understand the consumer’s expectations and market fit. It’s very hard to read each report in detail. You might be interested in some specific piece of information that can be extracted from this huge textual data that would make your life easy. For example, from this excerpt, you’re interested in some information like: “India is the largest growing pet market in the world. 85% of the total pet market in India is dominated by dogs alone, with 3 crores pet dogs in the country. The pet care market is approximately Rs 400 crore in size and is expected to grow at ~14% a year. This spells the potential for dog health insurance in India.”
- 85% of pets are the dogs
- Market size: Rs. 400 crores
- Expected growth: 14%
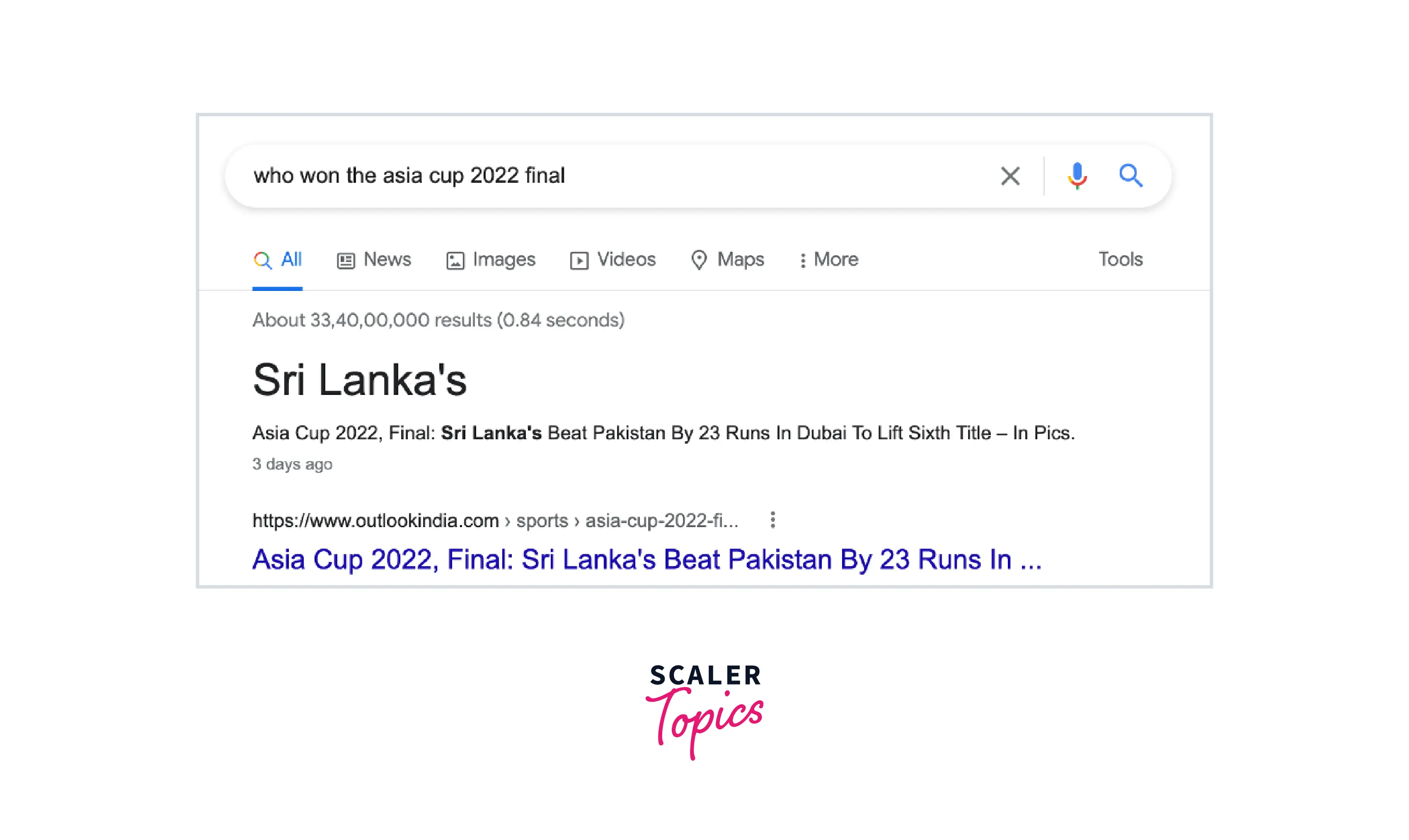
Even in daily life, maybe you have a specific question that needs to be answered like ‘who won the Asia Cup 2022 final’ and information ‘Sri Lanka’ is extracted as the answer from a news article.
With the rise of the internet, Web 2.0, and digitization, a lot of information is being generated at high speed in terms of news articles, social media, blogs, online learning content, etc. Many a time, the need comes when a human being or a system that is being built wants some specific information. The task of locating and extracting such knowledge from the text is called Information Extraction.
Formally put:
Extracting relevant information in a structured way from an unstructured text is called Information Extraction or IE.
There is various type of information extraction. We will talk quickly about a few important of them here:
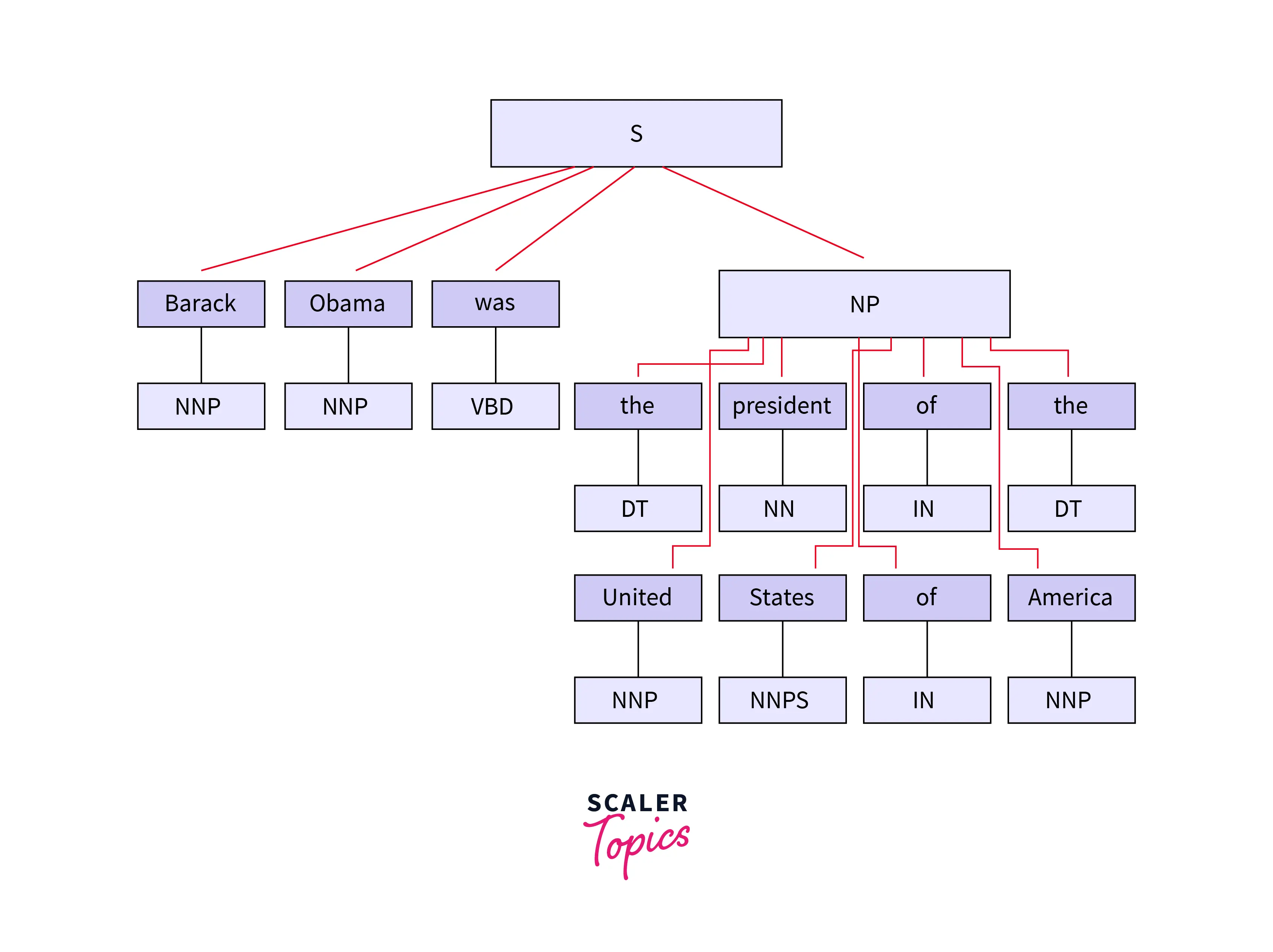
Named Entity Recognition Extracting the entities from text which can be referred to with a proper name. In this example, Barack Obama is the name of a person, and the United States of America is a country.
Barack Obama was the president of the United States of America.
Relation Extraction Extracting the relation between entities. In the above example, Barack Obama is related to the United States of America as president.
Barack Obama was the president of the United States of America.
Introduction to Chunking and Chinking
Chunking is the process of converting texts into chunks called phrases. The words which can’t be part of chunks are called chinks. A rule can be defined to identify what to consider for the chunk. These rules are the regular expressions built on top of part of speech.
For example, we can use a regex to extract the president of the United States of America as a Noun Phrase (NP) or chunk.
Barack Obama was the president of the United States of America.
Now coming to Chinking. Chinking is similar to chunking in the sense that chinking essentially is the process used to remove a chunk from a chunk. The chunk that you end up removing from your chunk is called the - chink. The way we used RegEx to extract chunks, we can use it to also extract chinks.
What is Word Embeddings?
Since almost all machine learning algorithms work on mathematical equations containing variables that need information represented as numbers. Before applying any kind of machine learning algorithm for information extraction, these words need to be converted to a numerical representation like an array of numbers. This array of numbers is called embedding or vector representation of a word. Each word is mapped to a vector something like:
barack = [1, 0, 0, 0, 0]
obama = [0, 1, 0, 0, 0]
was = [0, 0, 1, 0, 0]
the = [0, 0, 0, 1, 0]
president = [0, 0, 0, 0, 1]
In recent times, the two most popular techniques of generating word embeddings are 1. word2vec and 2. GloVe
What is Word2vec?
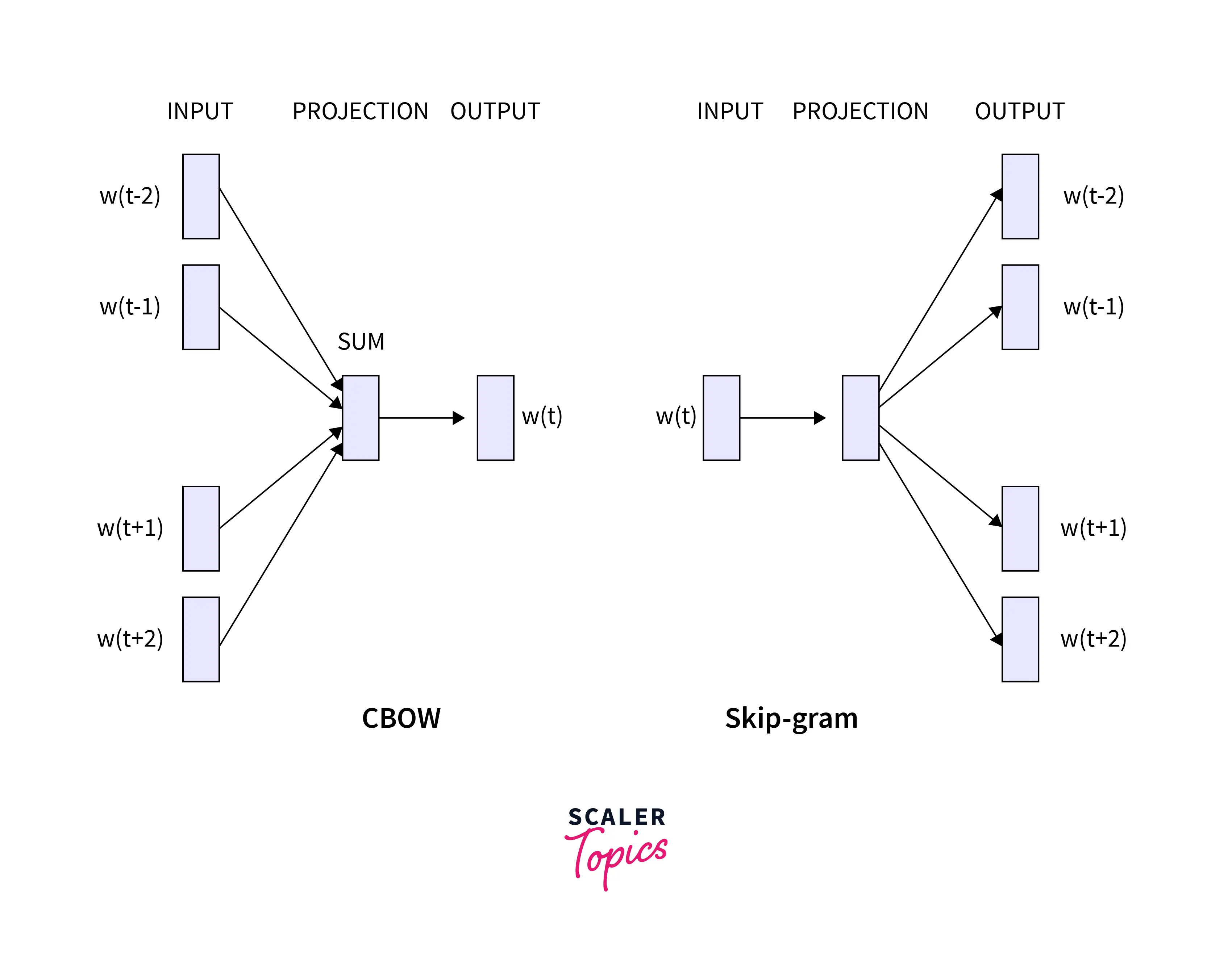
Word2Vec is an idea presented by Tomas Mikolov et al from Google where word representation or embeddings can be learned from neighbors. Neighbors provide information about the usage of the word. Word2vec works on the idea of learning from the surrounding words in a window of words. This can be done in two ways:
- Skip-gram
- Continuous bag of words (CBOW)
Skip-gram and CBOW
The main difference between Skip-gram and CBOW is the way they learn and predict words. Skip-gram learns the word representation by predicting the neighbors from the word, and CBOW by predicting the word from the neighbors.
GloVe
Global Vectors (GloVe) is a similar technique to learn word embeddings, developed by The NLP lab at Stanford University. The model is unsupervised learning to learn word representations by global word-word co-occurrence statistics and local context windows.
The key advantage of GloVe over Word2Vec and Word Embedding values is that GloVe computes the local word values on the large global data that Stanford University has trained them on, which results in considerably higher accuracy, even if our words are few. The glove has utilized the benefit of the local semantics of the text under study as well as the worldwide use of the word from the Stanford research.
It is based on the concept of the link between words. For instance, the close and distant relationship between south, north, east, and west, or the relationship between father, mother, brother, sister, or any combination of terms. The glove is now utilized to obtain the relationship between semantics such as synonyms, antonyms, equipment relationships, comparatives, superlatives, cities and nations, and so on.
The GloVe model is trained using non-zero inputs from a global word-word co-occurrence matrix, which tracks how frequently words co-occur in a particular corpus. To populate this matrix, the statistics must be collected in a single pass through the full corpus. This pass can be computationally expensive for large corporations, but it is a one-time expense. Because the number of non-zero matrix entries is often substantially fewer than the total number of words in the corpus, subsequent training iterations are much faster.
Morphology of Words
Words are not atoms which means they can be split into multiple meaningful parts. Words have internal structures and they are composed of what we call morphemes. Morphemes are minimal meaningful components of words.
Misunderstandings -> mis-understand-ing-s going -> go-ing
Understand and go are called the root or base words. Many times to reduce the vocabulary size and learn the word embeddings effectively the words are converted back to root form using lemmatization and stemming.
Parts-of-speech of Words in a Sentence
Part of speech tagging is the process of assigning part of speech to each word in the text.
| Barack | Obama | was | the | president |
|---|---|---|---|---|
| NOUN | NOUN | VERB | DET | NOUN |
The input is a sequence of words x1, x2, x3,.., xn and the output is sequence of part of speech tags y1, y2, y3,.., yn.
We can’t assign a tag directly based on the word because:
- There could be n number of words in any vocabulary which keeps updating.
- Based on the context tag for the same word might change. For example, the book can be a noun (I bought a book) or a verb (I will book a cab) based on the context.
To assign a tag, we need to learn the context of the word, which is a sequence of words around it. Many sequence learning algorithms can be used to train models like Hidden Markov Model or HMM, Conditional Random Fields, and deep learning-based models like BiLSTM with CRF, etc.
We can use any package like nltk or spacy to generate.
Let’s use nltk to generate pos tags.
- Install ntlk
- Download the pos tagger
- Tokenize the input text
- Generate pos tags
- Install svgling to visualize the chunks
- Run the chunker
Conclusion
- Information extraction is a technique to extract relevant information from text.
- Named Entity Recognition and relation extraction are examples of information extraction.
- Information extraction can be used in generating summaries as well.
- Words need to be converted into numerical forms called word embeddings.
- We discussed the deep learning-based embedding techniques word2vec and GloVe briefly.
- Finally, a code example for assigning the part of speech and extracting chunks from a text using nltk.