fine-tuning BERT for downstream tasks
Overview
Fine-tuning BERT for downstream tasks is a common technique to improve the performance of natural language processing (NLP) models on specific tasks. BERT, which stands for Bidirectional Encoder Representations from Transformers, is a powerful language representation model developed by Google. We can fine-tune it on various NLP tasks, such as text classification, named entity recognition, and question answering.
Pre-requistes
- To fine-tune a BERT model using the hugging face library, you will need the following: Install the hugging face library: You can install the hugging face library by using the following command:
- A pre-trained BERT model: You can use a pre-trained BERT model such as bert-base-uncased or bert-large-uncased as the starting point for your model. These models have been trained on a large corpus of text data and can be fine-tuned for various NLP tasks.
- Training data: You will need a dataset of labeled examples to train the model. This dataset should be in the form of input sequences and corresponding labels.
- Validation data: It is a good idea to hold out a portion of the training data as a validation set to evaluate the model's performance during training and fine-tune the hyperparameters as needed.
- A classification head: Depending on the task, you may need to add a classification head to the BERT model to map the model's output to the desired number of classes. You can do this by adding a fully-connected (FC) layer with the appropriate output units and using a softmax activation function.
- A suitable optimizer and loss function: You must choose an optimizer and loss function appropriate for the task and the model's architecture. Common choices include the Adam optimizer and the cross-entropy loss function.
- Hyperparameters: You will need to specify some hyperparameters, such as the learning rate, batch size, and the number of epochs for training the model. You can fine-tune these hyperparameters based on the model's performance on the validation set.
Introduction
Fine-tuning BERT involves using the pre-trained BERT model and adapting it to a specific task by adding a layer on top of the pre-trained model and training this additional layer on the target task. This process allows the model to learn task-specific information from the training data while leveraging the pre-trained BERT model's knowledge of general language representation.
Fine-tuning BERT can be done using the hugging face transformers library in Python. This library provides pre-trained BERT models and utilities for fine-tuning specific tasks. To fine-tune BERT, you will need to define your training data, including the input text and the corresponding labels, and then use the fit() method provided by the BertForSequenceClassification class to fine-tune the pre-trained BERT model on your data.
What Exactly Happens When We Fine-Tune BERT?
When we fine-tune BERT, we adopt the pre-trained BERT model to a specific downstream task by training a new layer on top of the pre-trained model on the target task's training data. That allows the model to learn task-specific information and improve its performance on the target task.
Here are the main steps involved in fine-tuning BERT:
STEP 1: Load the pre-trained BERT model and tokenizer using the hugging face transformers library.
STEP 2: Define the training data for the target task, including the input text and the corresponding labels.
STEP 3: Tokenize the input text using the BERT tokenizer.
STEP 4: Set the model to train mode.
STEP 5: Fine-tune the pre-trained BERT model on the target task's training data using the fit() method provided by the BertForSequenceClassification class. Thus, training a new layer on top of the pre-trained BERT model on the target task's training data.
STEP 6: Evaluate the performance of the fine-tuned BERT model on the target task.
These are the main steps involved in fine-tuning BERT for a downstream task. You can use this as a starting point and modify it as needed for your specific use case.
Fine-tuning BERT allows the model to learn task-specific information and improve its performance on the target task. Especially useful when the target task has a relatively small dataset, as fine-tuning the small dataset can help the model learn task-specific information that it might not be able to learn from the pre-trained BERT model alone.
Which layers change during fine-tuning?
During fine-tuning, only the weights of the additional layer added to the pre-trained BERT model are updated. The weights of the pre-trained BERT model are kept fixed, so only the added layer is changed during fine-tuning.
The added layer is typically a classification layer, which takes the output of the pre-trained BERT model and outputs the logits (unnormalized probabilities) for each class in the target task. The added layer is trained on the target task's training data to learn task-specific information and improve the model's performance on the target task.
In summary, only the added layer on top of the pre-trained BERT model is changed during fine-tuning. The weights of the pre-trained BERT model are kept fixed, so only the added layer is updated during training.
Downstream Tasks
Downstream tasks are natural language processing (NLP) tasks that can be performed using a pre-trained language representation model`, such as BERT. Some examples of downstream tasks include text classification, natural language inference, named entity recognition, and question answering.
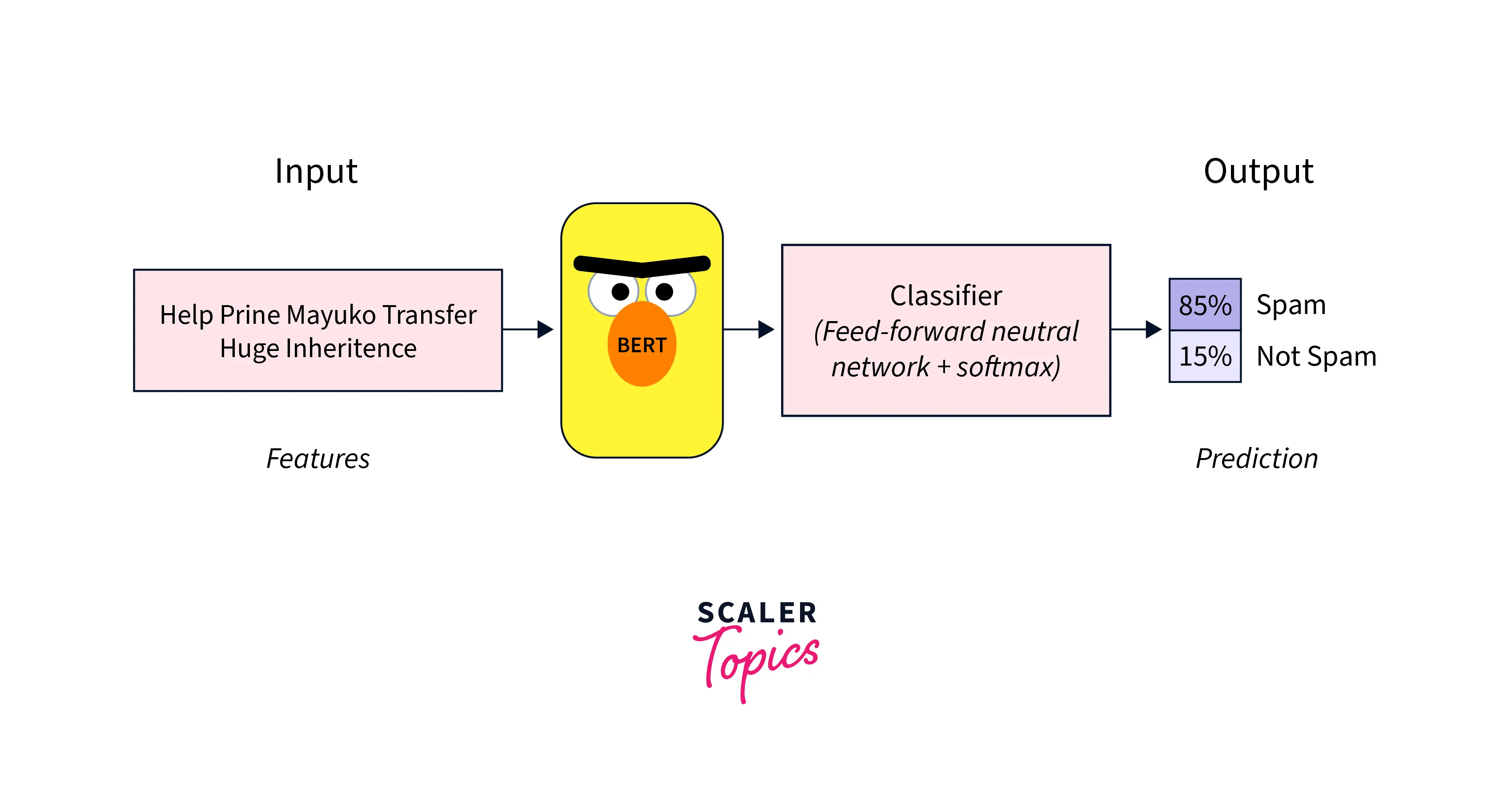
Text Classification
Text classification is the task of assigning a text to one or more predefined categories or labels. For example, we could train a text classification model to classify movie reviews as positive or negative.
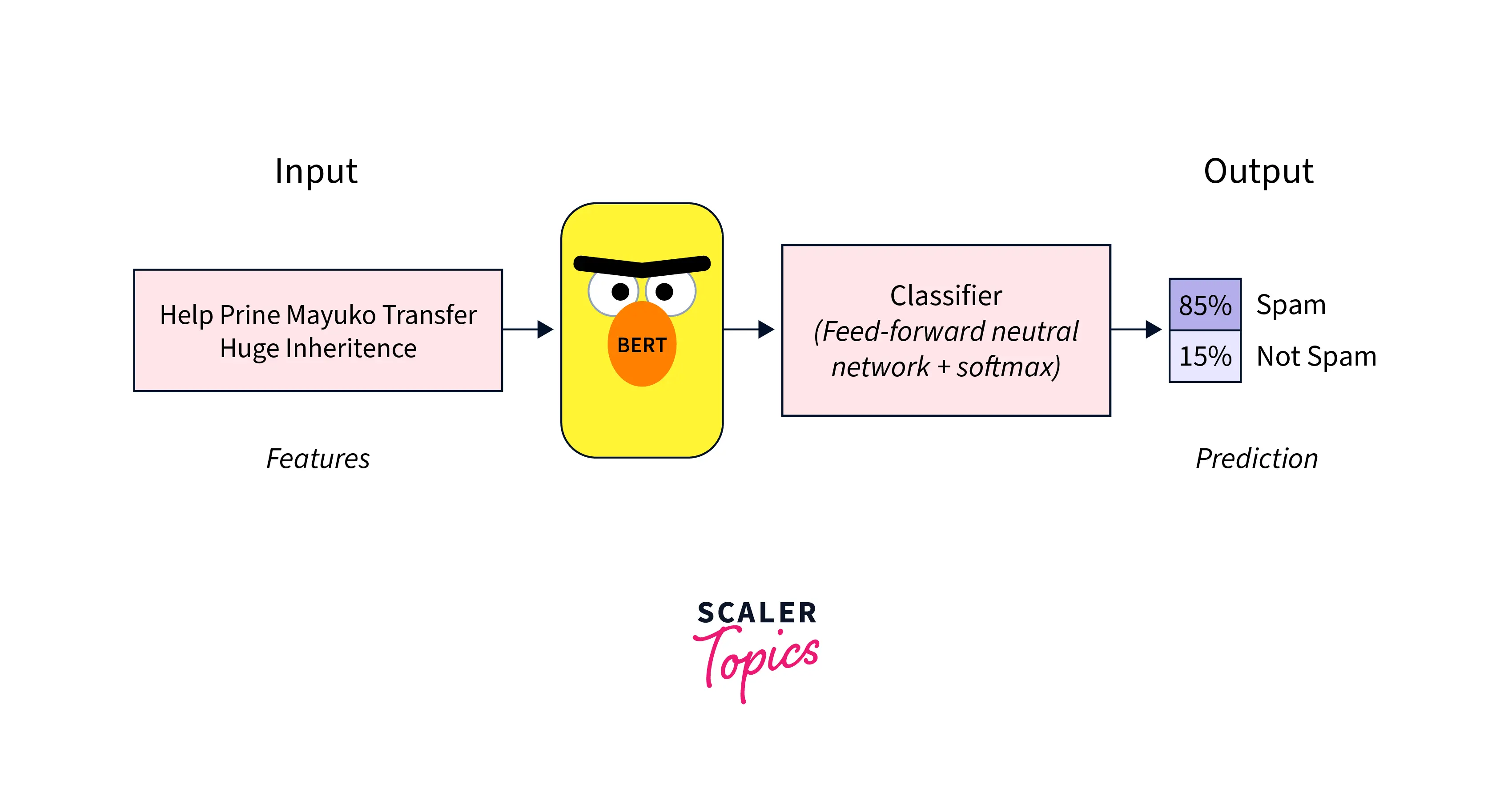
To fine-tune BERT for text classification, you can use the BertForSequenceClassification class provided by the hugging face transformers library. This class takes input data, such as sentences or paragraphs, and outputs each class's logits (unnormalized probabilities).
Natural Language Inference
Natural language inference, also known as recognizing textual entailment (RTE), determines whether a given premise text entails, contradicts, or is neutral for a given hypothesis text. For example, given the premise "The cat is on the mat" and the hypothesis "The cat is on the bed," a natural language inference model would output "contradiction."
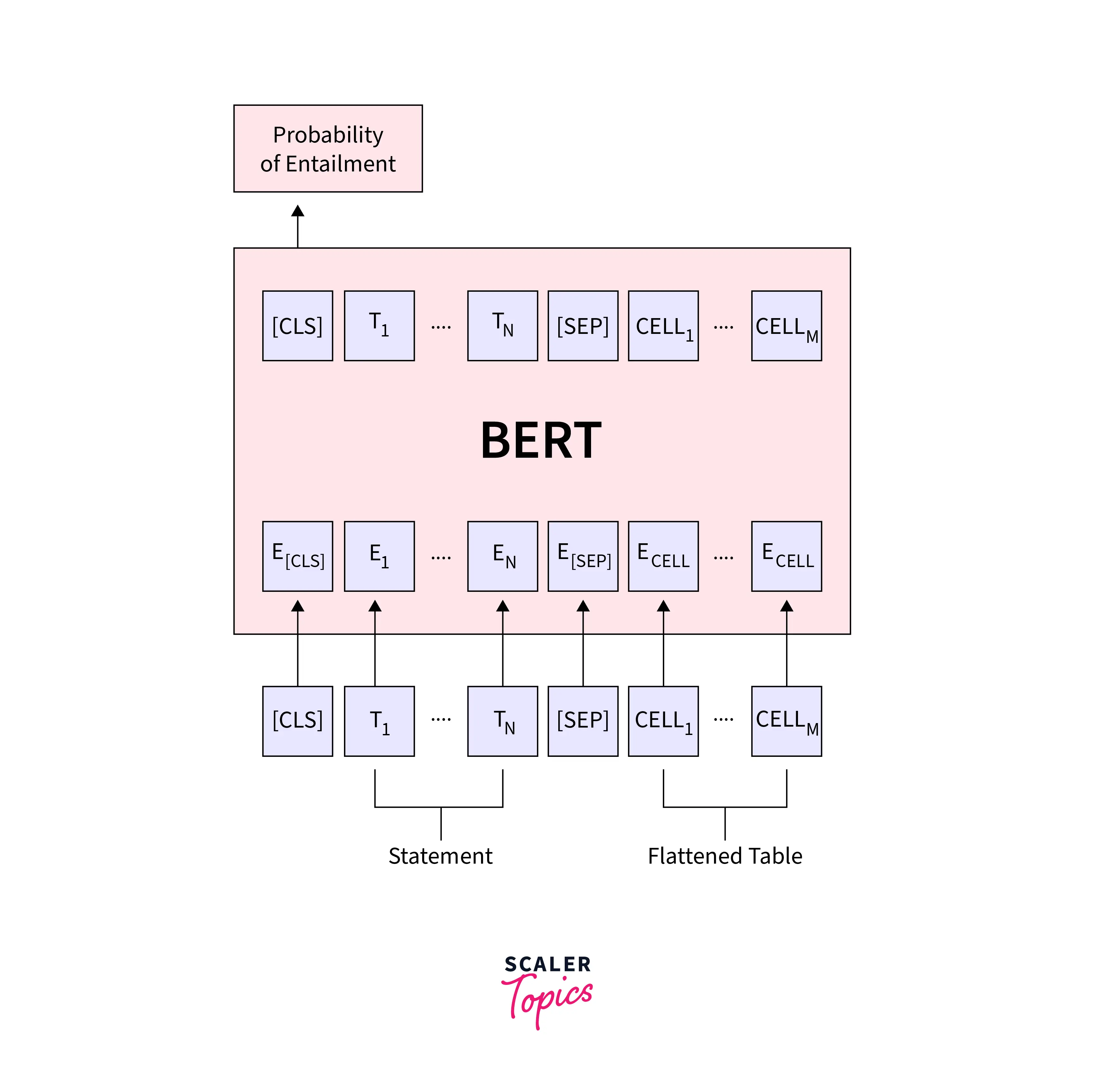
To fine-tune BERT for natural language inference, you can use the BertForSequenceClassification class that takes in a pair of premise and hypothesis texts and outputs the logits (unnormalized probabilities) for each of the three classes (entailment, contradiction, and neutral).
Named Entity Recognition
Named entity recognition identifies and classifies named entities in a text, such as people, organizations, and locations. For example, given the sentence "Barack Obama was the 44th President of the United States," a named entity recognition model would identify "Barack Obama" as a person and "the 44th President of the United States" as a title.
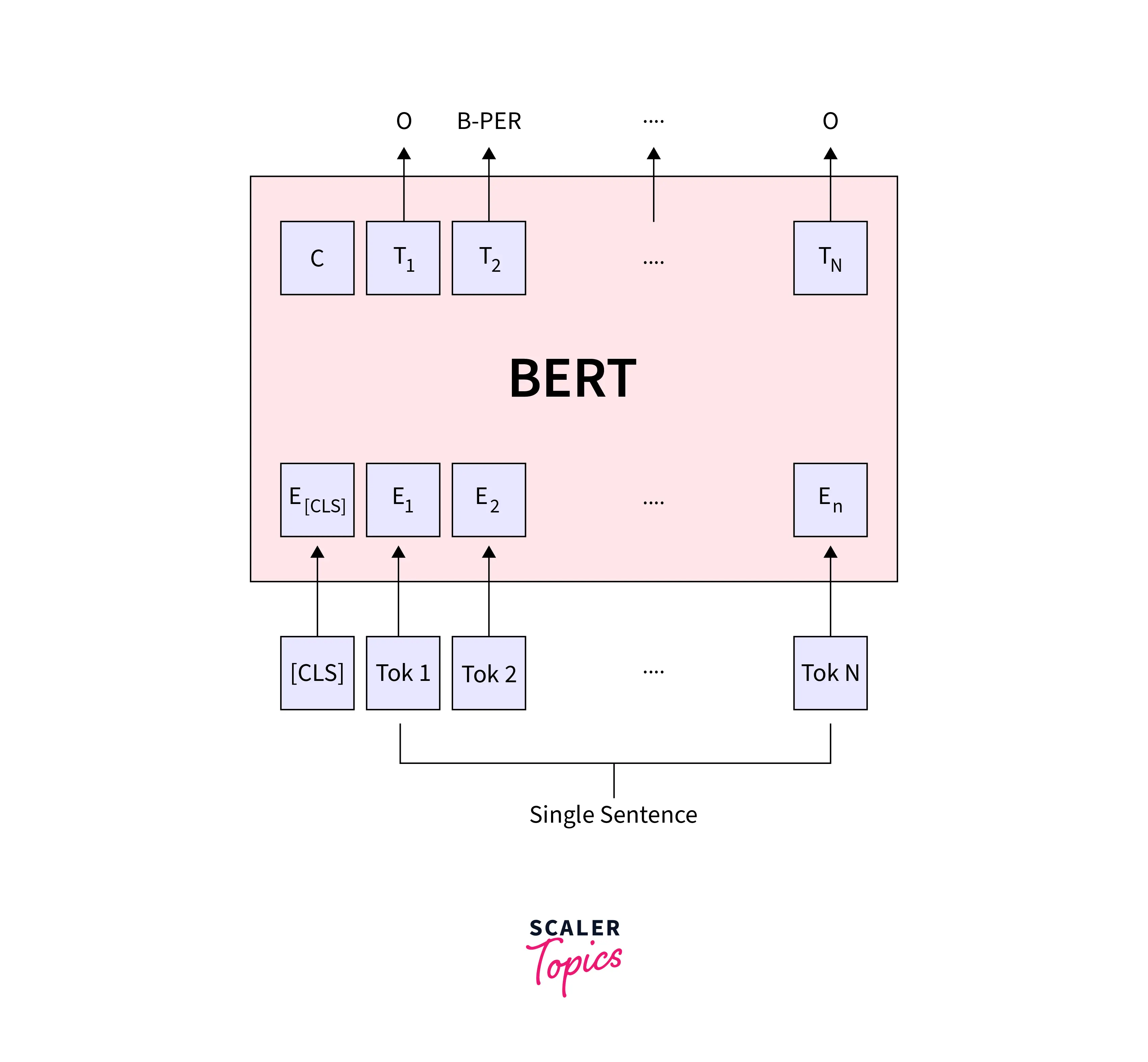
To fine-tune BERT for named entity recognition, you can use the BertForTokenClassification class provided by the hugging face transformers library. This class takes in the input text and outputs the logit for each token in the input text, indicating the class of the token (e.g., person, organization, location, etc.).
Question-Answering
Question answering generates a natural language answer to a given question based on a given context. For example, given the context "The capital of France is Paris" and the question "What is the capital of France?", a question-answering model would output "Paris" as the answer.
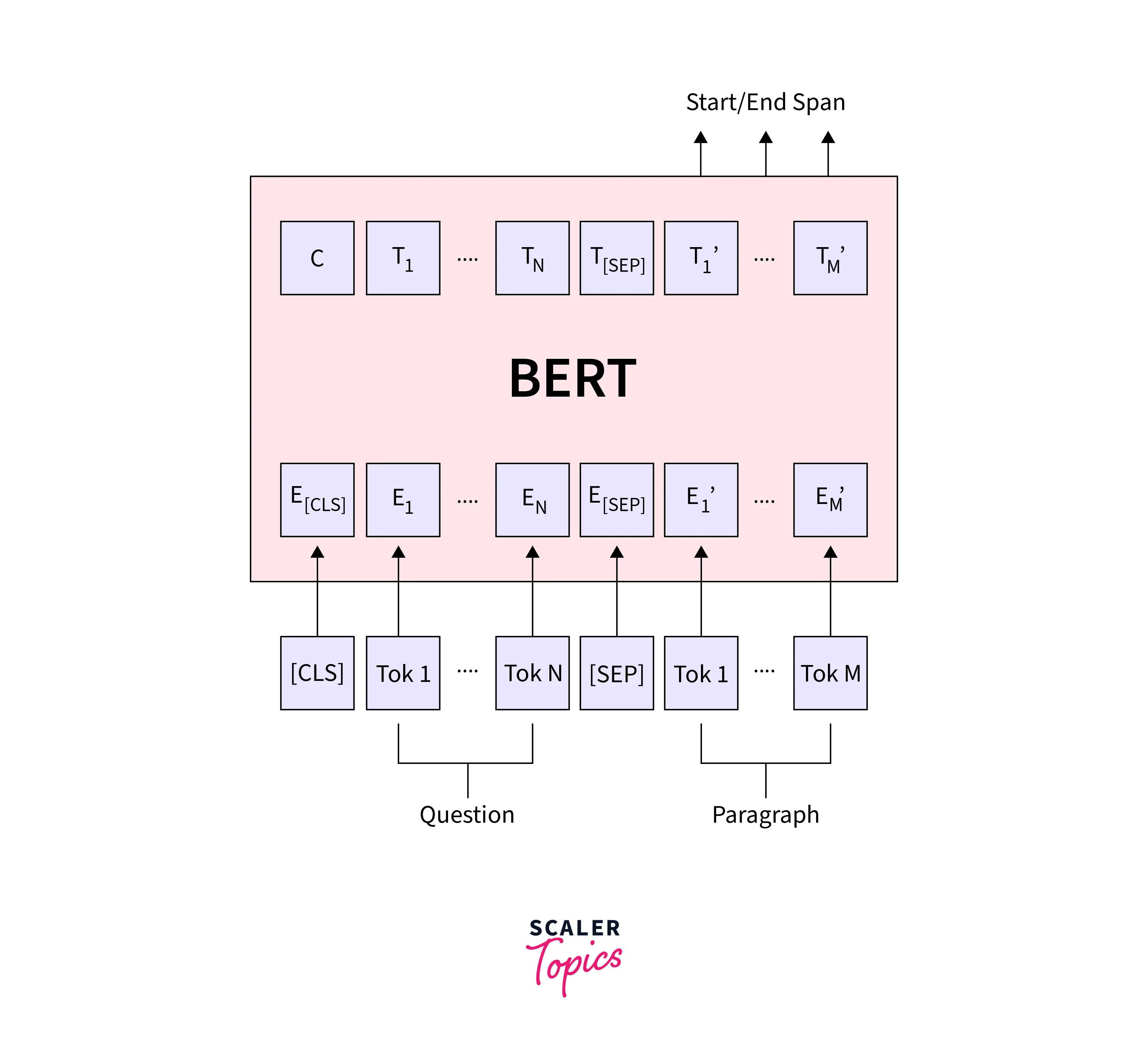
To fine-tune BERT for question answering, the BertForQuestionAnswering class takes in a context and a question and outputs the start and end indices of the answer in the context.
Researchers are constantly finding new ways to apply BERT and other language representation models to various NLP tasks. These are just a few examples of downstream tasks that can be performed using a pre-trained language representation model like BERT. Many other NLP tasks can be tackled using fine-tuned BERT models.
Conclusion
- In conclusion, fine-tuning BERT for downstream tasks is a common technique to improve the performance of natural language processing (NLP) models on specific tasks.
- Fine-tuning involves adapting the pre-trained BERT model to a specific task by training a new layer on top of the pre-trained model on the target task's training data. This allows the model to learn task-specific information and improve its performance on the target task.
- Overall, fine-tuning BERT can be a powerful technique for improving the performance of NLP models on specific tasks.
- It allows the model to leverage the pre-trained BERT model's knowledge of general language representation while learning task-specific information from the target task's training data.