Extracting embeddings from pre-trained BERT| Huggingface Transformers
Overview
The need for standardization in training models and using the language model, Hugging Face, was found.NLP is democratized by Hugging Face, where the constructed API allows easy access to pre-trained models, datasets, and tokens. This Hugging Face's transformers library generates embeddings, and we use the pre-trained BERT model to extract the embeddings.
Introduction
Transformers were designed as a model to translate one language to another, a solution to readily re-use these pre-trained transformers for different tasks is the BERT model. BERT(Bidirectional Encoder Representations from Transformers) revolutionized the NLP research and was defined as the extension of the encoder part of the transformer. BERT model stands for handling language problems that are 'context heavy' by mapping vectors onto words post by reading the entire sentence. Hugging Face transformers library generates embeddings and launches the BERT model.
What are Pipelines in Transformers?
Pipelines are the abstraction for the complex code behind the transformers library, providing an easy way to use models for inference and also offering a simple API dedicated to several tasks such as Masked Language Modeling, Sentiment Analysis, Feature Extraction and Question Answering etc.
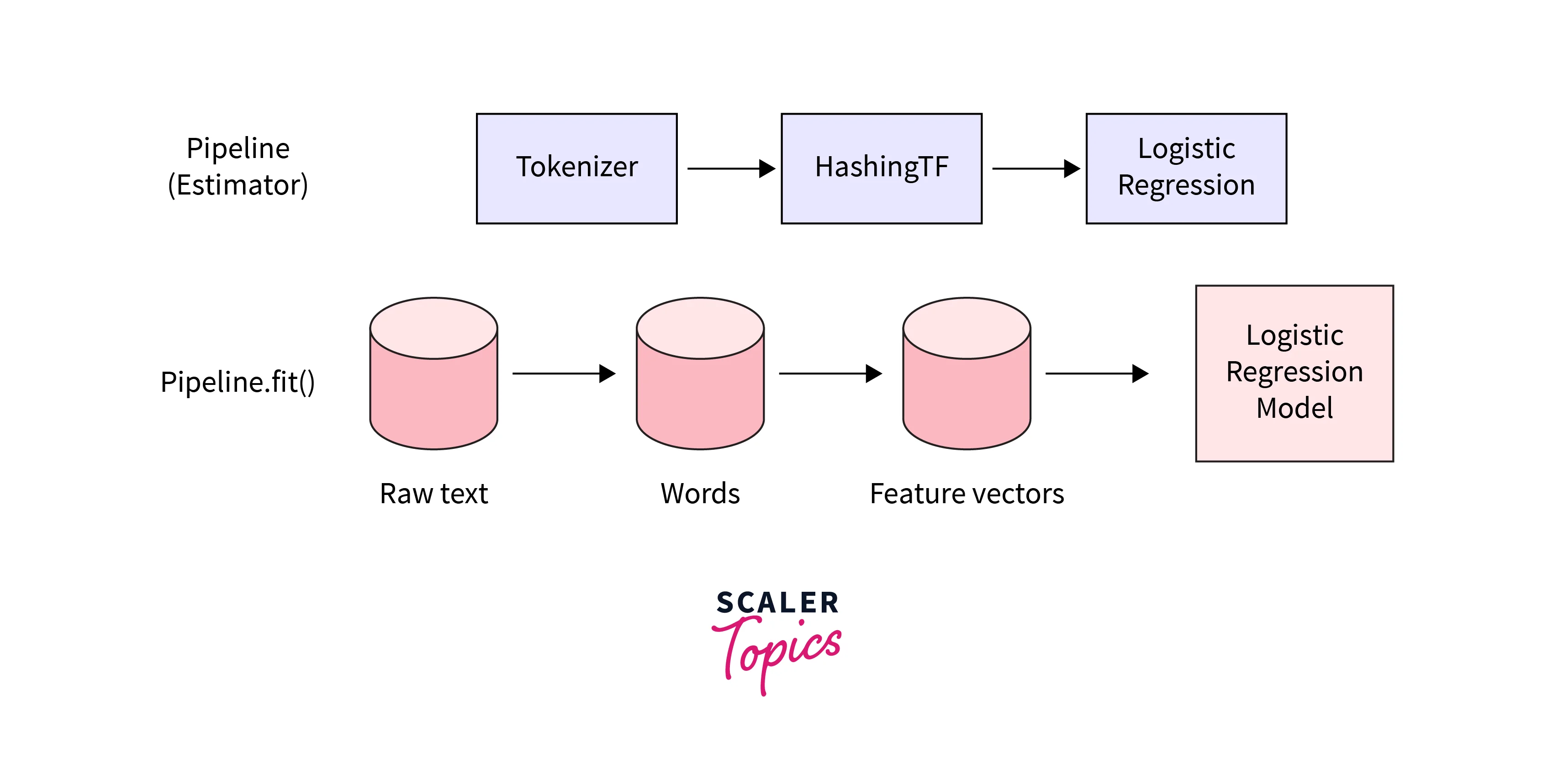
Pipelines are built-in with a tokenizer(mapping raw textual input to the token), a model(to make predictions from the inputs), and other pre-processing for enhancing the model's performance.
Why the Need for Hugging Face Transformers?
Transformer models are usually very large. Training and deploying these models with billions of parameters is a complicated undertaking. Thus, the goal of Hugging Face transformers is to provide a single API through which any Transformer model can be loaded, trained, and saved. Hugging Face transformers also provide flexibility to use a different framework at each stage of a model’s life; train a model in three lines of code in one framework, and load it for inference in another.
Advanced Features
- Easy-to-use state-of-the-art models: High performance on Natural Language Understanding(NLU) & Generation(NLG), Computer Vision, and audio tasks.
- Lower compute costs, smaller carbon footprint: Researchers can share trained models instead of retraining.
- Choose the proper framework for every part of a model’s lifetime: Train state-of-the-art models in 3 lines of code, and pick the appropriate framework for training, evaluation, and production.
- Easily customize a model to our needs: It provides examples for each architecture to reproduce the results published by its original authors.
Hugging Face Tutorial
The below tutorial will tutor you through the fundamentals of working with datasets. The main goal of the HuggingFace transformers is to provide an easy way to load datasets of any format or type.
About the Datasets
The bigger dataset, the better the results. The Hugging Face Dataset library provides an API to quickly download many public datasets and preprocess them. With the load_dataset function, you can directly download and cache a dataset from its identifier on the Dataset Hub. The object returned by the load_dataset function is a DatasetDict, which is a sort of dictionary containing each split of our dataset. Each split by indexing with its name can be accessed.
The amazing thing about the Hugging Face Datasets library is that everything is saved to disk using Apache arrow, which means that even if your dataset is huge, we won't get out of RAM.
The features attribute of a Dataset gives us more information about its columns. We can just remove the columns we don't need anymore with the remove_columns method, rename labels to labels(since the models from Hugging Face Transformers expect that and set the output format to our desired backend: torch, tensorflow or numpy.
Language Translation
The translation is a sequence-to-sequence task, which means it’s a problem that can be formulated as going from one sequence to another. We can train a new translation model from scratch if we have a big enough corpus of texts in two (or more) languages. We will fine-tune a Marian model pre-trained to translate from English to French on the KDE4 dataset.The model we will use has been trained on a large corpus of French and English texts taken from the Opus dataset, which contains the KDE4 dataset. We can get a better version of the pre-trained model after fine-tuning.
Zero-Shot Classification
NLI-based zero-shot classification pipeline using a ModelForSequenceClassification trained on NLI (Natural language inference) tasks. The equivalent of text-classification pipelines, but these models don’t require a hard-coded number of potential classes. They can be chosen at runtime. It usually means it’s slower, but it is much more flexible. This powerful approach makes it possible to predict the target of a text in about 15 languages without having seen any of the candidate labels. We can use this model by simply loading it from the hub.

Sentiment Analysis
We represent a pipeline by calling the pipeline() function in Hugging Face Transformers. The hugging face Transformers pipeline module does proper training of the model for sentiment classification and makes it easy to run sentiment analysis predictions with a specific available model in the hub.
- Load the corresponding model as per the task chosen, and here we load distilled BERT base model for sentiment classification
Thus the model is ready for the respective task to be performed.
This model analyses the sentiment behind the texts or sentences as input.
Question Answering
From the given text, the question-answering model can retrieve the answer to a question. This can be used in finding answers from any kind of documentation. This model can generate answers without context.
QA models and the Hugging Face Transformers library are inferred using the question-answering pipeline.
If no model checkpoint is given, the pipeline will be initialized with distilbert-base-cased-distilled-squad. This pipeline takes a question and a context from which the answer will be extracted and returned.
BERT Word Embeddings
To generate word embeddings using BERT, you first need to tokenize the input text into individual words or subwords (using the BERT tokenizer) and then pass the tokenized input through the BERT model to generate a sequence of hidden states. These hidden states can then be used to generate word embeddings for each word in the input text by taking the dot product of the hidden states with a learned weight matrix.
The BERT word embeddings are particularly useful because they are context-aware, meaning that the embedding for a word can vary depending on the context in which it appears. This is in contrast to many other word embedding methods, which generate a fixed embedding for each word regardless of context.
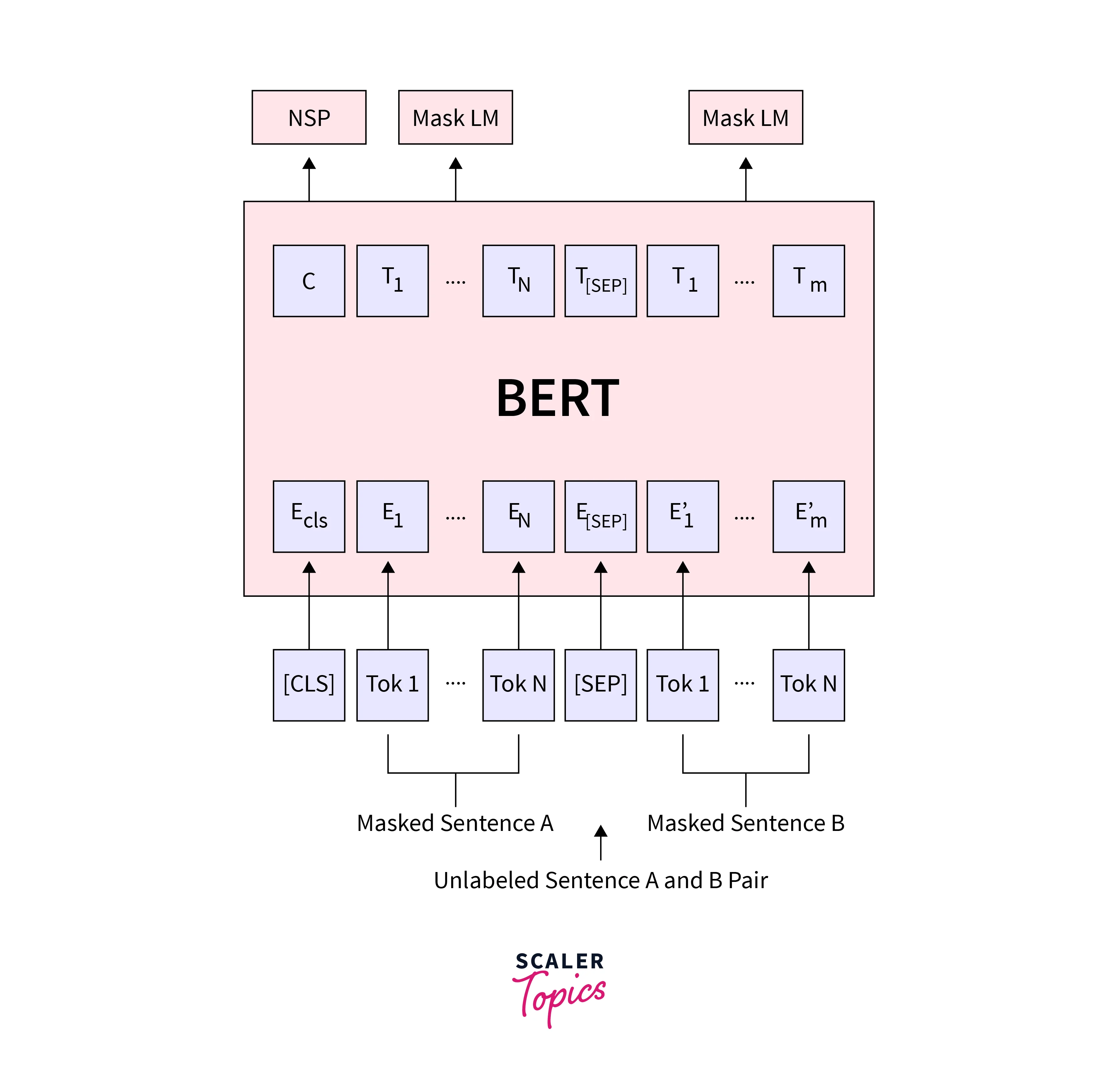
Why do we Use BERT Embeddings?
BERT (Bidirectional Encoder Representations from Transformers) is a method of pretraining language representations that were used to create models that NLP practitioners can then download and use for free. You can either use these models to extract high-quality language features from your text data, or you can fine-tune these models on a specific task (classification, entity recognition, question answering, etc.) with your data to produce a state of the art predictions.
Once a piece of information (a sentence, a document, or an image) is embedded, there starts the creativity; BERT extracts features, namely word and sentence embedding vectors, from text data. The embeddings are useful for keyword/search expansion, semantic search, and information retrieval, and perhaps more importantly, these vectors are used as high-quality feature inputs to downstream models.
BERT offers an advantage over models like Word2Vec regardless of the context within which the word appears. BERT produces word representations that are dynamically informed by the words around them. Thus, BERT is a model with absolute position embeddings.
Loading Pre-Trained BERT
Hugging Face Transformers provides a Pytorch interface for BERT which you can install. Interfaces for other pre-trained language models like OpenAI’s GPT and GPT-2 is also available in this library.
Next import pytorch, the pre-trained BERT model and a Bert Tokeizer.
Several classes for applying BERT to different tasks (token classification, text classification, etc.,) are provided by transformers BertModel is a good choice for using BERT just to extract embeddings.
The BertModel used here is smaller with two available sizes('base' and 'large') and uncased as it ignores casing.
Input Formatting
When using a pre-trained BERT model for natural language processing tasks, it is necessary to follow a specific format for the input data. Here are more details on each of the points you mentioned:
- The start and end of every sentence should contain Special Tokens: BERT expects the input data to be in the form of a sequence of tokens, where each token represents a word or subword in the input text. To mark the start and end of a sentence, BERT uses special "beginning of sentence" (BOS) and "end of sentence" (EOS) tokens. These tokens should be added to the start and end of each input sentence, respectively.
- Pad & Truncate all sentences to a single constant length: To process a batch of input data efficiently, it is necessary to pad or truncate all of the sentences to a single, constant length. This can be done by adding special "padding" (PAD) tokens to the end of shorter sentences or by truncating longer sentences to the desired length.
- With "attention mask," explicitly differentiate real tokens from padding tokens: When padding is used to ensure that all sentences in a batch have the same length, it is important to use an "attention mask" to tell the BERT model which tokens are real and which are padding. This is done by creating a binary mask with the same shape as the input data, where 1 indicates a real token and 0 indicates a padding token. The attention mask is then passed to the BERT model along with the input data, allowing the model to know which tokens to pay attention to and which to ignore.
Special Tokens:
[SEP] represented as Separator The end of each sentence should append a special token [SEP]. When BERT is given two separate sentences and asked to determine something, a special token [SEP] is an artifact of this two-sentence task.
[CLS] represented as Class Prepend the special token [CLS] to every sentence's beginning for classification tasks where this token has special significance. BERT consists of 12 Transformer layers where each transformer produces embeddings of the same number on output as the number of the input list of token embeddings. But the feature values will be changed in the output.
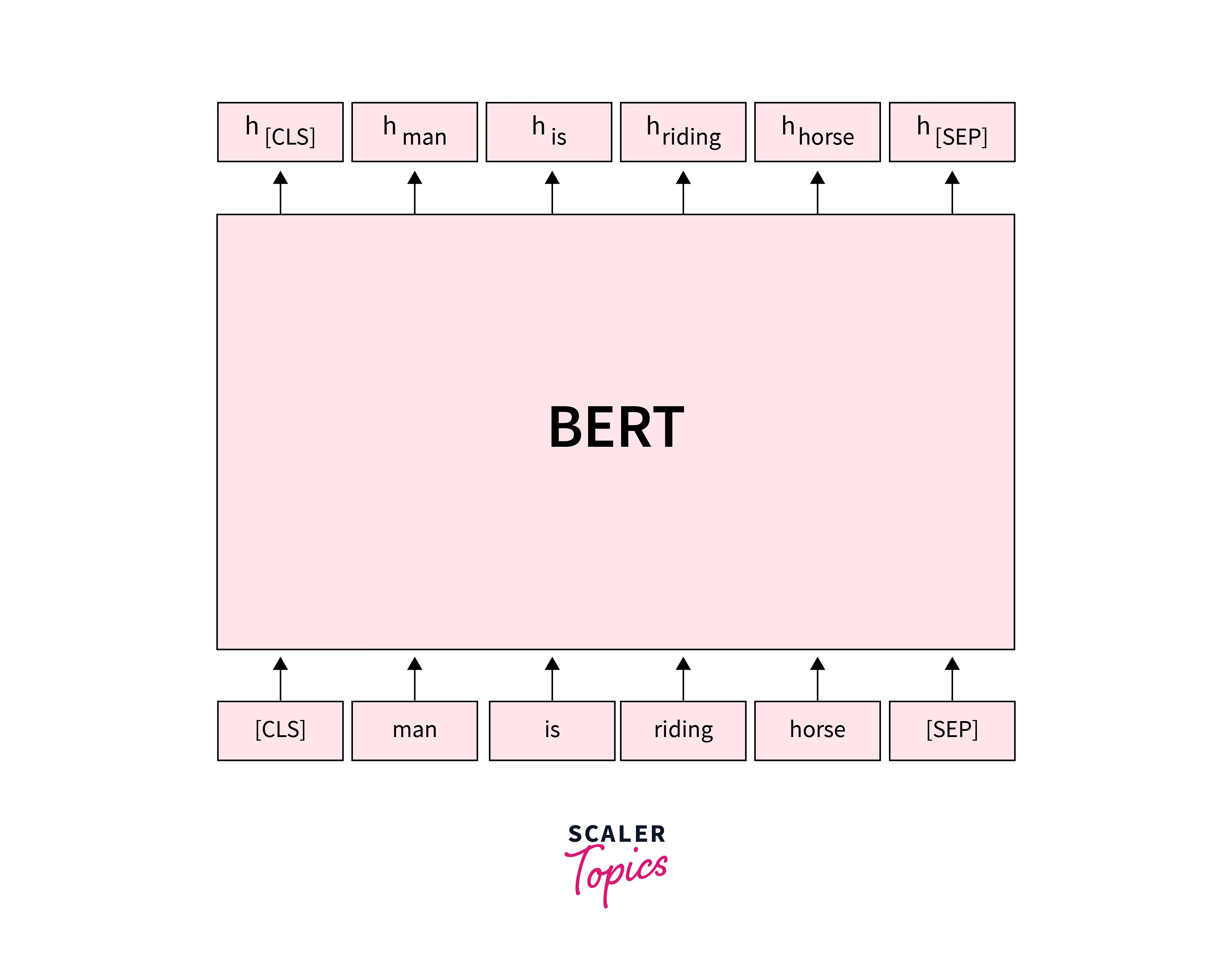
Tokenization:
The 'encode' function provided by the hugging transformers library will handle the parsing and data preparation process.
Before encoding our text, we need to decide on a maximum sentence length for padding and truncating.
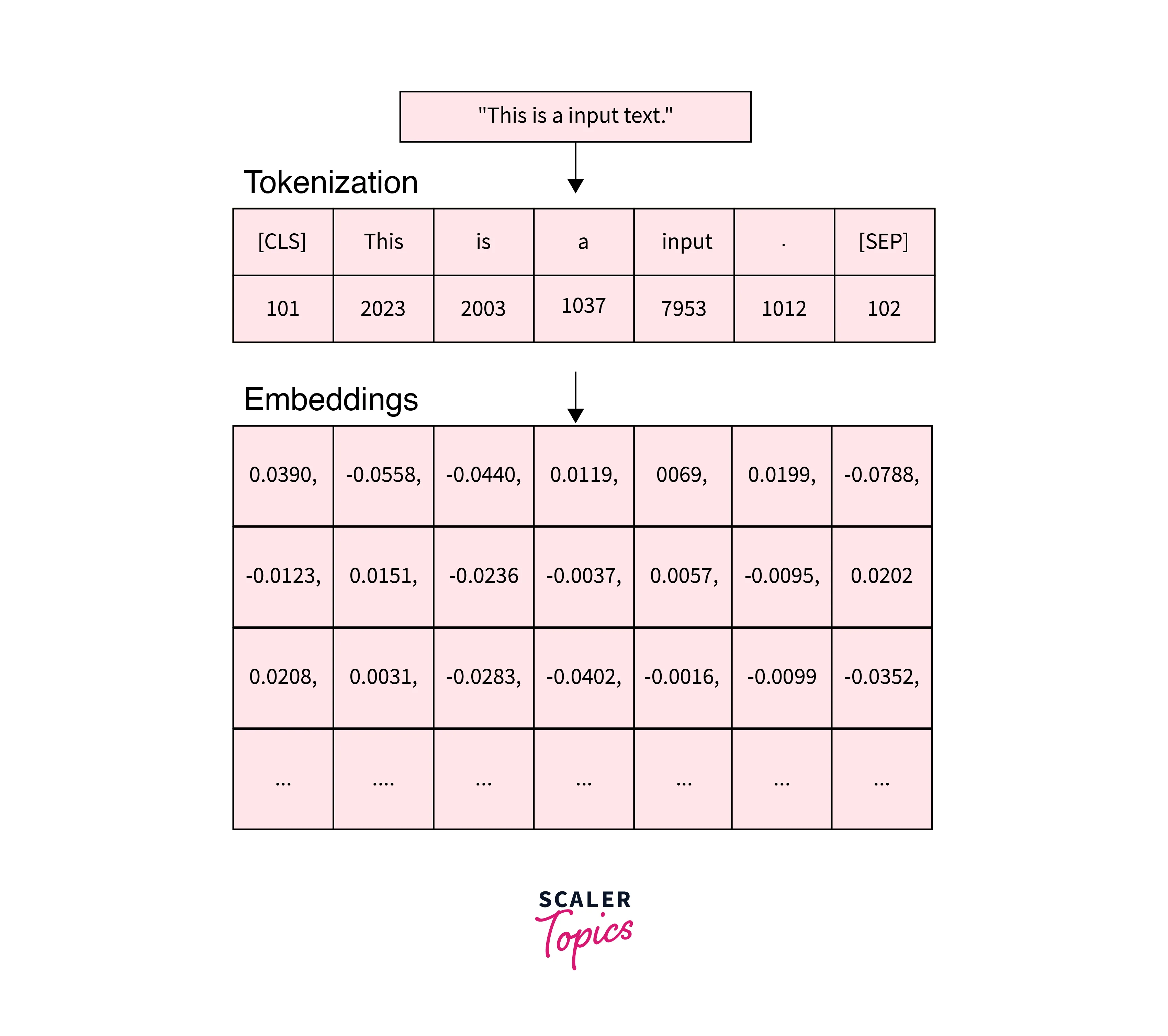
How to Perform Tokenization?
The tokenizer.encode_plus function combines multiple steps for us:
- The sentence is split into tokens
- Special [SEP] and [CLS] tokens are added
- Map tokens to their IDs
- Pad or truncate all sentences to the same length.
- Creating attention masks that differentiate real tokens from [PAD] tokens.
Segment ID:
BERT expects sentence pairs and for each token in tokenized_tex, we specify which sentence t belongs to as sentence 0(s series of 0s)or sentence 1(a series of 1s).
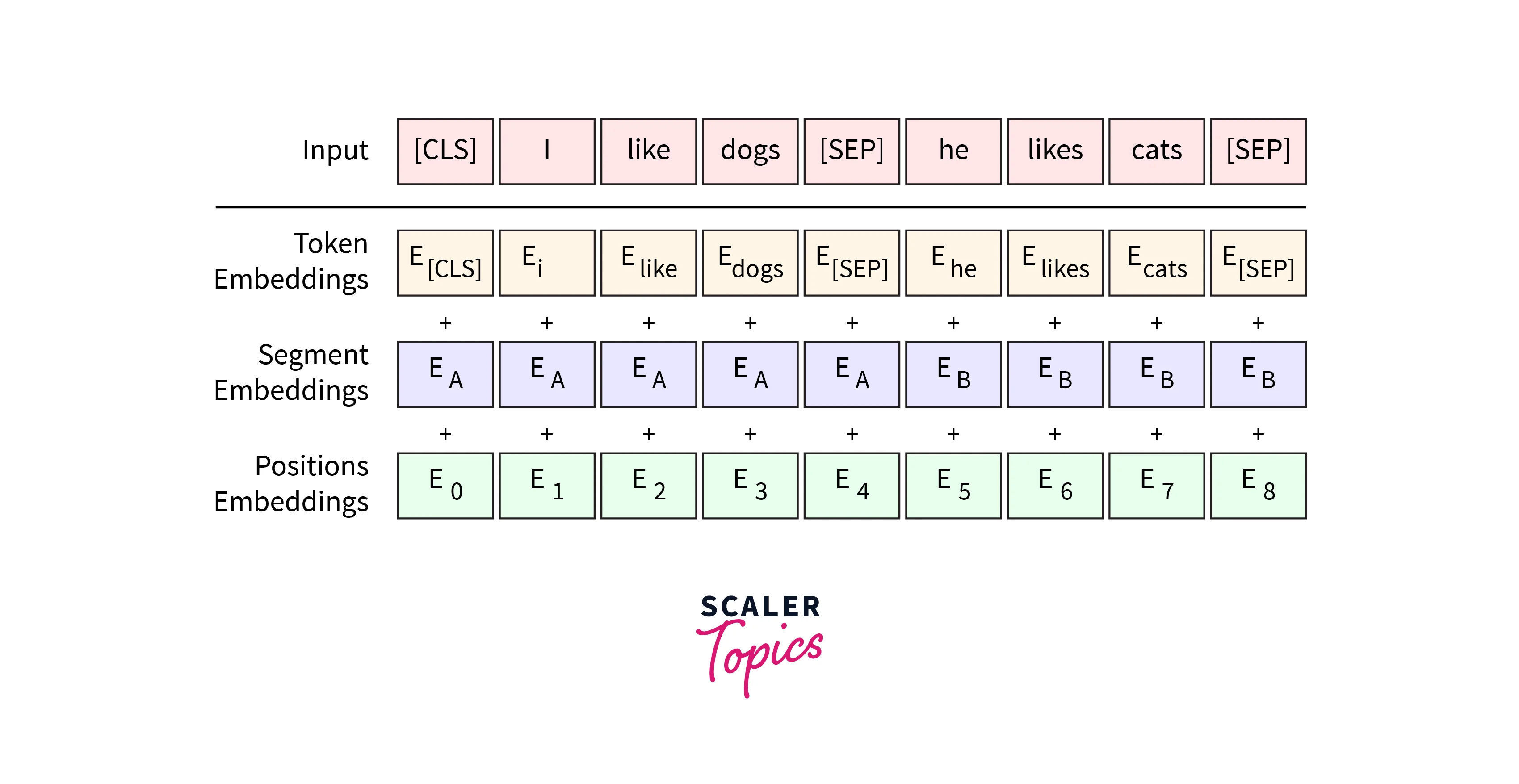
To process two sentences, assign each word in the first sentence plus the ‘[SEP]’ token a 0, and all tokens of the second sentence a 1.
Extracting Embeddings
How to Run BERT on Our Text?
Bert Model learns the inner representation of the English language, which is then used to extract features of the text for all downstream tasks.
We can train a standard classifier for a given dataset with labeled sentences using the features the Bert Model produces as inputs(text).
To get the features of a given text in Tensorflow using this model:
Conclusion
- In conclusion, extracting embeddings from pre-trained BERT models can be a powerful tool for natural language processing tasks such as text classification, sentiment analysis, and named entity recognition.
- These models have been pre-trained on large amounts of data and have been shown to have strong performance on a variety of tasks.
- By using the pre-trained weights and fine-tuning them on a specific task, it is possible to achieve state-of-the-art results.
- Additionally, extracting embeddings from these models allows for the transfer of knowledge to other NLP tasks and can help to improve the performance of downstream models. Overall, using pre-trained BERT models for embedding extraction is a promising approach in the field of NLP.