Application of IR in NLP
Overview
When we have large data set collections and want to query anything written in the natural language, we use the concept of Information Retrieval. Large companies have a large number of computerized files, and we perform a lot of reads and write operations going on in the files. If we want to get a file from the deck of the files and we have only a little metadata about the file, then we will need a lot of time for searching. To lower the searching time and organize the digital files, we use the concept of Document Indexing. Document Indexing is one of NLP's most important IR applications.
Introduction
Before learning about IR application in NLP, let us learn some basics about NLP.
- NLP stands for Natural Language Processing. In NLP, we analyze and synthesize the input, and the trained NLP model then predicts the necessary output.
- NLP is the backbone of technologies like Artificial Intelligence and Deep Learning.
- Every stage makes some respective change to the Doc object and feeds it to the subsequent stage of the process.
Now, when we are working with the NLP model, in many cases, we encounter large collections of data that are unstructured. So, to work with such unstructured large data collections and to fulfill our information need (extraction of useful data), we use Information Retrieval. More formally, Information Retrieval is the way to find useful material out of the unstructured data from a large data set or collection that satisfies our information needs.
We can take an example of internet searching to understand the need for IR and IR applications in NLP. Suppose we are still in the 90s and want to search for a particular thing on the internet. Now, as there was a limited number of pages and websites out there on the internet, the data were structured, and since the data was structured, so it took a lesser amount of space and time for the searching.
Suppose today's situation is where we have unlimited sources on the internet for a particular topic. Since there are a lot and a lot of pages present on the internet today, it cannot be structured data. So, the search space or memory has increased a lot over time, but thanks to the great computational devices, the time taken to search for a particular thing has decreased over the days. But the search space has remained the same, so we use the Information Retrieval technique to deal with such kind of searching over large data sets.
Applications of IR in NLP
We have previously discussed the use case of IR with the help of an example of the internet. Similarly, if we have large data set collections and want to query anything written in the natural language, we use the concept of Information Retrieval. Let us now see the various IR application in NLP in this section.
Document Indexing
Some companies have a large number of computer-based files, and a lot of read and write operations are going on in the files. So, if we want to get a file from the deck of the files and we have only a little metadata about the file, then we will need a lot of time for searching. So, to lower the searching time and organize the digital files, we use the concept of Document Indexing.
Refer to the image provided below for more clarity.
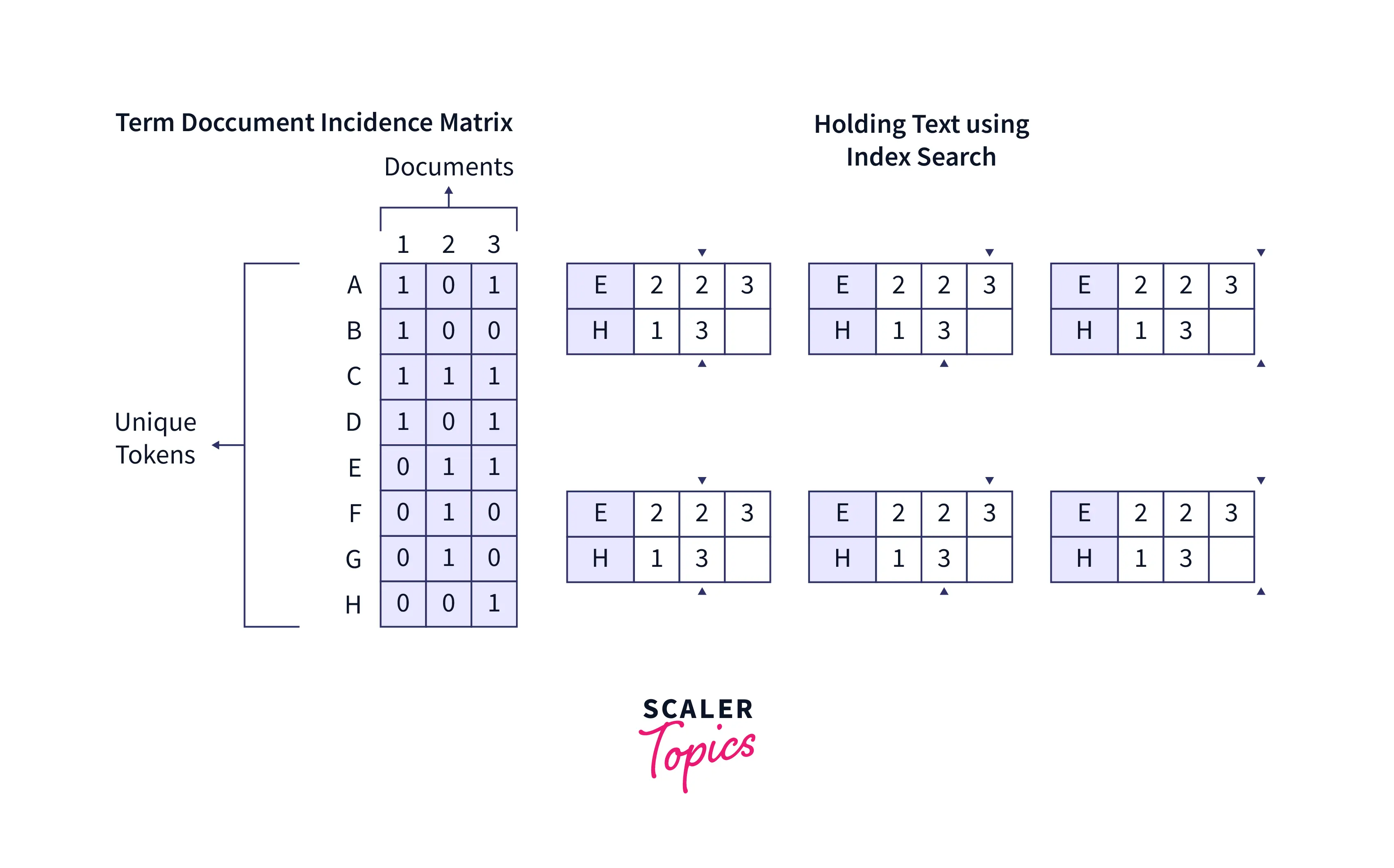
What is Document Indexing, Why is it Used, and Its Various Types?
Formally, we can define Document Indexing as the process of tagging documents and files with certain labels or attributes to search the files faster. Hence, the file retrieval time is also lowered a lot.
A company can provide the labels or attributes like client name, employee name, order date, order area, date, or other such custom tags that will help in specified searching. We can understand its importance with the help of the example of a book. In textbooks, we are provided with an index at the start of the book to search for a topic easily. Similarly, Document Indexing is the index page of the document files, and it helps in faster document retrieval. For example, if we have a 1000-page dictionary and want to search for the word sugar, . So, we can go page by page (letter by letter) until we find the letter s. Then, we can refer to an index provided at the start of the page and directly go to the page that starts with the letter s. In larger dictionaries, there are even deeper indices.
Let us now see the various reasons for using Document Indexing.
- Better organization of the files: In document indexing, we provide the index number to the files, so the files become structured, and thus it is a better organization of the files. We can provide Indexing based on naming, most accessed, size, location, organization, etc.
- Saves time: The right organization, i.e., Indexing, provides us with faster retrieval of the data, and hence we do not need to perform the linear searching of the files, so the time is also saved a lot. For example, suppose we have made the Indexing based on the alphabetical order of the files, and we want to search for a file starting with S then we directly go to the index number related to the letter S. This saves a lot of time if we have a huge number of files. We can even create Indexing inside an index for more fast retrieval.
- Saves money: All the above benefits save time and computation, so overall, money is also saved.
Other associated benefits of using document indexing include better collaboration, efficient workflows, easier audit compliance, etc.
There are mainly three types of Indexing. Let us discuss them a bit.
- Full-text Indexing: We scan the entire document's content in full-text Indexing. Scanning the entire document allows us to search for phrases and keywords easily. When we perform the CTRL+F on a certain page, the full-text Indexing happens in the background with our required phrase. Full-text searching is one of the easiest and most widely used Indexing and searching techniques, as users can perform it easily. However, since we are scanning the entire document, it requires a huge storage space.
- Automated Indexing Using Data Variables Lookup Indexing: Despite scanning the entire document, this searching technique targets the key fields, like customer numbers, names, locations, etc., within the database. Since we are targeting a specific key, the process is a bit complex and requires external software like document indexing tools. This indexing technique is used in companies for searching invoices, order IDs, and other search details of a customer with the help of metadata of the customer.
- Metadata Indexing: If we search a certain date, we first search the metadata space. For example, if we want to search for the details of a customer X who lives in Mumbai, we will first search the metadata instead of scanning the entire customer database. We will first look at the location of the desired customer from the metadata, i.e., Mumbai, and then perform our search in the Mumbai files.
We also have the Automated Indexing Using Field Data type of Indexing, which is somewhat similar to the metadata indexing technique.
Product Search
Let us see how the Indexing searches a particular product from the inventory. Again, selecting the right indexing technique is the key to faster data retrieval.
Determining the right indexing technique for our search mainly depends on the type of file we are working on. So, if we are dealing with searching invoices or orders, we must use metadata indexing. On the other hand, if we search in a smaller space, we can use full-text Indexing, etc.
Apart from these, we should also consider the use case of searching as the searching tools costs the company, so the use case and user requirements should also be considered. In many cases, company (usually small-scale companies) also performs manual Indexing.
Advantages:
- It helps in manual searching in smaller databases.
- We can add the type of Indexing and the value to be indexed according to our search.
- Users can easily query their search.
Refer to the image below to see how the normal product search occurs.
Conclusion
- If we have large data set collections and want to query anything written in the natural language, we use the concept of Information Retrieval. However, if we want to get a file from the deck of the files and we have only a little metadata about the file, then we will need a lot of time for searching.
- To lower the searching time and organize the digital files, we use the concept of Document Indexing. Document Indexing is one of the most important IR applications in NLP.
- In full-text Indexing, we scan the entire documents' content. Therefore, full-text searching is one of the easiest and most widely used Indexing and searching techniques, as users can perform it easily.
- In Automated Indexing Using Data Variables Lookup Indexing, we target a specific key, which makes the process a bit complex and requires external software like document indexing tools.
- In metadata indexing, if we search a particular data, we first search the metadata space. We also have Automated Indexing Using Field Data type of Indexing, similar to the metadata indexing technique.