Machine Translation in NLP
Overview
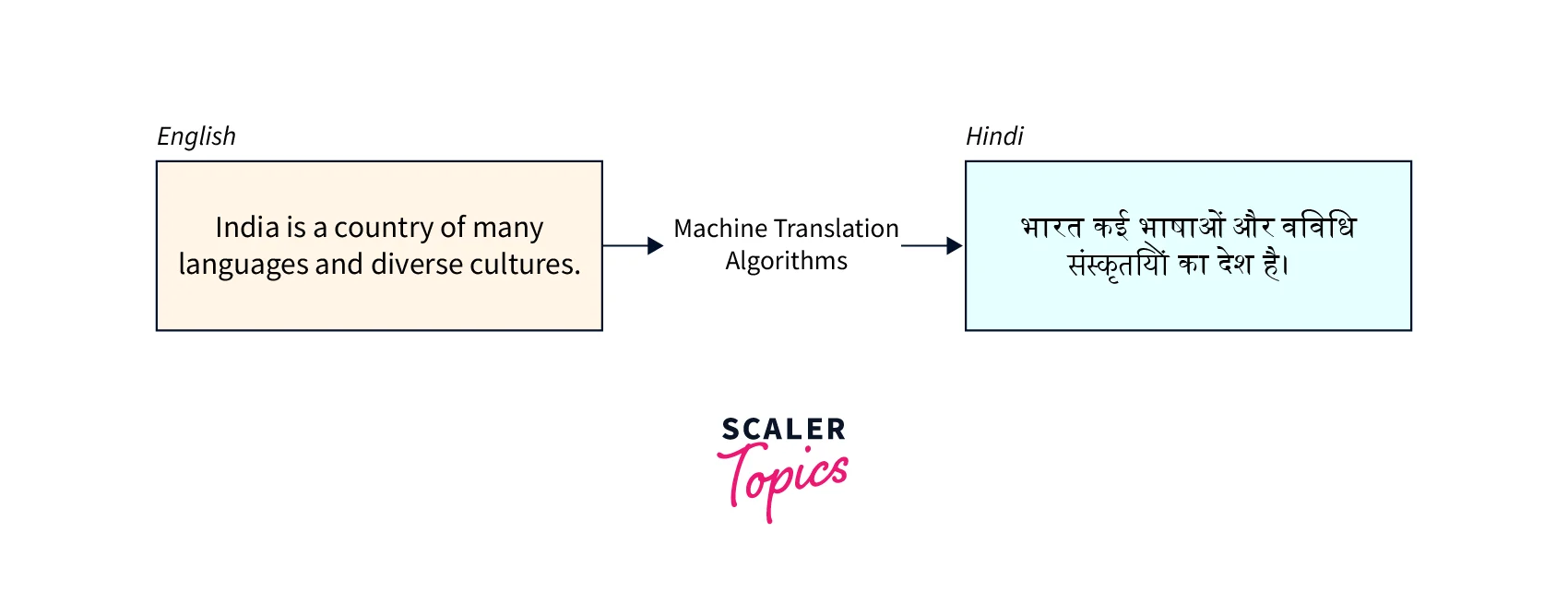
Machine Translation (MT) is a domain of computational linguistics that uses computer programs to translate text or speech from one language to another with no human involvement with the goal of relatively high accuracy, low errors, and effective cost.
Machine Translation is a very important yet complex process as there is currently a huge number of nuanced natural languages in the world.
What is a Machine Translation, and How does it Work?
Need for Machine Translation
There is an explosion of data in the modern world with the information revolution and since language is the most effective medium of communication for humans, there is also an increased need for translating from one language to another using NLP tools and other techniques.
- The demand for translation is majorly due to the exponential rise increase in the exchange of information between various regions using different regional languages.
- Examples such as access to web documents in non-native languages, using products from across countries, real-time chat, legal literature, etc. are some use cases.
Why is machine translation so hard to tackle?
Machine translation using NLP tools from one language to another is notoriously difficult due to the presence of many words with multiple meanings, sentences with potential possible readings, and the fact that certain grammatical relations in one language might not exist in another language.
Process of Machine Translation
The basic requirement in the complex cognitive process of machine translation is to understand the meaning of a text in the original (source) language and then restore it to the target (sink) language.
The primary steps in the machine translation process are:
- We need to decode the meaning of the source text in its entirety. There is a need to interpret and analyze all the features of the text available in the corpus.
- We also require an in-depth knowledge of the grammar, semantics, syntax, idioms, etc. of the source language for this process.
- We then need to re-encode this meaning in the target language, which also needs the same in-depth knowledge as the source language to replicate the meaning in the target language.
Evolution of Machine Translation
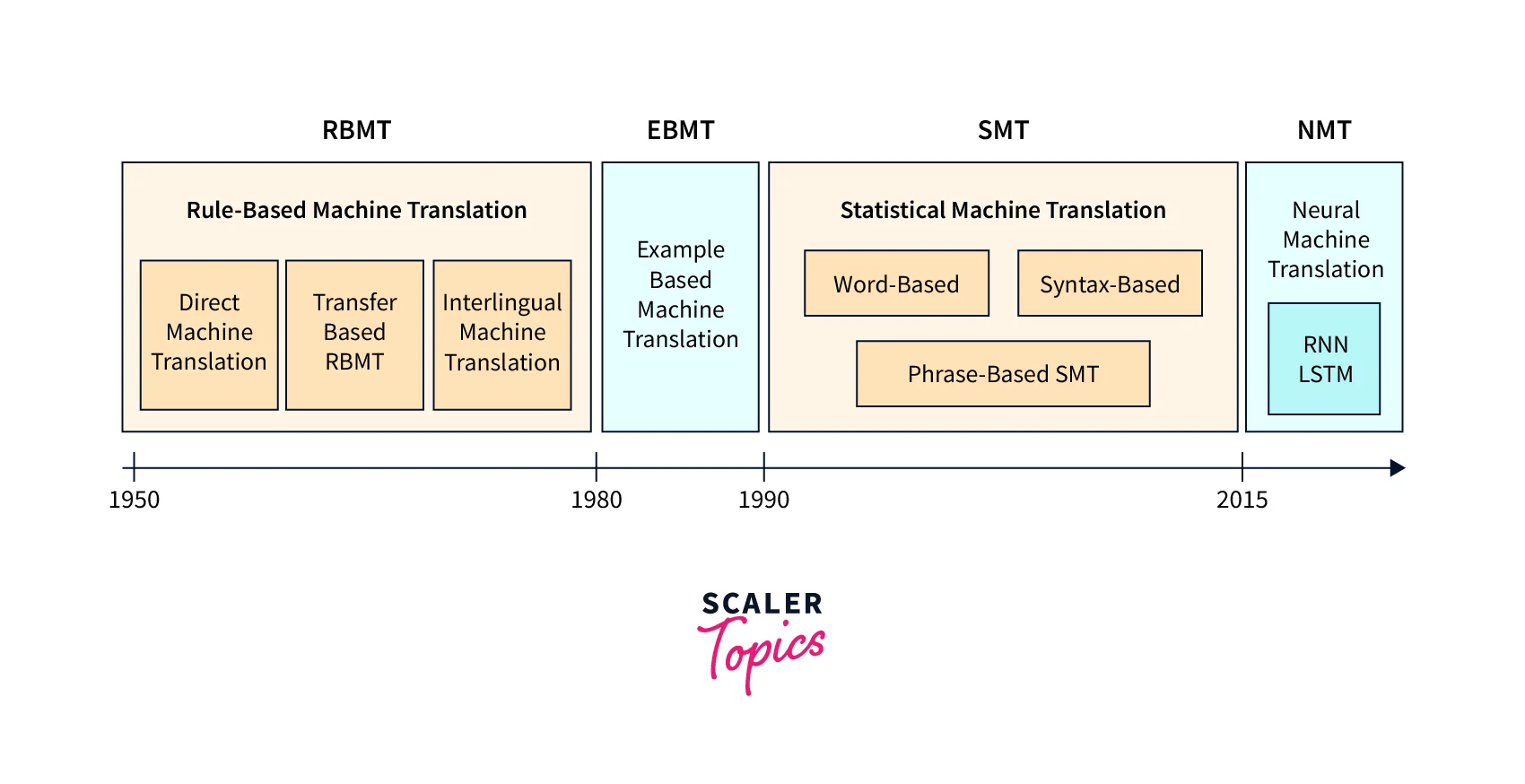
-
1950 to 1980: The major interest and support for machine translation in the decades from the 1950s to the 1980s was fueled by the need for high-speed, high-quality translation of arbitrary texts, which are heavily funded mostly by military and intelligence communities during the cold war era.
- The systems during this time were mainly rule-based, and almost all research and development centred around improving the performance of individual use cases.
-
1980-1990: In the late 1980s, example-based machine translation models were employed for some time till the early 1990s.
- The main idea is to provide the system with a set of sentences within the source language and then the corresponding translations in the target language. Both examples serve as examples for translations.
-
1990-2015: Machine translation systems based on statistical methods were introduced in the 1990s, replacing the earlier rule-based and example-based systems.
- The statistical-based methods come under the case of corpus-based machine translation methods.
-
2015-Present: Deep neural network-based models were developed for automatic machine translation by almost all technology companies for industrial applications, which achieved state-of-the-art results in the last few years recently among all NLP techniques.
- This recent utility of neural net-based models made the field named neural machine translation.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now
Different Types of Machine Translation in NLP
Machine translation methods are mainly classified into rule-based and corpus-based methods during the developments from the 1950s till now. Recently neural network-based models are primarily employed for translation tasks using NLP.
Let us discuss and learn the classification and methods involved in each type of model.
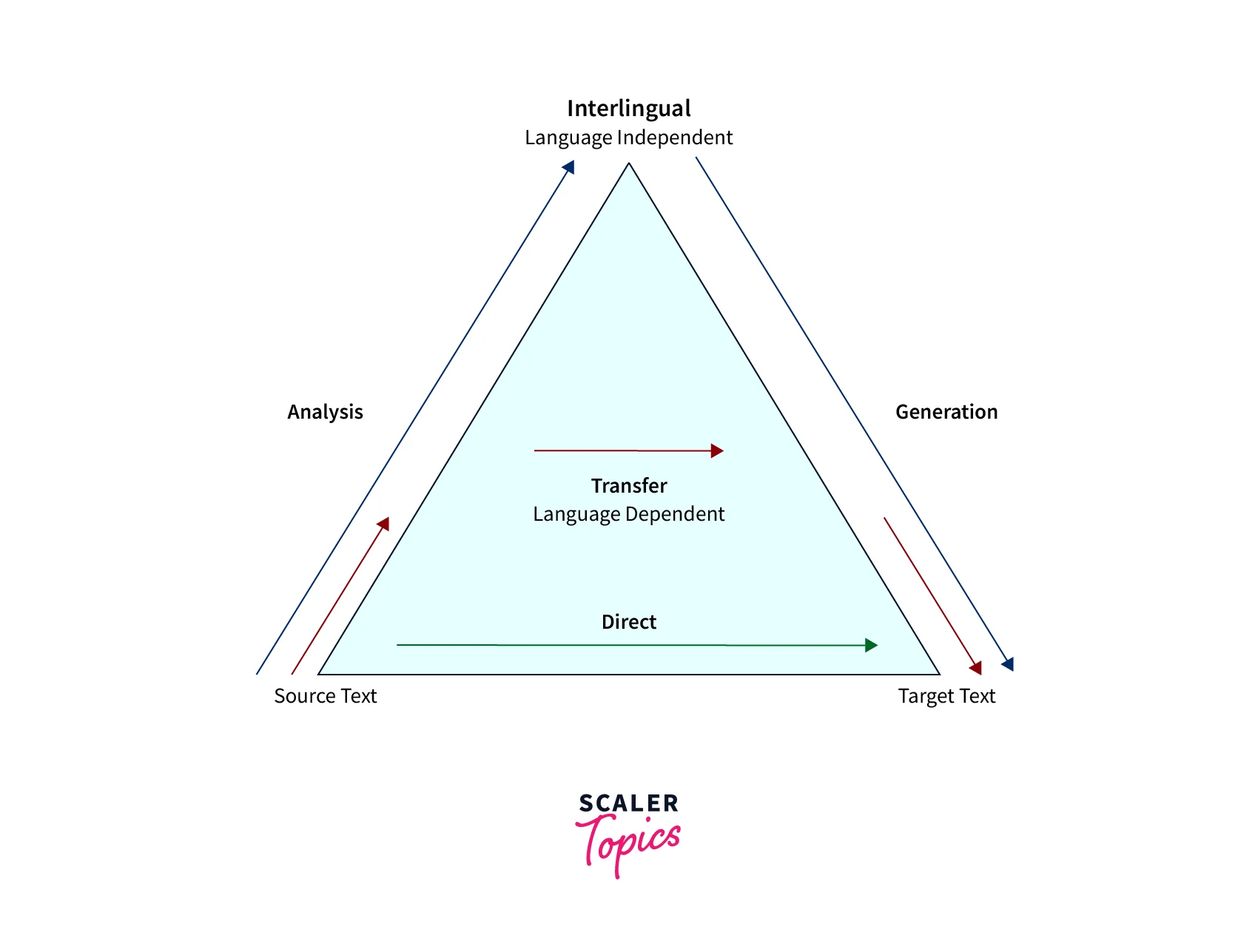
Rule-based Machine Translation or RBMT
Also called knowledge-based machine translation, these are the earliest set of classical methods used for machine translation.
- These translation systems are mainly based on linguistic information about the source and target languages that are derived from dictionaries and grammar covering the characteristic elements of each language separately.
- Once we have input sentences in some source languages, RBMT systems generally generate the translation to output language based on the morphological, syntactic, and semantic analysis of both the source and the target languages involved in the translation tasks.
- The sub-approaches under RBMT systems are the direct machine translation approach, the interlingual machine translation approach, and the transfer-based machine translation approach.
Corpus-based Machine Translation Approach or CBMT
Also called data driven machine translation, these methods majorly overcome the problem of knowledge acquisition problem of rule-based machine translation approaches. The Corpus-based machine translation methods can handle linguistic issues and generally find it difficult to translate cultural items and concepts.
- Corpus-Based Machine Translation is a set of methods that uses a bilingual parallel corpus to obtain knowledge for new incoming translation.
- This approach uses a large amount of raw data in the form of parallel corpora. This raw data contains text and their translations. These corpora are used for acquiring translation knowledge.
- Corpus-based approaches are classified into two sub-approaches: Statistical Machine Translation and the Example-based Machine Translation approach.
Example-based Machine Translation or EBMT
Example-based machine translation systems are trained from bilingual parallel corpora where the sentence pairs contain sentences in one language with their translations into another.
-
The foundational idea of example-based machine translation is the concept of translation by analogy.
- The principle of translation by analogy is encoded to the example-based machine translation through the example translations that are used to train the system.
-
The bilingual corpus with parallel texts serves as the main knowledge for an Example-based machine translation system in which translation by analogy.
- A set of sentences in the source language are given in the example-based machine translation system, and corresponding translations of each sentence in the target language with point-to-point mapping are also provided as input.
- These examples are used to translate similar types of sentences of the source language to the target language.
-
Example acquisition, example base, and management, example application, and synthesis are the four main tasks to be performed in EBMT methods.
Sample example for EBMT-based approach:
- Let us say we want to translate a simple sentence — I'm going to the playground., and let’s say that we have already translated another similar sentence — I’m going to the movies. — and we can find the word “movies” in the dictionary.
- All we need is to figure out the difference between the two sentences, and then translate the missing word in the new language.
- The more examples we have, the better the translation will be.

Example-based machine translation systems paved the path further to statistical-based machine translation systems.
Master structured AI Engineering + GenAI hands-on, earn IIT Roorkee CEC Certification at ₹40,000
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol NowStatistical Machine Translation or SMT
Statistical machine translation (SMT) models are generated with the use of statistical models whose parameters are derived from the analysis of bilingual text corpora. The ideas for SMT come from information theory.
-
The principle theory of SMT-based models is that they rely on the Bayes Theorem to perform the analysis of parallel texts.
- The central idea is that every sentence in one language is a possible translation of any sentence in the other language, but the most appropriate is the translation that is assigned the highest probability by the system.
-
The SMT methods need millions of sentences in both the source and target languages for analysis to collect the relevant statistics for each word.
- In the early set of models, the abstracts of the European Parliament and the `United Nations Security Council meetings, which were available in the languages of all member countries, were taken for getting the required probabilities.
-
SMT-based methods are further classified into Word-based SMT, Phrase-based SMT, and Syntax based SMT approaches.
Issues with SMT-based Approaches
- Sentence Alignment: As we are using two corpora to match sentences, many times we will encounter single sentences in the source language, which can be found translated into several sentences in the target language.
- Example: When translating from English to German, the sentence "Raghu does not live here," the word "does" doesn't have a clear alignment in the translated sentence "Raghu wohnt hier nicht."
- Statistical Anomalies: Real-world training sets may override translations like proper nouns.
- Example: "I took the train to Berlin" gets mistranslated as "I took the train to Paris" due to an abundance of "train to Paris" in the training set generally.
- Idioms: Depending on the corpora used, idioms may not translate idiomatically into the target language.
- , For example,, using Canadian Hansard as the bilingual corpus, "hear" may almost invariably be translated to "Bravo!" since in Parliament, "Hear, Hear!" becomes "Bravo!".
- Different Word Orders: Since the word orders in languages differ, Statistical machine translation methods do not work well between languages that have significantly different word orders, for example Japanese and European languages.
- Corpus Creation: This can be very costly for users with limited resources, and sometimes the results are also unexpected where the superficial fluency can be deceiving.
- Data Dilution: This is one of the most common anomalies caused when attempting to construct a new statistical model to represent a distinct terminology for a specific corporate brand or domain.
Become the Ai engineer who can design, build, and iterate real AI products, not just demos with an IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol NowHybrid Machine Translation or HMT
-
Hybrid Machine Translation approaches take advantage of both statistical and rule-based translation methodologies which were proven to have better efficiency in the area of machine translation systems using NLP.
- These techniques are better than the previous methods and have more power, flexibility, and control in translation tasks in general.
- Most governmental and industrial-based machine translation systems use the hybrid-based approach to develop translation from source to target language, which is based on both rules and statistics.
-
Hybrid-based approaches combine the best of both worlds such that they can be used in several different ways.
- In cases where translations are performed in the first stage using a rule-based approach, they can be followed by adjusting or correcting the output using statistical information.
- On the other way, rules are used to pre-process the input data as well as post-process the statistical output of a statistical-based translation system.
Neural Machine Translation or NMT
Neural Machine Translation methods in NLP employ artificial intelligence techniques and, in particular, rely upon neural network models which were originally based on the human brain to build machine learning models with the end goal of translation and also further learning languages, and improving the performance of the machine translation systems constantly.
- Neural Machine Translation systems do not need any specific requirements that are regular to other machine translation systems like statistical-based methods in general.
- Neural Machine Translation works by incorporating training data, which can be generic or custom depending on the user’s needs.
- Generic Data: Includes the total of all the data learned from translations performed over time by the machine translation engines employed in the entire realm of translation.
- This data also serves as a generalized translation tool for various applications, including text, voice, and documents.
- Custom or Specialized Data: These are the sets of training data fed to machine translation tasks to build specialization in a subject matter.
- Subjects include engineering, design, programming, or any discipline with its specialized glossaries and dictionaries.
- Generic Data: Includes the total of all the data learned from translations performed over time by the machine translation engines employed in the entire realm of translation.
Advantages of NMT Models:
- NMT has achieved the state of the art performance in large-scale translation tasks in many languages like English to French, English to German etc.
- NMT requires minimal domain knowledge and is conceptually very simple and powerful.
- NMT has a small memory footprint as it does not store gigantic phase tables and language models.
- NMT also can generalize well to very long word sentences.
What are the Benefits of Machine Translation?
Machine translation is a very important tool in the translation process of modern-day application workflows.
Let us look at the primary benefits offered by using MT approaches:
-
Fast Translation Speed: Machine translation using NLP has the potential to translate millions of words for high-volume translations happening in modern day-to-day processes.
- MT cuts the human translator effort usually done post-editing.
- We can use machine translation to tag high-volume content and organize the contents so that we can look up over search or retrieve content in translated languages quickly.
-
Excellent Language Selection: Most machine language translation tools these days can translate more than 100 languages.
- The MT programs are powerful enough to translate multiple languages at once so they can be rolled out to a global user base across products and do documentation updates on the fly.
- MT is well-suited to many language pairs these days (English to most European languages) with very high accuracies.
-
Reduced Costs: As annotation with humans doesn't scale well both in terms of cost and speed, we can use machine translation using NLP to cut translation delivery times and costs.
- We can also produce basic translations with little compute costs that can be further utilized by human translators so that they can further refine and edit from previous steps.
Sequence to Sequence Model
With the advent of recurrent network models for a variety of complex tasks where the order of the task (like the sequence of words in a sentence) is important, Sequence to Sequence has become very popular for machine translation tasks in NLP.
Sequence to Sequence models primarily consists of an encoder and decoder model architecture and utilize a combination of recurrent units in their layers.
- The encoder and the decoder are two distinct individual components working hand in hand together to produce state-of-the-art results while performing different kinds of computations.
- The input sequences of words are taken as the input by the encoder, and the decoder component typically has the relevant architecture to produce the associated target sequences.
- In the machine translation task, the source language is passed as input to the encoder as a sequence of vectors, and then it is passed through a series of recurrent units whose end output is stored as the last hidden state as the encoder state representation.
- This hidden state is used as input for the decoder and passed through a series of recurrent again as a for loop, usually each output sequentially so that the output produced has the highest probability.
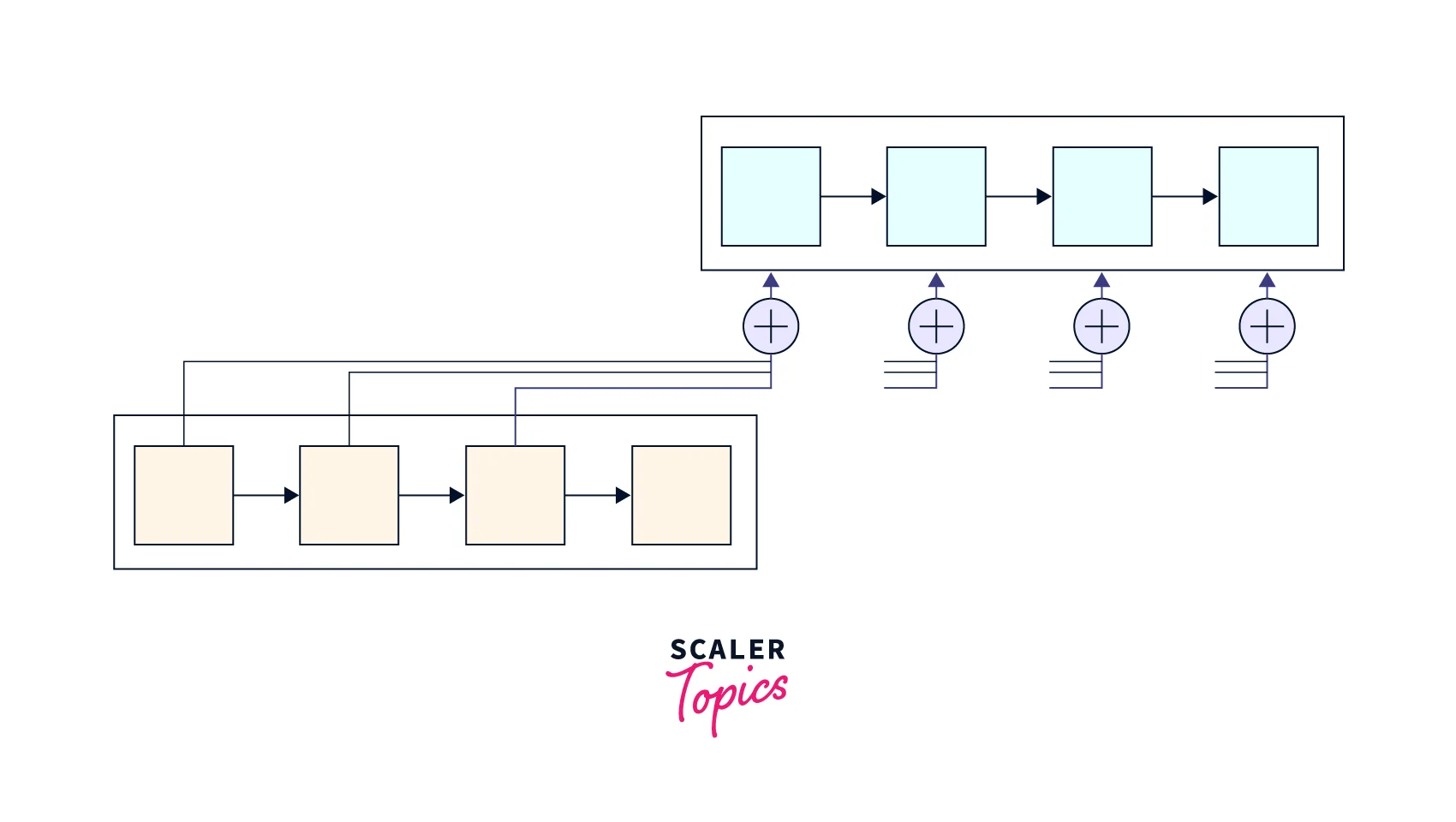
Attention Model
One of the potential issues with using encoder–decoder architecture of seq-2-seq models is that the neural network typically compresses all the necessary information of a source sentence into a fixed-length vector and also keeps track of what words are exactly important.
- The task is difficult for recurrent layers to cope with long sentences, especially those that are longer than the sentences in the input training corpus.
- Attention is proposed as a novel solution to the limitation of this particular encoder-decoder model of decoding long sentences by selectively focusing on sub-parts of the sentence during translation.
Intuition for Attention Models
Attention allows neural network models to approximate the visual attention mechanism humans use in processing different tasks.
- The initial step of the model works by studying a certain point of an image or text with intense high-resolution focus, like how humans process a new scene in an image or text while talking.
- While focussing on current high-resolution contexts, it also perceives the surrounding areas in low resolution simultaneously.
- The last step is to then adjust the focal point as the network begins to understand the overall picture together.
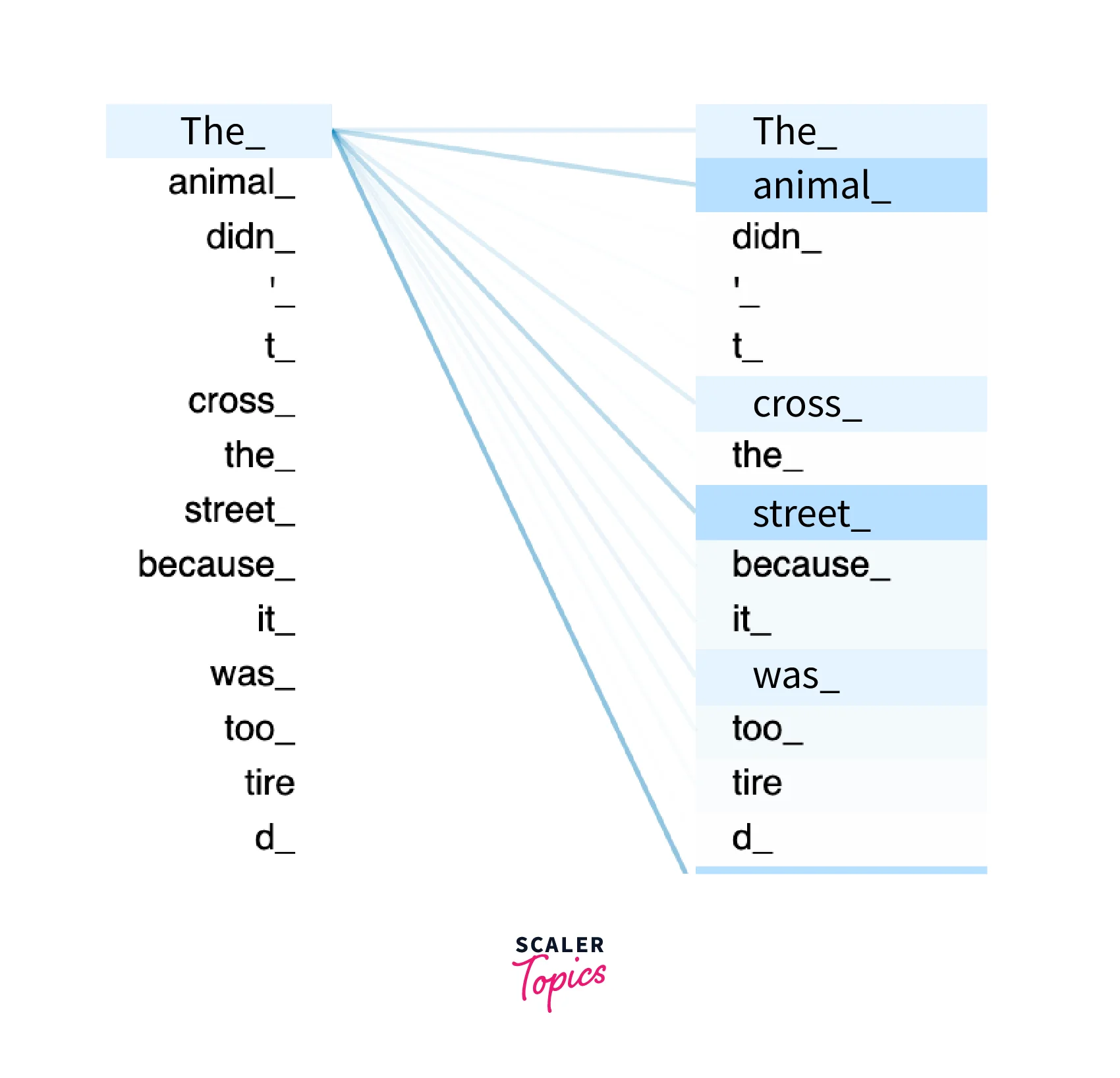
Using Attention in Neural Machine Translation Models
When using attention for neural machine translation tasks, the meaning of the whole sentence is mapped into a fixed-length vector, which then generates a translation based on that vector as a whole.
- The overall model translates the sentence by paying attention to the general, high-level overall sentiment of the sentence instead of only concentrating on doing word-to-word translation.
- Attention-based models for Neural Machine Translation are proven to drastically improve accuracy and are much easier to construct and faster to train the models.
- There are mainly two types of attention-based models, generalized/global attention and self-attention.
Transformer Model
Transformers models also come under sequence-to-sequence models for many computational tasks, but they rely mostly on the attention mechanism to draw the dependencies between layers of the network.
- When compared with the previous neural network architectures, the Transformer based neural attention models achieved the highest BLEU scores on machine translation tasks while also requiring significantly less compute and training time.
- The primary idea in the transformer is to apply a self-attention mechanism and model the relationships between all words in a sentence directly regardless of their respective position like in the recurrent networks.
Transformer also possesses the encoder-decoder architecture like in RNN-based Seq2Seq models for transforming one sequence into another.
- The main difference with the existing Seq2Seq models is that they do not imply any recurrent layers and instead handle the entire input sequence in at once and don’t iterate word by word.
- The encoder is a combination of a Multi-Head Self-Attention Mechanism and a series of Fully-Connected Feed-Forward Networks.
- The decoder is a combination of Masked Multi-Head Self-Attention Mechanism, Multi-Head Self-Attention Mechanism, and also Fully-Connected Feed-forward Networks.
Machine Translation vs. Human Translation
- While machine translation is the automatic and instant translation of text from one language to another using software tools, human translation, on the other hand, includes the actual brainpower of humans in the form of one or more translators translating the text manually.
- With the rise of AI technologies and open source APIs offered in the market, numerous translation tools are available at practically no or zero cost making it a reasonable answer for organizations who will be unable to manage the cost of expert translations.
- While machine translation is powerful to scale in terms of cost and speed, careful judgment needs to be exercised to call between human and machine translation which requires additional consideration and subtlety in the translation task.
Applications of Machine Translation
Let us discuss some of the major applications of machine translation employed in the industry currently.
Text Translation
Automated Text Translation is mainly used in an assortment of sentence-level and text-level translation applications.
- Sentence-Level Translation applications typically incorporate the translation of inquiry and recovery inputs and the translation of (OCR) outcomes of picture optical character acknowledgement.
- Text-Level Translation applications incorporate the translation of a wide range of unadulterated reports and the translation of archives with organized data.
Speech Translation
Voice input is ubiquitous in most modern applications with the exponential advancement of modern chips in mobile and processing voice input has come to be ingenious and necessary for human-computer utilization, and discourse translation has become a significant application in such situations.
- The typical cycle for discourse interpretation includes multiple steps like - source language discourse, then source language text, target language text, followed by target language discourse".
- The text translation step from source language text to target-language text is the module moderating machine translation task.
Other Applications
- Machine translation technology using NLP can help law firms and corporate legal departments understand and process large quantities of legal documents quickly.
- In construction and manufacturing projects, competitive bid documents translated from foreign languages can provide all the information needed so that one can act as quickly as possible and increase the chances of securing the contracts in respective fields.
- MT is also used in many other fields like e-commerce where content translation is done, and also in many web-related tasks.
Conclusion
- Machine translation is the process of automatic translation of text from one language to another using software tools.
- Machine translation tools evolved from using rule-based methods to corpus-based methods. Neural machine translation methods are the state of the models in MT tasks.
- Machine translation is widely used in text-based, speech-based, and many other industrial applications in modern mobile phones, web-based tasks, and most business settings.
- We will then compare machine translation with human translation and look at different state-of-the-art models for translation tasks.
- Machine translation tools using NLP can be employed to effectively scale across time and cost, but human translators with expert skills need to be employed in nuanced and creative translation tasks.
- Sequence to Sequence models employ encoder-decoder architecture and recurrent layers (like LSTM, RNN) to model machine translation tasks.
- Attentions are a set of novel computational mechanisms proposed to solve the problems encountered in recurrent mechanisms of Sequence to Sequence models.
- Transformers utilize attention mechanisms along with the encoder-decoder architecture to achieve state-of-the-art results in machine translation tasks.