Simple (Unsmoothed) N-gram in NLP
Overview
N-grams are continuous sequences of words or symbols or tokens in a document and are defined as the neighboring sequences of items in a document. They are used most importantly in tasks dealing with text data in NLP (Natural Language Processing).
N-gram models are widely used in statistical natural language processing, speech recognition, phonemes and sequences of phonemes, machine translation and predictive text input, and many others for which the modeling inputs are n-gram distributions.
What are n-grams?
N-grams are defined as the contiguous sequence of n items that can be extracted from a given sample of text or speech. The items can be letters, words, or base pairs, according to the application. The N-grams typically are collected from a text or speech corpus (Usually a corpus of long text dataset).
- N-grams can also be seen as a set of co-occurring words within a given window computed by basically moving the window some k words forward (k can be from 1 or more than 1).
- The co-occurring words are called "n-grams," and "n" is a number saying how long a string of words we have considered in the construction of n-grams.
- Unigrams are single words, bigrams are two words, trigrams are three words, 4-grams are four words, 5-grams are five words, etc.
Applications of N-grams: N-grams of texts are extensively used in the n-gram model in NLP, text mining, and natural language processing tasks.
- For example, when developing language models in natural language processing, n-grams are used to develop not just unigram models but also bigram and trigram models.
- Tech companies like Google and Microsoft have developed web-scale n-gram models that can be used in a variety of NLP-related tasks such as spelling correction, word breaking, and text summarization.
- One other major usage of n-grams is for developing features for supervised Machine Learning models such as SVMs, MaxEnt models, Naive Bayes, etc. The main idea is to use tokens such as bigrams (and trigrams and advanced n-grams) in the feature space instead of just unigrams.
Importance of order of words in text & NLP
- In general, the order of the words that are used in the natural language of the text is not random. If we consider the English language, we can use the words "the green apple" but not "apple green the" in a sentence.
- The relationships between words in the flow of the text are also very complex. N-grams are tooted as a relatively simple way of capturing some of these relationships between the words.
- We can capture quite a bit of information by just looking at which words tend to show up next to each other more often. By constructing the n-grams, we can construct the co-occurring words and use them in modeling relationships and other applications.
- Example: The general idea with n-grams is that we can look at each pair or triple or set of four or more words that occur next to each other in a sufficiently large corpus.
- When we construct these pairs of words, we are more likely to see "the green" and "green apple" several times but less likely to see "apple green" and "green the".
- This kind of context is useful to know and utilize in many use cases of NLP. We can figure out what someone is more likely to say to help decide between the possible outputs for an automatic speech recognition system.
How are n-grams Classified?
N-grams are classified into different types depending on the value that n takes. When , it is said to be a unigram. When , it is said to be a bigram. When , it is said to be a trigram. When , it is said to be a 4-gram, and so on.
- Different types of n-grams are suitable for different types of applications in the n-gram model in nlp, and we need to try different n-grams on the dataset to confidently conclude which one works the best among all for the text corpus analysis.
- It is also established with research and substantiated that trigrams and 4 grams work the best in the case of spam filtering.
An Example of n-grams
Let us look at the example sentence Cowards die many times before their deaths; the valiant never taste of death but once and generate the associated n-grams related to the sentence.
- Unigrams: These are simply the unique words in the sentence.
- Cowards, die, many, times, before, their, deaths, the valiant, the valiant, never, taste, of, death, but, once.
- Bigrams: These are simply the pairs of co-occurring words in the sentence formed by sliding one word at a time in the forward direction to generate the next bigram.
- cowards die, die many, many times, times before, before their, their deaths, deaths the, the valiant, valiant never, never taste, the taste of, of death, death but, but once
- Trigrams: These are the 3 pairs of co-occurring words in the sentence formed by sliding two words at a time in the forward direction to generate the next trigram.
- cowards die many, die many times, many times before, times before their, before their deaths, their deaths the, deaths the valiant, the valiant never, valiant never taste, never taste of, taste of death, of death but, death but once
- 4-grams: Here we have the window such that we have combinations of 4 words together
- cowards die many times, die many times before, many, times before their, times before their deaths, before their deaths the, their deaths the valiant, deaths the valiant never, the valiant taste, valiant never taste of, never taste of death, taste of death but, of death but once
- Simialary we can pick and generate 5-grams etc.
Step-by-Step Implementation of n-grams in Python
Load the Dataset and Libraries
Import the libraries for processing data and other utilities
- import os, sys, gc, warnings
- import logging, math, re
- import pandas as pd
- import numpy as np
- import seaborn as sns
- import matplotlib.pyplot as plt
- from matplotlib.pyplot import figure
- from IPython.display import display, HTML
- from IPython.core.interactiveshell import InteractiveShell
The following settings help in proper formatting and display of the output of code we run.
- warnings.filterwarnings("ignore")
- pd.set_option('max_rows', None)
- pd.set_option('max_columns', None)
- InteractiveShell.ast_node_interactivity = "all"
- display(HTML(data=""""""))
If a particular library is not found, it can simply be downloaded from within the notebook by running a system command pip install sample_library command. For example to install seaborn, run the command from a cell within jupyter notebook like:
! pip install seaborn
Getting and Loading the Dataset
- For this particular text classification problem, we are getting data from Kaggle datasets related to Stock market sentiment classification which can be found here stock market sentiment analysis dataset.
- The dataset is a corpus of tweets that are pulled from Twitter and tagged manually for training models on this tagged variable that we can use for our n-gram model in NLP.
- There is a single dataset CSV file that is to be downloaded and kept in the same location in the place where the jupyter notebook with the code which we run here is there.
Sample data looks like below:
| Text | Sentiment |
|---|---|
| OI Over 21.37 | 1 |
| PGNX Over 3.04 | 1 |
| AAP - user if so then the current downtrend will break. Otherwise just a short-term correction in a med-term downtrend. | -1 |
| Monday's relative weakness. NYX WIN TIE TAP ICE INT BMC AON C CHK BIIB | -1 |
| GOOG - ower trend line channel test & volume support. | 1 |
| AAP will watch tomorrow for ONG entry. | 1 |
Load the dataset here
Summary of the data set
Summary of target variable, We also plot the value counts of the target variable
Text Pre-processing
- Preprocess the text in the corpus: We will clean the text by stripping punctuation and whitespace, converting to lowercase, and removing stopwords, these steps can be generally followed for the n-gram model in nlp.
- Let us also see how to use the spacy NLP library in python to get stop words and them with stopwords from nltk and remove the combined set of stop words on the pandas raw dataset directly
This is to download required libraries from nltk
- import nltk
- nltk.download('punkt')
- nltk.download("stopwords")
- nltk.download('wordnet')
Importy the necessary utilities
- from nltk.corpus import stopwords
- from nltk import word_tokenize, sent_tokenize
Download spacy if it doesn't exist and import the library
Extract list of stop words from spacy
Combine the stop words with the ones from nltk
We will write a function for utilizing the stop words and process them on the pandas data frame column directly for our n gram model in nlp.
Function for cleaning the text
Let us apply the processing functions here
Dataset after pre-processing the text looks like this:
| Text | Sentiment | text_clean |
|---|---|---|
| OI Over 21.37 | 1 | oi 2137 |
| PGNX Over 3.04 | 1 | pgnx 304 |
| AAP - user if so then the current downtrend will break. Otherwise just a short-term correction in a med-term downtrend. | -1 | aap user current downtrend break short-term correction medterm downtrend |
| Monday's relative weakness. NYX WIN TIE TAP ICE INT BMC AON C CHK BIIB | -1 | mondays relative weakness nyx win tie tap ice int bmc aon c chk biib |
| GOOG - ower trend line channel test & volume support. | 1 | goog ower trend line channel test volume support |
Explore the Dataset
We will also do the EDA on the dataset related to the text in the corpus. For understanding the text in the dataset we will look at the distribution of words across different analyses.
Plot the length of the text appearing in the dataset
Output:
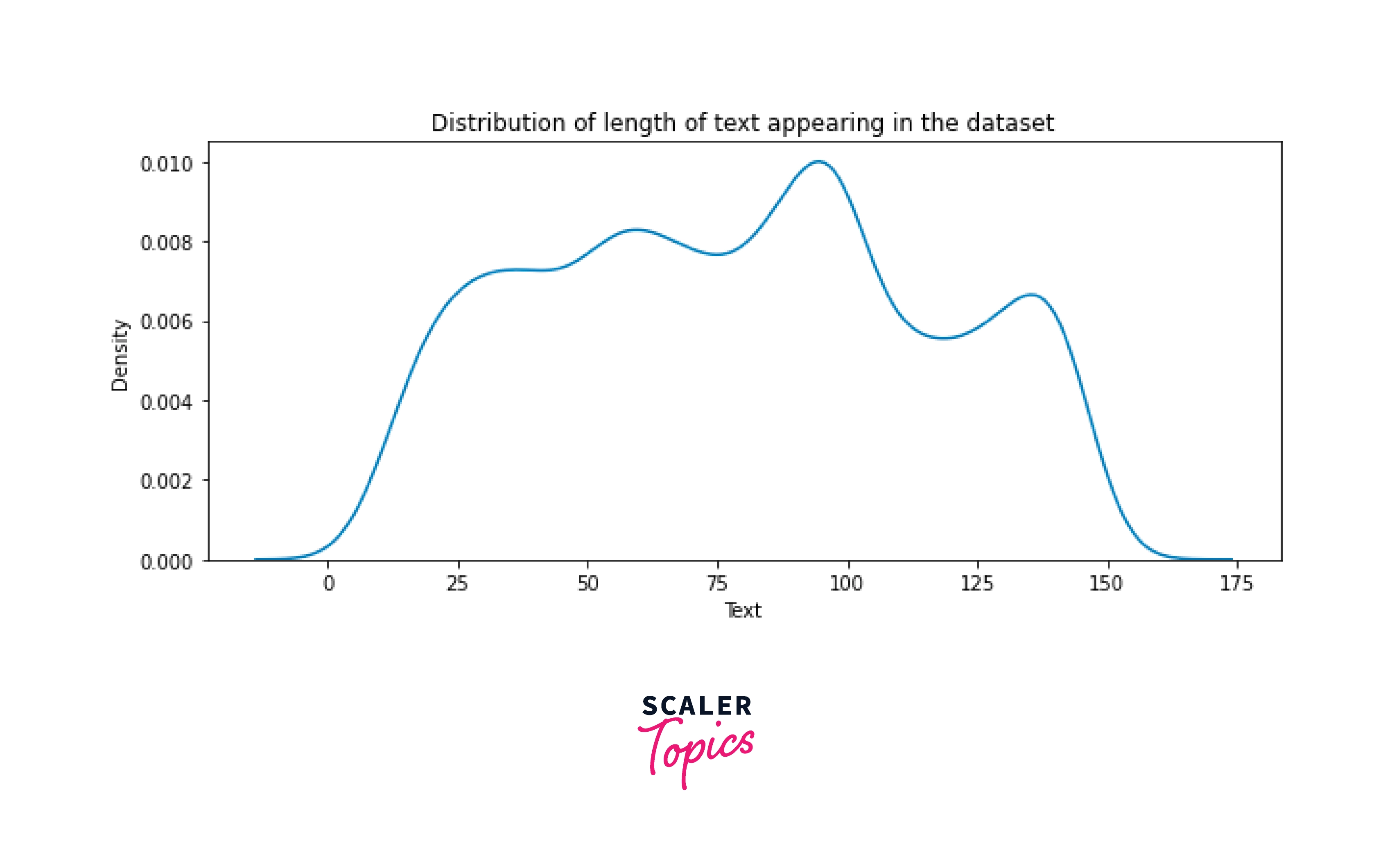
Let us now look at the distribution of words by different sentences in the corpus. Compute the number of words in each line
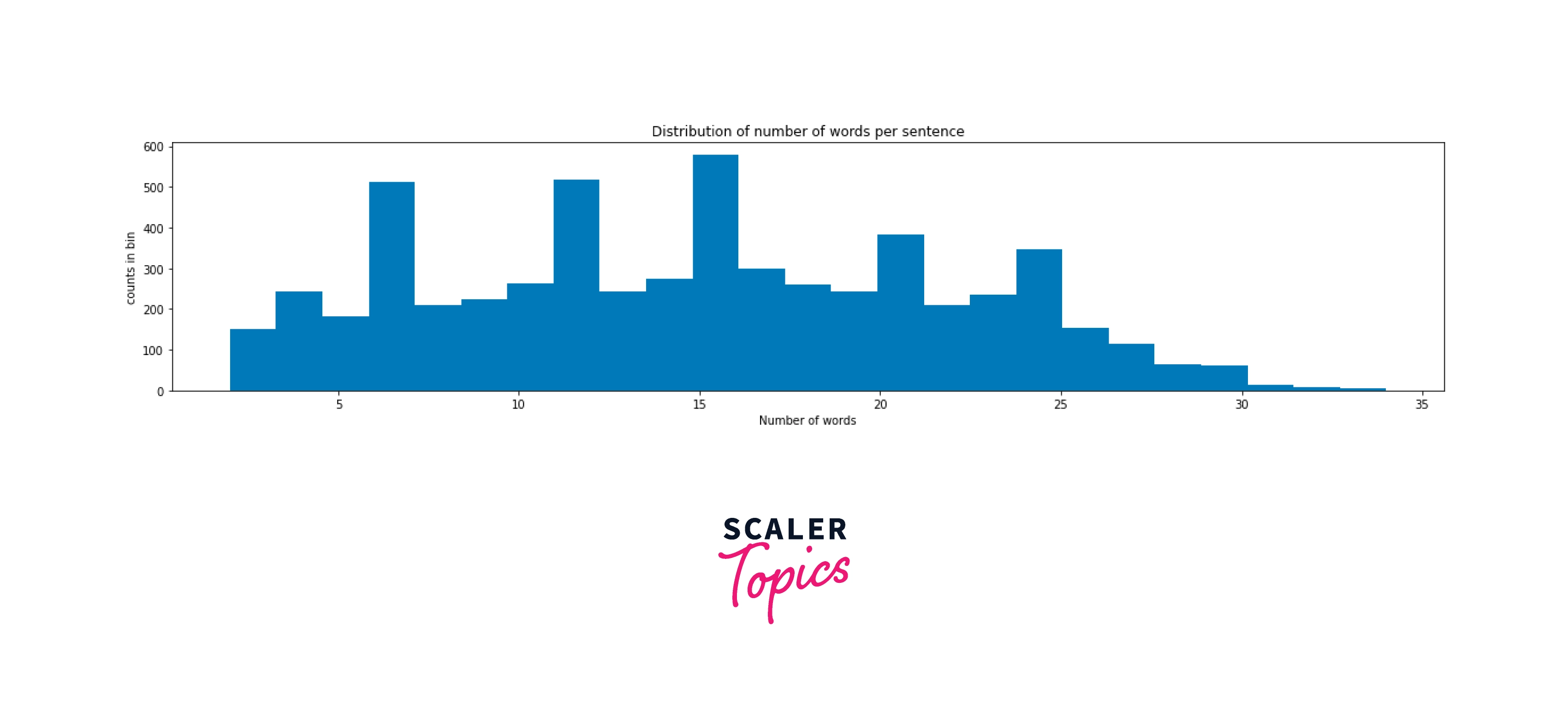
Plot the distribution of the number of words
Output:
Distribution of context vs. number of words
Output:
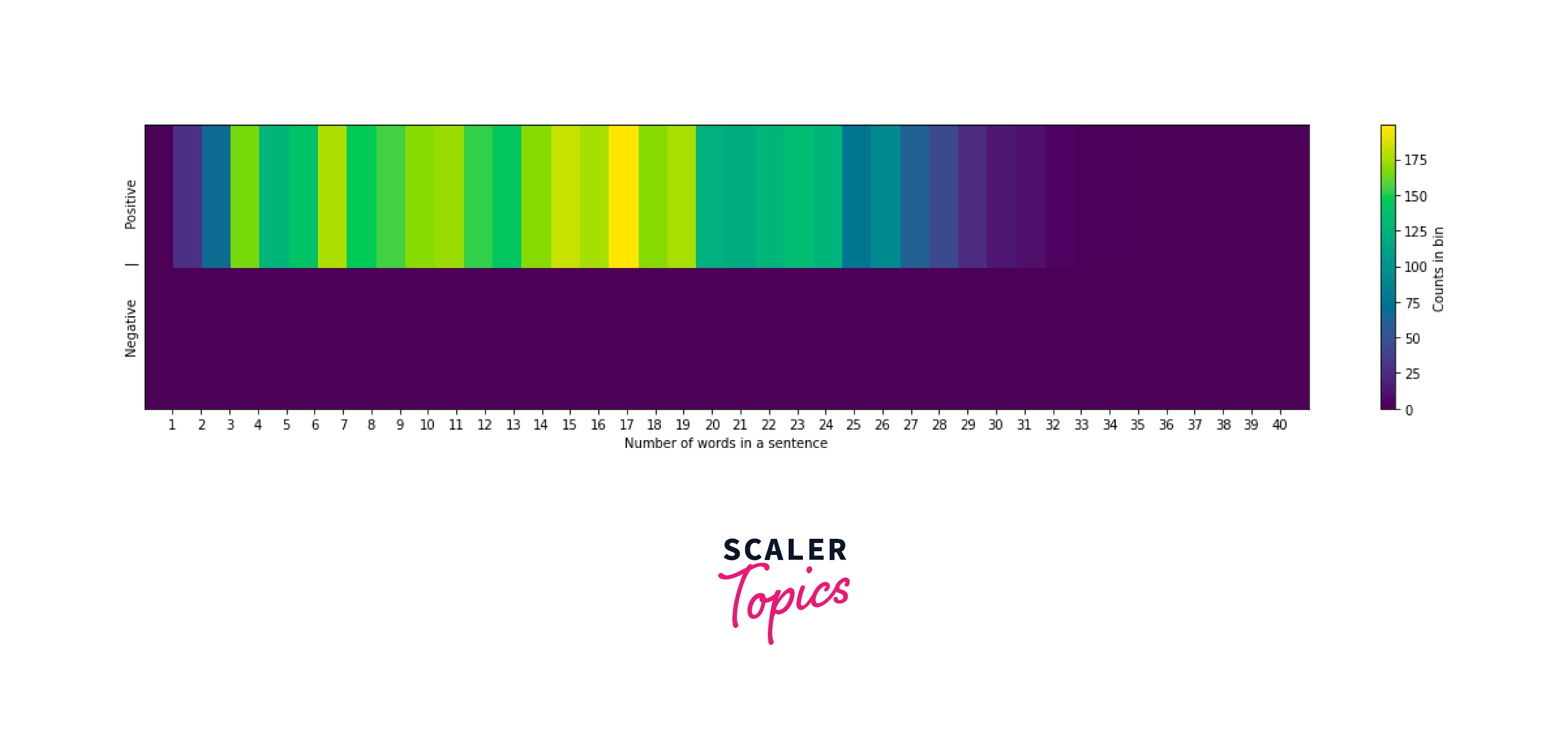
- One main finding from the eda: We can see that positive sentences tend to have more words than negative ones
n-gram Analysis and Visualization
- For understanding the most frequent words we can look at the wordclouds of unigrams and bigrams in our further analysis.
- We will write the Code to generate N-grams: Here let us write a function to extract n-grams and use it to plot top bigrams and trigrams in our raw text corpus.
- nltk also provides the function ngrams. It can be used to determine a set of all possible n consecutive words appearing in a text.
Load the function from the nltk library
- from nltk.util import ngrams
Code for n-grams without using nltk: If we do not want to use the nltk package for generating n-grams, we can use the following function directly on the corpus to generate n-grams of different types for the n-gram model in nlp.
Load the text utilities library
import re
We will Write the function here
Creating Unigrams
- We will generate unigrams and draw the wordclouds to look at the most frequent words. We will then plot for unigrams, bigrams, and trigrams
- We will import the wordcloud library for plotting the word counts. Then We shall check if the library exists, if not we install and import it
Generate the Unigrams
- Here we will tokenize all the words in the corpus and lemmatize them and add to the overall corpus as we iterate over the entire dataframe of raw data.
- We will extract and plot unigrams (or distinct words in the dataset) using wordcloud which is a good visualization for the n gram model in nlp.

Creating Bigrams
Extract and plot bigrams

Creating Trigrams
We can create trigrams simplifying using the function created for trigrams with
Let us now plot the moccurringring trigrams instead of wordclouds for alternative representation.
Load the required library for counting the n-grams (trigramheree).
from collections import Counter
| bigram_text | trigram_text |
|---|---|
| kickers_watchlist watchlist_xide xide_tit tit_... | kickers_watchlist_xide watchlist_xide_tit xide... |
| user_aap aap_movie movie_55 55_return return_f... | user_aap_movie aap_movie_55 movie_55_return 55... |
| user_id id_afraid afraid_short short_amzn amzn... | user_id_afraid id_afraid_short afraid_short_am... |
Train-test Split and Results of the Model
- We will write a function to utilize the vectorizer in different cases and train aasgdclassifier which is a better model for handling high dimensional data like n-gram features and output the performance of the model for comparison.
Load the required libraries and functions
- from sklearn.linear_model import SGDClassifier
- from sklearn.model_selection import train_test_split
- from scipy.sparse import csr_matrix
Let us compare the model with input features for the following different combinations:
- Unigrams, Bigrams, Trigrams individually
- Unigrams & Bigrams, Bigrams & Trigrams , Unigrams & Bigrams & Trigrams as combinations
Initiate the scores list
Unigram model
Bigram model
Trigram model
Unigrams & Bigrams model
Bigrams & Trigrams model
Unigrams & Bigrams & Trigrams combined model
Let us look at sample model performance from the above models:
| Model | Validation |
|---|---|
| Uni | 0.772790 |
| Bi | 0.691298 |
| Tri | 0.662983 |
| Uni-Bi | 0.761050 |
| Tri-Bi | 0.691989 |
| Uni-Bi-Tri | 0.769337 |
From the preliminary models, it can be seen that the unigram models give the best performance along with multi-gram models of 3 grams (unigram plus bigram plus trigram grams models). The model can be further tuned for finding the best hyperparameters of the model and experimenting with other sets of models.
Smoothing
Need for Smoothing: The main purpose of smoothing is to prevent a language model (in particular n-gram models) from assigning zero probability to unseen events and handling out-of-vocabulary words.
- Handling Out-of-vocabulary Words: One of the issues with n-gram language models is out-of-vocabulary (OOV) words, encountered in computational linguistics and natural language processing when the input includes words not present in a system's dictionary or database during its preparation.
- By default, when a language model is estimated, the entire observed vocabulary is used but in some cases, some words can appear in the same context but they may not be in the train set. Smoothing can help assign non-zero probabilities in such cases.
- In some specific cases it may also be necessary to estimate the language models with a specific fixed vocabulary. In such a scenario, the n-grams in the corpus that contain an out-of-vocabulary word are ignored. Still, the n-gram probabilities are smoothed over all the words in the vocabulary even if they were not observed.
- Smoothing is a tool to make the models more generalizable and realistic and prevent overfitting.
Kneser-Ney Smoothing (also known as Kneser-Essen-Ney smoothing): This is a method primarily used to calculate the probability distribution of n-grams in a document based on their histories. The smoothing is done in Kneser-Ney Smoothing by moving some probability towards unknown n-grams from known ones for the n-gram model in nlp.
- It is widely considered the most effective method of smoothing due to its use of absolute discounting by subtracting a fixed value from the probability's lower order terms to omit n-grams with lower frequencies.
- Kneser-Ney Smoothing approach has been considered equally effective for both higher and lower-order n-grams.
Example for Kneser-Ney Smoothing: One common example used to demonstrate the efficacy of Kneser-Ney smoothing generally is the phrase San Francisco. Let us say that this particular phrase is abundant in a given training corpus we used.
- Let us also consider an example context: I can’t see without my reading ____. By common sense, it is known that the word glasses should fill in the blank.
- But since San Francisco is a common term and the unigram probability of Francisco will also be high. If we simply use the absolute frequency of unigram models, then the term Francisco will take over and lead to some strange results in such scenarios.
- Kneser-Ney fixes such oddities by looking at the question of how likely a word is to appear in an unfamiliar bigram context so eventually it outputs such that in the end.
Conclusion
- N-grams are contiguous sequences of n items extracted from a given sample of text or speech where the items can be letters, words, or base pairs as per the application.
- N-grams are combinations of words that come together to express one better meaning from the context of a sentence or snippet of data.
- N-Grams are classified differently according to the number of combinations of words, where they are unigrams when , they are called bigrams when , and are called trigrams when for the n-gram model in NLP.
- N-gram models are widely used in many applications like probability, communication theory, computational linguistics, etc.
- N-grams can also be used as input features for machine learning models, and by experimenting, we can find combinations of n-grams providing the desired accuracy depending on the application domain.
- The goal of smoothing is to prevent overfitting and handling out of vocabulary words in language models.