What is Name Entity Recognition in NLP?
Overview
Name Entity Recognition (NER) is a sub-task of natural language processing (NLP) that involves identifying and classifying named entities in a text into predefined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc. named entity recognition NLP is also used to extract structured information from unstructured text and is a key task in many NLP applications, such as question answering, information retrieval, and machine translation.
Introduction
In today's world, we are constantly generating vast amounts of text data through social media, news articles, emails, and more. While this data contains valuable information, it is often unstructured and easier to analyze with proper processing. Named entity recognition NLP is one tool that can help extract useful information from unstructured text data by identifying and classifying named entities.
Named Entity Recognition (NER) is a subfield of Natural Language Processing (NLP) that focuses on extracting and classifying named entities in text. Named entities are specific terms that represent real-world objects, such as people, organizations, locations, and dates. The named entity recognition NLP model aims to identify and classify these named entities to extract useful information from unstructured text data.
What is Named Entity Recognition (NER)?
As mentioned above, the named entity recognition NLP model identifies and classifies named entities in text. Named entities are specific terms that represent real-world objects, such as people, organizations, locations, and dates. NER aims to extract these named entities from text and classify them into predefined categories.

For example, consider the following sentence: "Barack Obama was born in Hawaii on August 4, 1961."
In this sentence, "Barack Obama" is a person, "Hawaii" is a location, and "August 4, 1961" is a date. We can extract valuable information about Barack Obama's birthplace and birthdate by identifying and classifying these named entities.
Different Blocks Present in A Typical NER Model
A typically named entity recognition NLP model consists of several components, including:
- Tokenization: Tokenization breaks text into individual tokens (usually words or punctuation marks).
- Part-of-speech tagging: Labelling each token with its corresponding part of speech (e.g., noun, verb, adjective, etc.).
- Chunking: Group tokens into "chunks" based on their part-of-speech tags.
- Name entity recognition: Identifying named entities and classifying them into predefined categories.
- Entity disambiguation: The process of determining the correct meaning of a named entity, especially when multiple entities with the same name are present in the text.
Deep Understanding of Named Entity Recognition with An Example
To get a better understanding of how named entity recognition NLP works, let's walk through an example using the following sentence:
"Mark Zuckerberg founded Facebook in 2004 in Menlo Park, California."
- Tokenization: The first step in our NER process is to tokenize the text, which means breaking it into individual tokens. In this case, our tokens would be: ['Mark', 'Zuckerberg', 'founded', 'Facebook', 'in', '2004', 'in', 'Menlo', 'Park', ',', 'California', '.']
- Part-of-speech tagging: We would label each token with its corresponding part of speech. This step might produce the following tags: ['NNP', 'NNP', 'VBD', 'NNP', 'IN', 'CD', 'IN', 'NNP', 'NNP', ',', 'NNP', '.']
- Chunking: Using the part-of-speech tags, we can now group the tokens into "chunks" based on their tags. In this case, we might have the following chunks: [('Mark', 'NNP'), ('Zuckerberg', 'NNP'), ('founded', 'VBD'), ('Facebook', 'NNP'), ('in', 'IN'), ('2004', 'CD'), ('in', 'IN'), ('Menlo', 'NNP'), ('Park', 'NNP'), (',', ','), ('California', 'NNP'), ('.', '.')]
- Named entity recognition: Using the information from the chunking step, we can now identify and classify the named entities in the text. In this case, we have two named entities: "Mark Zuckerberg" and "Facebook", both of which are people, and "Menlo Park, California", which is a location.
- Entity disambiguation: In this step, we would determine each named entity's meaning. For example, if multiple people have the name "Mark Zuckerberg", we must determine which one is being referred to in the text.
How does Named Entity Recognition Work?
Several approaches can be used to perform named entity recognition NLP models. The most common methods include the following:
- Rule-based methods use a set of predefined rules and patterns to identify named entities in text.
- Statistical methods use a probabilistic framework to identify named entities in a text by training a model on a large annotated text corpus.
- Machine learning methods also use probabilistic frameworks but rely on Machine Learning algorithms to learn the patterns in the data.
- Once the model is trained, we can identify named entities in a new text by applying the learned patterns and features.
- Machine learning-based methods tend to be more accurate and scalable than rule-based methods, but they require more labeled training data.
How can I use NER Model?
Depending on your specific needs, there are many ways to use a named entity recognition NLP model. Some common use cases include:
- Extracting contact information from emails or online forms: NER can extract contact information like names, phone numbers, and email addresses from emails or online forms.
- Analyzing customer feedback: NER can classify customer feedback by extracting product names and classifying the feedback as positive, negative, or neutral.
- Summarizing news articles or social media posts: NER can extract key information from news articles or social media posts, like main actors, locations, and events, to generate automatic summaries.
- Identifying named entities in legal documents: NER can extract important information from legal documents, such as contracts and agreements, by identifying the names of people, organizations, and locations.
These are a few examples, but NER can also be used in many other applications, such as improving search results, extracting structured data from resumes, and more. It is a powerful tool for making sense of unstructured text data and leveraging it for various applications.
Use-cases of Named Entity Recognition
Named Entity Recognition NLP models (NER) have a wide range of applications in various industries, including:
- Healthcare: Named Entity Recognition NLP models can extract patient information and diagnoses from medical records and identify drugs and treatments mentioned in the text.
- Cyber Security: NER can be used in cyber security to extract and classify entities such as IP addresses, URLs, and file names from security logs, network traffic, and other sources, which can help to identify and track cyber threats.
- Finance: NER can extract financial information from news articles, financial reports, and other text sources.
- Marketing: NER can analyze customer feedback and identify common themes or issues.
- Human Resource: NER can extract important information from resumes and job postings, such as job titles, names, and qualifications, which We can use to automate the recruiting and hiring process.
- Legal: NER can be used to identify named entities in legal documents for analysis and summarization.
- Education: NER can be used to extract important information from educational materials, such as named entities, concepts, and topics covered in the text, which can help to index, organize and search the educational materials and also help the students to search the information related to their queries.
How to Implement a NER Model
Depending on your needs and resources, there are many ways to implement a named entity recognition NLP model. Some popular tools and libraries for implementing NER include: Stanford NER: A Java-based NER toolkit developed by Stanford University.
- spaCy: A Python library for NLP tasks, including NER.
- NLTK: A Python library for NLP tasks, including NER.
- OpenNLP: An Apache-licensed NLP library written in Java.
Here is an example of implementing a simple Named Entity Recognition NLP model using the Python library spaCy. This example assumes you have installed spaCy and downloaded the necessary model files.
Output
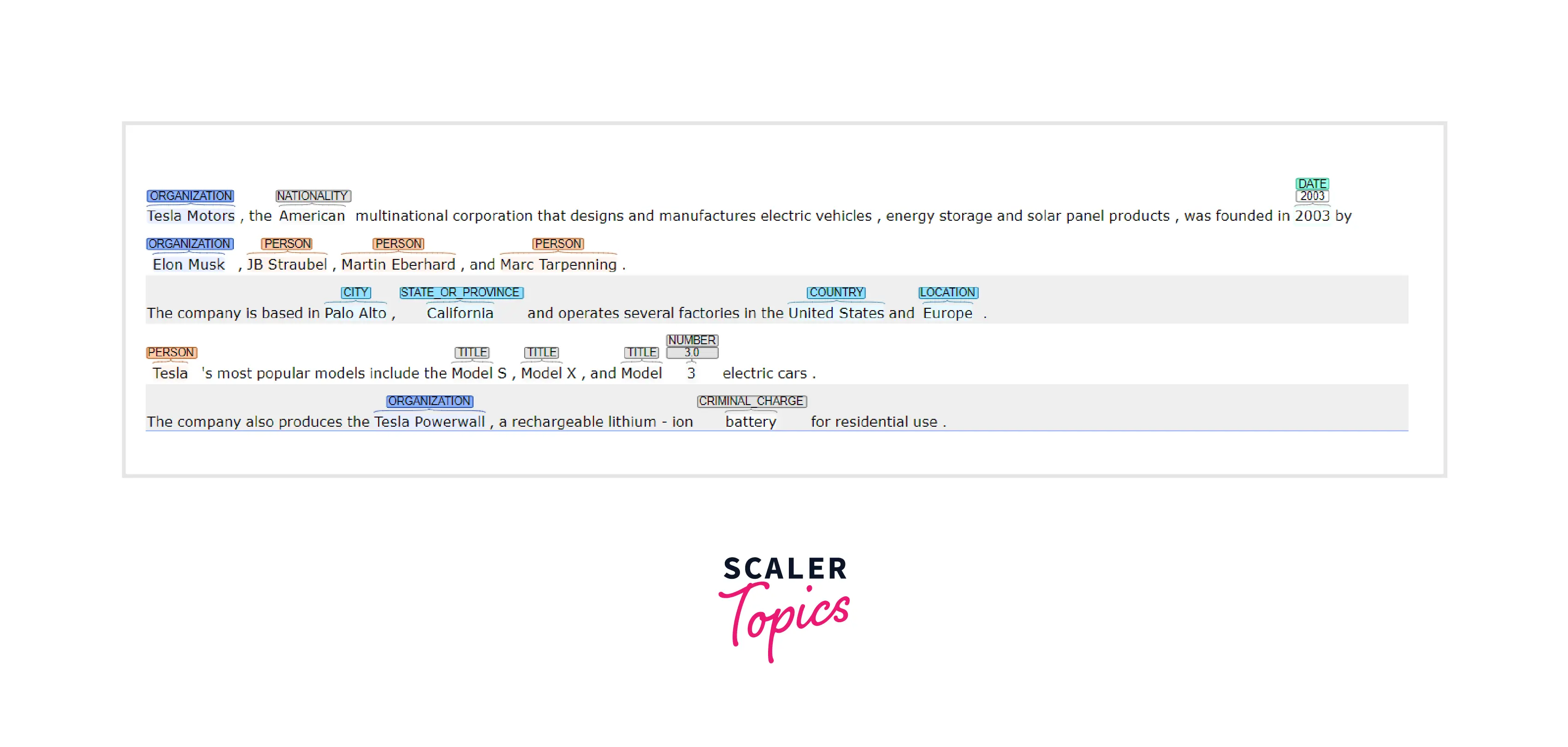
This code loads the en_core_web_sm model, a small English model supporting the named entity recognition NLP model. It then processes a sample sentence using the model and prints the text and label of each named entity in the document.
This example contains named entities such as "Tesla Motors" (organization), "American" (Nationality), "Elon Musk" (person), "Palo Alto" (location), "Model S, Model X, and Model 3" (Product), "Tesla Powerwall" (Product) and "United States, Europe" (Location). NER model will extract all these named entities, classify them and make the text more structured.
Conclusion
- In summary, Named Entity Recognition NLP is a valuable tool for extracting and classifying named entities in text data.
- We can use it in various industries and applications, and many tools and libraries are available for implementing a named entity recognition NLP model.
- By identifying and classifying named entities, we can extract valuable information from unstructured text data and use it for various purposes.