Applications of Transformers
Overview
The transformers module uses the pipeline API to execute inference tasks quickly. The transformers have a collection of numerous pre-trained models that can perform tasks on audio, text, vision, etc. With the help of the transformers library, we can apply the state-of-the-art NLP models quite easily. The various NLP transformers applications are tokenization, spell-checking, auto-completion, text summarization, text classification, named entity recognition, etc. Before using the transformers library, we first need to install it as it is an external library without the Python interpreter.
Pre-requisites
Before learning about the NLP transformers application, let us learn some basics about NLP itself.
- NLP stands for Natural Language Processing. In NLP, we analyze and synthesize the input, and the trained NLP model then predicts the necessary output.
- NLP is the backbone of technologies like Artificial Intelligence and Deep Learning.
- In basic terms, NLP is nothing but the computer program's ability to process and understand the provided human language.
- The NLP process first converts our input text into a series of tokens (called the Doc object) and then performs several operations of the Doc object.
- A typical NLP processing process consists of stages like tokenizer, tagger, lemmatizer, parser, and entity recognizer. In every stage, the input is the Doc object, and the output is the processed Doc.
- Every stage makes some kind of respective change to the Doc object and feeds it to the subsequent stage of the process.
Introduction
As we all know, in the field of NLP, we train the models with the help of some data sets with texts, images, numbers, digits, videos, audio, etc. If we want to perform various methods like tokenization, spell-checking, auto-completion, text summarization, text classification, named entity recognition, etc., we have a very useful Python library named transformers. The transformers library executes numerous tasks of the state-of-the-art models for complex NLP tasks.
With the help of the transformers library, we can apply the state-of-the-art NLP models quite easily. In this article, we will learn how to perform the tasks of the various NLP transformers applications like tokenization, spell checking, auto-completion, text summarization, text classification, named entity recognition, etc., with the help of the transformers module.
The transformers module uses the pipeline API to execute inference tasks quickly. In addition, the transformers have a collection of numerous pre-trained models that can perform tasks on audio, text, vision, etc.
The next section lets us see the various NLP transformers applications.
Applications of Transformers
As previously discussed, the transformers library contains pre-trained models that can perform tasks like tokenization, spell checking, auto-completion, text summarization, text classification, named entity recognition, etc.
So, before getting deep into implementing the various types of transformations, let us first install the transformers library, as it is an external library that does not come up with the Python interpreter.
We can install the transformers library using the below command :
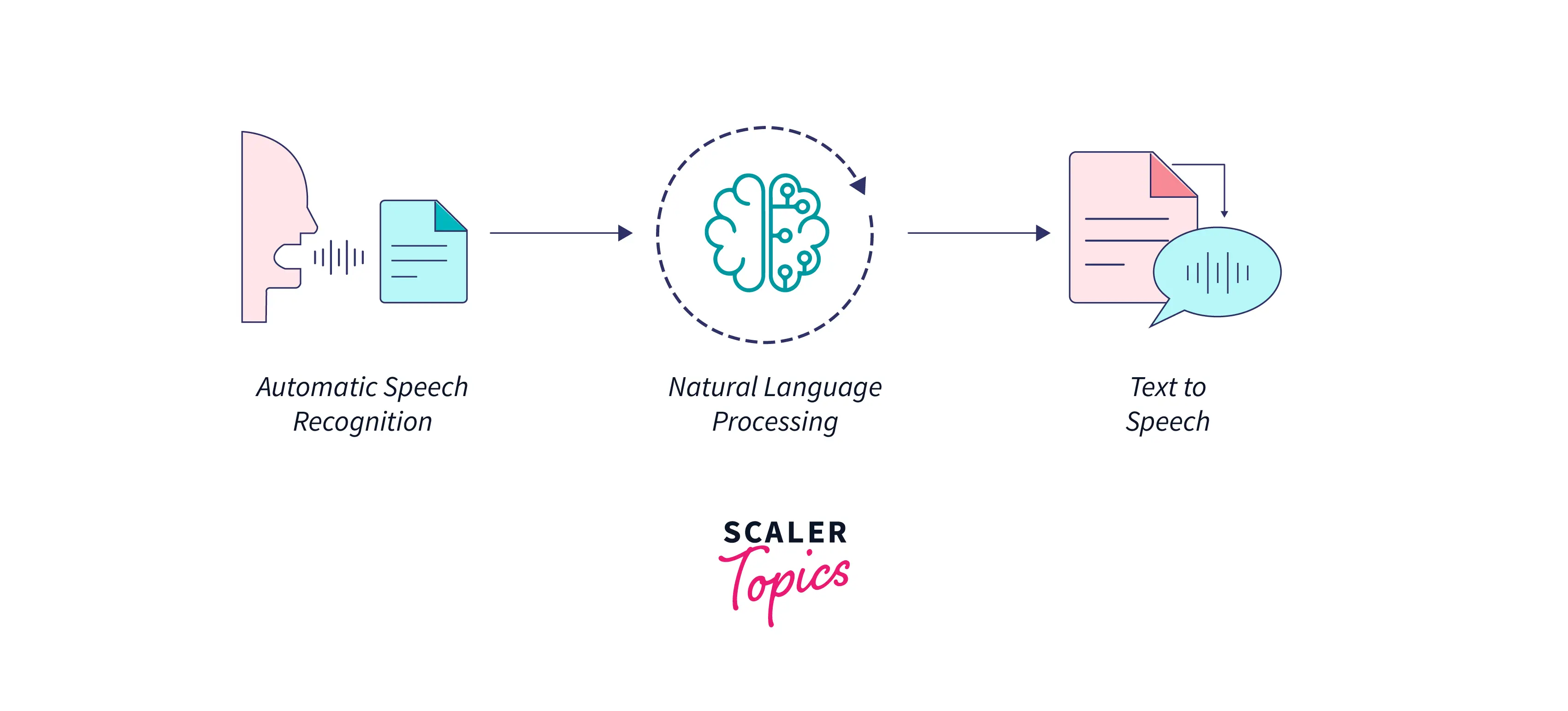
Speech Recognition
Speech recognition is nothing but a program that identifies the words of a user and then converts those words into some readable format text. Speech recognition can also be referred to as the ability of a machine to convert our voice into text. Hence, speech recognition is also known as speech-to-text. We have numerous pre-trained models that can convert human audio into text. They are also trained to work with multiple languages. Some examples of speech recognition include Google Assistant, Apple Siri, etc.
Speech recognition consists of four stages mainly :
- Analyzing the audio of the user.
- Breaking the audio into multiple parts.
- Digitalize the audio parts into a machine-readable format.
- Lastly, match the text (converted from audio) using some algorithm to find the result.
We generally deal with acoustic models and language models in the field of speech recognition systems.
Please refer to the image provided below for more clarity.
Text Summarization
The uprooting of the summary generated from the planned text is known as text summarization. Therefore, we must provide the job description and the summarization identifier to initialize the text summarization pipeline.
The arguments that are needed to be passed are :
- text.
- minimum sequence.
- maximum sequence.
Let us see an example for more clarity taken from Wikipedia (Machine Learning).
Code :
Output :
Auto-complete
For auto-completing, we use the fill-mask technique. We pass the fill-mask parameter in the NLP pipelining system. Let us take an example for more clarity where we will provide an incomplete sentence, and our NLP model will use mast_token to complete sentences.
Code :
Output :
Named Entity Recognition
When we say that we are performing the named entity recognition, we assign some entity name (such as I-MISc, I-PER, I-ORG, I-LOC, etc.) to the tokens in the text sequence.
Now for the initialization of the pipeline to perform the named entity recognition, we first need to assign a task identifier to the pipeline. Then we can pass the object as a single stream of text.
Let us see an example for more clarity.
Code :
Output :
Let us now learn and see what these entities mean.
- I-MISC : It stands for Miscellaneous entity.
- I-PER : It stands for a person's name.
- I-ORG : It represents an organization.
- I-LOC : It stands for location.
Question-Answering
If we have some questions in the text and want to find the answer to the provided question, then we can pass the question-answering argument in the pipelining. For example, in the transformers pipeline, we need to find the text context and the problem. Let us take an example for more clarity.
Code :
Output :
Translation
Translation means converting text from one language to another language. One of the most common examples is Google Translator, which we use daily to convert our text into multiple languages. The transformers library internally uses the application of state-of-the-art models to make the language translations.
Now for the language translation, we first perform the pipeline initialization with the help of the original language identifier and the to-be-translated language identifier. So, for example, if we want to perform the translation from French to English, we can use : translation_fr_to_en.
Let us look at the code example for more clarity.
Output :
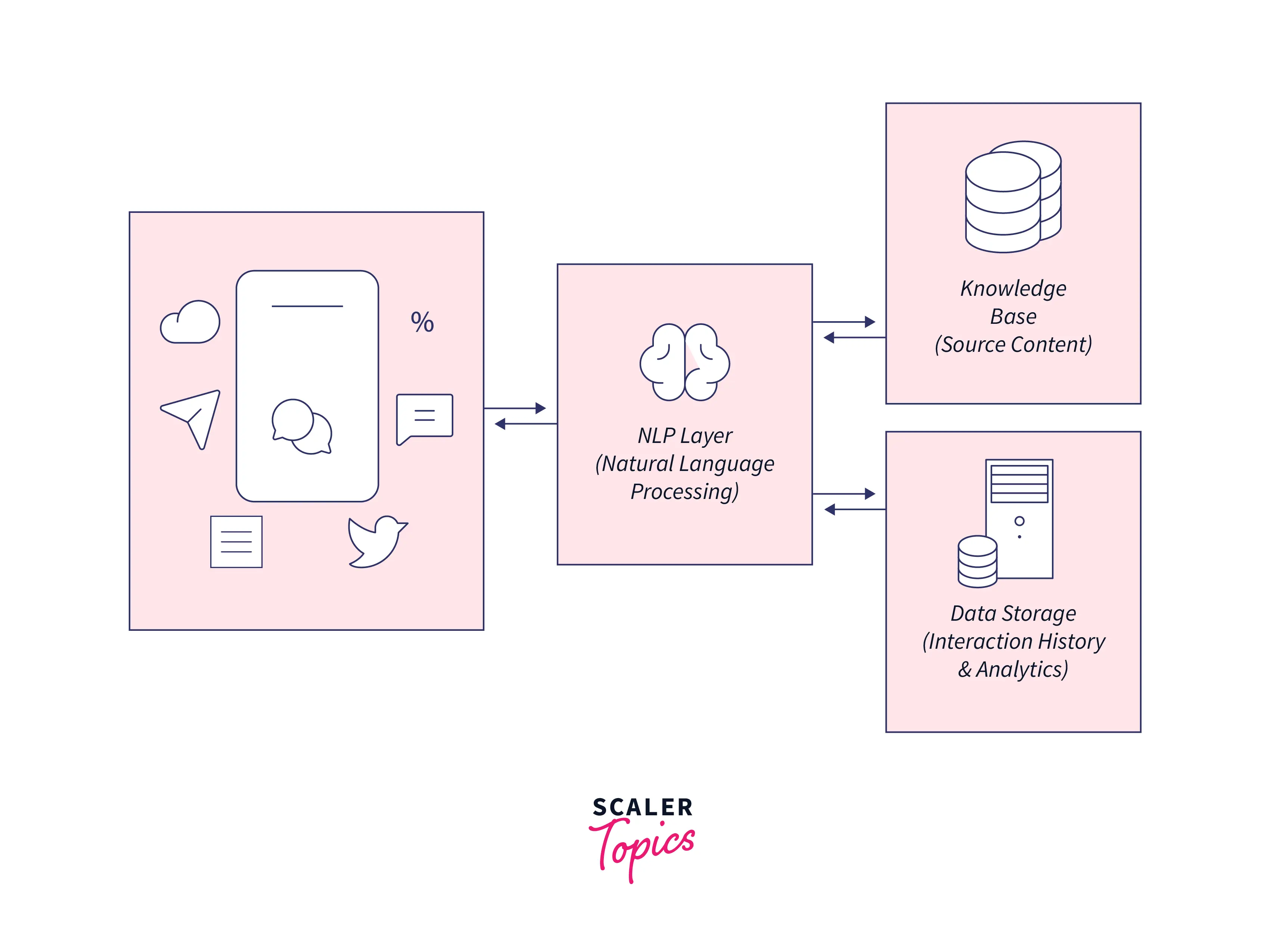
Chat-bots
As we all know, Natural Language Processing is the applied field of Artificial Intelligence, so we can use the power of AI and NLP-trained models to address the users' queries. So, to answer the general queries of the user, we create chatbots for our business; thus, the user gets satisfaction or response.
Chatbots internally use machine learning and NLP models trained with numerous predefined input data sets containing numerous questions and answers that users generally ask. The main aim of using a chatbot for any business is to give a sudden response and solve general queries. If the query is not solved, these chatbots redirect the questions to the customer managing teams.
Please refer to the image provided below for more clarity.
Others
Let us look at other NLP transformers applications like text classification, market intelligence, character recognition, spell checking, etc.
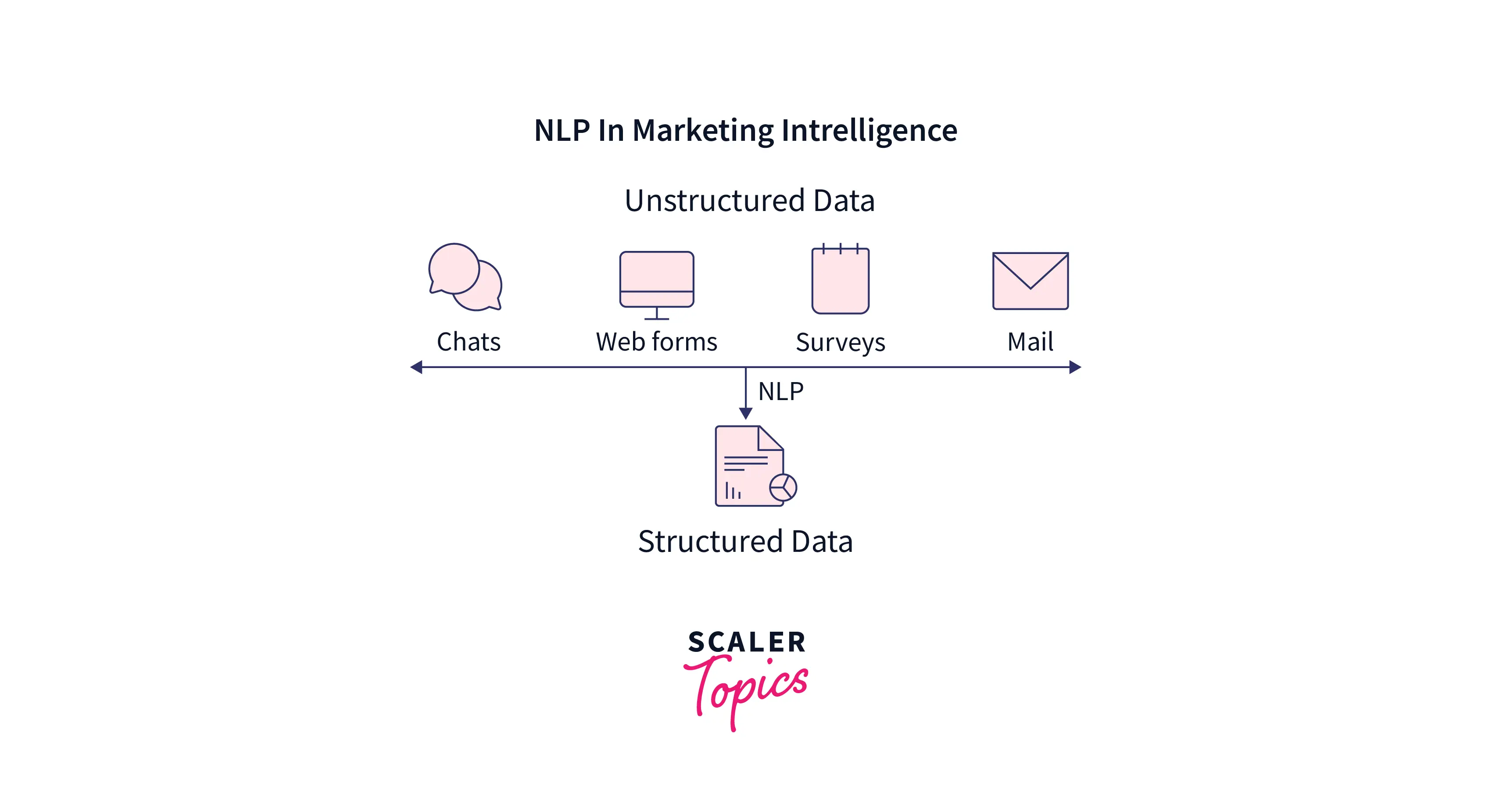
Market Intelligence :
When we collect everyday data relevant to a certain market or a business and then use this data to train the NLP model and finally use the trained model to predict the analytics of the current market is called marketing intelligence.
Marketing intelligence is used to analyze and make decisions using the behavior of competitors, products, markets, customer needs, etc.
Please refer to the image provided below for more clarity. In the below image, we have gathered information from various sources to get the data for market intelligence.
Text Classification :
Text classification in NLP is a process in which we categorize the text into one or more classes so that the text can be organized, structured, and filtered into any parameter. For example, in linear text classification, we categorize the data set into a discrete class depending on the linear combination of its explanatory variables. On the other hand, in non-Linear text classification, we categorize the non-linearly separable instances. For example, an activation function checks whether a neuron of the neural network is still active. In a more theoretical term, this function decides or checks whether the input to a particular neuron is important.
Some of the reasons for using the text classifications are :
- Scalability.
- Consistency.
- Speed.
Some of the most commonly used text classification algorithms are as follows :
- Linear Support Vector Machine
- Logistic Regression
- Naive Bayes
Let us now take an example to understand the working of text classification using the transformers library. For performing the text classification, we need to provide two inputs to the function : the task we want to perform and the model we need to use for executing the task.
Code :
Output :
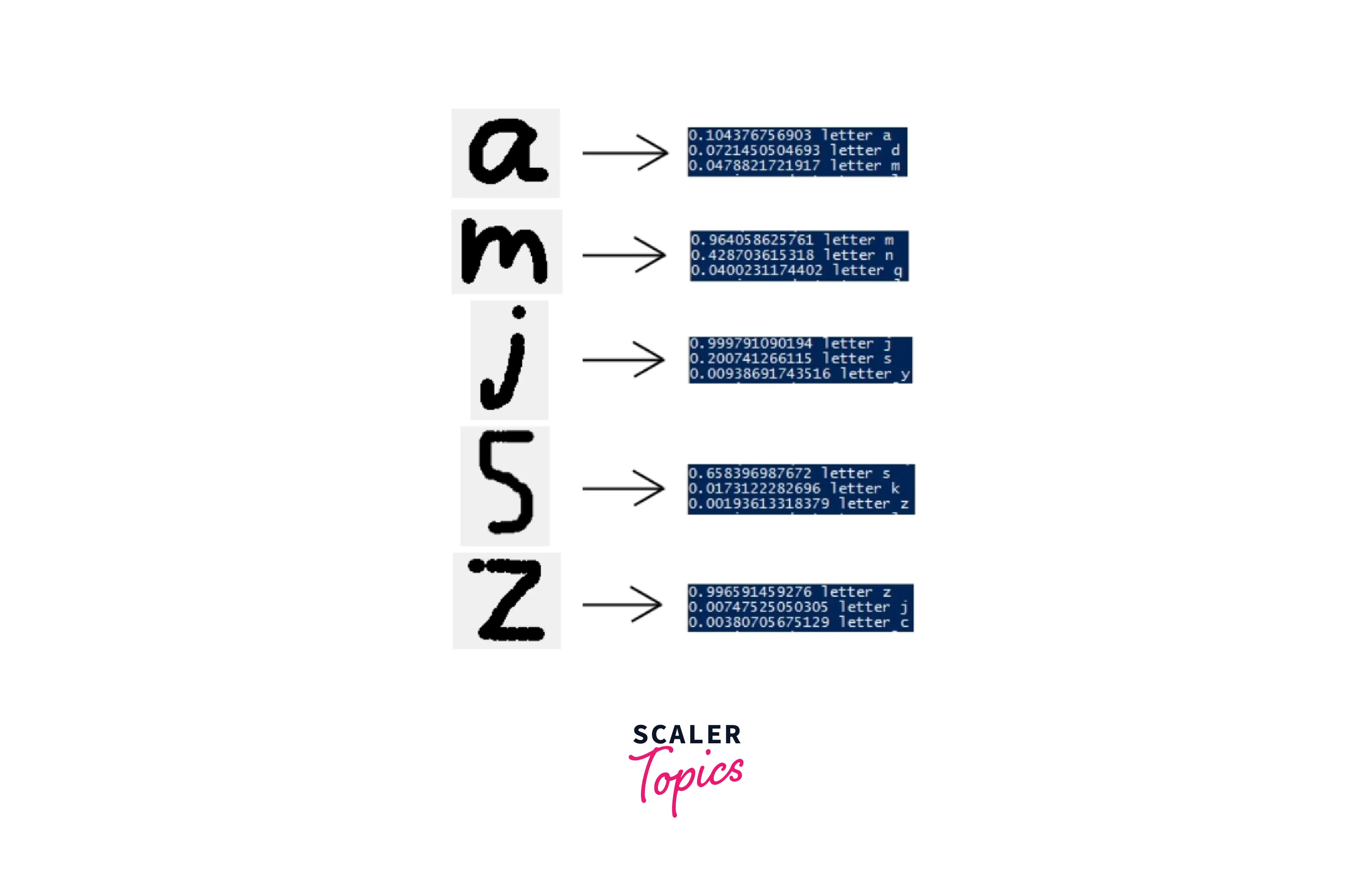
Character Recognition :
The process through which the computer reads and analyzes the text to recognize the characters, numbers, letters, etc., is known as character recognition.
We have several trained NLP models with the help of different types of characters, numbers, and symbols from various languages. These models can be integrated with applications to recognize characters and other symbols from the input text.
Please refer to the image provided below for more clarity. In the below image, we have gathered the probability of a certain character.
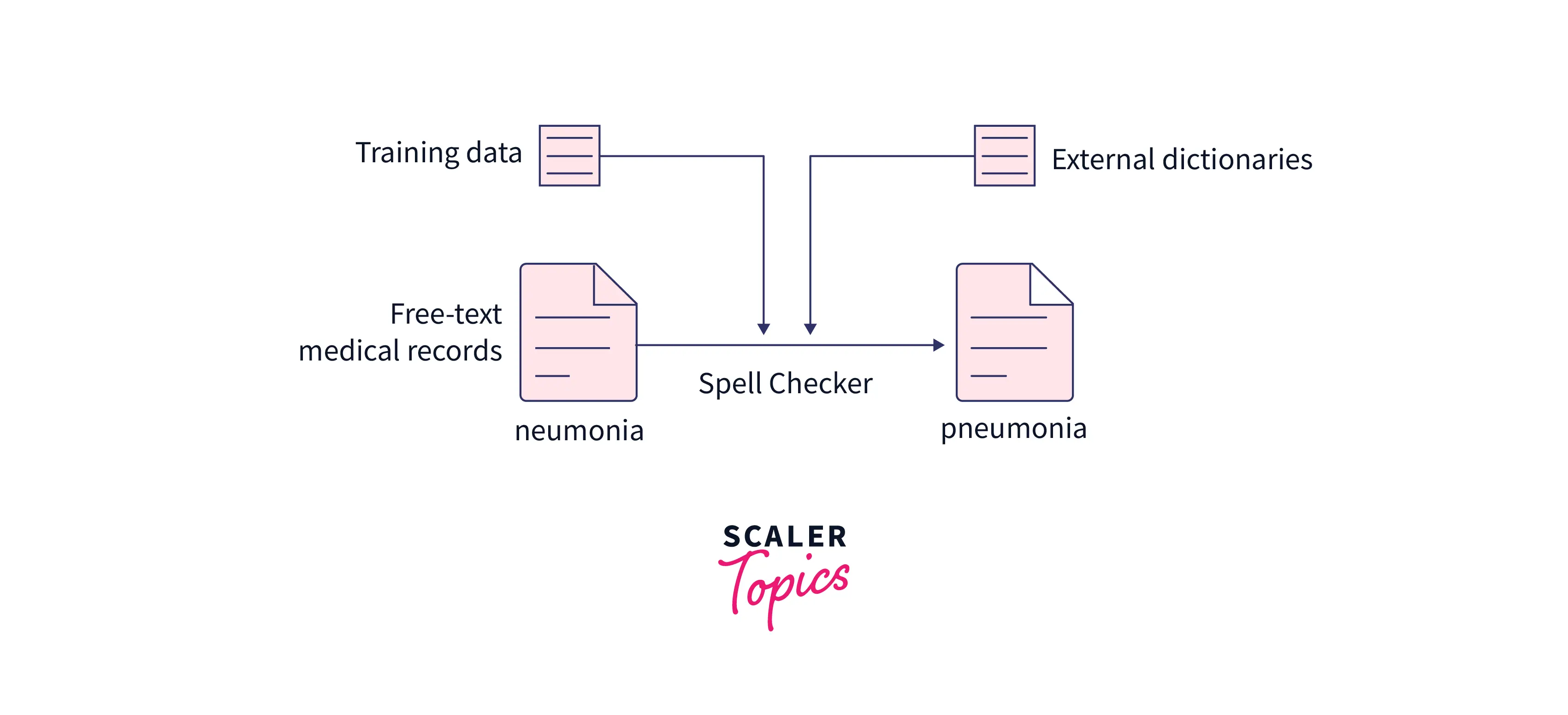
Spell-Checking :
Spell-checking is one of the primary use cases of NLP, where the computer uses the model trained with dictionaries to detect whether the text is correct. One of the prime examples of such a spell checker is Grammarly.
In simpler terms, spell check detects and sometimes provides suggestions for incorrectly spelled words in a text. It compares each word with a known list of correctly spelled words.
Please refer to the diagram provided below for more clarity.
Conclusion
- The transformers module uses the pipeline API to execute inference tasks quickly. In addition, the transformers has a collection of numerous pre-trained models that can perform the tasks on audio, text, vision, etc.
- With the help of the transformers library, we can apply the state-of-the-art NLP models quite easily. The various NLP transformers applications are tokenization, spell-checking, auto-completion, text summarization, text classification, named entity recognition, etc.
- The uprooting of the summary generated from the planned text is known as text summarization. To initialize the pipeline of the text summarization, we need to provide the job description and the summarization identifier.
- For auto-completing, we use the fill-mask technique. Therefore, we pass the fill-mask parameter in the NLP pipelining system. Named Entity Recognition means assigning some entity name (such as I-MISc, I-PER, I-ORG, I-LOC, etc.) to the tokens present in the text sequence.
- Text classification in NLP is a process in which we categorize the text into one or more classes so that the text can be organized, structured, and filtered into any parameter.