Quickstart With Python’s NLTK in NLP
Overview
The NLTK (Natural Language Toolkit) API is the go-to API for Python NLP (Natural Language Processing). It is a very useful tool for preprocessing text data for future analysis, such as using ML models. It aids in the conversion of words to numerical formats, which the machine learning models can then operate with. This is the first installment of a basic introduction to NLTK for getting your feet wet, and it presupposes some basic Python experience.
Introduction
Natural language processing (NLP) is the study of how to make natural human language understandable to computer programs. Natural Language Toolkit (NLTK) is a Python module that can be used for performing various tasks in the NLP space.
A large portion of the data you may be examining is unstructured and comprises human-readable text. You must first preprocess this data before you can analyze it programmatically. In this article, you'll get your first taste of the types of text preparation jobs you can perform with NLTK, so you'll be prepared to use them in future projects. You'll also learn how to perform basic text analysis and produce visuals.
Getting Started With NLTK
Let us now take a look at the tool we will be able to use for our day-to-day natural language programming tasks.
What is NLTK?
NLTK or Natural Language toolkit is an open-source, community-driven project. This tool is used for teaching and working with computational linguistics with Python. It allows you to perform all kinds of natural language processing tasks.
Installation
Before we move on to the multiple functions that NLTK can perform, let's first install the library.
The installation of this library can be done in Python using the package manager - pip. The best practice is to download it in a virtual environment.
To install nltk with pip, write the following code in your shell:
Or simply:
In this tutorial we will also be creating a few visualizations for 'Named Entity Recognition' and you will require the libraries - NumPy and Matplotlib as well. To download these libraries you can make use of the commands - pip install numpy and pip install matplotlib in your shell.
To test the installation of the NLTK library, simply write import nltk. If it throws an error, try re-installation, if not, you're good to go! Let's get started with NLTK and its various functions.
NLP Functions using NLTK
Tokenization
One of the very basic tasks that we would like to perform in a natural language processing use case is to break down our texts into words from sentences. This will allow you to work with smaller chunks of text that are still somewhat cohesive and comprehensible even when taken out of context. It's the initial step toward transforming unstructured data into structured data that can be analyzed more easily.
Now when you tokenize your text, you can tokenize by word or tokenize by sentence. Here's how each helps:
Tokenizing by word: Words are the building blocks of natural language. They are the smallest unit of meaning that can nevertheless be understood on their own. Tokenizing your text by word allows you to detect words that appear frequently. For example, if you were to examine a set of employment advertisements, you may notice that the term "Python" appears frequently. That could indicate a significant demand for Python skills, but you'd have to dig deeper to find out.
Tokenizing by sentence: Tokenizing by sentence allows you to evaluate how words relate to one another and see the additional context. For example, is there a lot of harsh language surrounding the phrase "Python" because the recruiting manager dislikes Python? Are there more phrases that are not from the domain of software development, implying that you may be dealing with a completely different kind of Python than you expected?
To perform the task of tokenization using the Natural Language ToolKit, you must simply import the relevant part of NLTK as follows:
Now to tokenize by sentence, you can use the sent_tokenize(string) function.
Output:
The output of sent_tokenize(), as you can see, has broken down our passage of 4 sentences, and given us as output a list of those 4 sentences.
Let's try tokenizing by word:
Output:
As you can see in the output, the function has returned us a list of all the words present in the text. However, you may be concerned about the punctuation marks. This will have to be dealt with separately. Other tokenizers, such as the PunktSentenceTokenizer, a pre-trained unsupervised ML model, could also be used. If we wish, we can even train it ourselves using our own dataset.
You got a list of strings that NLTK considers to be words, such as:
"sentence" 'tokenize' 'can'
But the following strings were also considered to be words:
"'s" ',' '.'
See how Let's was split at the apostrophe to give you Let's and 's? This happened because NLTK knows that Let and 's (a contraction of “is”) are two distinct words, so it counted them separately.
Filtering Stop Words
Another natural language processing task is the removal of stop words. Stop words are essentially words that you would want to ignore from the text during processing. Very common words like in, is, and an are often considered stop words since they don’t add a lot of meaning to a text in and of themselves.
Here's how to make use of nltk to remove stop words:
Now before you move on to removing stop words, we must first tokenize our text.
Output:
Here, in the remove_stops function, we simply iterated over the tokenized text using a for loop and added all the words that do not stop words into a list. We made use of the casefold() function to ignore whether our words were in upper case or lower case. This is important because the words present in the stop words set are only in lower case. For this task, we could also have used list comprehension which is a faster method for list operations.
Stemming
Another important natural language processing task is Stemming. The idea behind stemming is to reduce words to their root, or the essential portion of a term. For example, the root "help" is shared by the words "helping" and "helper." Stemming allows you to focus on the fundamental meaning of a word rather than the specifics of how it is used. There are other stemmers in NLTK, but you'll be utilizing the Porter stemmer.
Let's take an example:
Output:
Let's compare the output to the original sentence:
| Original Word | Stemmed Word |
|---|---|
| Discovery | discoveri |
| discovered | discov |
| discoveries | discoveri |
| Discovering | discov |
Here we have a few inconsistent results. Why would 'discovery' produce 'discoveri' whereas 'discovering' produces 'discov'?
Understanding and overstemming are two types of stemming errors:
When two related words should be reduced to the same stem but aren't, this is known as understemming. This is an example of a false negative. Overstemming occurs when two unrelated words are reduced to the same stem even though they should not be. This is an example of a false positive.
The Porter stemming algorithm was developed in 1979, hence it is somewhat outdated. The Snowball stemmer, also known as Porter2, improves on the original and is also available through NLTK, so you can use it in your applications. It's also worth mentioning that Porter stemmer's goal is to uncover alternative forms of a word rather than whole words.
Fortunately, there are additional methods for reducing words to their basic meaning, such as lemmatizing, which will be covered later in this article. But first, let's go through the different parts of speech.
Parts of Speech Tagging
Part of speech is a grammatical term that refers to the responsibilities that words play when they are combined in sentences. Tagging parts of speech, often known as POS tagging, is the task of categorizing words in your text based on their part of speech.
There are eight parts of speech in English:
| Part of Speech | Role | Example |
|---|---|---|
| Noun | Person, Thing, Place | Mt. Everest, Laptop, India |
| Pronoun | Used to replace a Noun | He, She, It |
| Adjective | Used to describe a Noun | Colorful, lively |
| Verb | Action or a state of being | is, read |
| Adverb | Describes or gives information about a verb, an adjective, or even another adverb | always, very, efficiently |
| Preposition | Provides information about how a noun or pronoun is related to another word. | at, in, from |
| Conjunction | Connects or joins two phrases or words | and, but, so, because |
| Interjection | Exclamation | Wow, oh, yay |
For articles, NLTK uses the word - determiner. Let's look at how NLTK tags parts of speech.
Output:
You have all the parts of speech tags of every word in a tuple, which seems coded. What do these mean? To find a list of the meanings of these tags (such as PRP, MD, NN, etc) simply write down this line:
This will result in a long list of descriptions of every POS tag with meaning.
Now that you are aware of what every tag means, you can see that the model has tagged every word correctly:
- pie was tagged NN because it is a singular noun.
- you was tagged PRP because it is a personal pronoun.
- invent was tagged VB because it is the base form of a verb.
Lemmatization
Now that you've mastered the components of speech, you can return to lemmatizing. Lemmatizing, like stemming, reduces words to their basic meaning or the root of the word, but it gives you an entire English word that makes sense on its own rather than simply a fragment of a word like 'discoveri'.
A lemma is a word that represents an entire set of words, which is referred to as a lexeme. If you were to seek up the word "blending" in a dictionary, you would need to look at the entry for "blend," but "blending" would be listed in that entry. The lemma in this case is blend, and blending is part of the lexeme. By lemmatizing a term, you are reducing it to its lemma.
Here's how we can implement Lemmatization using NLTK.
Output:
The result of the word 'scarves' was a scarf which is easy to derive since the lemma of this word is similar to the word itself. What about different words that are not too similar to their lemmas? Such as 'worst'?
The output of this would also be 'worst' since the lemmatizer considers this word to be a noun. However this is not the correct root form of the verb, and hence for better accuracy, we can specify that it must be treated as an adjective.
Output:
Now we have the right result! The default input for pos is n for noun, but by adding the value pos="a," you ensured that "worst" was handled as an adjective. As a result, you got 'bad,' which looks nothing like your original word and is nothing like what you'd get if you stemmed it. This is because "worst" is the superlative form of the adjective "bad," and lemmatizing reduces both superlatives and comparatives to their lemmas.
You can try tagging your words before lemmatizing them now that you know how to use NLTK to identify parts of speech to avoid mixing up homographs, or words that are spelled the same but have different meanings and can be separate parts of speech.
Chunking
Chunking is slightly similar to tokenizing. With the help of tokenize, you can extract words or sentences, however, chunking allows you to identify phrases.
This process groups words using part of speech tagging and then applies chunk tags to those groups. Chunks do not overlap and that is why you can find an instance of a word in only one chunk at a time.
Let's look at an example using NLTK:
Now with this block of code, you have part of speech tags. However, to perform chunking you require chunk grammar.
A chunk of grammar is a set of rules that govern how sentences should be chunked. It frequently uses regular expressions or regexes. You don't need to know how regular expressions operate for this article, but they will come in handy in the future if you wish to process text.
Let's create a basic chunk grammar with a simple regular expression rule -
NP here means Noun Phrase, in this grammar, we will create chunks of nouns and phrases. Let's break this grammar down, according to this grammar, the chunks will:
- Start with a determiner ('DT') that is optional (?)
- It can also have any number (*) of adjectives (JJ)
- The grammar ends with a noun (NN)
Now we are going to create a chunk parser using this grammar.
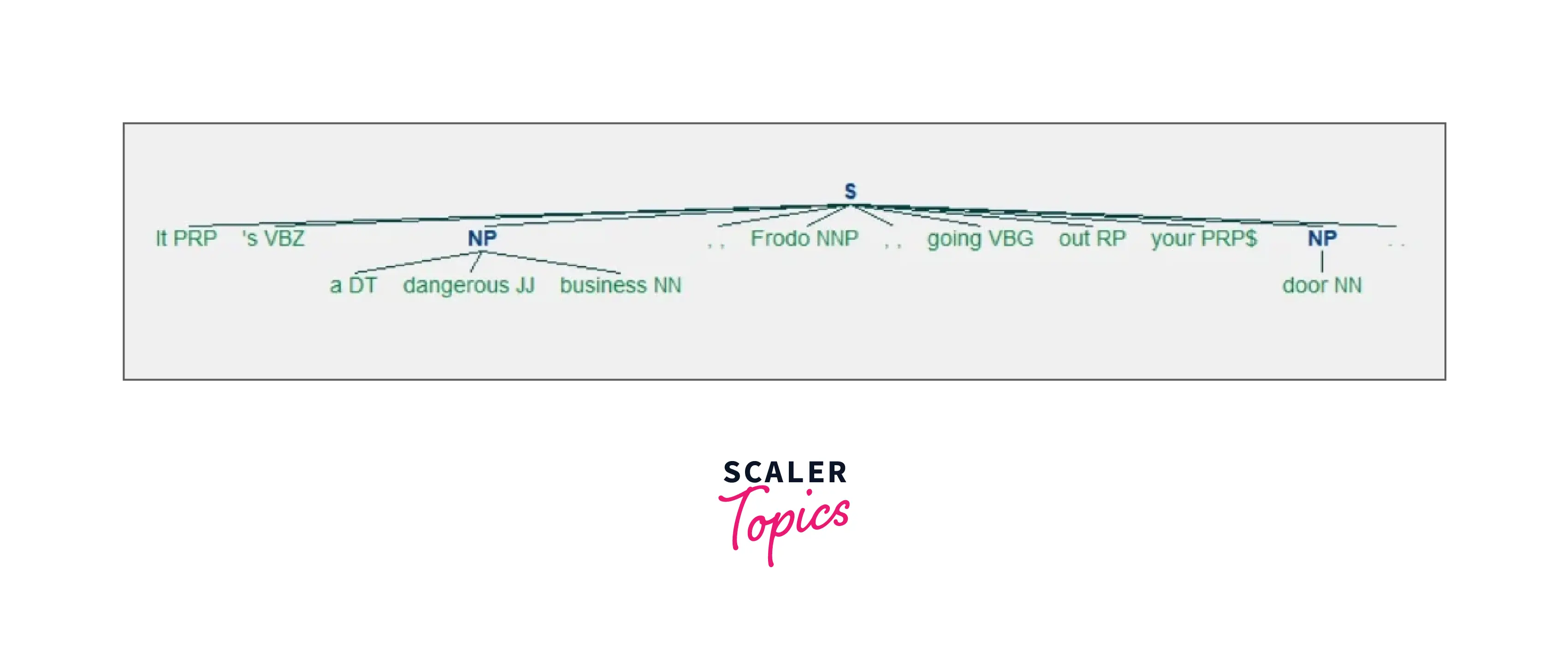
In this output as you might see, you got as output 2 NP phrases - a dangerous business (which has all three - article, noun, adjective), door (just a noun).
Now that you're comfortable with chunking, let's get to chinking.
Chinking
Chinking is a process that is usually used along with Chunking. With the help of chunking, we can include a pattern, however, with chinking you can exclude a pattern.
Let's reuse the code from our previous example, where we already had part of the speech tags ready for our quote.
The next step is to write a grammar that will help you decide what to include and exclude from your chunks. You'll use more than one line this time because you'll have more than one rule. Because you'll be utilizing multiple lines for the grammar, you'll use triple quotes ("""):
The first rule of grammar in your sentence is {\<.\*>+}. This rule has curly braces that face inward ({}) because it determines which patterns to include in your chunks. You want to include everything in this case: <.*>+.
}\<JJ\>{ is the second rule of your grammar. This rule has curly braces facing outward (}{}) because it determines the patterns you wish to exclude from your chunks. You want to omit adjectives in this case: \<JJ>.
Let's now create the chunk parser with this grammar:
Output:
Here, the word dangerous (JJ) was excluded from our chunks because it is an adjective. Let's also look at the graphic representation:

You've removed the adjective 'hazardous' from your chunks, leaving two chunks that include everything else. The first chunk contains all of the material that appeared before the omitted adjective. The second chunk includes everything after the omitted adjective.
Now that you understand how to eliminate patterns from chunks, it's time to investigate named entity recognition (NER).
Using Named Entity Recognition (NER)
Named entities are noun phrases that relate to specific places, individuals, or organizations. You can use named entity recognition to discover named entities in your text and determine what type of named entity they are.
The following is a list of named entity types from the NLTK book:
| Type of NE | Example |
|---|---|
| ORGANIZATION | WHO, UNESCO |
| PERSON | PM Modi, President Obama |
| LOCATION | India, Oman |
| DATE | February, 2001-02-06 |
| TIME | 2 pm |
| MONEY | 175 crore Indian Rupees |
| PERCENT | 17.8% |
| FACILITY | Stonehenge |
| GPE | South East Asia |
You can make use of nltk.ne_chunk() to recognize the given named entities.
Let us look at the graphical representation:
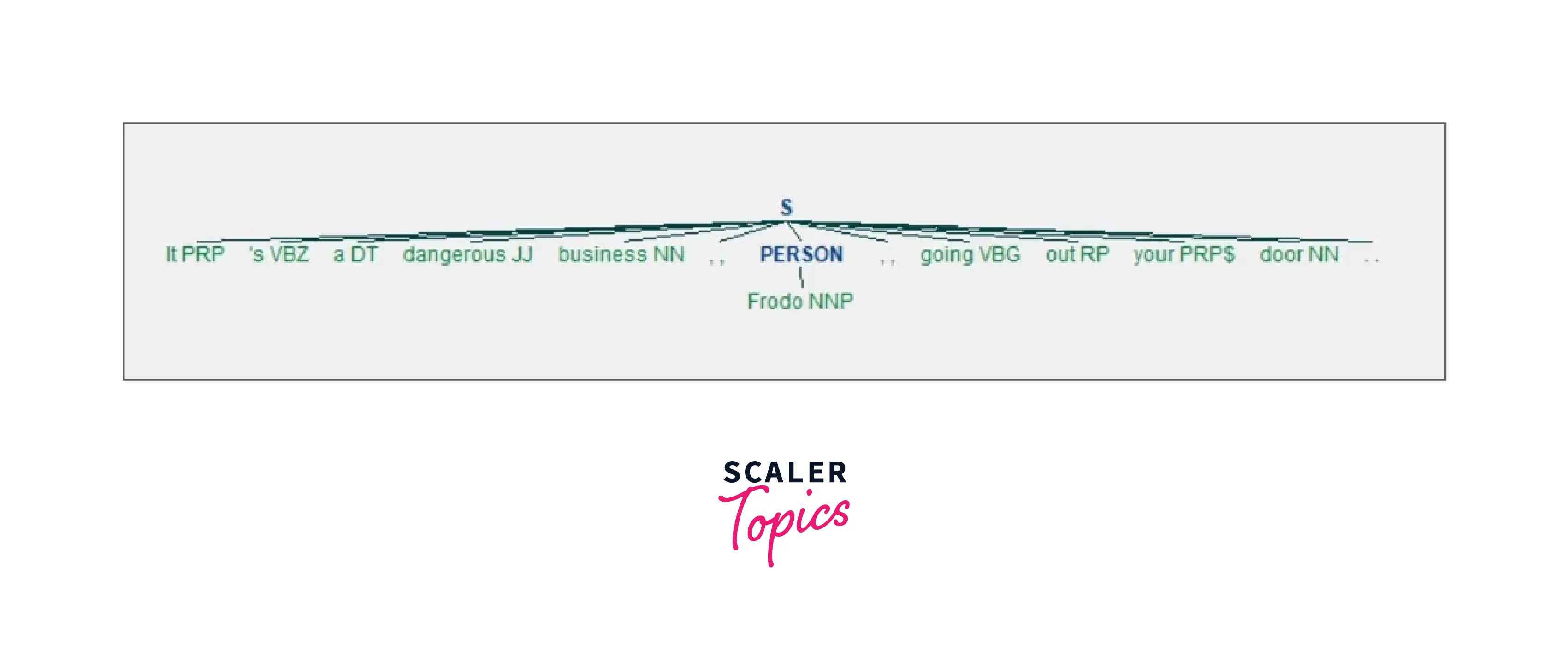
Here you can see that "Frodo" has been tagged as a person (PERSON tag). You can also use the parameter binary=True if you only want to know what the named entities are and not what type of named entity they are:
Here's what you get:
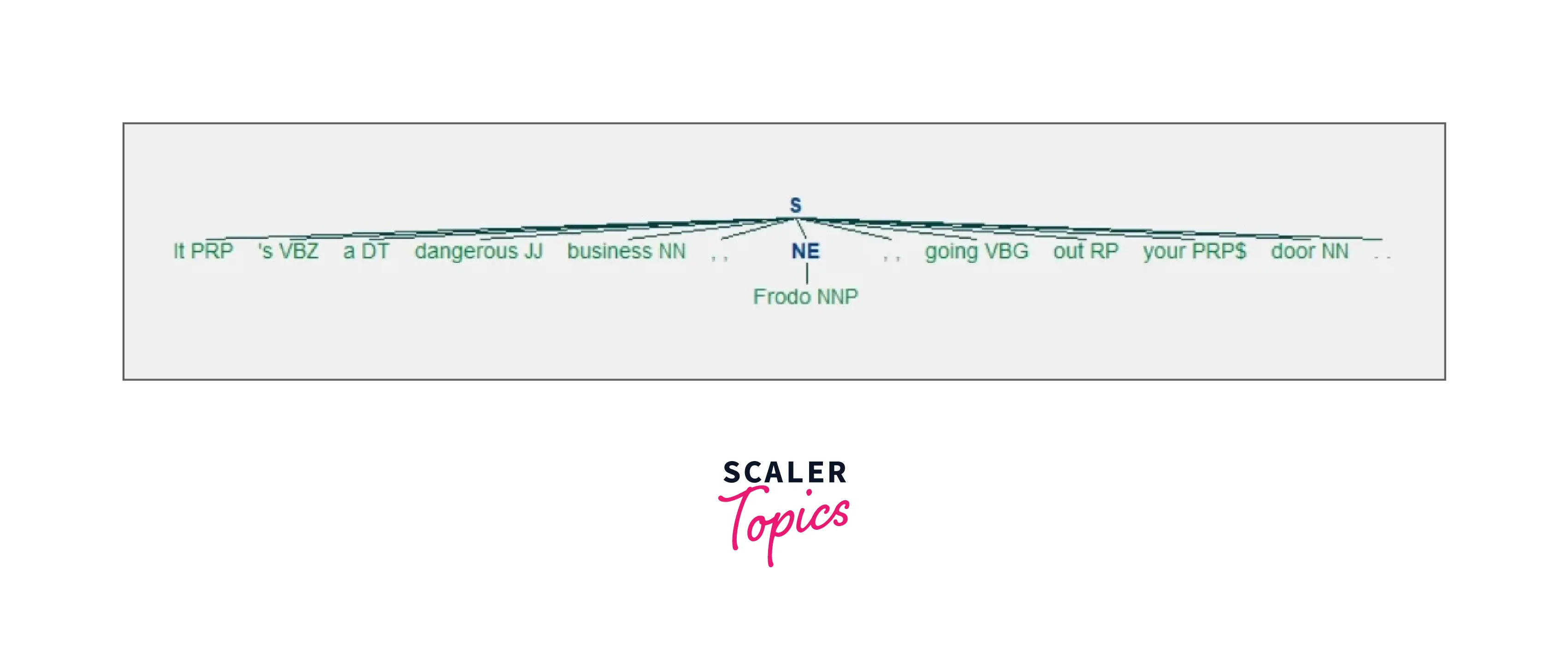
That's how you recognize named entities! However, you may go a step further and extract named entities directly from your text. Make a string from which named entities can be extracted, and test this function out!
This function collects all named entities with no repeats. To do so, you tokenize by word, then apply part of speech tags to those words before extracting named entities based on those tags. Because you specified binary=True, the named things you will receive will not be identified specifically. You'll only notice that they have names.
Using Concordance
A concordance allows you to see each time a word is used, as well as its immediate context. This can provide insight into how a word is utilized in a phrase and what terms are used with it. Now before we get started with using a concordance, we'd have to import some text that can be used for our analysis.
A group of texts - corpus.
NLTK provides you with several texts or corpora and here's how you can download and use them:
Output:
Let's use text8 for our concordance analysis. The personals corpus is called text8, so we’re going to call .concordance() on it with the parameter "woman":
Try it out and see the results. You'll be able to find 11 matches where a woman was used, and the context in which the word was used. Dipping into a corpus with a concordance won't offer you the whole picture, but it can be intriguing to observe what pops out.
You can now perform every basic natural language processing task you want with the help of NLTK!
Conclusion
- Natural Language Toolkit (NLTK) is a Python module that can be used for NLP.
- NLTK or Natural Language toolkit is an open source, community-driven project. This tool is used for teaching and working with computational linguistics with Python. It allows you to perform all kinds of natural language processing tasks.
- Some of the NLP Functions using NLTK are - Tokenization, Stop word removal, Stemming, Part of Speech Tagging, Lemmatization, Chunking, Chinking, Named Entity Recognition, and Concordance.