A Basic Parser in NLP
Overview
A parser in NLP uses the grammar rules (formal grammar rules) to verify if the input text is valid or not syntactically. The parser helps us to get the meaning of the provided text (like the dictionary meaning of the provided text). As the parser helps us to analyze the syntax error in the text; so, the parsing process is also known as the syntax analysis or the Syntactic analysis. We have mainly two types of parsing techniques- top-down parsing, and bottom-up parsing. In the top-down parsing approach, the construction of the parse tree starts from the root node. And in the bottom-up parsing approach, the construction of the parse tree starts from the leaf node.
Introduction
Before learning about the parser in NLP, let us first learn some basics about the NLP itself and grammar as both topics are the backbone for a parser in NLP.
NLP stands for Natural Language Processing. In NLP, we perform the analysis and synthesis of the input and the trained NLP model then predicts the necessary output. NLP is the backbone of technologies like Artificial Intelligence and Deep Learning. In basic terms, we can say that NLP is nothing but the computer program's ability to process and understand the provided human language.
A parser uses the grammar rules (formal grammar rules) to verify if the input text is valid or not syntactically. So, what is grammar? Well, grammar is a set of rules developed to verify the words of a language. Grammar helps us to form a well-structured sentence.
The overall process of a parser is depicted in the diagram shown below.
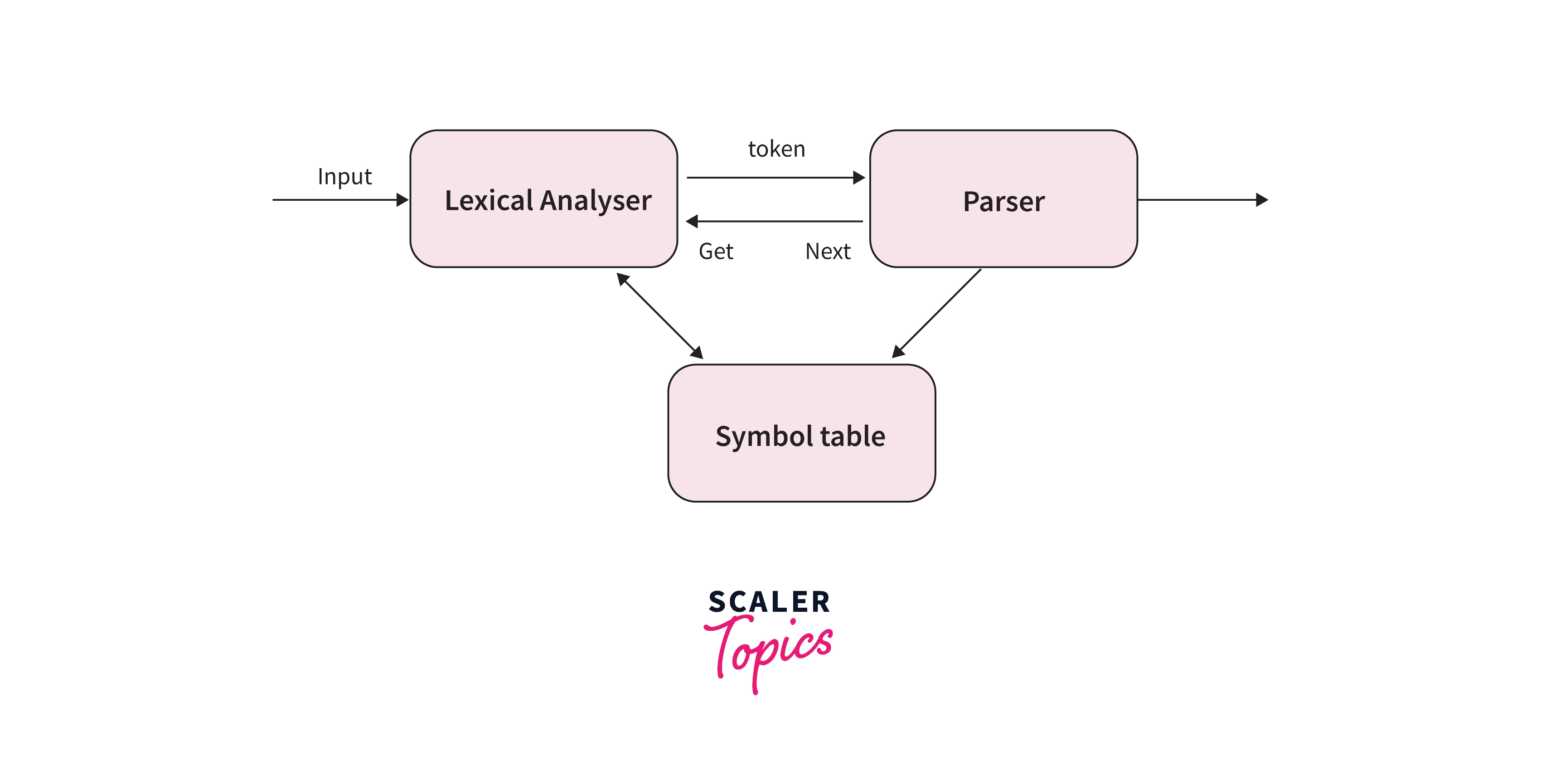
What is Parsing?
The NLP process starts by first converting our input text into a series of tokens (called the Doc object) and then performing several operations of the Doc object. A typical NLP processing process consists of stages like tokenizer, tagger, lemmatizer, parser, and entity recognizer. In every stage, the input is the Doc object and the output is the processed Doc, so, every stage makes some kind of respective change to the Doc object and feeds it to the subsequent stage of the process. The processing of our text (which is termed as Doc) is done in various incremental stages. So, whenever we provide the input text to the NLP, the processing starts by first tokenizing it (converting the text into tokens), and then it is converted into an object namely- Doc.
Now, in all of the above components, the parser plays a very vital role as it reports any kind of syntax error in the text. The parser not only tells us about the syntax errors but also helps us to recover from the most commonly occurring errors so that the processing of the rest of the program does not get halted.
Note: The parser is very important in the world of TOC as well, as it helps to generate the parse tree for the compiler.
The word parsing comes from the Latin word pars which means part. The parser helps us to get the meaning of the provided text (like the dictionary meaning of the provided text). As we discussed that the parser helps us to analyze the syntax error in the text; so, the parsing process is also known as the syntax analysis or the Syntactic analysis.
The syntax analysis uses the formal grammar rules to check the text and if the text follows the rules of grammar then it accepts the text else it rejects the text. For example, if the input text is: Give me hot ice cream.. Then the parser or the syntactic analyzer will reject the text as it does not follow the rules of formal grammar.
The formal definition of a parser in NLP can be a component that process and analyzes the input string of symbols and checks or confirms whether the string is following the rules of the formal grammar or not.
The main functions of a parser are as follows:
- The parser reports to us any syntax error in the syntax of the text.
- The parser helps us to recover from the most commonly occurring errors so that the processing of the rest of the program does not get halted.
- Parser helps in generating the parse tree.
- Parser also helps in creating the symbol table that is used by various stages of the NLP process and thus it is quite important.
- Parses also help in the production of IR or Intermediate Representations.
Let us now look at some of the areas where Parsing plays a vital role in the NLP process.
- Sentiment Analysis.
- Relation Extraction.
- Question Answering.
- Speech Recognition.
- Machine Translation.
- Grammar Checking.
We mainly use two types of parsing namely- deep parsing and, shallow parsing. In shallow parsing, we only pass a limited portion of the entire syntactic information so, it is usually used for the less important or less complex NLP applications. Some of the use cases of shallow parsing are- information extraction, and text mining. On the other hand, in deep parsing, we follow a search strategy that results in the complete syntactic structure of a sentence so, it can be used for complex NLP applications. Some of the use cases of deep parsing are- dialogue systems, and summarization.
The parsing is done in several ways hence we can say that there are several parsers present in the NLP world. Let us look at some of the most commonly used parsers and the subsequent parsing techniques in the coming sections.
Top Down Parsing
The top-down parsing approach follows the left-most derivation technique. In the top-down parsing approach, the construction of the parse tree starts from the root node. So, first, the root node is formed and then the generation goes subsequently down by generating the leaf node (following the top to down approach).
Some of the important points regarding top-down parsing are:
- The top-down parsing uses the leftmost derivation approach to construct the parsing tree of the text.
- The top-down parser in NLP does not support the grammar having common prefixes.
- The top-down parser in NLP also guarantees that the grammar is free from all ambiguity and has followed the left recursion.
We can perform the top-down parsing using two ways:
- Using backtracking.
- Without using backtracking.
The recursive descent parser in NLP follows the top-down parsing approach. This parser checks the syntax of the input stream of text by reading it from left to right (hence, it is also known as the Left-Right Parser). The parser first reads a character from the input stream and then verifies it or matches it with the grammar's terminals. If the character is verified, it is accepted else it gets rejected.
Bottom-up Parsing
The bottom-up parsing approach follows the leaves-to-root approach or technique. In the bottom-up parsing approach, the construction of the parse tree starts from the leaf node. So, first, the leaf node is formed and then the generation goes subsequently up by generating the parent node, and finally, the root node is generated (following the bottom-to-up approach). The main aim of bottom-up parsing is to reduce the input string of text to get the start symbol by using the rightmost derivation technique.
Some of the important points regarding bottom-up parsing are:
- The bottom-up parsing approach is used by various programming language compilers such as C++, Perl, etc.
- This technique can be implemented very efficiently.
- The bottom-up parsing technique detects the syntactic error faster than other parsing techniques.
The bottom-up parsers or LR parsers are of four types:
- LR(0)
- SLR(1) or Simple LR
- LALR or LookAhead LR
- CLR or Canonical LR
Here, the term or symbol L means that we are reading the text from left to right and the symbol R means that we are using the rightmost derivation technique to generate the parse tree.
The Shift-reduce parser in NLP follows the bottom-down parsing approach. The shift-reduce parser finds the sequence of words that is corresponding to the right-hand side of the grammar production and in the scanning, it replaces the sequence of words with the subsequent left-hand side of the production. This approach is followed by the shift-reduce parser until the whole phrase or sentence gets reduced.
Finite-State Parsing Methods
The finite-state parsing methods have evolved in the past two decades and provided us with very interesting studies on Natural Language Processing.
Morphological Parsing and Dependency parsing are some of the most important finite-state parsing methods. In the morphological parsing, we try to find out the morphemes of the provided input word. The morphological parsing helps us to yield important information that is used in NLP applications. In the dependency parsing method, our main aim is to find the linguistic units or words that are related to each other via direct link. This direct link is depicting the dependencies of the words. The NLTK Python package provides us with two ways of performing dependency parsing namely- Probabilistic, projective dependency parsing, and Stanford parsing.
Conclusion
- A parser in NLP uses the grammar rules to verify if the input text is valid or not syntactically. The parser helps us to get the meaning of the provided text.
- As the parser helps us to analyze the syntax error in the text; so, the parsing process is also known as the syntax analysis or the Syntactic analysis.
- The syntax analysis uses the formal grammar rules to check the text and if the text follows the rules of grammar then it accepts the text else it rejects the text.
- In the top-down parsing approach, the construction of the parse tree starts from the root node. And in the bottom-up parsing approach, the construction of the parse tree starts from the leaf node.
- In shallow parsing, we only pass a limited portion of the entire syntactic information so, it is usually used for the less important or less complex NLP applications.
- In deep parsing, we follow a search strategy that results in the complete syntactic structure of a sentence so, it can be used for complex NLP applications.
- In the morphological parsing, we try to find out the morphemes of the provided input word. In the dependency parsing method, our main aim is to find the linguistic units or words that are related to each other via direct link.