Relation Extraction in NLP
Overview
In Natural Language Processing (NLP), Relation Extraction is the subtask of the Information Extraction task, which aims to identify relations between entities and assign them some kind of label or class. For example, given the sentence “Barack Obama was the president of the USA.”, Barack Obama is related to the USA as 'president'. A relation extractor aims at predicting the relationship of the 'president' between these two entities. Relations are one of the most important aspects for building knowledge graphs, which is significant to various NLP applications like summarization, Q&A, search, sentiment analysis, etc.
Introduction
While processing text in NLP for various use cases, once we have identified the named entities, and would like to extract the relationships that might exist among these entities. A relation is usually defined as triplet <entity1, relation_type, entity2>.
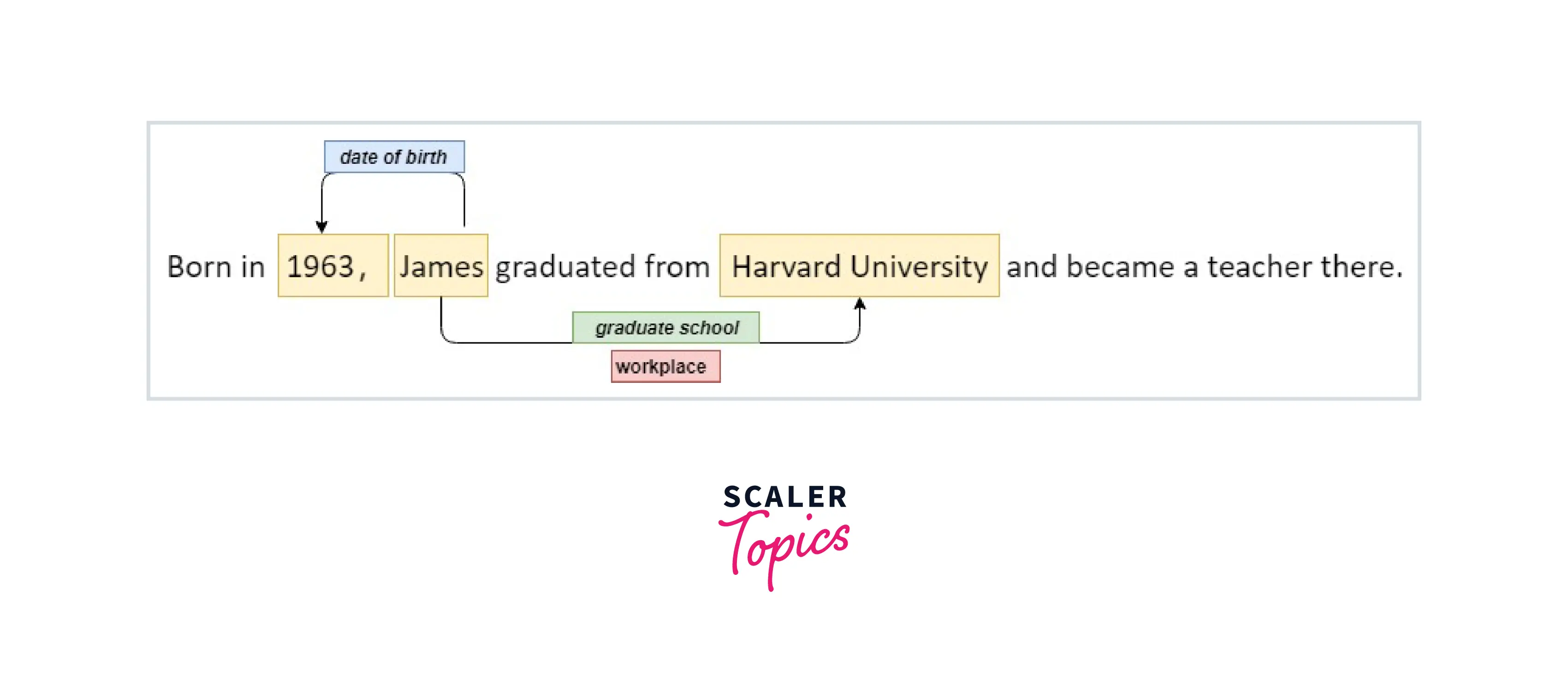
Let's take a very simple example.
Let's take two entities, James and Harvard Univeristy. Given this sentence, the relation between these two entities can be defined as:
Let's take another complex example:
" Twitter is a microblogging and social networking service founded by Jack Dorsey, Noah Glass, Biz Stone, and Evan Williams in the year 2006. Parag Agrawal succeeded Jack Dorsey and was appointed as CEO in November 2021 and was fired in October 2022, along with top executives Chief Financial Officer (CFO) Ned Segal and legal affairs and policy chief Vijaya Gadde when Elon Musk took over in 2022."
In the above example there are many entities being mentioned and we would like to know the relation between them to answer the following questions:
- Who was the founder of Twitter?
- Who purchased Twitter in 2022?
As a first step, all the names of entities need to be identified.
" Twitter[ORG] is a microblogging and social networking service founded by Jack Dorsey[PER], Noah Glass[PER], Biz Stone[PER], Evan Williams[PER] in the year 2006[DATE]. Parag Agrawal[PER] succeeded Jack Dorsey[PER] and was appointed as CEO in November 2021 and was fired in October 2022[DATE], along with top executives Chief Financial Officer (CFO) Ned Segal[PER] and legal affairs and policy chief Vijaya Gadde[PER] when Elon Musk[PER] took over in 2022."
In the next step, the relations can be extracted. Based on the use cases, domains, etc. a set of relations are defined. For example, Any person, irrespective of their role, can be defined as an employee if they work for an organization. Similarly, more relations like founder, owner, investor etc. can be defined.
The goal of relation extraction is to find these relations from the text.
Some entities can have multiple relations as well. Jack Dorsey was the founder as well as CEO of Twitter. His relation can be defined as the founder as well as employee.
Approaches for Relation Extraction
There are many algorithms and approaches for relation extraction, but to limit our scope, we will talk about the three most prominent approaches
- Pattern,
- Supervised and
- Unsupervised.
Patten or Rule Based
The earliest and still common algorithm for relation extraction patterns was first developed by Hearst, and, therefore often called Hearst patterns. Consider the following sentence:
Agar is a substance prepared from a mixture of red algae, such as Gelidium, for laboratory or industrial use. Most human readers will not know what Gelidium is, but they can readily infer that it is a kind of red algae, whatever that is.
The following pattern allows us to infer type-of(Gelidium,red algae)
- NP0 such as NP1{,NP2 ...,(and|or)NPi},i ≥ 1
- for all NPi,i ≥ 1, relation is: type-of(NPi,NP0)
Supervised
In a supervised learning approach, a relation extraction task is defined as a classification task. A training corpus is annotated with the relations and entities, and the annotated texts are then used to train classifiers.
- Find pairs of named entities (usually in the same sentence).
- Apply a relation classification on each pair.
The classifier can use any supervised technique (logistic regression, RNN, Transformer, random forest, neural classifier, etc).
Unsupervised
The goal of unsupervised relation extraction is to extract relations from the text when we have no labeled training data and not even any list of relations. This task is often called Open Information Extraction or Open IE. In Open IE, the relations are simply strings of words (usually beginning with a verb). An example is the ReVerb system developed at the University of Washington's Turing Center, which extracts relation in the following steps.
- Run a part-of-speech tagger and entity chunker over sentence s
- For each verb in s, find the longest sequence of words w that start with a verb and satisfy syntactic and lexical constraints, merging adjacent matches.
- For each phrase w, find the nearest noun phrase x to the left which is not a relative pronoun.
- Find the nearest noun phrase y to the right.
- Assign confidence c to the relation r = (x,w, y) using a confidence classifier and return it.
Let's take an example:
United has a hub in Chicago, which is the headquarters of United Continental Holdings.
ReVerb finds United to the left and Chicago to the right of has a hub in, and skips over which to find Chicago to the left of `is the headquarters of.
The final output is:
Sample code for reverb
Assume that there is a sentence like 'Bananas are an excellent source of potassium'. In this Banana and potassium are related to the phrase source.
Please download and install the reverb software from Github
Conclusion
- Relation extraction is one of the most powerful techniques in NLP.
- It helps make sense of and semantics of the text written in terms of relations.
- We discussed various approaches and saw examples of relation extraction.