Skip-Gram Model in NLP
Overview
The skip-gram model is a method for learning word embeddings, which are continuous, dense, and low-dimensional representations of words in a vocabulary. It is trained using large amounts of unstructured text data and can capture the context and semantic similarity between words.
Introduction
The skip-gram model was introduced by Mikolov et al. in their paper "Efficient Estimation of Word Representations in Vector Space" (2013). The skip-gram model is a way of teaching a computer to understand the meaning of words based on the context they are used in. An example would be training a computer to understand the word "dog" by looking at sentences where "dog" appears and seeing the words that come before and after it. By doing this, the computer will be able to understand how the word "dog" is commonly used and will be able to use that understanding in other ways.
Here's an example to illustrate the concept:
Let's say you have the sentence.
The dog fetched the ball.
If you are trying to train a skip-gram model for the word "dog", the goal of the model is to predict the context words "the" and "fetched" given the input word "dog". So, the training data for the model would be pairs of the form (input word = "dog", context word = "the"), (input word = "dog", context word = "fetched").
Architecture of Skip-Gram Model
The architecture of the skip-gram model consists of an input layer, an output layer, and a hidden layer. The input layer is the word to be predicted, and the output layer is the context words. The hidden layer represents the embedding of the input word learned during training. The skip-gram model uses a feedforward neural network with a single hidden layer, as shown in the diagram below:
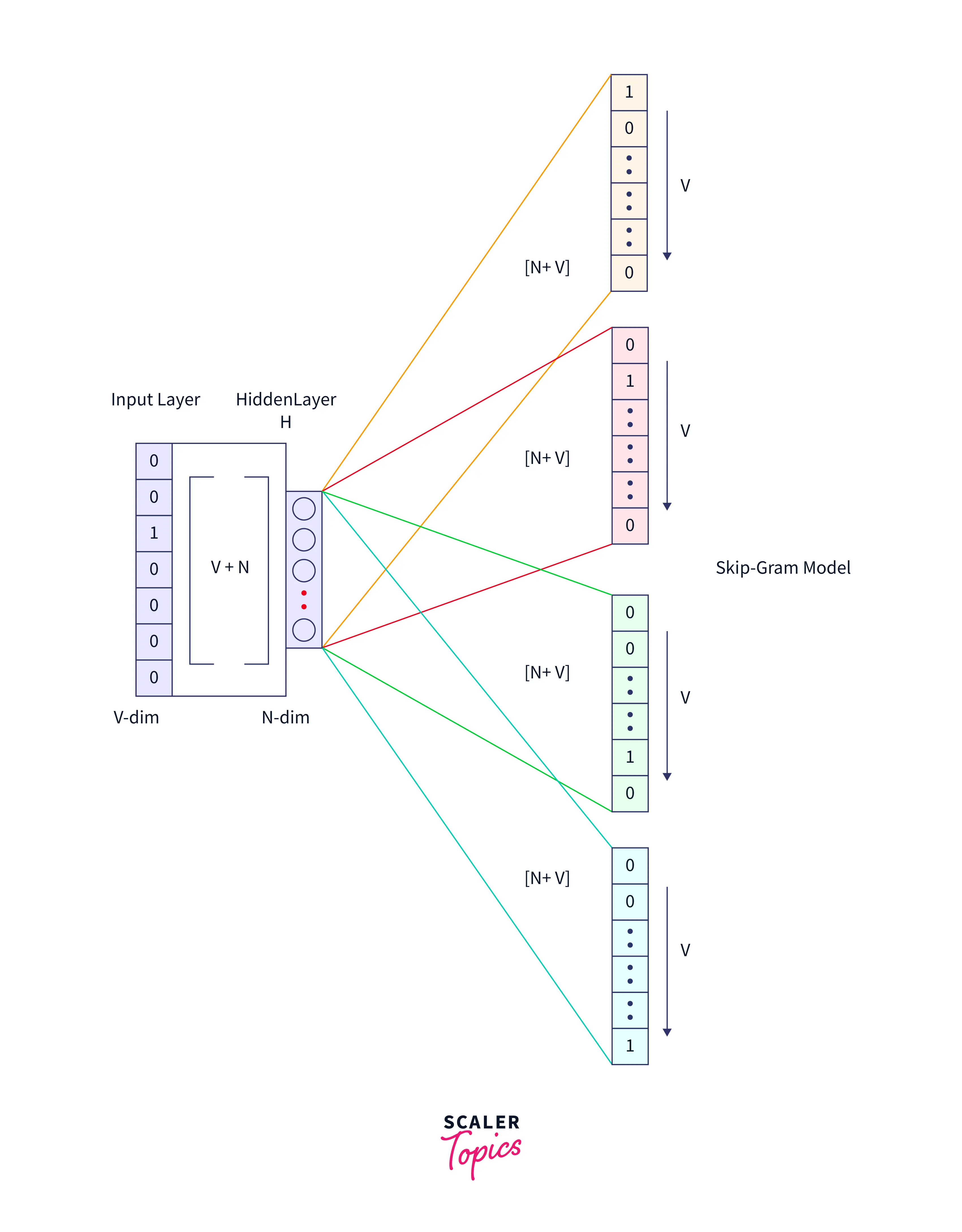
Input Layer --> Hidden Layer --> Output Layer
The input and output layers are connected to the hidden layer through weights, adjusted during training to minimize the prediction error. The skip-gram model uses a negative sampling objective function to optimize the weights and learn the embeddings.
The skip-gram model is a method for learning word embeddings that captures the context and semantic similarity between words in a vocabulary. It is trained using a feedforward neural network with a single hidden layer and is widely used in NLP tasks.
Implementing the Skip-gram Model
To implement a skip-gram model for word embeddings, you will need a large corpus of text in a single language and tools for preprocessing and tokenizing the text. You can download and access the text using the Natural Language Toolkit (NLTK) library.
We can use TensorFlow with the Keras API to build and train the model. A skip-gram generator can create training data for the model in pairs of words (the target word and the context word) and labels indicating whether the context word appears within a fixed window size of the target word in the input text.
The model architecture should include embedding layers for the target and context words and a dense layer with a sigmoid activation function to predict the probability of the context word appearing within a fixed window of the target word. The trained word embeddings can be extracted from the model once trained. The model can then be compiled with a loss function, an optimizer, and fit on the skip grams.
Build the Corpus Vocabulary
Let's preprocess the text of the Bible to create a vocabulary of words that we will use to train the word embedding model. This includes removing punctuation and numbers, lowercasing all the words, and filtering out empty strings and lines with fewer than three words.
Calculate the vocabulary size and the size of the embeddings, which is the length of the dense vector representation of each word. Create a tokenizer and fit it on the normalized text, and create mappings from words to ids and vice versa.
Output
Build a Skip-gram [(target, context), relevancy] Generator
Generate skip grams from the preprocessed text. A skip-gram is a pair of words (the target word and the context word) and a label indicating whether the context word appears within a fixed window size of the target word in the input text. Skip grams are used as training data for the word embedding model.
Output
Build the Skip-Gram Model Architecture
The next step is to define the word embedding model's architecture using Keras's functional API. The model has two embedding layers for the target and context words, which are concatenated and passed through a dense layer with a sigmoid activation function to predict the probability of the context word appearing within a fixed window of the target word.
Output
Train the Model
In order to train the word embedding model on the skip grams we'll use the fit method. The model is trained for a specified number of epochs, the number of times the model sees the entire dataset during training.
Output
Get Word Embeddings
To see results from the model, we first need to extract the trained word embeddings from the word embedding model. The word embeddings are the weights of the embedding layer, which are the dense vector representations of the words in the vocabulary. The shape of the weights tensor is (vocab_size, embedding_size), where vocab_size is the size of the vocabulary and embedding_size is the length of the dense vector representation of each word.
Output
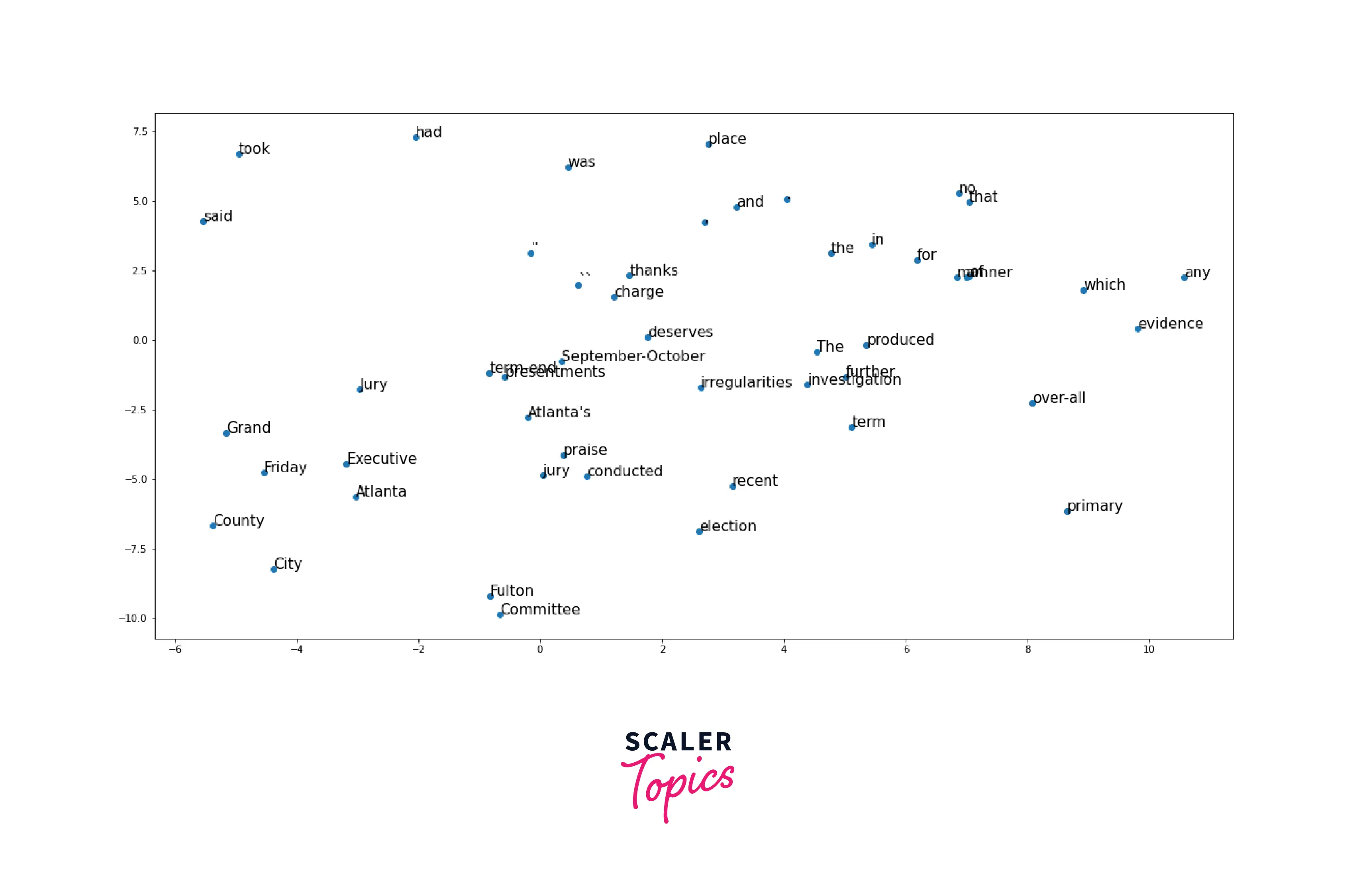
Conclusion
- In conclusion, the skip-gram model is a popular method for generating word embeddings, dense vector representations of words in a vocabulary.
- The skip-gram model takes a large corpus of text as input and trains a neural network to predict the context words that appear within a target word's fixed window based on the text's co-occurrence.
- The word embeddings can be extracted from the weights of the embedding layer in the trained model and can be used as input to other natural language processing tasks, such as text classification, sentiment analysis, and machine translation.
- The skip-gram model has been shown to produce high-quality word embeddings that capture the semantic and syntactic relationships between words in the text, making it a useful tool for a wide range of NLP applications.