Spark NLP
Overview
Between the plethora of existing libraries that could perform natural language processing tasks, the requirement for a library that could do every single NLP task arose. Apache Spark-based natural language processing library - Spark NLP is the module that can perform every single task. Let's take a look at this module.
Introduction
Because of the popularity of NLP and the boom in Data Science in recent years, many amazing NLP libraries have been built, and even beginner data science enthusiasts have begun to experiment with various NLP techniques utilizing these open-source libraries. The most prominent NLP libraries, which have been heavily utilized in the community and are at varying stages of development, are - NLTK (Natural Language ToolKit), TextBlob, SpaCy, Gensim, etc.
These libraries are useful for various NLP tasks such as building a chatbot, searching through a patent database, matching patients to clinical trials, grading customer service or sales calls, extracting facts from financial reports, and so on.
So since we have a good collection of libraries that can perform NLP tasks, what is Spark NLP, and why do we need it?
What is Spark NLP?
Spark NLP is an open-source NLP library built on top of Apache Spark and the Spark ML library. It allows for advanced natural language processing tasks with 3 languages - Python, Java, and Scala. Its goal is to provide an API for natural language processing pipelines that implements cutting-edge academic research into production-grade, scalable, and trainable software. The library includes pre-trained neural network models, pipelines, and embeddings, as well as support for custom model training.
The library covers many common NLP tasks, including tokenization, stemming, lemmatization, part-of-speech tagging, sentiment analysis, spell checking, named entity recognition, and more. The Spark NLP library is written in Scala and has no dependency on any other ML or NLP library.
Before discussing the Spark NLP module in detail, let's first cover the need for this module.
The Need for Spark NLP
Since we already know that there are plenty of libraries that can help with natural language processing tasks, what makes Spark NLP different?
Here are a few reasons:
-
A single unified solution for all the natural language processing needs. For scalable, high-accuracy, and high-performance natural language processing tasks, despite the presence of multiple libraries, there is not a single library that has all. Spark NLP provides a unified solution.
Task Spark NLP SpaCy NLTK CoreNLP Sentence Detection Yes Yes Yes Yes Tokenization Yes Yes Yes Yes Stemming Yes Yes Yes Yes Lemmatization Yes Yes Yes Yes Part Of Speech Tagger Yes Yes Yes Yes Named Entity Recognition Yes Yes Yes Yes Dependency Parse Yes Yes Yes Yes Text Matcher Yes Yes No Yes Date Matcher Yes No No Yes Chunking Yes Yes Yes Yes Spell Checker Yes No No No Sentiment Detector Yes No No Yes Pretrained Models Yes Yes Yes Yes Training Models Yes Yes Yes Yes
Remember that any NLP pipeline is always a subset of a larger data processing pipeline:
Loading training data, converting it, using NLP annotators, constructing features, training the value extraction models, evaluating the results (train/test split or cross-validation), and hyperparameter estimation are all part of question answering. We require an all-in-one solution to alleviate the load of text preprocessing and connecting the dots between different processes of solving a data science challenge using NLP. So, a good NLP library should be able to appropriately turn free text into structured features and allow you to train your NLP models, which can then be readily fed into the downstream machine learning (ML) or deep learning (DL) pipeline.
- A library that takes advantage of transfer learning and implements the latest and greatest algorithms and models present in natural language processing research.
- Lack of any natural language processing library that is fully supported by Spark. As a general-purpose in-memory distributed data processing engine, Apache Spark has garnered a lot of industry attention. It already includes its ML library (SparkML) and a few other modules for specific NLP activities, but it does not cover all of the NLP jobs required for a full-fledged solution. When you try to incorporate Spark into your pipeline, you normally need to use other NLP libraries to complete specific jobs before feeding your intermediary steps back into Spark. However, separating your data processing framework from your NLP frameworks implies that the majority of your processing time is wasted serializing and copying strings back and forth, which is wasteful.
There was a need to have an NLP library with a simple-to-learn API, also available in a programming language of your choice, which was fast, scalable, and included streaming and distributed use cases.
Considering this, John Snow Labs decided to take the lead and develop the Spark NLP library.
Spark NLP Architecture
Moving on to the architecture of Spark NLP. Now since Spark NLP is essentially based on Apache Spark, let's talk about the components of Spark NLP concerning Spark itself.
Because of its capacity to process streaming data, Apache Spark, which was once a component of the Hadoop ecosystem, is now the big-data platform of choice for corporations. It is a sophisticated open-source engine that offers real-time stream processing, graph processing, interactive processing, in-memory processing, and batch processing at high speed, with an easy-to-use interface.
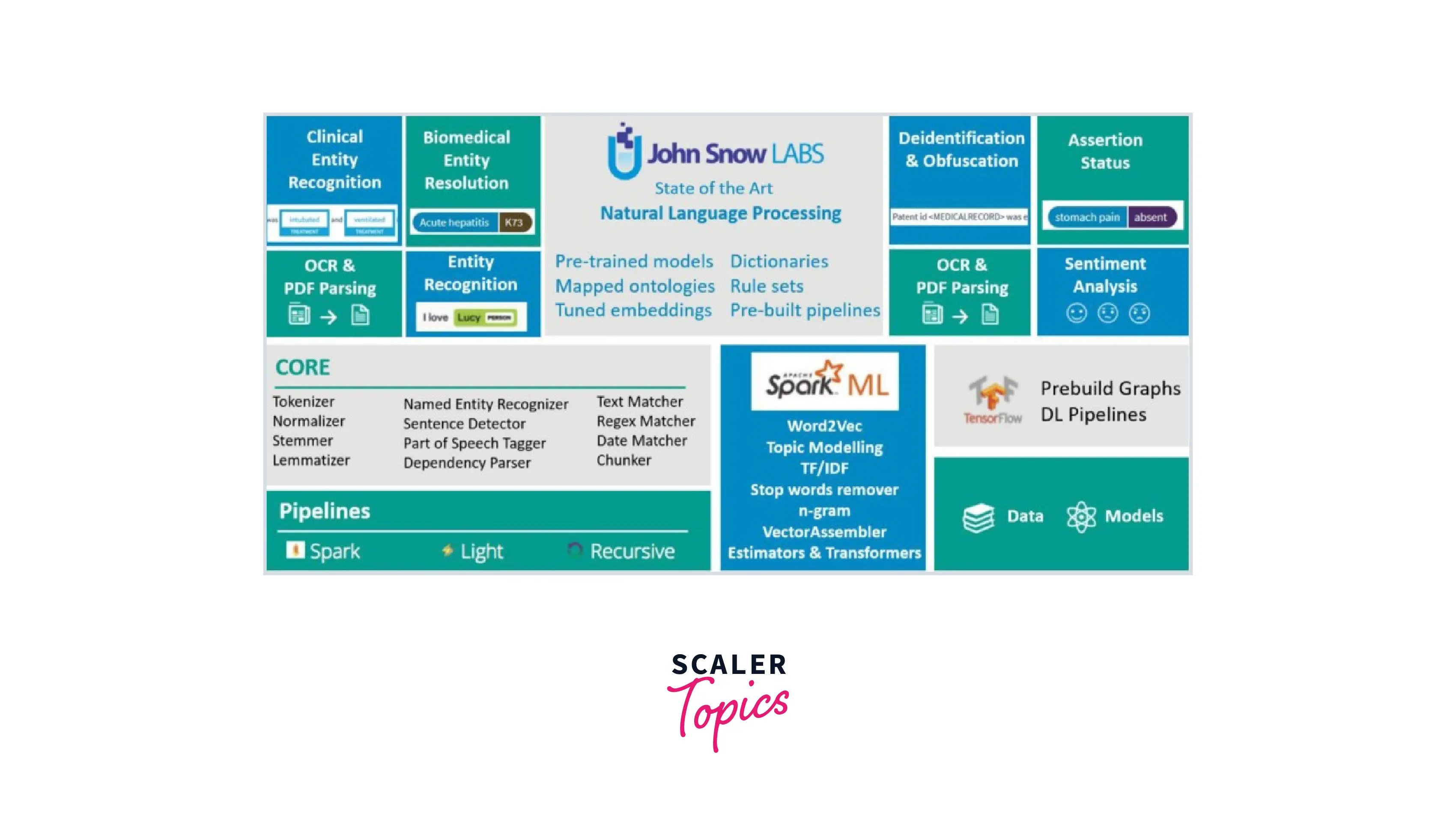
Now, Apache Spark has a module called Spark ML which has several machine-learning components -
- Estimators - trainable algorithms.
- Transformers - Either the result of a trained estimator or an algorithm that does not require any training.
- Pipeline - Estimators and Transformers can both be a part of a "pipeline," which is essentially a sequence of steps that are to be executed in order and depend on each other's result.
The module Spark NLP introduces what we call Annotators that merge within the framework and the algorithms within, working to predict the results in parallel. Let's talk about each component in detail.
Annotators
Before we get to annotators, let's look at the concept of Annotation.
Annotation is nothing but the basic result of any Spark NLP operation. The structure of an annotation looks like this:
- annotatorType: The type of annotator generated the current annotation.
- begin: It is the beginning of match content that is relative to raw text.
- end: It is the end of the content matched relative to raw text.
- result: As the name suggests, it is the main output.
- metadata: Metadata is data about data, i.e., contains additional information, as well as the content of the matched result.
- embeddings: This contains vector mappings if required.
This annotation object is generated automatically by annotators after a transform process. Manual work to create an annotation is not required.
Now, coming back to Annotators. They are the spearhead of natural language processing functions in Spark NLP. Annotators have 2 forms.
- Annotator Approaches: Annotator Approaches are those that require a training stage and represent a Spark ML Estimator. They have a fit(data) function that trains a model based on certain data. They create an annotator model or transformer, which is the second sort of annotator.
- Annotator Models: Annotator Models are transformers or spark models with a transform(data) function. This function takes a data frame as input and inserts a new column containing the outcome of the current annotation. All transformers are additive, which means they add to current data rather than replace or delete past data.
You can include both forms of annotators in a pipeline, and all of the annotators that are included in the pipeline will be executed in the order that is defined and will then transform the data accordingly. This pipeline is then turned into a PipelineModel after the fit() stage is called. This pipeline may be stored on the disk and reloaded at any time.
Here are some of the annotators that are offered by Spark NLP v2.2.2:
| Annotator | Description |
|---|---|
| Tokenizer | Identifies tokens that have tokenization open standards |
| Normalizer | It removes all the dirty characters from text |
| Stemmer | Returns stemmed form of words to retrieve the meaningful/root part of the word |
| Lemmatizer | Returns the lemmas of words to return the meaningful root of the word |
| RegexMatcher | Uses reference files to match some regular expressions and then place them in the provided key |
| TextMatcher | It is the annotator that matches entire phrases (by their token) provided in a file matched against a document |
| Chunker | In order to return relevant sentences from a document, a pattern of part-of-speech tags is matched |
| DateMatcher | Reads various date and time expressions and converts them to a specified date format. |
| SentenceDetector | Identifies sentence bounds in raw text. Pragmatic Segmenter rules are used |
| DeepSentenceDetector | Identifies sentence limits in raw text. A Named Entity Recognition DL model is used |
| POSTagger | Each word in a phrase is assigned a Part'Of'Speech tag |
| ViveknSentimentDetector | Each word in a phrase is assigned a Part'Of'Speech tag |
Pre-trained Models
PTMs (in the context of NLP) are models that have learned language representations after being trained on massive textual corpora. These representations can then be applied to subsequent NLP tasks.
Spark NLP provides the following pre-trained models in four languages (English, French, German, and Italian), and all you have to do is give the model name and then configure the model parameters based on your use case and dataset. Then, instead of having to train a new model from scratch, you may enjoy the pre-trained SOTA algorithms immediately applied to your data with the transform() function.
Let's take an example of loading a pre-trained named entity recognition model.
Transformers
There are certain types of columns in data frames that every annotator accepts or that an annotator can give as output. But what happens if we do not have that column type in our dataframe? That's when transformers come into play. There are 5 different transformers in Spark NLP that are used to get the data or transform it from one annotator type to another. Here are the transformers in Spark NLP:
- TokenAssembler: This transformer reconstructs a Document type annotation from tokens, normally after they've been normalized, lemmatized, normalized, spell checked, and so on, so that it may be used in other annotators.
- Doc2Chunk: Converts DOCUMENT type annotations into CHUNK type with the contents of a chunkCol.
- Chunk2Doc: Converts a CHUNK type column back into the DOCUMENT type column. This transformer can be used when trying to re-tokenize or do further analysis on a CHUNK result.
- Finisher: Once we have our NLP pipeline up and running, we may want to use our annotation findings somewhere else where they are easily accessible. The Finisher converts the values of the annotation into a string.
Features of Spark NLP
Some of the features of Spark NLP have already been mentioned. However, here is the list of features of Spark NLP.
- Tokenization
- Normalizer
- Lemmatizer
- Regex Matching
- Text Matching
- Chunking
- Date Matcher
- Part-of-speech tagging
- Sentence Detector
- Dependency parsing (Labeled/unlabeled)
- Sentiment Detection (ML models)
- Spell Checker (ML and DL models)
- Word Embeddings (GloVe and Word2Vec)
- BERT Embeddings
- ELMO Embeddings
- Universal Sentence EncoderSentence Embeddings
- Chunk Embeddings
- Stop Words Removal
- Stemmer
- NGrams
Application of Spark NLP
Now that we have read about the features of Spark NLP, along with its architecture, let's look at some examples of the applications of Spark NLP.
In this example, we're going to make use of a Pre-Trained Spark NLP pipeline called - Explain Document DL. This is a simple pipeline that can effectively streamline your text preprocessing tasks. It performs basic processing steps and also recognizes entities.
The first thing that we're going to do is import the Spark NLP library and start it up as follows:
Since our goal is to create a pipeline model that performs text preprocessing tasks, here are some of the annotators that are present in this pipeline by default:
- Tokenizer
- Deep Sentence Detector
- Lemmatizer
- Stemmer
- Part of Speech (POS)
- Context Spell Checker (NorvigSweetingModel)
- Word Embeddings (glove)
- NER-DL (trained by SOTA algorithm)
So our next step is to import the pre-trained pipeline.
This line of code would start the download of the pre-trained pipeline.
Output:
Now that we have the pipeline ready, we need to apply it to some text.
In the text above, we have two misspelled words - beautiful and picture. Let's observe the results now.
Output:
Let us now try and look at the results of different steps of the pipeline such as - lemmatization, stems, part of speech tags, and also spell check, etc, and store it in a pandas data frame.
Output:
| token | stem | lemma | pos | spell checked | ner | |
|---|---|---|---|---|---|---|
| 0 | John | john | John | NNP | John | I-PER |
| 1 | Smith | smith | Smith | NNP | Smith | I-PER |
| 2 | would | would | would | MD | John | O |
| 3 | love | love | love | VB | love | O |
| 4 | to | to | to | TO | to | O |
| 5 | visit | visit | visit | VB | visit | O |
| 6 | many | mani | many | JJ | many | O |
| 7 | beautful | beauti | beautiful | JJ | beautiful | O |
| 8 | cities | citi | city | NNS | cities | O |
| 9 | and | and | and | CC | and | O |
| 10 | take | take | take | VB | take | O |
| 11 | a | a | a | DT | a | O |
| 12 | pictre | pictur | picture | NN | picture | O |
| 13 | . | . | . | . | . | O |
| 14 | He | he | He | PRP | He | O |
| 15 | lives | live | life | VBZ | lives | O |
| 16 | in | in | in | IN | in | O |
| 17 | Germany | germani | Germany | NNP | Germany | I-LOC |
| 18 | for | for | for | IN | for | O |
| 19 | the | the | the | DT | the | O |
| 20 | last | last | last | JJ | last | O |
| 21 | 12 | 12 | 12 | CD | 12 | O |
| 22 | years | year | year | NNS | year | O |
| 23 | . | . | . | . | . | O |
The spell checker in the pipeline has even fixed the spelling errors. This was one of the many applications of Spark NLP.
Conclusion
- In this article, we were introduced to a natural language processing module - Spark NLP.
- Spark NLP is an open-source NLP library built on top of Apache Spark and the Spark ML library.
- Here is why we need Spark NLP:
- A single unified solution for all the natural language processing needs
- A library that takes advantage of transfer learning and implements the latest and greatest algorithms and models present in natural language processing research
- Lack of any natural language processing library that is fully supported by Spark.
- Spark NLP consists of the following:
- Annotators: Annotation is the basic result of any Spark NLP operation. The annotation object is generated automatically by annotators after a transform process. They are the spearhead of natural language processing functions in Spark NLP.
- Pre-Trained Models: PTMs (in the context of NLP) are models that have learned language representations after being trained on massive textual corpora.
- Transformers