spaCy’s Statistical Models
Overview
The computer's ability to understand and interpret human language is termed Natural Language Processing(NLP). This aspect of machine learning is extremely useful and has been implemented in numerous ways. There are several libraries in the Python language that deals with NLP tasks. One such library is spaCy and this article revolves around the spaCy library.
Introduction
Unstructured textual data is produced at a large scale, and it’s important to process and derive insights from unstructured data. To do so, we need to convert the data into a form that is understood by the computer and NLP is the way to do it. spaCy is a free and open-source library for Natural Language Processing in Python with a lot of in-built capabilities. The popularity of spaCy is growing steadily as the factors that work in its favor of spaCy are the set of features it offers, the ease of use, and the fact that the library is always kept up to date.
What are Statistical Models?
The process of applying statistical analysis to a dataset is called statistical modeling. A statistical model is a mathematical representation (or model) of observed data.
spaCy's statistical models are the power engines of spaCy. These models help spaCy to perform several NLP-related tasks, such as part-of-speech tagging, named entity recognition, and dependency parsing.
List of Statistical Models in spaCy
- en_core_web_sm: English multi-task CNN trained on OntoNotes. Size — 11 MB
- en_core_web_md: English multi-task CNN trained on OntoNotes, with GloVe vectors trained on Common Crawl. Size — 91 MB
- en_core_web_lg: English multi-task CNN trained on OntoNotes, with GloVe vectors trained on Common Crawl. Size — 789 MB
We import the spaCy models using spacy.load(‘model_name’).
How to Use the Statistical Models?
Using Your Model
We will perform POS tagging using spaCy
To use spaCy for your model, follow the steps below:-
- Install spaCy from your command line.
- Import the package
- Create spaCy object
- Print the tags using the spacy object
Output:-
Naming Conventions
In spaCy, all the pipeline packages follow the naming convention: [lang]_[name]. For spaCy’s pipelines, we divide the name into three components:
- Type: This signifies capabilities (e.g. core for the general-purpose pipeline with tagging, parsing, lemmatization, and named entity recognition, or dep for only tagging, parsing, and lemmatization).
- Genre: Type of text the pipeline is trained on, e.g. web or news.
- Size: Package size indicator, sm, md, lg, or trf.
Package Versioning
The pipeline package versioning signifies both the compatibility with spaCy, as well as the model version. A package version a.b.c means:-
- spaCy major version: For example, 2 for spaCy v2.x.
- spaCy minor version: For example, 3 for spaCy v2.3.x.
- Model version: Different model config: e.g. from being trained on different data, with different parameters, for different numbers of iterations, with different vectors, etc.
spaCy’s Processing Pipeline
Let's create a spaCy object.
Now, pass a string of text to the nlp object, and receive a Doc object.
What does the NLP Object do?
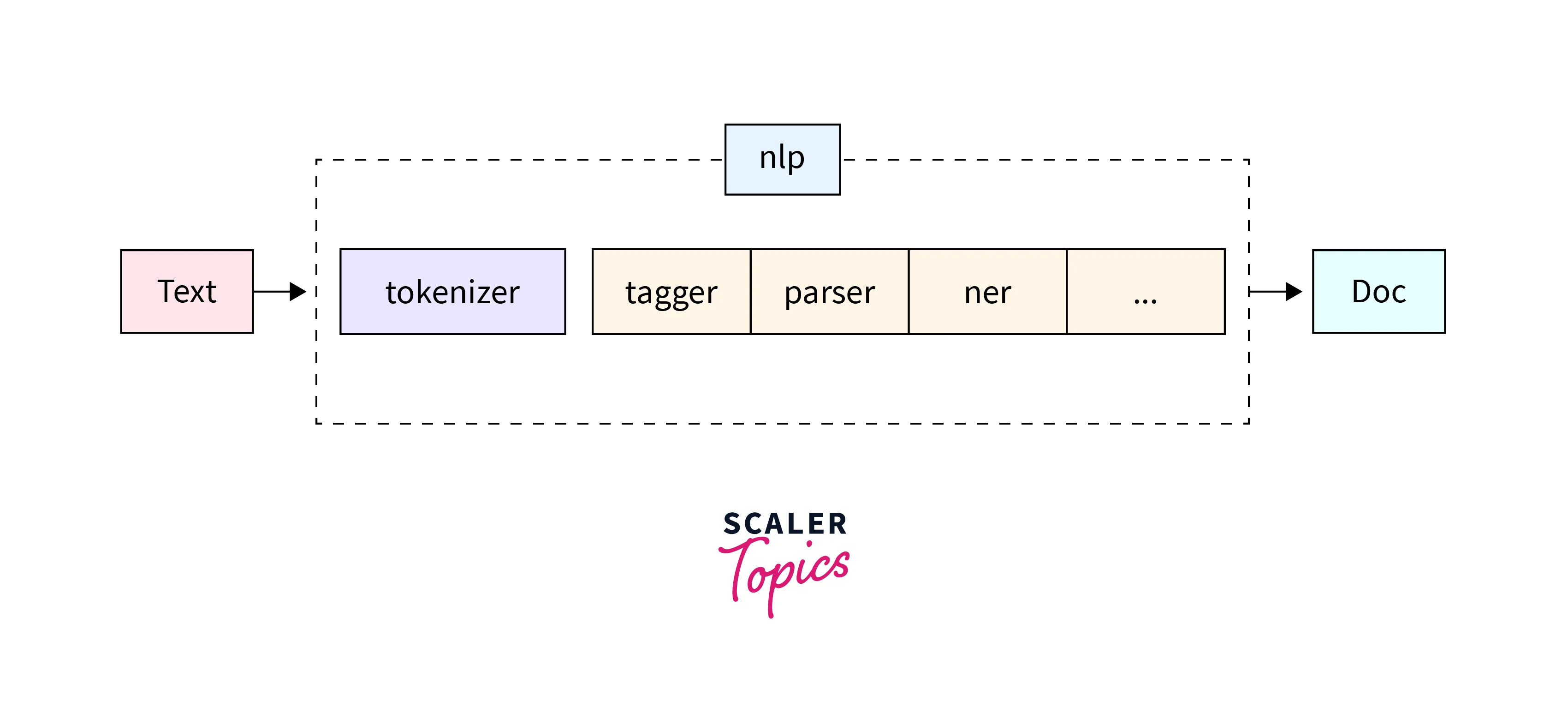
- First, the tokenizer is applied to turn the string of text into a Doc object.
- Next, a series of pipeline components are applied to the doc in order. In this case, the tagger, then the parser, then the entity recognizer.
- Finally, the processed doc is returned, so you can work with it.
Conclusion
The key takeaways from this article are:-
- spaCy is a free and open-source library for Natural Language Processing in Python with a lot of in-built capabilities.
- The process of applying statistical analysis to a dataset is called statistical modeling.
- The statistical models help spaCy to perform several NLP-related tasks, such as part-of-speech tagging, named entity recognition, and dependency parsing.