Syntax-Driven Semantic Analysis in NLP
Overview
Semantic analysis means checking the text for meaningfulness. It is defined as drawing the exact or the dictionary meaning from a piece of text. One should not confuse semantic analysis with lexical analysis. Lexical analysis is based on smaller tokens, but on the other side, semantic analysis focuses on larger chunks. In Natural Language Processing or NLP, semantic analysis plays a very important role. This article revolves around the syntax-driven semantic analysis in NLP.
Introduction
One of the prerequisites of this article is a good knowledge of grammar in NLP.
Syntax-driven semantic analysis is the process of assigning representations based on the meaning that depends solely on static knowledge from the lexicon and the grammar. This provides a representation that is "both context-independent and inference free".
Syntax-driven semantic analysis is based on the principle of composability.
Definition:
The meaning of a sentence is the sum of the meanings of its constituent elements.
However, this idea should not be interpreted. The meaning of a sentence is not just based on the meaning of the words that make it up but also on the grouping, ordering, and relations among the words in the sentence.
What is Syntax?
Syntax refers to the set of rules, principles, and processes involving the structure of sentences in a natural language.
The syntactic categories of a natural language are as follows:
- Sentence(S)
- Noun Phrase(NP)
- Determiner(Det)
- Verb Phrase(VP)
- Prepositional Phrase(PP)
- Verb(V)
- Noun(N)
Syntax is how different words, such as Subjects, Verbs, Nouns, Noun Phrases, etc., are sequenced in a sentence.
Semantic Errors
A semantic error is a text which is grammatically correct but doesn’t make any sense.
Consider the statement in the C language:
1.25 is not an integer literal, and there is no implicit conversion from 1.25 to int, so this statement does not make sense. But it is grammatically correct.
Semantic errors are also called malapropisms. This means replacing a word with another existing word similar in letter composition and/or sound but semantically incompatible with the context.
Attribute Grammar
Attribute Grammar is a special type of context-free grammar. To provide context-sensitive information, some additional information (attributes) is appended to one or more of its non-terminals.
In other words, attribute grammar provides semantics to context-free grammar. Attribute grammar, when viewed as a parse tree, can pass values or information among the nodes of a tree.
Example
The right part of the CFG contains the semantic rules that signify how the grammar should be interpreted. Here, the values of non-terminals S and E are added together and the result is copied to the non-terminal S.
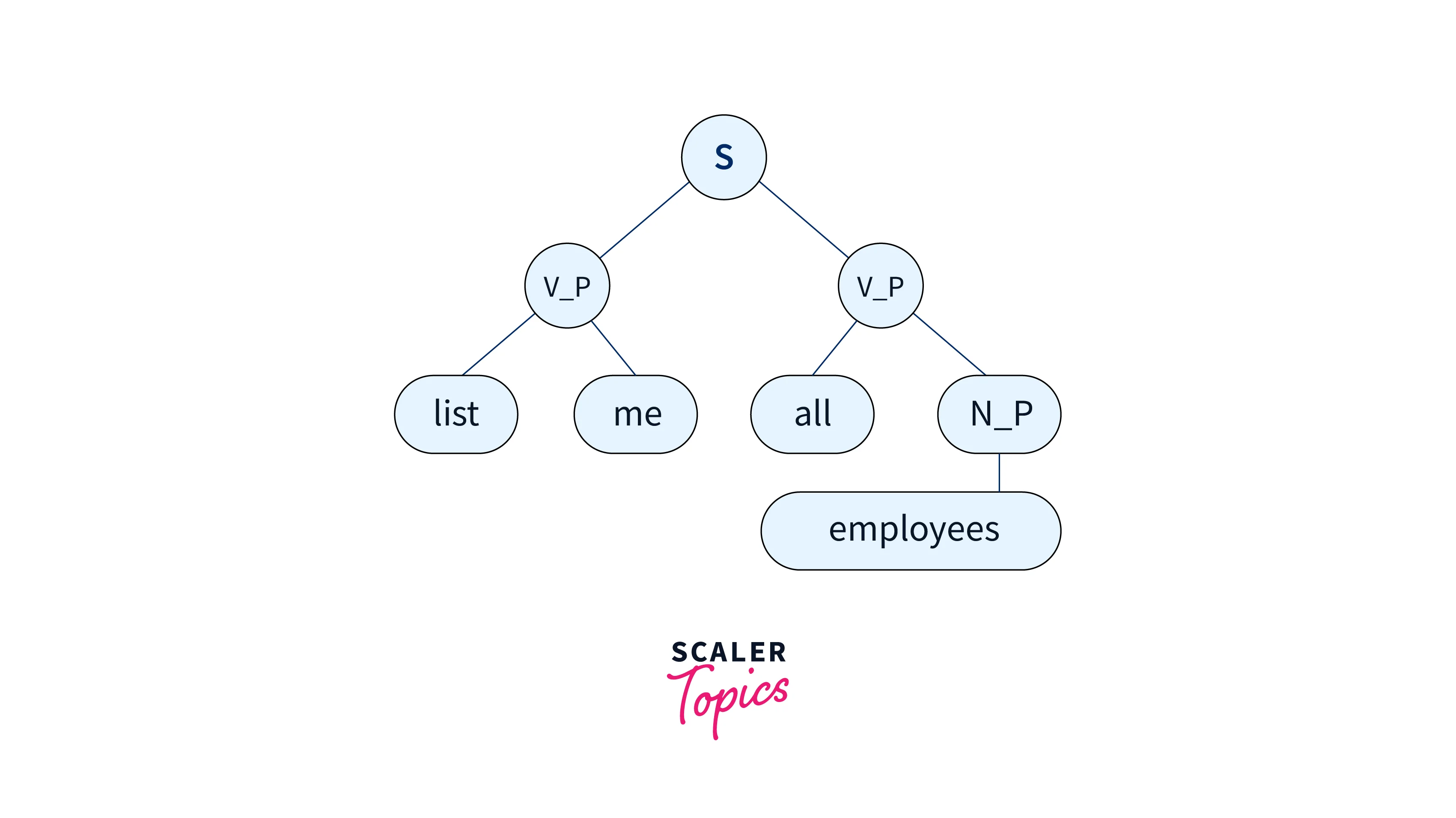
Steps in Semantic Representation
Mapping of a Parse Tree to Semantic Representation
Semantic parsing is the process of mapping natural language sentences to formal meaning representations. Semantic parsing techniques can be performed on various natural languages as well as task-specific representations of meaning.
Semantic Analysis is related to creating representations for the meaning of linguistic inputs. It deals with how to determine the meaning of the sentence from the meaning of its parts. So, it generates a logical query which is the input of the Database Query Generator.
- The task of the Database Query Generator is to map the elements of the logical query to the corresponding elements of the user databases.
- The query generator uses four routines, each of which manipulates only one specific part of the query.
- The first routine selects the part query that corresponds to the appropriate DML command with the attribute's names (i.e. SELECT * clause).
- The second routine selects the part of the query that would be mapped to a table's name or a group of tables' names to construct the FROM clause.
- The third routine selects the part of the query that would be mapped to the WHERE clause (condition).
- The fourth routine selects the part of the natural language query that corresponds to the order of displaying the result (ORDER BY clause with the name of the column).
The purpose of this system is to get the correct result from the database. It executes the query on the database and produces the results required by the user.
Lambda Calculus
Lambda calculus is a notation for describing mathematical functions and programs. It is a mathematical system for studying the interaction of functional abstraction and functional application. It captures some of the essential, common features of a wide variety of programming languages. As it directly supports abstraction, it is a more natural model of universal computation than a Turing machine.
Syntax
A λ-calculus term is:
- a variable x∈Var, where Var is a countably infinite set of variables;
- an application, a function e0 applied to an argument e1, usually written or , or
- a lambda abstraction, an expression λx.e representing a function with input parameter x and body e. Where a mathematician would write x ↦ x2, or an SML programmer would write , in the λ-calculus, we write λx.x2.
Ambiguity Resolution
POS Tagger
Language cannot elude ambiguity. Not only could a sentence be written in different ways and still convey the same meaning, but even lemmas — a concept that is supposed to be far less ambiguous — can carry different meanings.
Consider the following sentences:
- The batsmen had a good play today.
- I am learning to play the guitar.
The word "play" has two completely different meanings in both sentences. The first one is a noun, and the second is a verb. Assigning the correct grammatical label to each token is called PoS (Part of Speech) tagging, and it’s not a piece of cake.
The ambiguity in POS tagging can be resolved using expert.ai.
Code Implementation:
Let's import the library first.
For this code example, we will take two sentences with the same word(lemma) "key".
The first "key" is a noun and the second one is an adjective.
To analyze each sentence we need to create a request to NL API: the most important parameters — shown in the code below as well — are the text to analyze, the language, and the analysis we are requesting, represented by the resource parameter.
Creating the first request from the api:
Let's see the results:
Output:
The model is correct! The first sentence's "key" is a noun.
Let's check the next sentence:
Output:-
Correct again! This time the lemma "key" is tagged as an adjective.
WSD Mechanism
WSD stands for Word Sense Disambiguation. It is the ability to determine which meaning of the word is activated by the use of the word in a particular context. WSD is used in the problem of resolving semantic ambiguity.
For example, consider the two examples of the distinct sense that exist for the word “bass” −
- I can hear the bass sound.
- He likes to eat grilled bass.
The first "bass" is an adjective and the second one is a noun.
Let's see some of the methods for word sense disambiguation(WSD):
- Dictionary-based or Knowledge-based Methods:
These methods primarily rely on dictionaries, treasures, and lexical knowledge base. They do not use corpora evidence for disambiguation. - Supervised Methods:
In these methods, machine learning models make use of sense-annotated corpora to train. The models assume that the context can provide enough evidence on its own to disambiguate the sense. The context is represented as a set of “features” of the words. It includes information about the surrounding words also. However, the words knowledge and reasoning are deemed unnecessary. Support vector machine and memory-based learning are the most successful supervised learning approaches to WSD. - Semi-supervised Methods:
Word sense disambiguation algorithms use semi-supervised learning methods due to a lack of training corpus. Semi-supervised methods use both labeled as well as unlabeled data. These methods require a very small amount of annotated text and a large amount of plain unannotated text. The technique that we use by semisupervised methods is bootstrapping from seed data. - Unsupervised methods:
These methods have no labelled data. They assume that similar senses occur in a similar context. they work on the principle that senses can be induced from the text by clustering word occurrences by using some measure of similarity of the context. They are also called word sense induction or discrimination.
Conclusion
The key takeaways from this article are:
- Syntax-driven semantic analysis is assigning meaning representations based solely on static knowledge from the lexicon and the grammar.
- It provides a representation that is "both context-independent and inference free".
- A semantic error is a text which is grammatically correct but doesn’t make any sense.
- Ambiguity in semantic analysis can be removed by using expert.ai in POS tagging and the WSD mechanism.