T5 (Text-to-Text Transfer Transformer)
Overview
T5 transformers, also known as Text-to-Text Transfer Transformers, is a cutting-edge transformer-based language model developed by researchers at Google. It has gained widespread attention and acclaim in the field of Natural Language Processing (NLP) due to its innovative and unified approach to handling diverse NLP tasks.
What is T5?
T5 represents a significant advancement in NLP models, as it introduces a novel text-to-text framework. Unlike traditional models that are designed to address specific tasks, T5 transformers treat all NLP tasks as text-to-text transformations. In this framework, both the input and output for various NLP tasks are treated as textual sequences, making the model more adaptable and versatile.
Under this approach, T5 transformers can perform various tasks, including text classification, translation, summarization, question-answering, and more, by rephrasing the problem as a text generation task. This simplifies the model's architecture and training process, enabling it to leverage its pre-training knowledge effectively for downstream tasks.
Pre-training of T5 Model
T5 transformers use a transformer-based architecture for pre-training, which allows them to capture long-range dependencies and context effectively. The transformer architecture employs attention mechanisms to focus on relevant parts of the input text, making it highly efficient at handling sequential data.
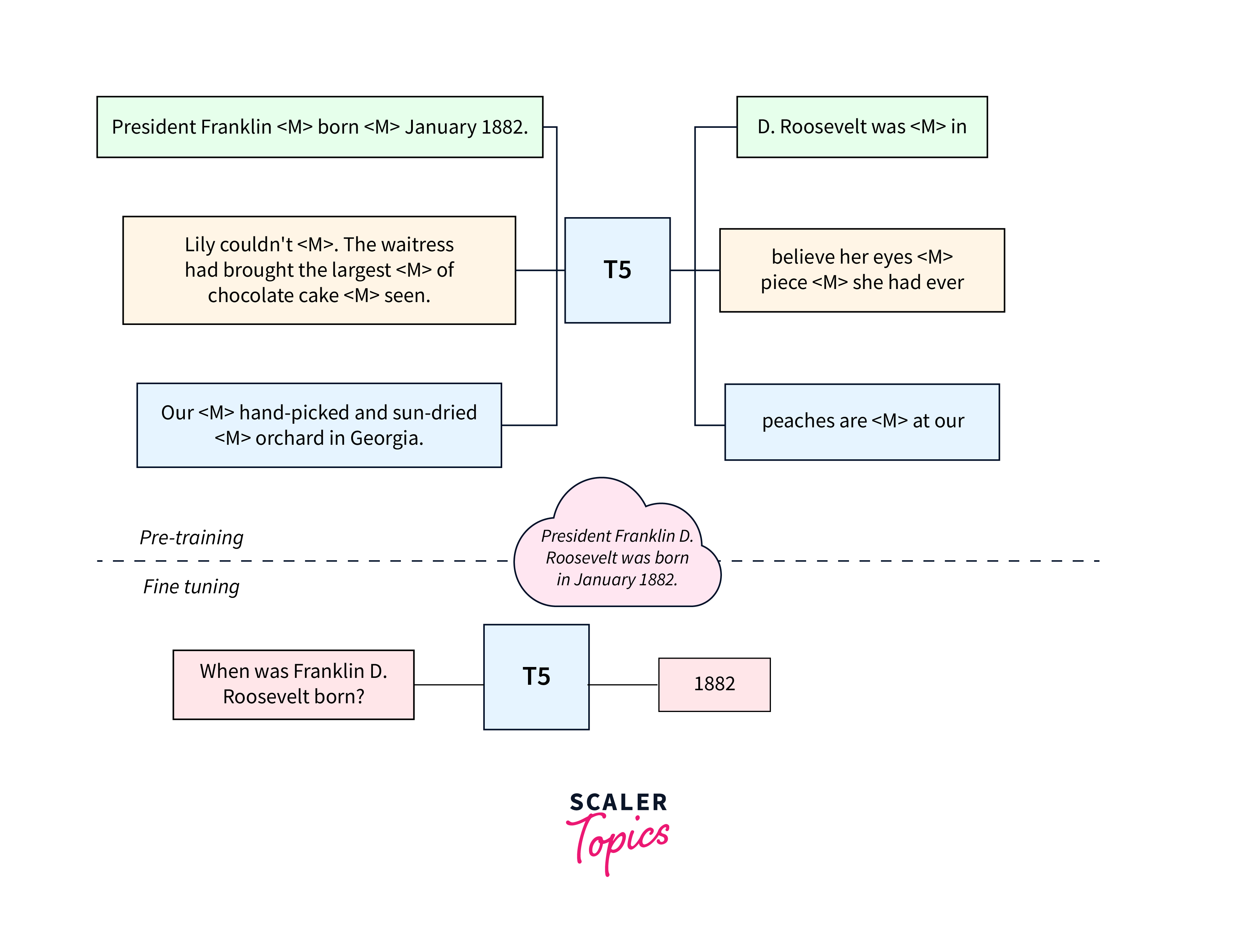
In pre-training, T5 is trained to predict missing or masked words within sentences. By learning to fill in the gaps effectively, the model acquires a comprehensive understanding of syntax, semantics, and grammar. This unsupervised learning process equips T5 transformers with rich linguistic knowledge, making it a powerful language model.
After pre-training on a massive amount of data, T5 transformers become proficient in understanding the intricacies of language, making it ready for fine-tuning on specific NLP tasks. Fine-tuning allows the model to adapt its pre-trained knowledge to perform well on targeted downstream applications, leading to impressive performance across various NLP benchmarks and challenges.
Some key points to note about T5 pre-training are:
- T5 is an encoder-decoder model and converts all NLP problems into a text-to-text format.
- T5 is trained using teacher forcing, which means that for training, we always need an input sequence and a corresponding target sequence.
- T5 is pre-trained on a multi-task mixture of unsupervised and supervised tasks.
- T5 is trained with a multi-task learning methodology, where the idea is to club multiple tasks while pre-training the model.
- T5 is trained with the MLM (Masked Language Model) objective, which is similar to BERT.
- T5 models need a slightly higher learning rate than the default one set in the Trainer when using the AdamW optimizer.
Transfer Learning to Specific NLP Tasks
After pre-training on a vast corpus of raw text data, T5 becomes a language model with a deep understanding of language structures and semantics. The real power of T5 lies in its ability to transfer this knowledge to various specific NLP tasks. This transfer learning process involves taking the pre-trained T5 model and fine-tuning it on task-specific datasets.
The key idea behind transfer learning is that the knowledge gained during pre-training can be leveraged and adapted to new tasks. Rather than starting from scratch for each NLP task, fine-tuning allows T5 to build upon its pre-trained linguistic understanding and customize it for the targeted applications.
Fine-tuning T5 for Downstream Applications
To fine-tune the T5 model for downstream applications using the Hugging Face Transformers library you can follow these steps:
-
Install the required libraries:
Install the Hugging Face Transformers library and any other necessary dependencies by running the following command -
Import the required modules:
Import the necessary modules from the Transformers library -
Load the T5 model and tokenizer:
Load the pre-trained T5 model and tokenizer using the T5ForConditionalGeneration and T5Tokenizer classes -
Prepare the dataset:
Download and preprocess the dataset you want to use for fine-tuning. Make sure the dataset is in a format suitable for your downstream application. -
Tokenize the dataset:
Tokenize the dataset using the T5 tokenizer. This step converts the text data into numerical tokens that the model can understand. -
Prepare the input and output tensors:
Extract the input and output tensors from the encoded dataset. -
Fine-tune the model:
Fine-tune the T5 model on your dataset using the AdamW optimizer. -
Save the fine-tuned model:
Save the fine-tuned model for future use.
Note: that the above code assumes you have already defined the dataset_text variable with your actual dataset. Additionally, you may need to modify the code based on the specific requirements of your downstream application and dataset.
T5's Text-to-Text Framework
T5's text-to-text framework represents a paradigm shift in NLP models, offering enhanced flexibility, transfer learning capabilities, and improved performance across various NLP tasks. This innovative approach has contributed significantly to advancing the state-of-the-art in natural language understanding and generation.
Text-to-Text Approach in T5
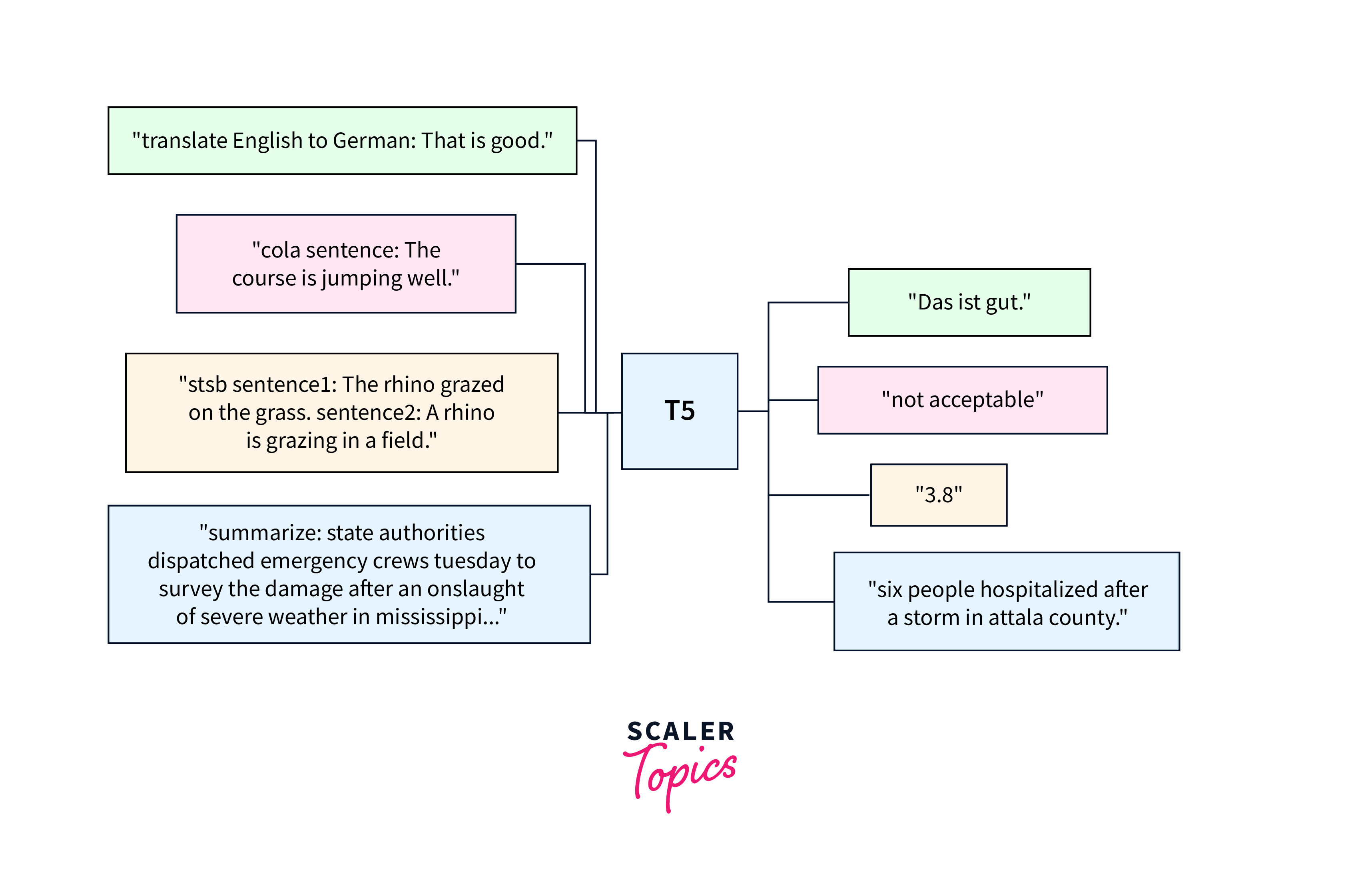
The Text-to-Text Transfer Transformer (T5 transformer), unlike traditional NLP models that use task-specific architectures and formulations, T5 frames all NLP tasks as text-to-text transformations. This unified approach treats the input and output of various tasks as textual sequences.
In the text-to-text framework, every NLP task is redefined as a problem of transforming an input text into an output text. This allows T5 to handle a diverse range of tasks, including text classification, machine translation, summarization, question-answering, and more, by converting each task into a text generation problem.
By formulating all tasks in the same way, T5 enables a single model to handle a wide variety of NLP challenges without task-specific modifications. It learns to generate the correct output text based on the input text and the specific task, making it highly adaptable and capable of multitasking with ease.
How T5 Transforms Input and Output Formats?
To understand how the T5 transformer works within the text-to-text framework, let's consider an example of sentiment analysis. In traditional models, sentiment analysis might require an architecture designed specifically for classification, where the input is a sentence, and the output is a sentiment label (e.g., positive or negative).
However, in T5's text-to-text approach, sentiment analysis is transformed into a text generation task. The input text would be the sentence, and the desired output text would be the corresponding sentiment label as text (e.g., "positive" or "negative"). The model is then trained to generate the correct output text given the input text, effectively solving the sentiment analysis task as a text-to-text problem.
This approach is generalizable to a wide array of NLP tasks. For machine translation, the input would be the source text in one language, and the output would be the translated text in another language. For summarization, the input would be a long document, and the output would be a condensed summary. This consistency in input and output formats simplifies the training process and facilitates knowledge transfer across tasks.
Advantages of the Text-to-Text Framework:
The text-to-text framework employed by T5 offers several key advantages
a. Versatility:
T5's unified approach allows it to handle a vast array of NLP tasks without task-specific modifications or separate models for each task. This versatility greatly simplifies model deployment and management.
b. Transfer Learning:
By using the same text-to-text framework for pre-training, the T5 transformer acquires a broad understanding of language and can efficiently transfer this knowledge to different downstream tasks during fine-tuning. This transfer learning capability enhances performance and reduces the need for large amounts of task-specific training data.
c. Simplified Architecture:
The text-to-text framework enables a more straightforward and consistent model design compared to traditional task-specific architectures. This simplicity facilitates model development, debugging, and maintenance.
d. Multitasking:
T5 can handle multiple NLP tasks simultaneously due to the consistency in the text-to-text formulation. This multitasking ability allows for efficient use of computational resources and improved overall model performance.
T5 Variants and Model Sizes
T5 transformer comes in various model sizes, each with different numbers of parameters and complexity levels. The model sizes are typically denoted using terms like T5-Small, T5-Base, T5-Large, and so on.

The model size indicates the number of layers, hidden units, and other architectural components, influencing its capacity and performance.
T5-Small
T5-Small is the smallest variant of the T5 model. It has a relatively smaller number of parameters compared to larger versions, making it computationally efficient and suitable for scenarios with limited computational resources. However, its performance may be slightly lower compared to larger variants on complex tasks.
Pros:
- Computational Efficiency:
T5-Small requires less computational power for both training and inference, making it suitable for resource-constrained environments. - Quick Iteration:
Its smaller size allows for faster experimentation and model development.
Cons:
- Limited Capacity:
T5-Small may have limitations in handling more complex NLP tasks or capturing intricate language patterns effectively. - Performance Trade-off:
It might not achieve state-of-the-art performance on large-scale NLP benchmarks.
T5-Base
T5-Base is the standard or baseline version of T5. It strikes a balance between model complexity and efficiency, making it widely used and well-suited for many NLP tasks. It offers a good trade-off between computational cost and performance and serves as a solid starting point for most applications.
Pros:
- Balanced Performance:
T5-Base strikes a good balance between computational efficiency and task performance, making it a widely used variant. - Robustness:
It performs well across a broad range of NLP tasks and can be a reliable choice for various applications.
Cons:
- Moderate Computational Requirements:
While it is more efficient than larger variants, T5-Base still requires a substantial amount of computational resources for training and inference.
T5-Large
T5-Large is a larger and more powerful variant with more parameters than T5-Base. It exhibits improved performance on a wide range of NLP tasks, especially those requiring a deeper understanding of language. However, its larger size comes with increased computational requirements.
Pros:
- High Performance:
T5-Large typically achieves state-of-the-art results on many NLP benchmarks, surpassing smaller variants. - Complex Tasks:
It can handle complex NLP tasks that demand deeper language understanding.
Cons:
- High Computational Cost:
T5-Large demands significant computational power and memory, which can be expensive and time-consuming for training and inference. - Longer Training Time:
Training T5-Large models can take longer due to the increased number of parameters.
T5-XL
T5-XL is an extra-large variant, designed to handle even more complex NLP tasks. It typically outperforms smaller versions on most benchmarks but requires significant computational resources for training and inference.
Pros:
- Top Performance:
T5-XL often achieves the best results among T5 variants, making it a strong contender for research and advanced applications. - Complex Language Understanding:
It excels in tasks requiring extensive linguistic knowledge.
Cons:
- Extreme Computational Requirements:
T5-XL demands substantial computational resources, limiting its accessibility to well-equipped environments. - Longer Training Time:
Training T5-XL models is time-consuming due to their massive parameter size.
Evaluating T5's Performance
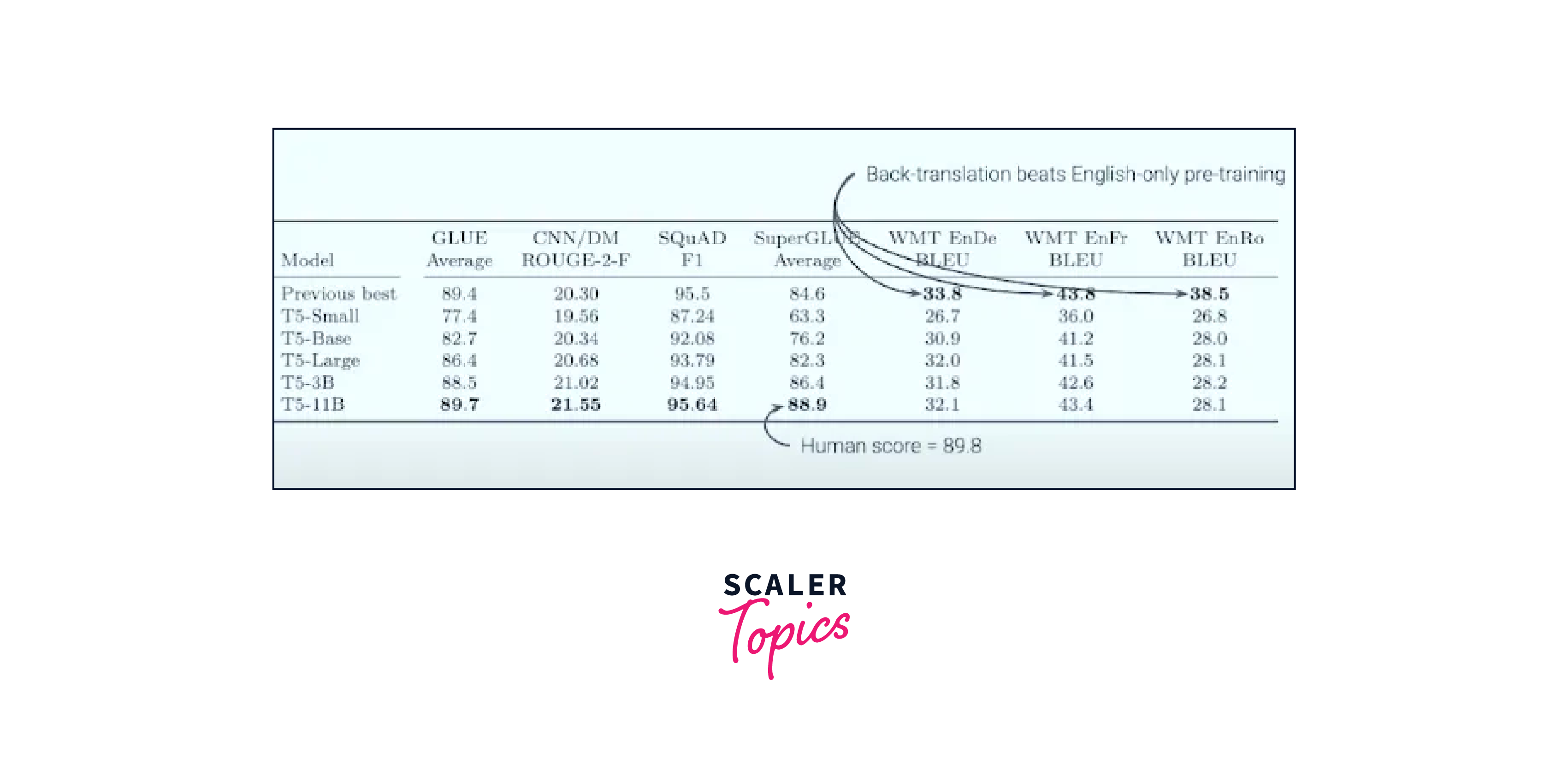
Comparing T5 transformer's results with those of other competitive models on these benchmarks helps identify its strengths and weaknesses, and how it ranks among state-of-the-art language models. The adaptability of T5 across these tasks is enabled by its text-to-text framework and its ability to transfer learned knowledge through fine-tuning.
Benchmarking T5 Against Other Language Models
Benchmarking is a crucial aspect of evaluating the T5 transformer's performance in comparison to other language models. Researchers and practitioners typically use standardized NLP datasets and tasks to assess how well T5 performs compared to other state-of-the-art models. Some popular benchmarks include:
-
GLUE (General Language Understanding Evaluation):
GLUE is a collection of diverse NLP tasks, including sentence classification, sentiment analysis, natural language inference, and more. T5 transformer's performance on the GLUE benchmark provides insights into its overall language understanding capabilities. -
SuperGLUE:
SuperGLUE is an extension of GLUE that consists of more challenging tasks, such as commonsense reasoning and advanced question-answering. Evaluating T5 on SuperGLUE highlights its ability to handle complex language understanding tasks. -
SQuAD (Stanford Question Answering Dataset):
SQuAD evaluates models on their ability to answer questions based on a given context. T5 transformer's performance on SQuAD showcases its reading comprehension and question-answering capabilities. -
WMT (Workshop on Machine Translation) Benchmarks:
T5's performance on translation tasks, such as English-to-German or German-to-English, is evaluated on WMT benchmarks. This assesses its ability to handle machine translation effectively.
Measuring T5's Generalization and Adaptability
Evaluating T5's generalization and adaptability involves assessing its ability to perform well on unseen or out-of-distribution data and tasks. Common approaches to measure generalization include:
-
Cross-Domain Evaluation:
T5's performance on tasks from domains or datasets not used during training indicates how well it generalizes to new contexts. -
Few-Shot Learning:
Evaluating T5 on tasks with limited training data (few-shot learning) assesses its ability to learn from small datasets effectively. -
Zero-Shot Learning:
Testing T5 on tasks it has not been explicitly fine-tuned on (zero-shot learning) demonstrates its capability to transfer knowledge from related tasks.
Applications of T5 in NLP Tasks
T5's versatility and strong performance make it applicable across a wide range of NLP tasks, including but not limited to:
- Text Generation:
T5 can generate human-like text, making it useful for tasks like text completion, text summarization, and creative writing. - Translation:
T5 excels in machine translation, allowing it to translate text between multiple languages with high accuracy. - Sentiment Analysis:
T5 can determine the sentiment of a text, classifying it as positive, negative, or neutral. - Question Answering:
T5's strong reading comprehension abilities enable it to answer questions based on provided contexts. - Named Entity Recognition (NER):
T5 can identify and extract entities (e.g., names, organizations, locations) from the text. - Text Classification:
T5 can categorize text into predefined classes, making it useful for tasks like spam detection and topic classification. - Dialog Systems:
T5 can be incorporated into conversational agents to generate responses and interact with users. - Text Paraphrasing:
T5 can rephrase sentences or texts while preserving the underlying meaning.
Conclusion
- T5, or Text-to-Text Transfer Transformer, is a powerful transformer-based language model developed by Google for Natural Language Processing (NLP) tasks.
- T5 frames all NLP tasks as text-to-text transformations, where both input and output are treated as textual sequences.
- T5 comes in different model sizes, such as T5-Small, T5-Base, T5-Large, and T5-XL, each with varying parameters and performance levels.
- T5's versatility is showcased in various NLP applications, including translation, sentiment analysis, question-answering, and text generation