Basic Text Representation in NLP
Overview
The first ever instructions which might have been fed to a computer were numerical. We already know that a computer is brilliant with numbers and has replaced the calculator. But did you know that they have replaced human jobs such as a call center agent or an assistant as well? The development in the field of computers has been going on for decades, and there is still a lot left to discover. But how can a computer understand and react to human language? How do when you open the Google app and ask a question, get the answers right away? All of this is possible because of the field of artificial intelligence called Natural Language Processing. This connects computers to human language by processing text, speech, and voice. Text data is integral to NLP and is readily available. We need to convert this data into a form that the computer can understand. This is basic text representation in NLP.
Introduction
The raw text corpus is preprocessed and transformed into a number of text representations that are input to the machine learning model. The data is pushed through a series of preprocessing tasks such as tokenization, stopword removal, punctuation removal, stemming, and many more. We clean the data of any noise present. This cleaned data is represented in various forms according to the purpose of the application and the input requirements of the machine learning model.
Common Terms Used While Representing Text in NLP
- Corpus( C ): All the text data or records of the dataset together are known as a corpus.
- Vocabulary(V): This consists of all the unique words present in the corpus.
- Document(D): One single text record of the dataset is a Document.
- Word(W): The words present in the vocabulary.
Types of Text Representation in NLP
Text representation can be classified into two types:-
- Discrete text representation
- Distributed text representation
In discrete text representation, the individual words in the corpus are mutually exclusive and independent of one another. Eg: One Hot Encoding. Distributed text representation thrives on the co-dependence of words in the corpus. The information about a word is spread along the vector which represents it. Eg: Word Embeddings.
This article focuses on the discrete text representation in NLP. Some of them are:-
- One Hot Encoding
- Bag of words
- Count Vectorizer
- TF-IDF
- Ngrams
One Hot Encoding
In this representation of NLP, every word in a text corpus is assigned a vector that consists of 0 and 1. This vector is termed the one hot vector in NLP. Every word is assigned a unique hot vector. This allows the machine learning model to recognize each word uniquely through its vector. The one hot vector contains a single "1", the rest all being zeroes. The "1" here is present in the position corresponding to the position of the word in the sentence or in the vocabulary.
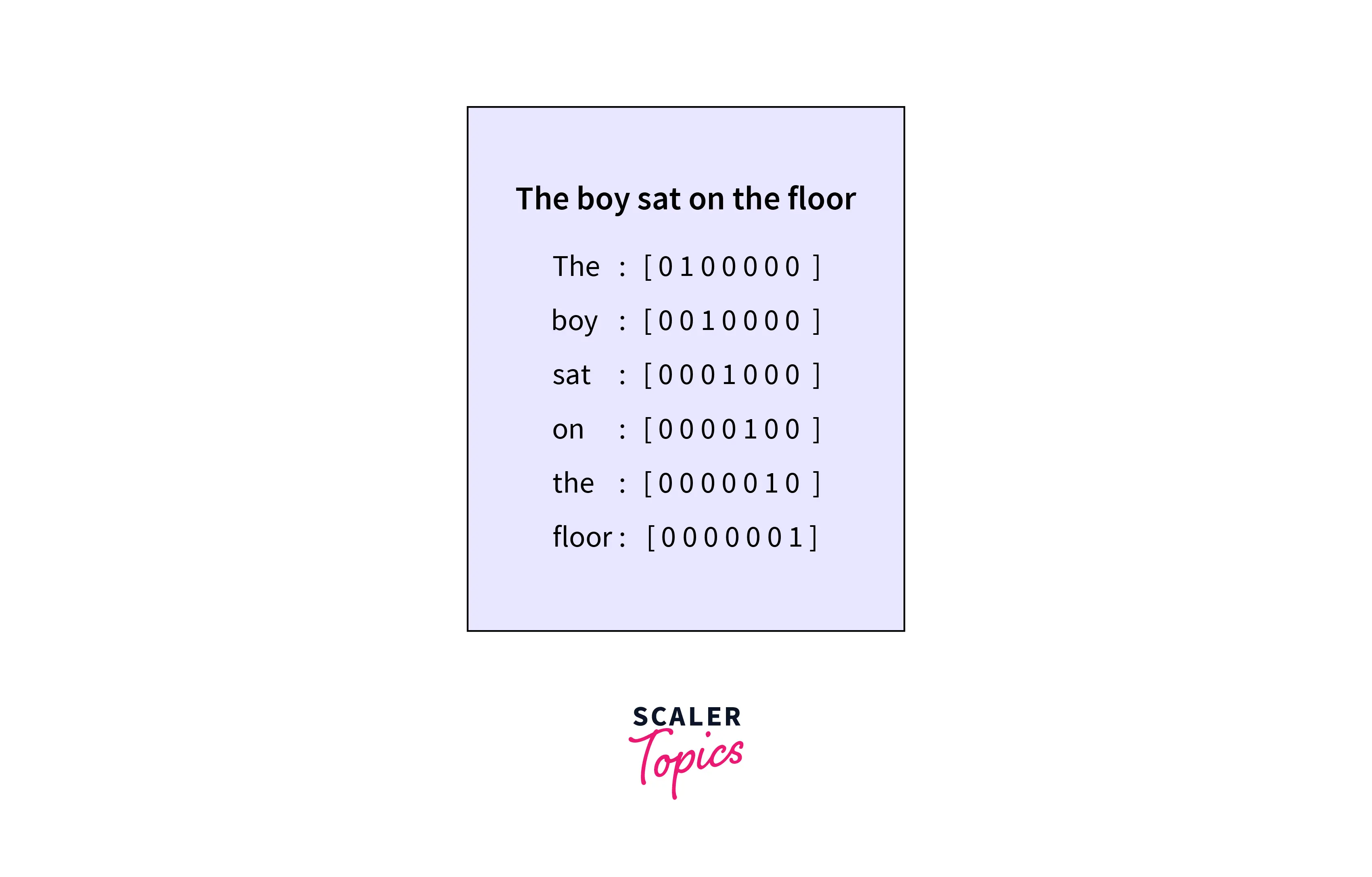
In this image, the word "The" is in position one. Hence there is "1" at index one in its one-hot vector. The same concept is applied to all the words. Notice the words "the and "the" have different one-hot vectors. We can avoid this by applying lower casing to all the words during text preprocessing. The size of this one-dimensional vector will be the size of the vocabulary.
When we apply one hot encoding, each word or token in the vocabulary is transformed into a vector. So the sentences involved are, in turn, transformed to a matrix of size (p,q). "p" is the number of tokens in the sentence, and "q" is the size of the vocabulary.
One hot encoding has one major drawback. The size of a one-hot vector is directly proportional to the size of the vocabulary of the corpus. So, as the size of the corpus increases, the size of the vector also increases. Hence it is not feasible to use one-hot encoding for very large corpora.
One hot encoding implementation using sklearn
Output:-
Advantages
- Easy to understand and implement
Disadvantages
- We get a highly sparse matrix with each sentence, the majority of the values are zero.
- If the documents are of different sizes, we get different-sized vectors.
- This representation does not capture the semantic meaning of the words.
Bag of Words
This representation, unlike one hot encoding, converts a whole piece of text into fixed-length vectors. This is done by counting the number of times a word has appeared in the document. The frequency count of words helps us to compare and contrast documents. This representation has a variety of applications such as topic modeling, document classification, spam email detection, and many more.

On an elementary level, the bag of words is implemented using CountVectorizer.
CountVectorizer
CountVectorizer implements the bag words concept by computing the frequency of each word in the corpus and creating a matrix with the sentences(or their position) as rows, and words as columns and filling it with the words' corresponding frequencies.
CountVectorizer is implemented using Sklearn.
Output:-
In the above code, you can see that NLP with index 5 has a count 3. The frequency can also denote the weightage of a word in a sentence. These weights can be leveraged for different types of analysis and used for training ML models.
Advantages of CountVectorizer
- Easy to implement
- We get the frequency of each word
- The size of the vector is the size of the dictionary.
Disadvantages of CountVectorizer
- We do not extract any semantic meaning from the words.
- This method also loses the positional information of a word.
- High-frequency words do not necessarily have the highest weightage.
On an advanced level, the bag of words is implemented using TF-IDF representation.
TF-IDF
This representation of text in NLP overcomes some of the drawbacks of CountVectorizer. There is a need to suppress high-frequency words and ignore very low-frequency words so that we can normalize the weights. The word which appears multiple times in a document and rarely in the corpus should have a good weightage. This weightage is calculated using two formulas:- Term Frequency and Inverse Document Frequency.
Term Frequency: The ratio of the number of occurrences of a word in a document to the number of terms in the document is called term frequency.
count of in / number of words in
"t" is the term and "d" is the number of terms in the .document The tf of the word "love" in the sentence "I love nlp" is 1/3.
Inverse document frequency: Idf of a term is the log of the ratio of the number of documents in the corpus to the number of documents with the term in them.
N is the number of documents and df is the number of documents with the term t. We add 1 to the denominator of the fraction to avoid division by 0.We multiply tf and idf to get the tf-idf weightage.
The tf-idf of the term t in document d is:
TF-IDF is implemented using TfidfVectorizer of the Sklearn library.
Output:-
Advantages
- Easy to understand and interpret.
- Penalizes both high and low-frequency words.
Disadvantages
- We do not capture the positional information of a word.
- Semantic meanings of the words are not captured.
Ngrams
This representation is similar to the countVectorizer bag words model, the only difference is that instead of calculating the frequency of one word we calculate the frequency of groups of words(in groups of two or more) occurring together in the corpus. In this way, we get a better understanding of the text. Based on the number of words grouped together, the model has termed a bigram (2 words), trigram(3 words), and so on.
Output:-
Notice that for the first statement the phrase "nlp has" with key 5, has contributed 1 to the fifth index in the resultant vector.
Advantages of Ngrams
- Ngrams capture the semantic meaning of the sentence and help in finding the relationship between words.
- Easy to implement
Disadvantages
- Out of vocabulary(OOV): We cannot capture the relationships between the words or their semantic meanings if they are not in the vocabulary
Linear Text Classification
Text classification is the supervised learning method of categorizing pieces of text available in the dataset. We assign labels to the text on the basis of their genre, specialty, etc. We can use text classification for sentiment analysis, topic detection, spam email detection, language detection, and many more.
We are going to see how classification models like RandomForest are implemented and how TF-IDF vectorizer is used.
We use the "Disaster tweet dataset from Kaggle", where each tweet is labeled as 1 if it is about a disaster and 0 otherwise.
The dataset looks like this :

After preprocessing, the dataset looks like this:

Output:-
We get the predictions for the testing part of the dataset from the classifier. The accuracy of the model is 78.7%
Applications of Text Representation
- Text Classification:
- For the classic problem of text classification, it is important to represent text in vector form so as to process it for classification of text.
- Topic Modelling:
- The topic modeling use case of NLP requires text to be represented in the correct format to be modeled into different topics.
- Autocorrect Model:
- The autocorrect model, as the name suggests is the model that is used for correcting spelling errors, for the most part. Now for the suggestions to be accurate, we need our texts represented in a format that uses probability.
- Text Generation:
- Much like the previous use case, text generation too requires a probabilistic text representation format.
Conclusion
This article was all about text representation in NLP. Here are the key takeaways from this article:-
- Representing text in a particular manner is very crucial before training a machine learning model.
- The more complex the representation gets, the more accuracy and results of the model get better.
- We learned about discrete text representations such as one hot encoding, bag of words, tf-idf, etc. and how they are implemented.
- We saw how one hot encoding encodes each word into a sparse vector and how countVectorizer uses the frequency of each word to encode it, squeezing the entire sentence into a single vector.
- Tf-Idf improves the countVectorizer, by attempting to normalize the weightage of all the words in the corpus.
- Finally we saw the different methods to classify text.
Text representation is crucial, without it, things will get very difficult. Every NLP implementation that involves text data needs a good text representation. The aim of this article was to provide some basic ideas for representing text in NLP, more efforts should be invested in further understanding of these representations.